帮助文档与用户指南
欢迎来到 Synthetic Data Generator 的官方文档中心。本手册旨在为您配置各类统计学模块的参数提供全面指导,从而生成稳健且具备学术严谨性的虚拟数据集。
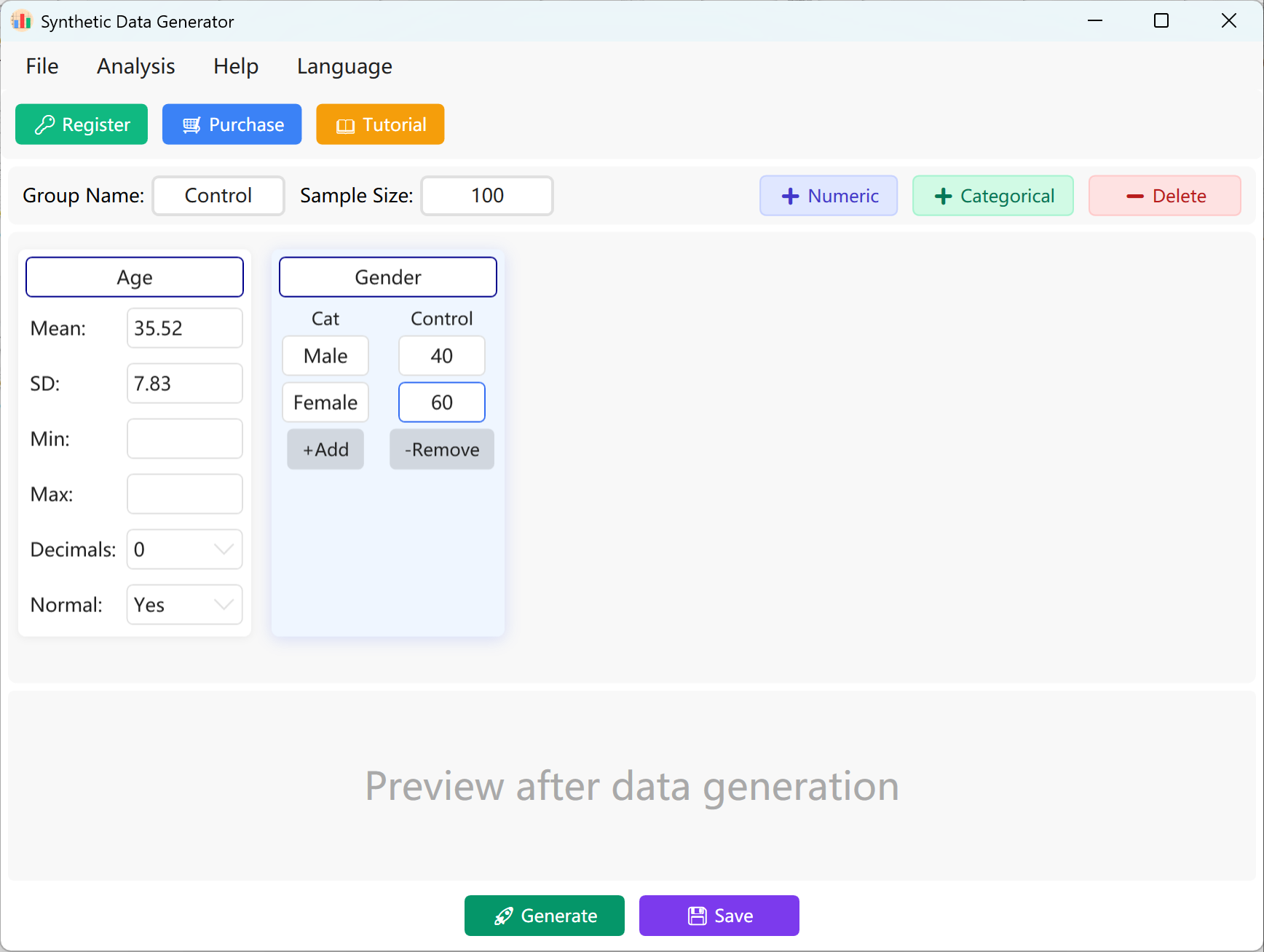
1. 总览与通用界面
主仪表板是各个模块选择的核心枢纽。用户可以在此处定义全局样本量、组别名称(如:控制组、实验组)以及跨学科的变量类型(数值型或分类变量)。
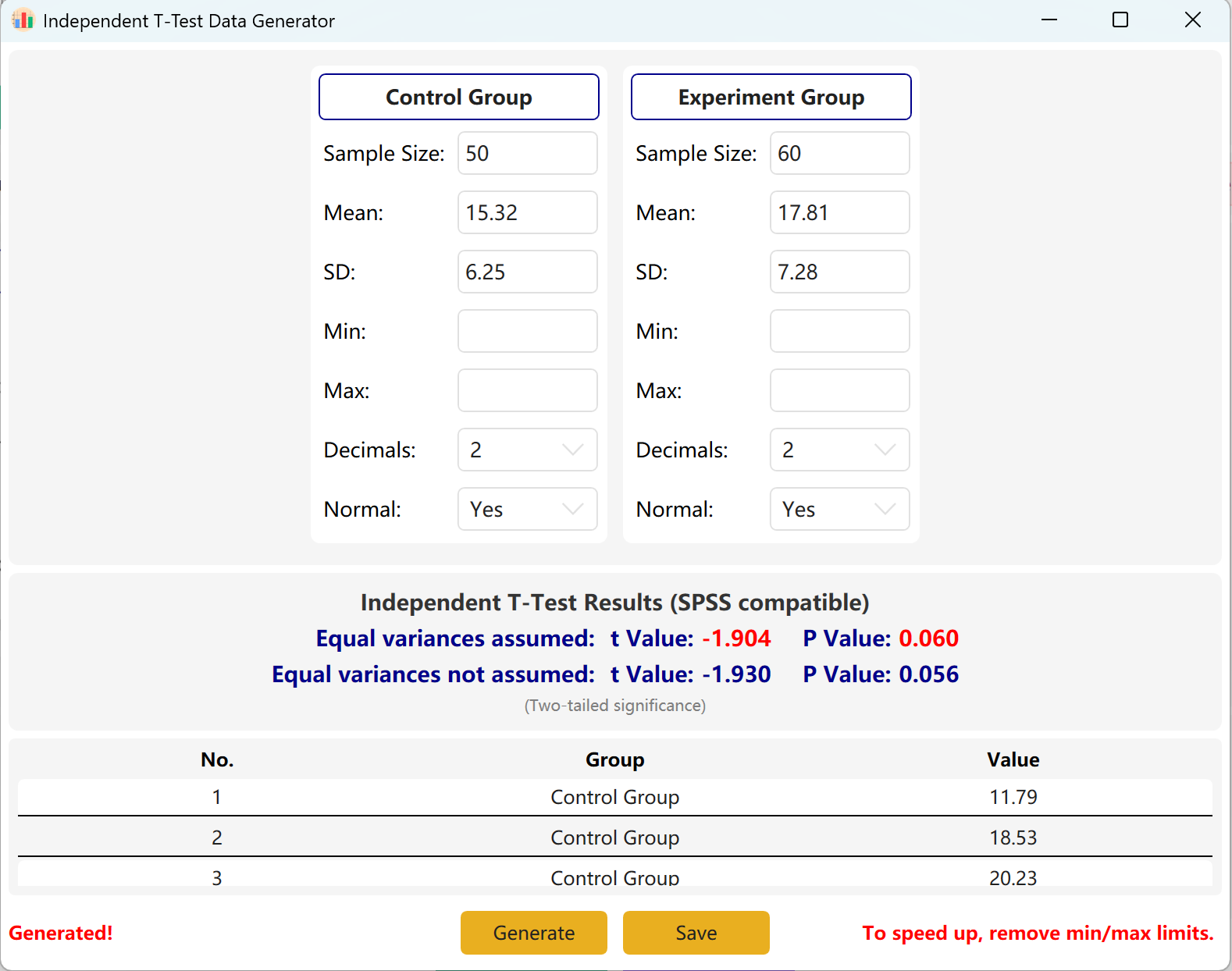
2. 独立样本 T 检验
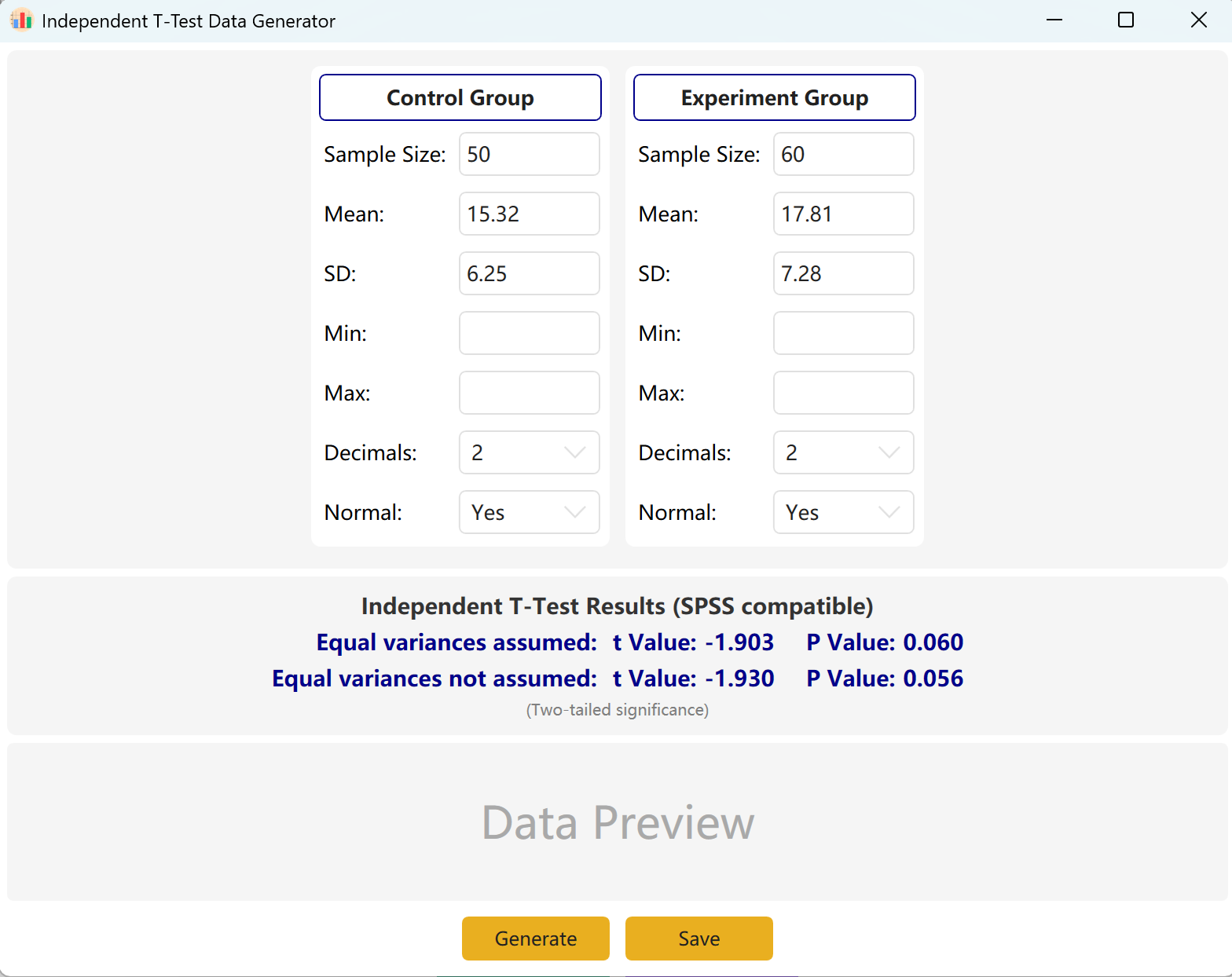
专为比较两个不同组别均值的横断面研究设计。广泛应用于临床试验(例如治疗组与安慰剂组间的疗效差异)以及社会学调查中。
- 组别配置: 可独立设置每组的样本量 (N)、均值 (μ) 和标准差 (σ)。
- 分布控制: 提供强制正态分布拟合的选项。
- 数据输出: 生成兼容 SPSS 的结果,包含方差齐性检验(Levene's Test)及双尾显著性 P 值。
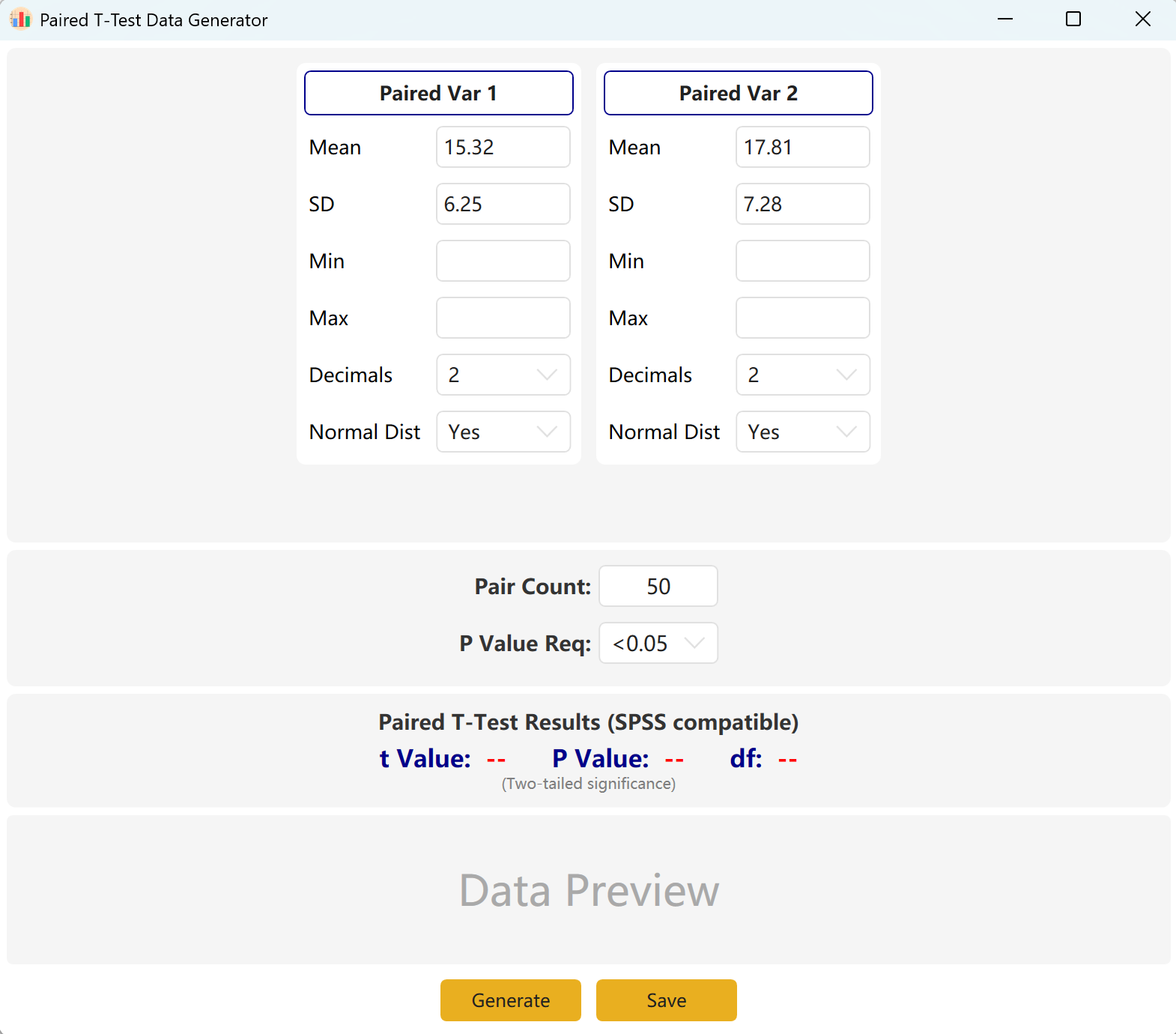
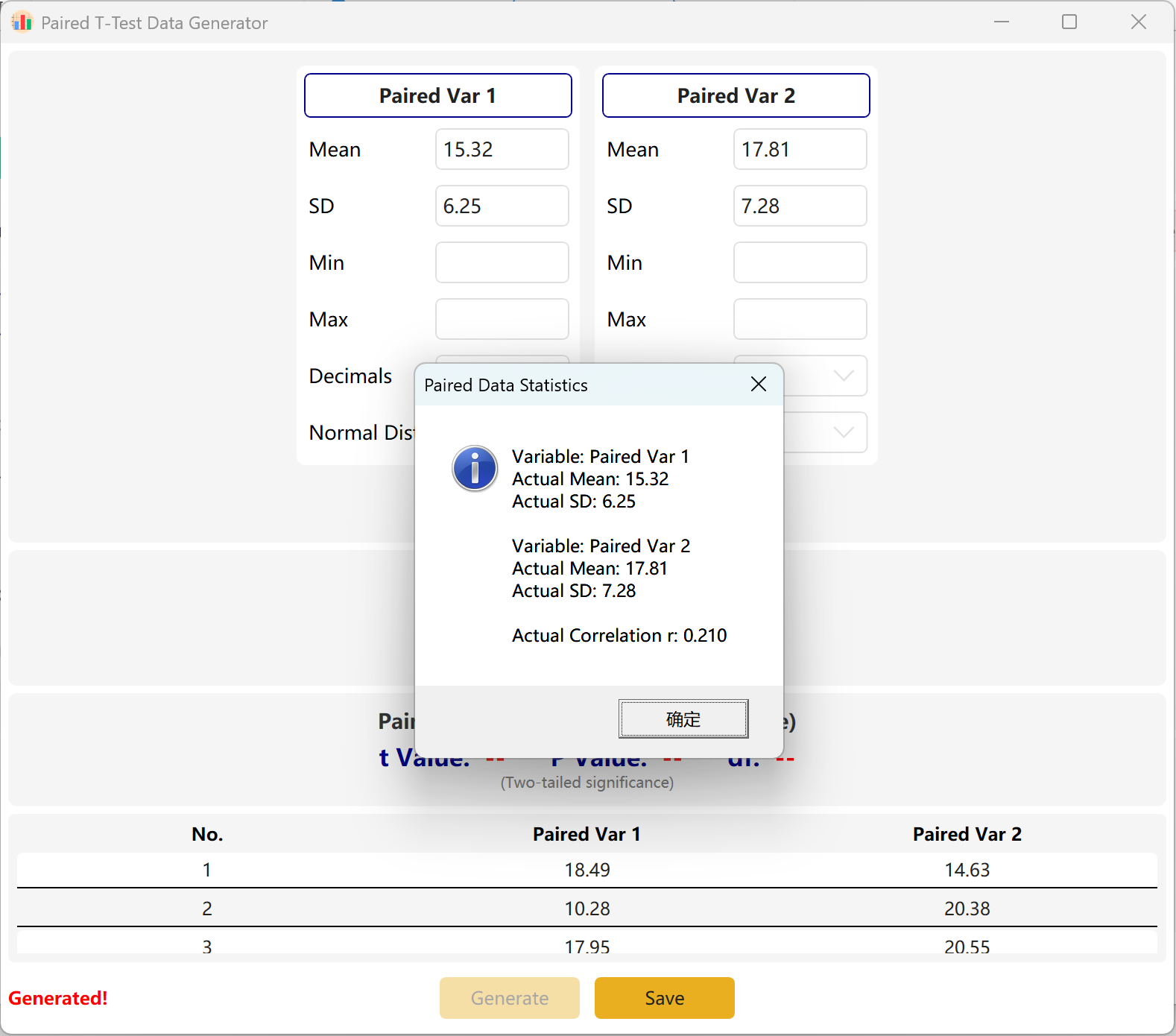
3. 配对样本 T 检验
用于对同一对象进行两次测量的纵向研究或交叉研究(例如:前测与后测比较)。该模块侧重于模拟配对观测值之间的均值差。
- 配对变量: 分别配置“配对变量1”和“配对变量2”的均值及标准差。
- 目标控制: 指定精确的配对数量及目标 P 值(如 <0.05),生成具有统计学意义的配对差值。
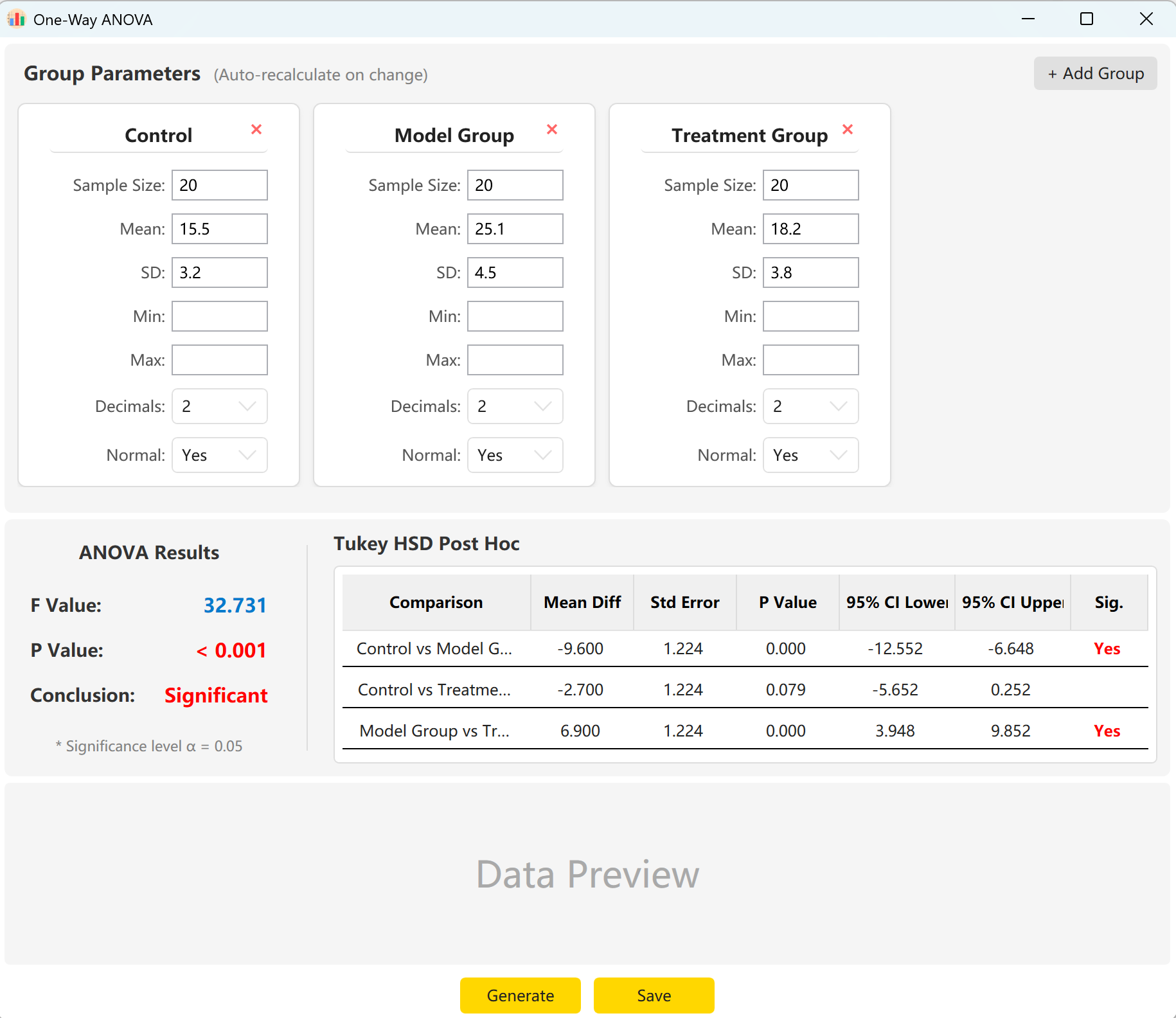
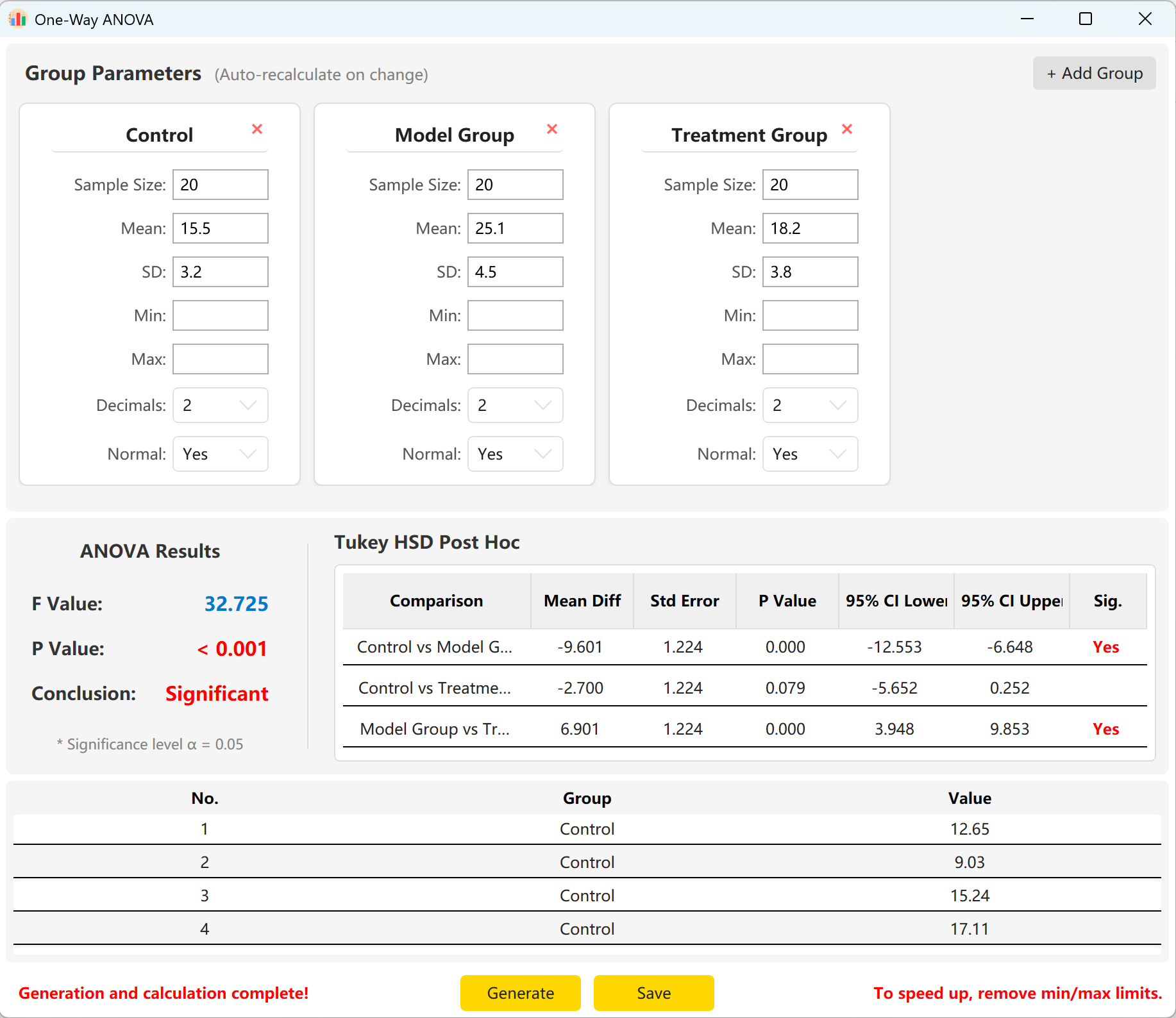
4. 单因素方差分析 (One-Way ANOVA)
适用于比较三个或更多独立组别的均值。底层算法通过控制组内方差与组间差异的比例,精确匹配目标 F 值。
- 多组别支持: 动态添加多个组别(如控制组、模型组、高剂量组)并赋予独立参数。
- 事后检验 (Post-Hoc): 自动计算 Tukey HSD 事后检验结果,详细展示配对组间的均值差、标准误和 95% 置信区间。
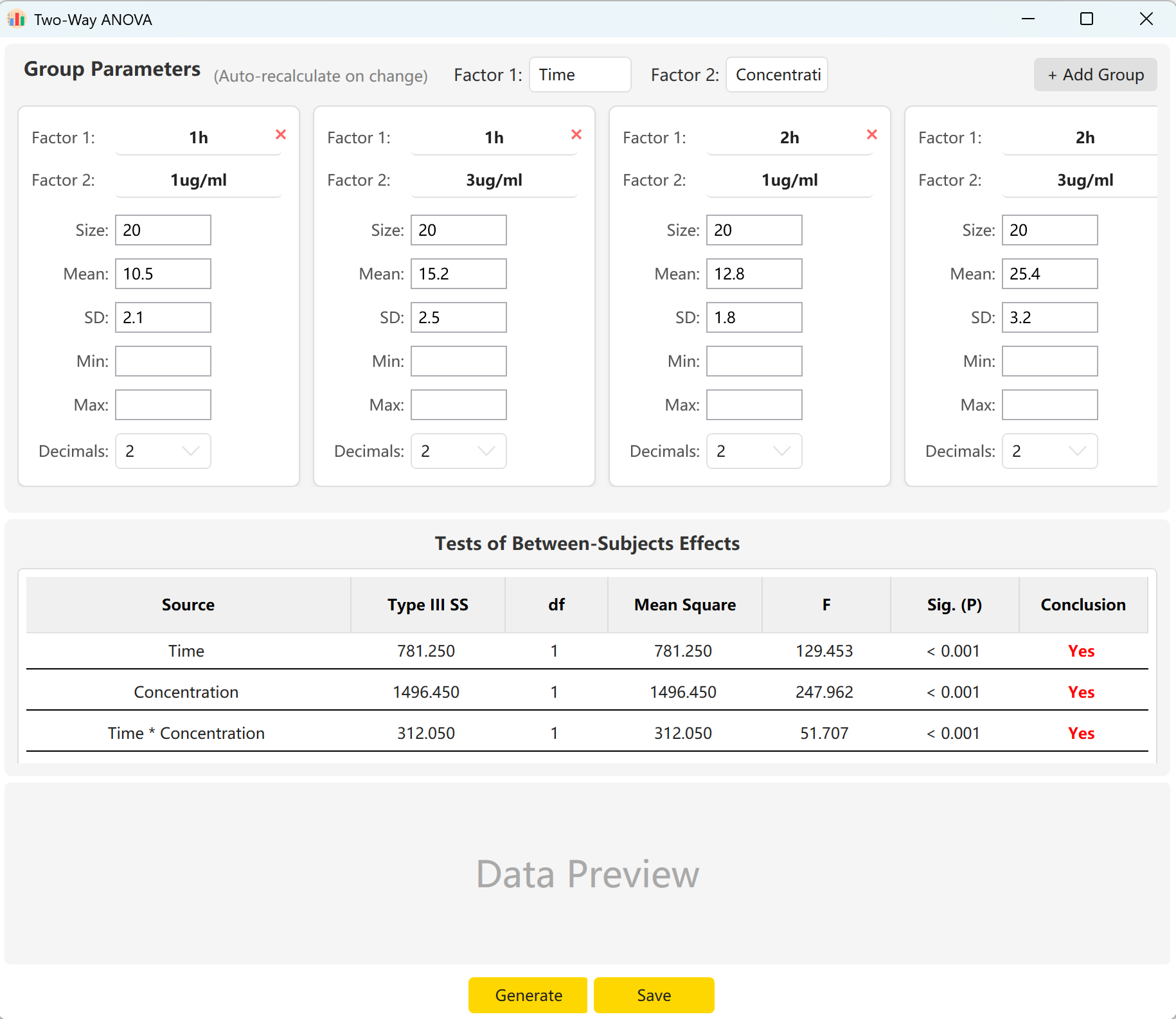
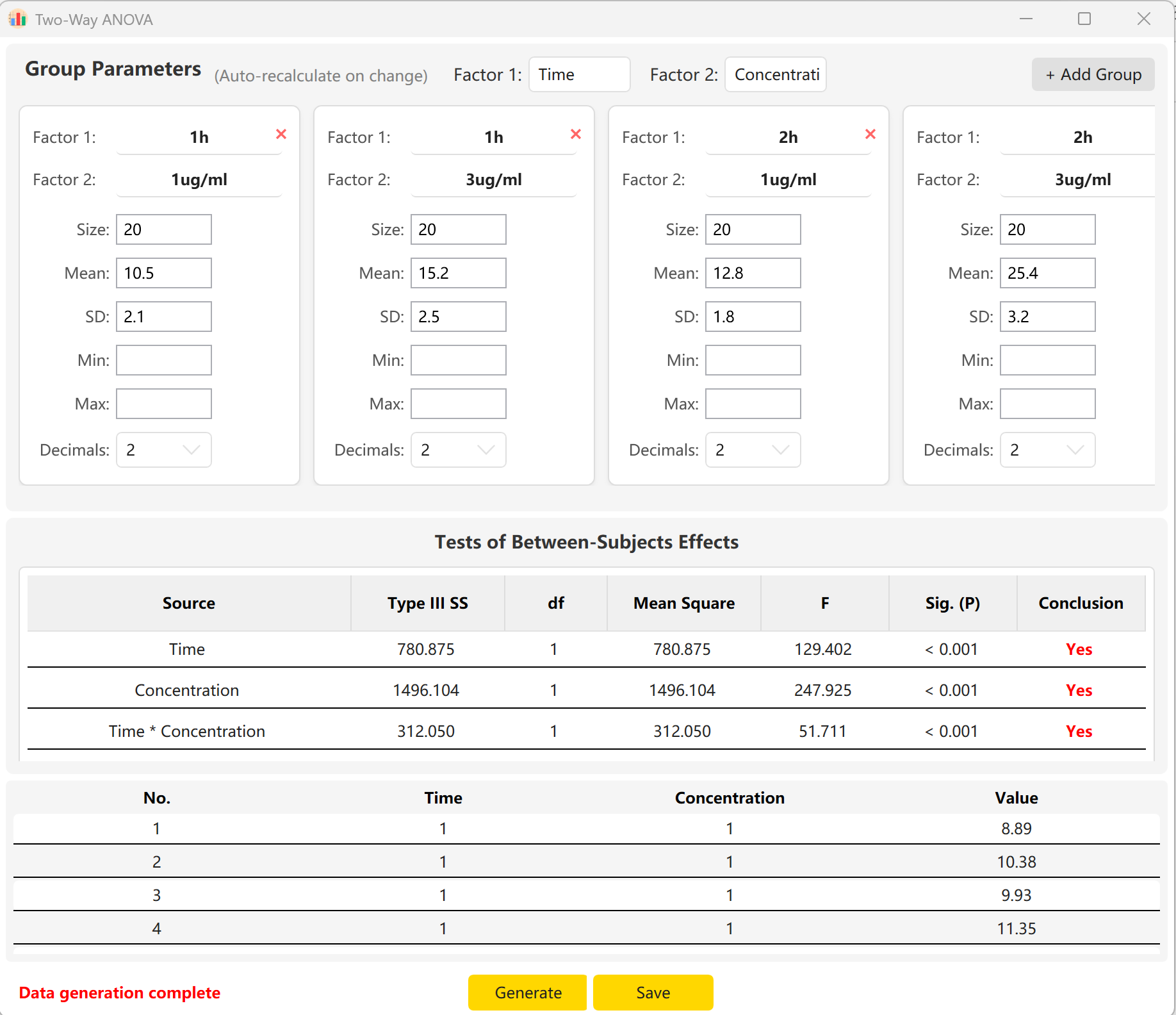
5. 双因素方差分析 (Two-Way ANOVA)
考察两个自变量(因子)对一个连续型因变量的影响。是析因设计实验中评估主效应与交互效应的必备工具。
- 因子矩阵: 设定因子 A 和因子 B,并定义交叉分组参数。
- 交互效应: 独立控制行、列及其交互项的显著性水平,以模拟复杂的科研假设。
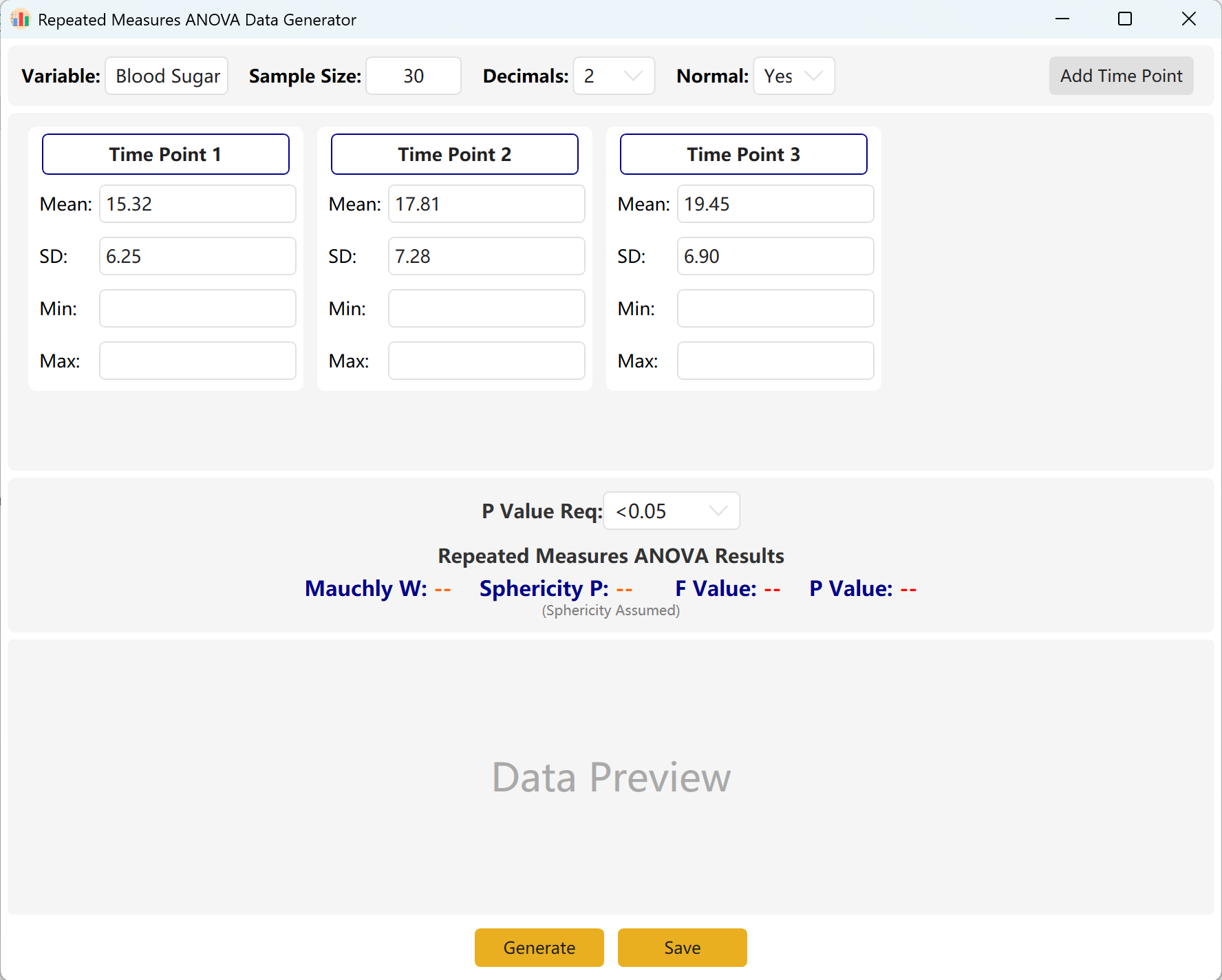
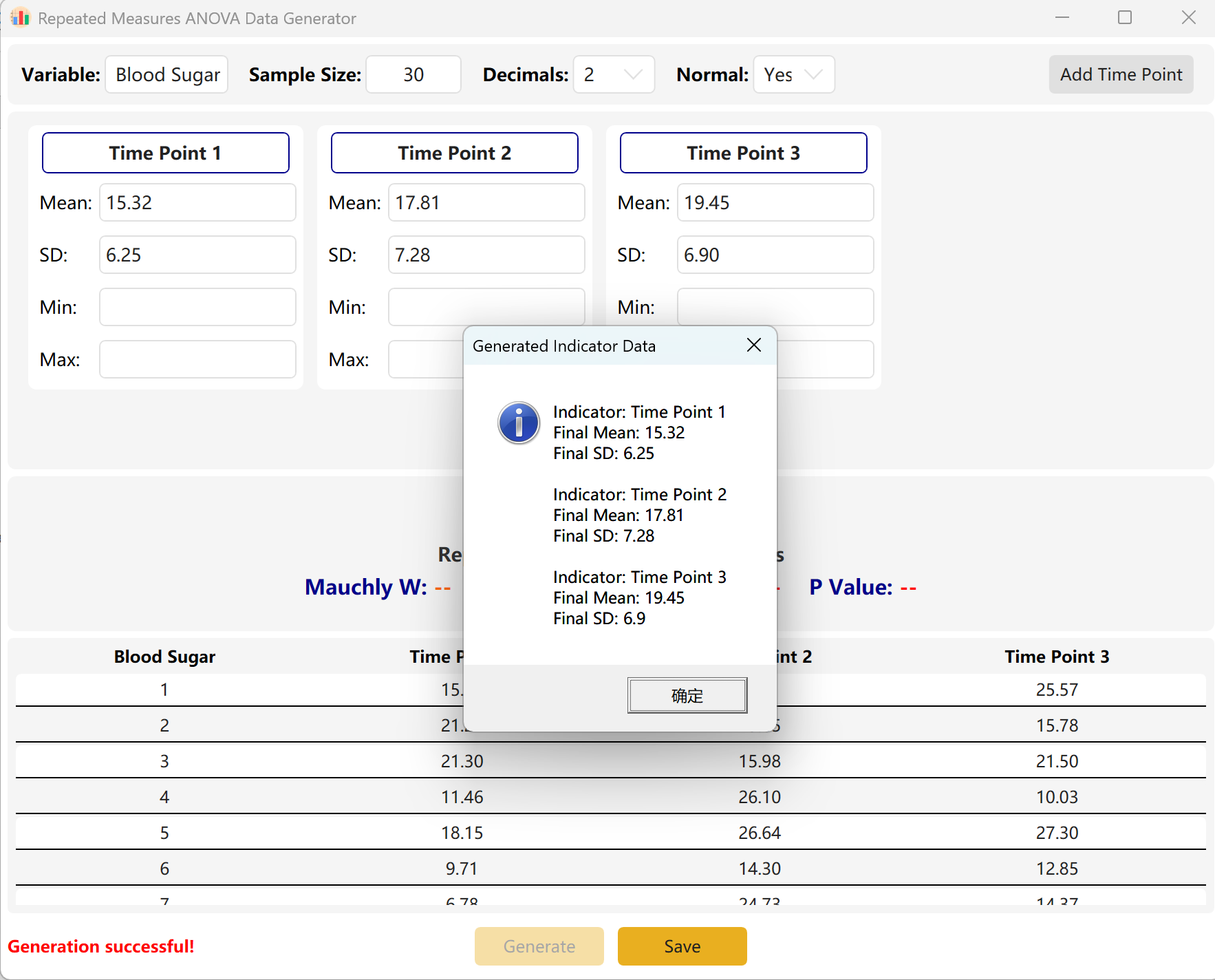
6. 重复测量方差分析
配对 T 检验在三个及以上时间节点上的延伸拓展。极其适合长期随访的纵向研究(例如:基线、第1个月、第3个月的指标追踪)。
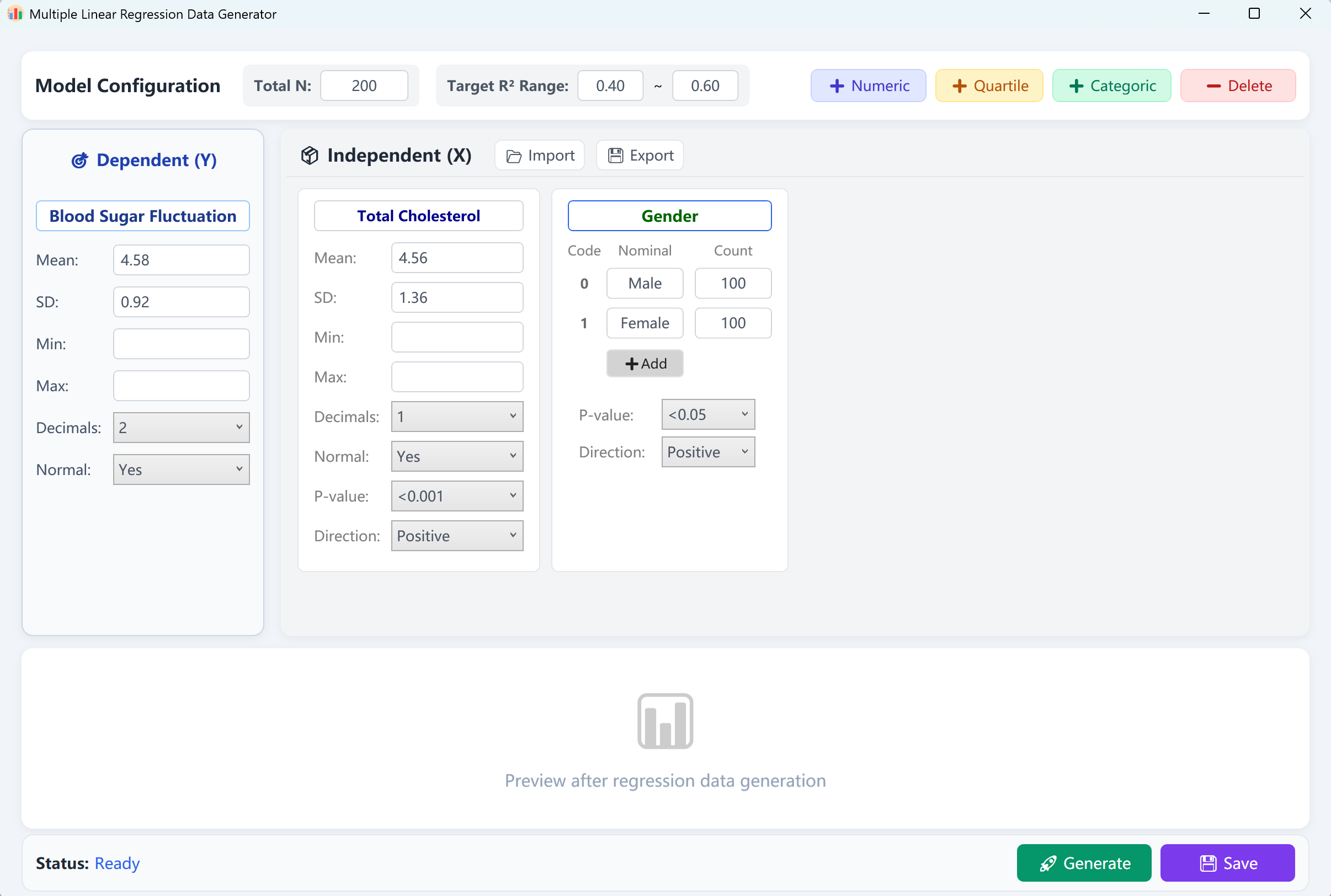
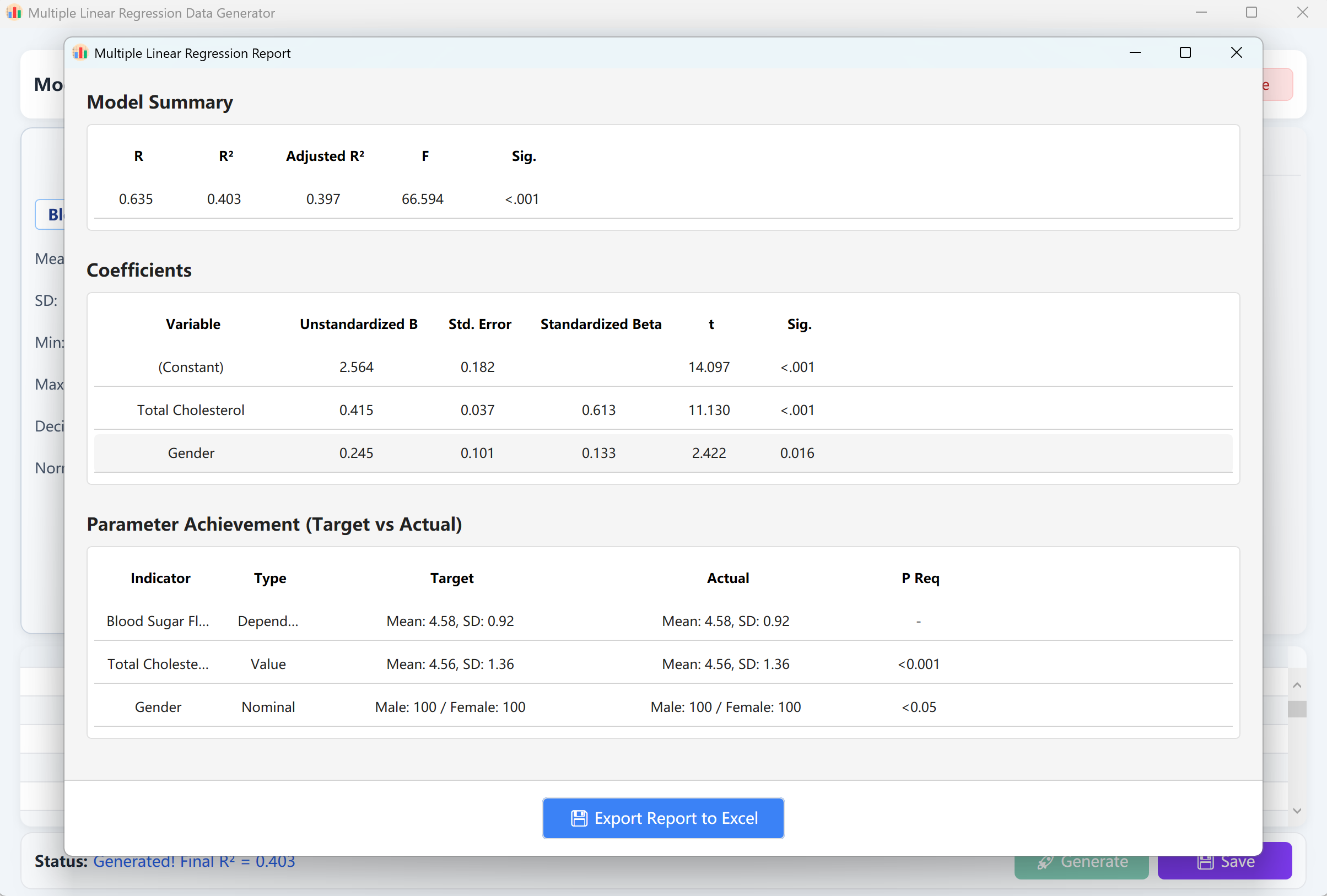
7. 多元线性回归
核心预测模型工具。它模拟一个受多个自变量 (X) 影响的连续型因变量 (Y),自变量支持连续、分类或有序类型。
- R² 控制范围: 定义整体模型的解释力区间(例如 0.40 ~ 0.60)。
- 变量相关性: 指定个体预测变量的影响方向(正向/负向)及期望的 P 值阈值。
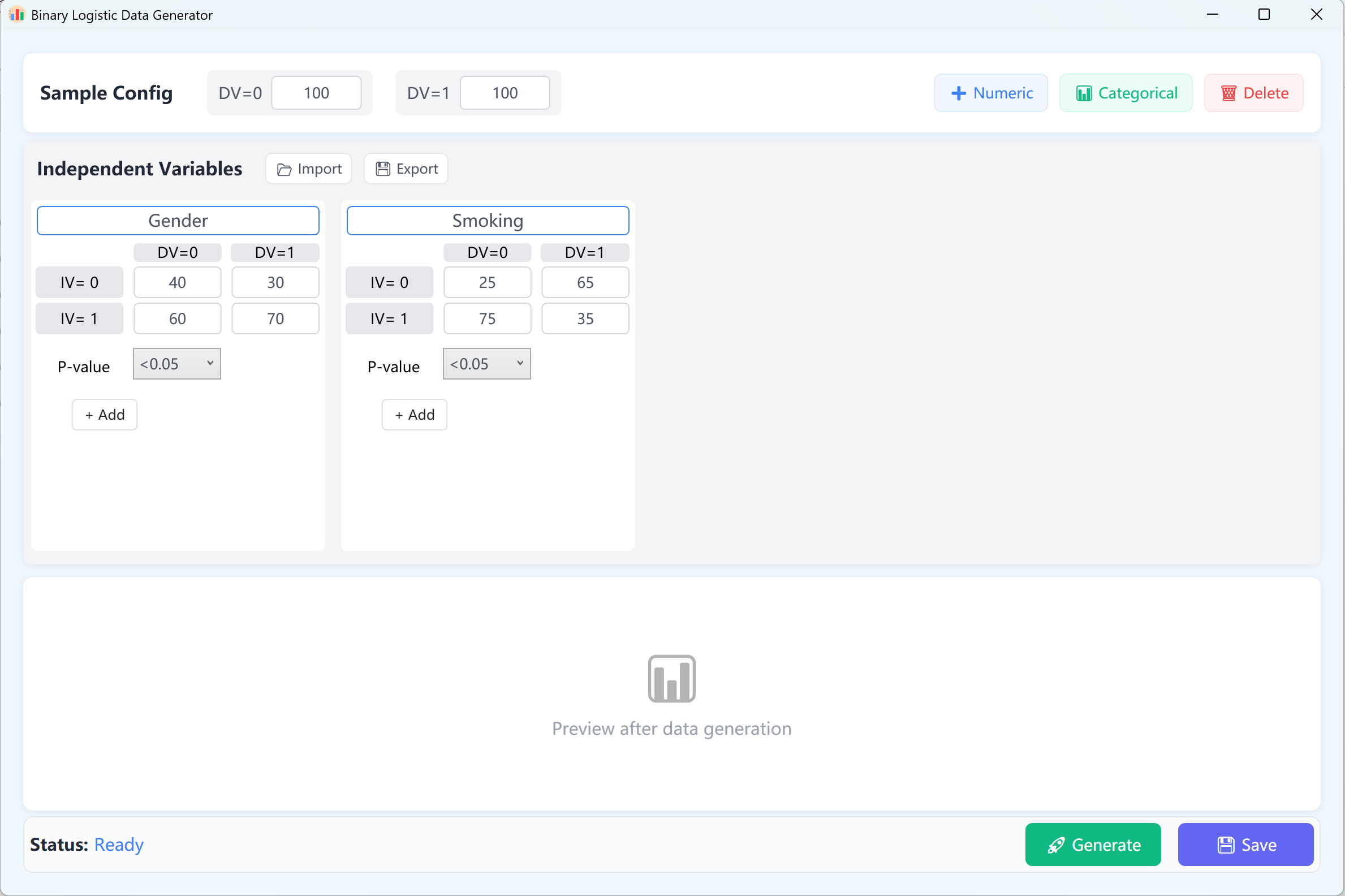
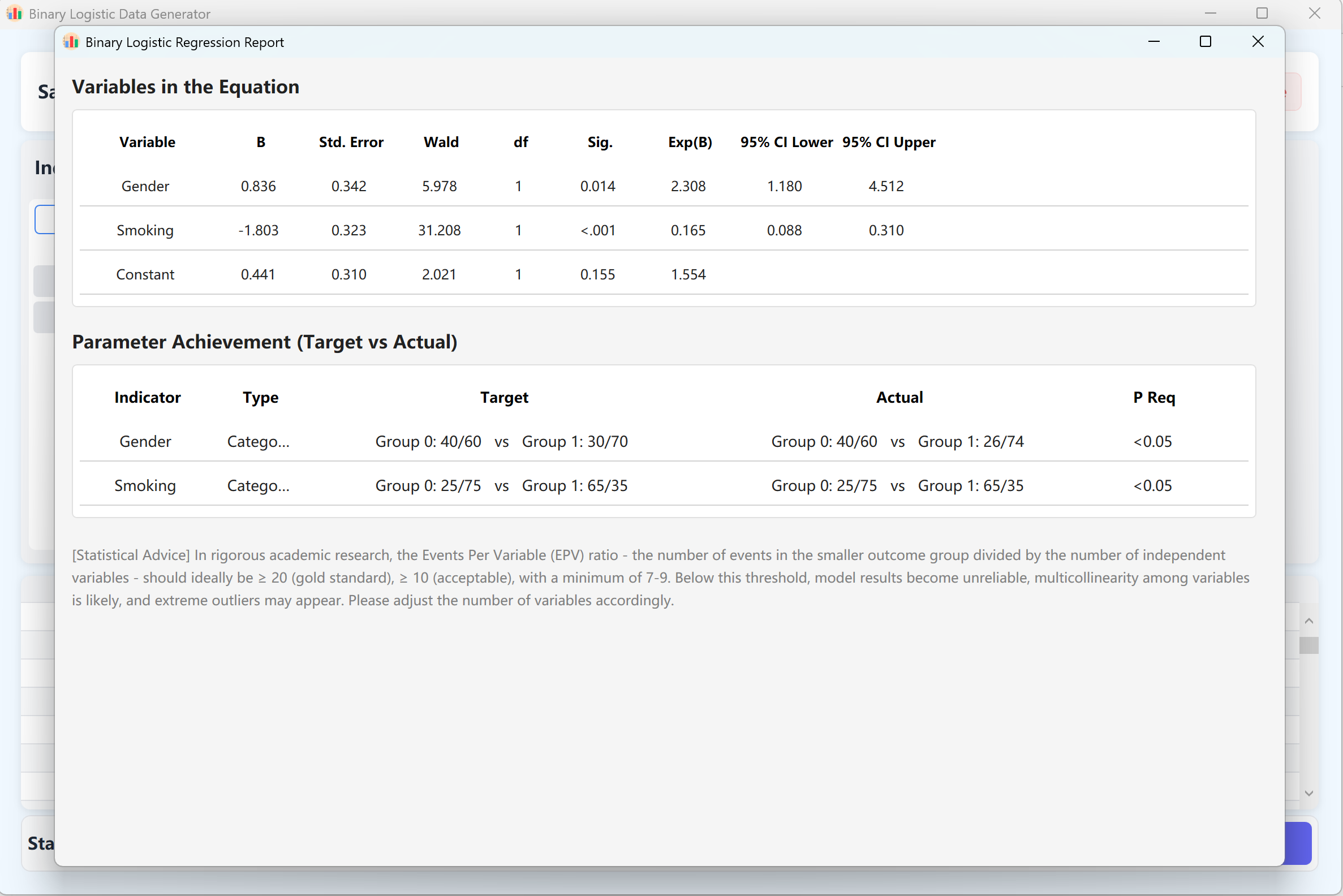
8. 二元 Logistic 回归
处理结局变量为二分类(如发病/未发病,存活/死亡)分类问题的核心工具。在流行病学中广泛用于危险因素筛查与识别。
- 交叉频率矩阵: 精确配置分类预测变量(如吸烟史、性别)在不同结局状态下的分布频率。
- 显著性与 OR 值: 锁定 P 值以确保生成的虚拟数据精准体现出研究假设所期望的比值比 (Odds Ratio)。
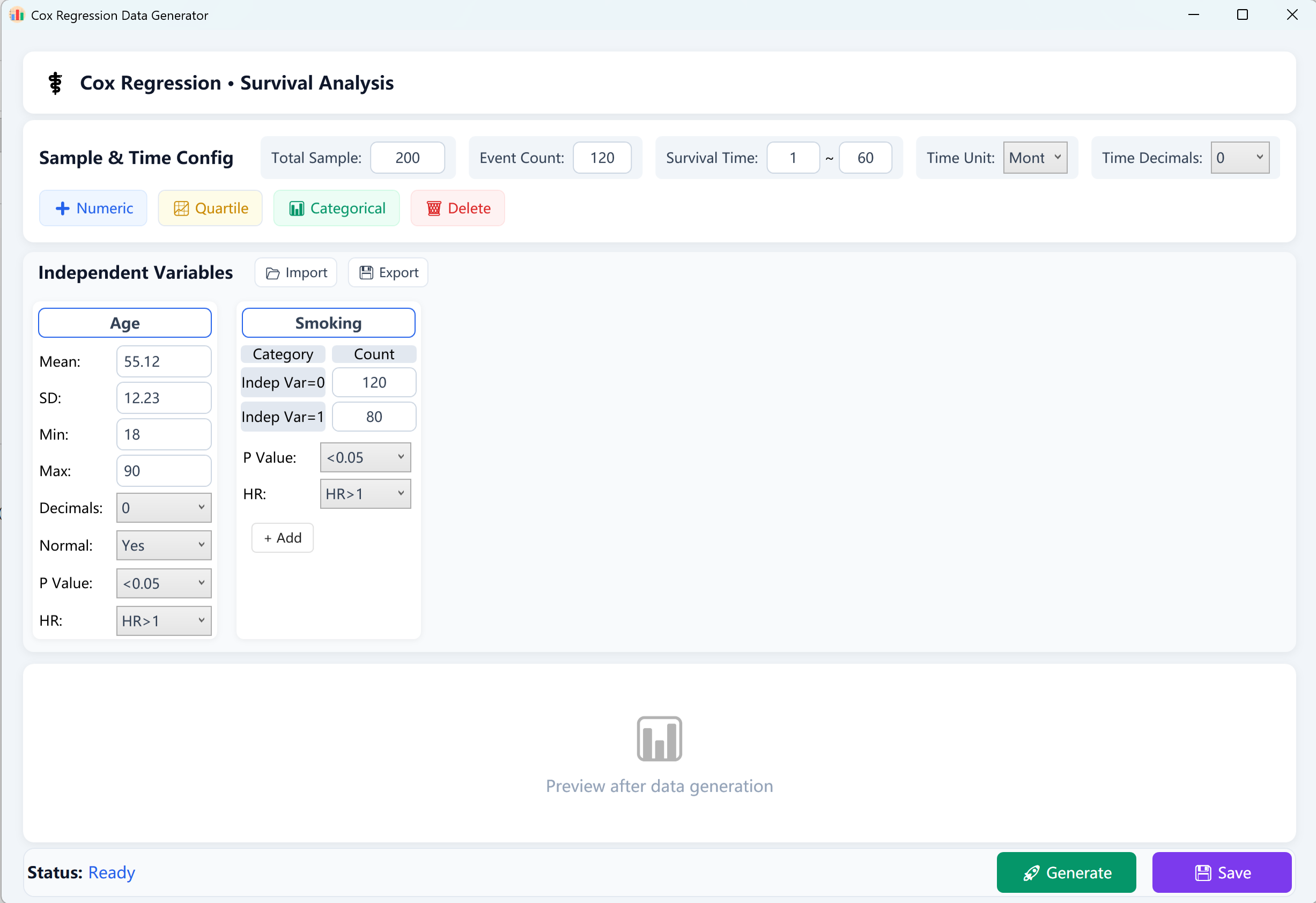
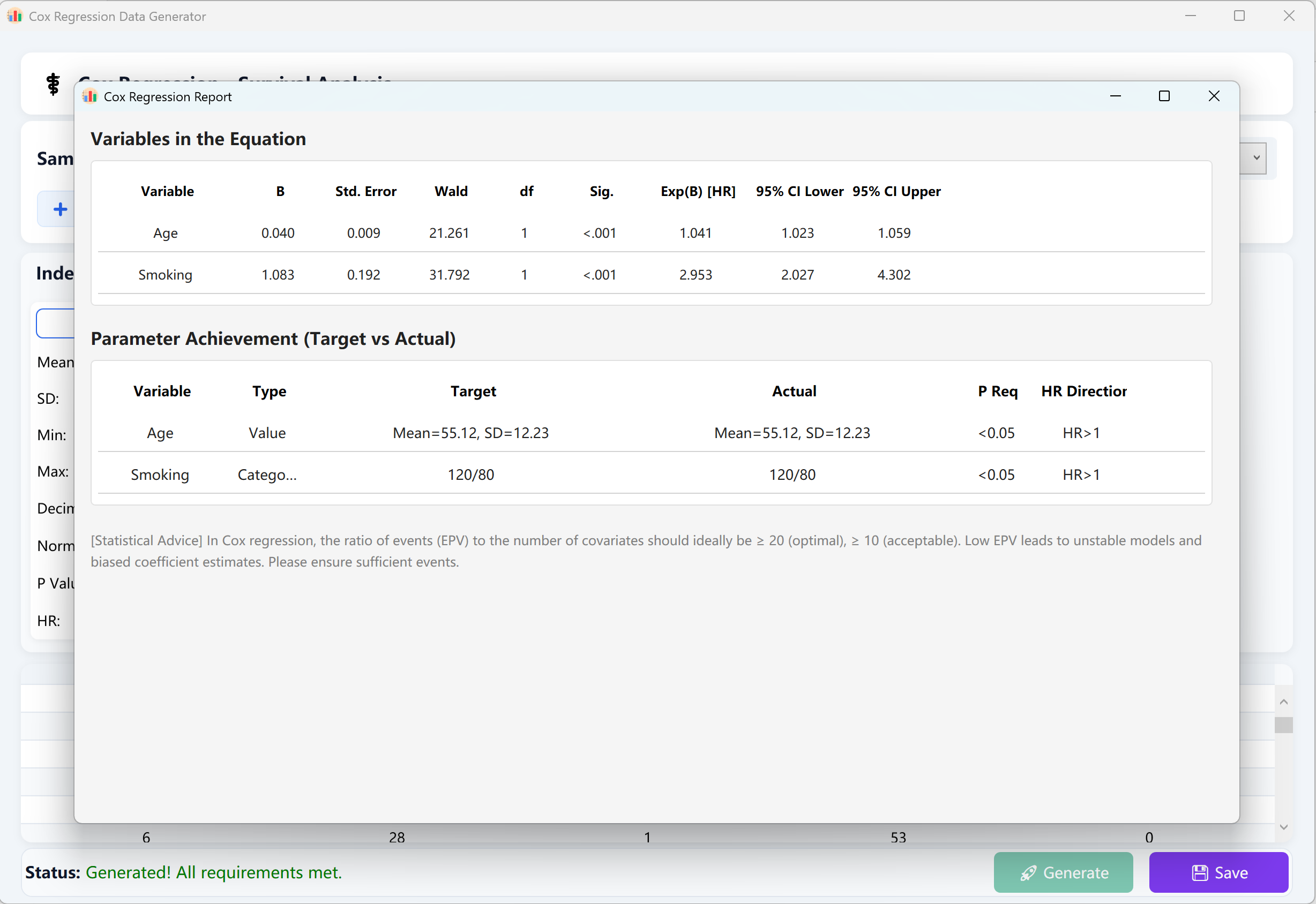
9. Cox 比例风险回归 (生存分析)
生存分析领域的“金标准”。在模拟至事件发生时间 (Time-to-Event) 数据的同时纳入右删失考量,帮助研究人员评估各类协变量对生存时间的复合影响。
- 时间与事件配置: 定义总样本量、实际事件发生数(死亡/失败案例)以及全局生存跨度(如 1~60 个月)。
- 风险比 (HR): 控制各个自变量是增加风险 (HR > 1) 还是作为保护因素降低风险 (HR < 1)。
10. 非参数检验 (2 个独立样本)
当数据严重偏态或不满足正态分布假设时的理想替代方案(如 Mann-Whitney U 检验)。通过秩次逻辑有效评估两组间的分布中位数差异。
1.png)
2.png)
11. 非参数检验 (K 个独立样本)
作为 Kruskal-Wallis H 检验的对应模块。为三个或更多独立组别快速生成偏态的连续变量或有序分类数据。
1.png)
2.png)
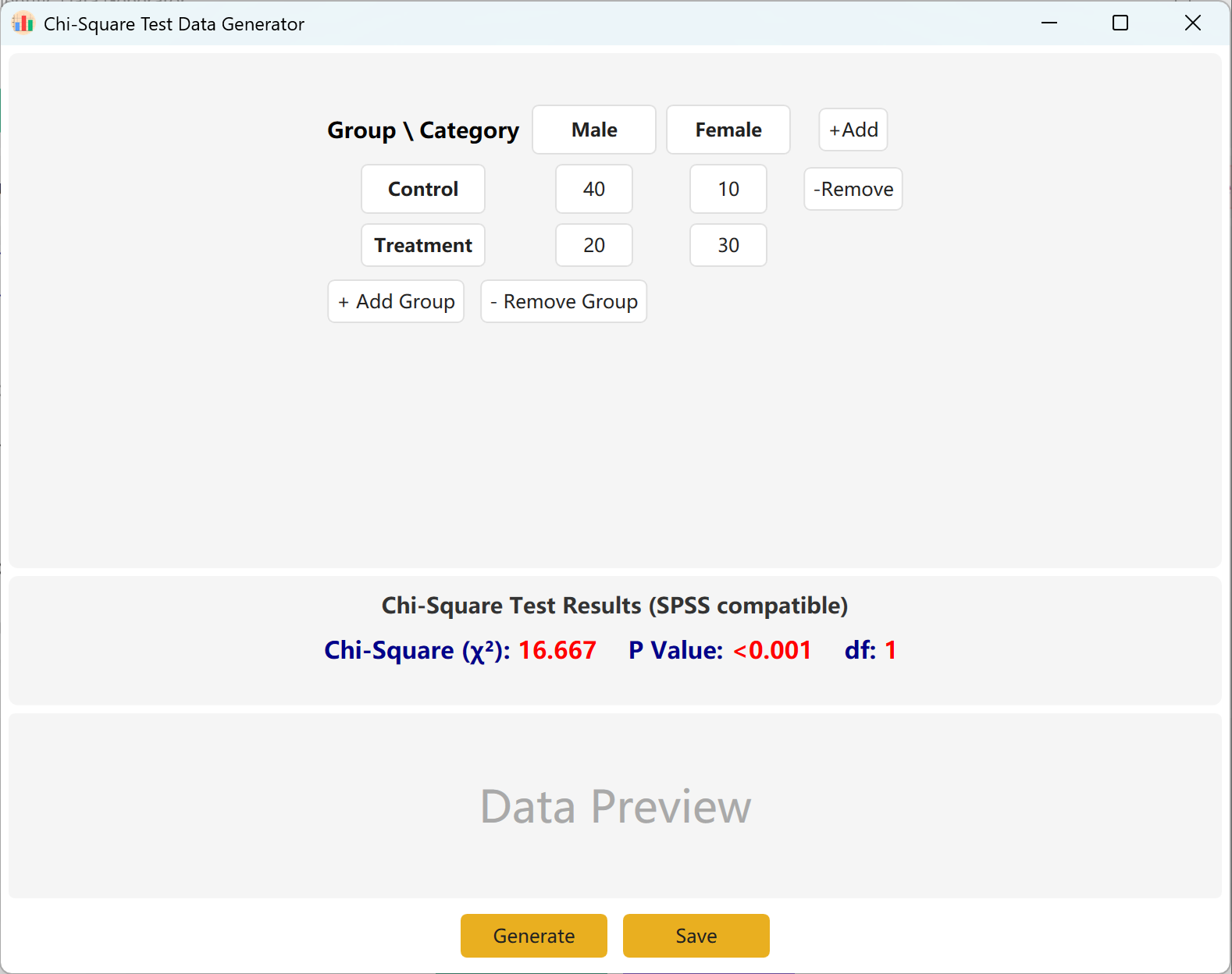
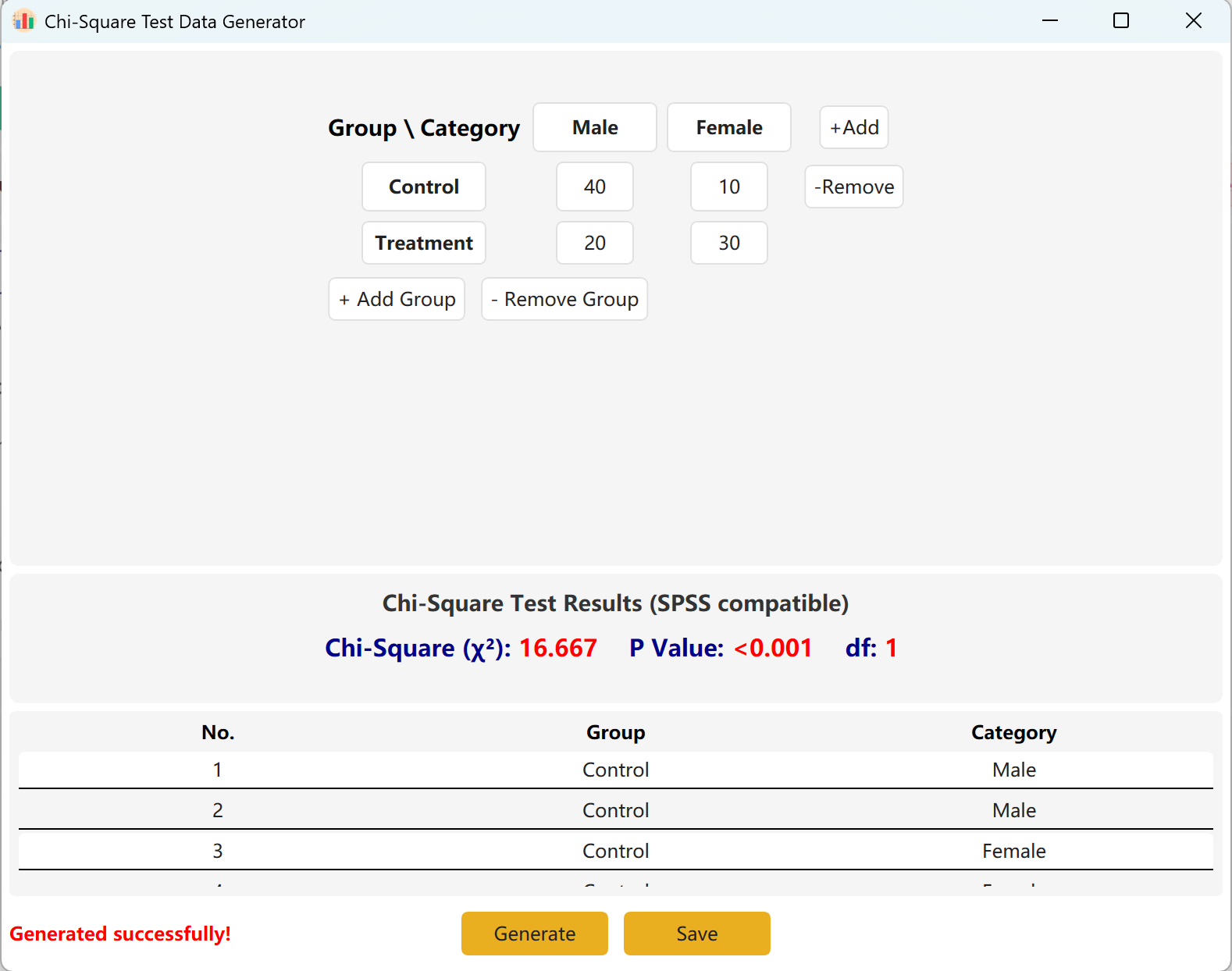
12. 卡方检验 (Chi-Square)
判断两个离散型分类变量之间是否存在显著关联。是人口统计学交叉表(Cross-tabulation)分析和频率研究的最基础工具。
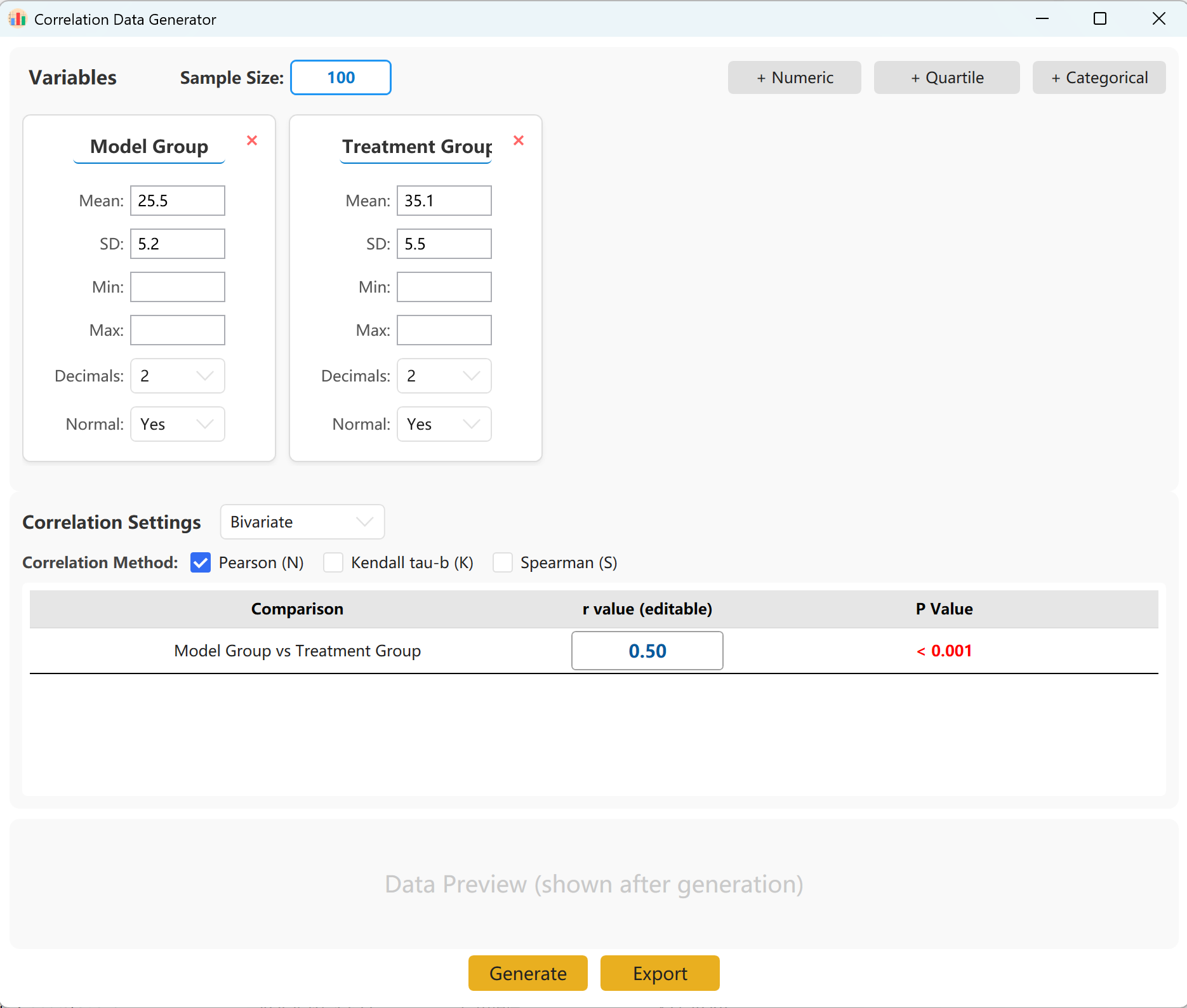
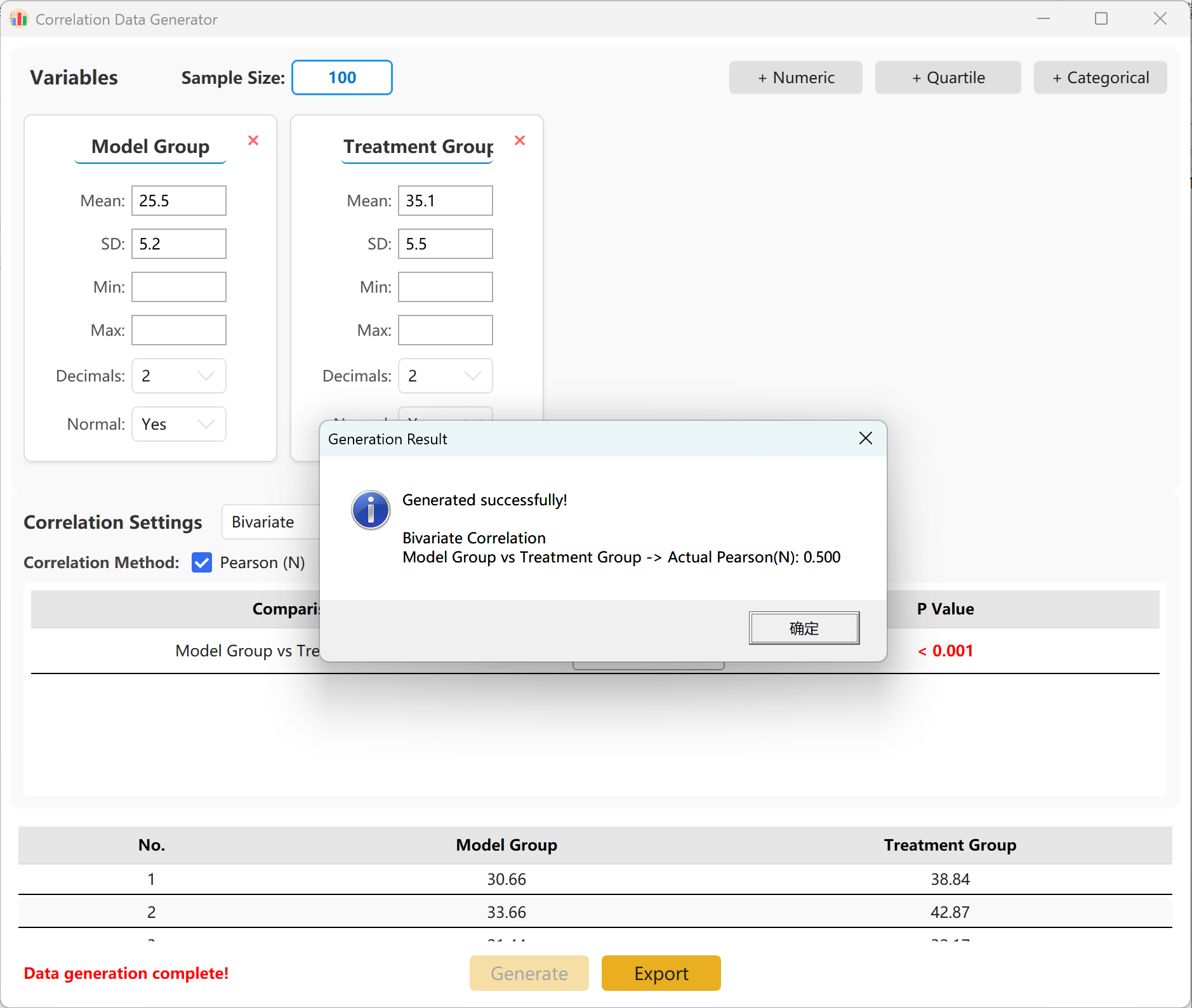
13. 相关性分析 (Correlation)
通过强制设定目标相关系数(r 值)和双侧显著性,模拟双变量之间的线性或单调关系(支持 Pearson 及 Spearman 算法)。
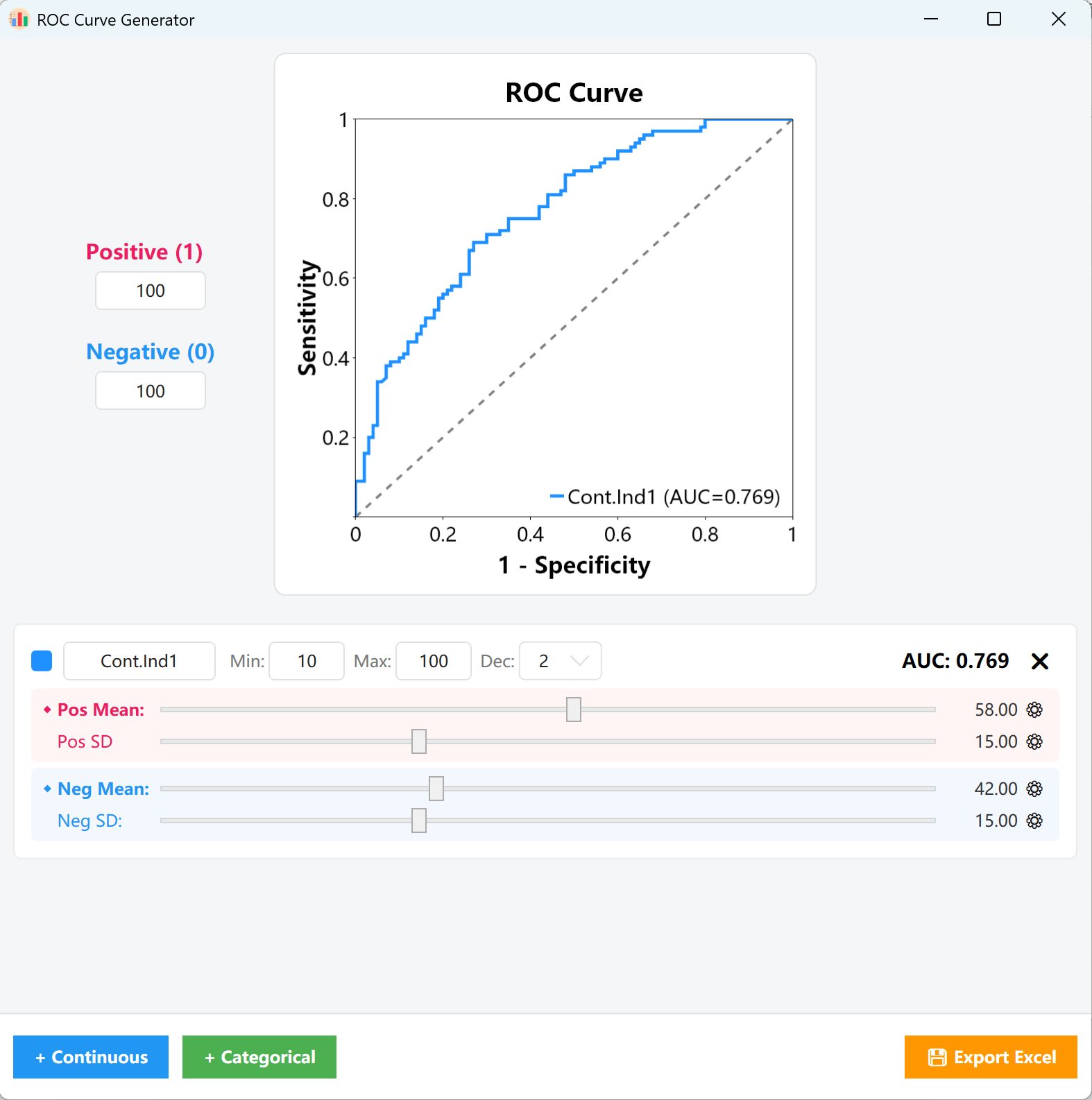
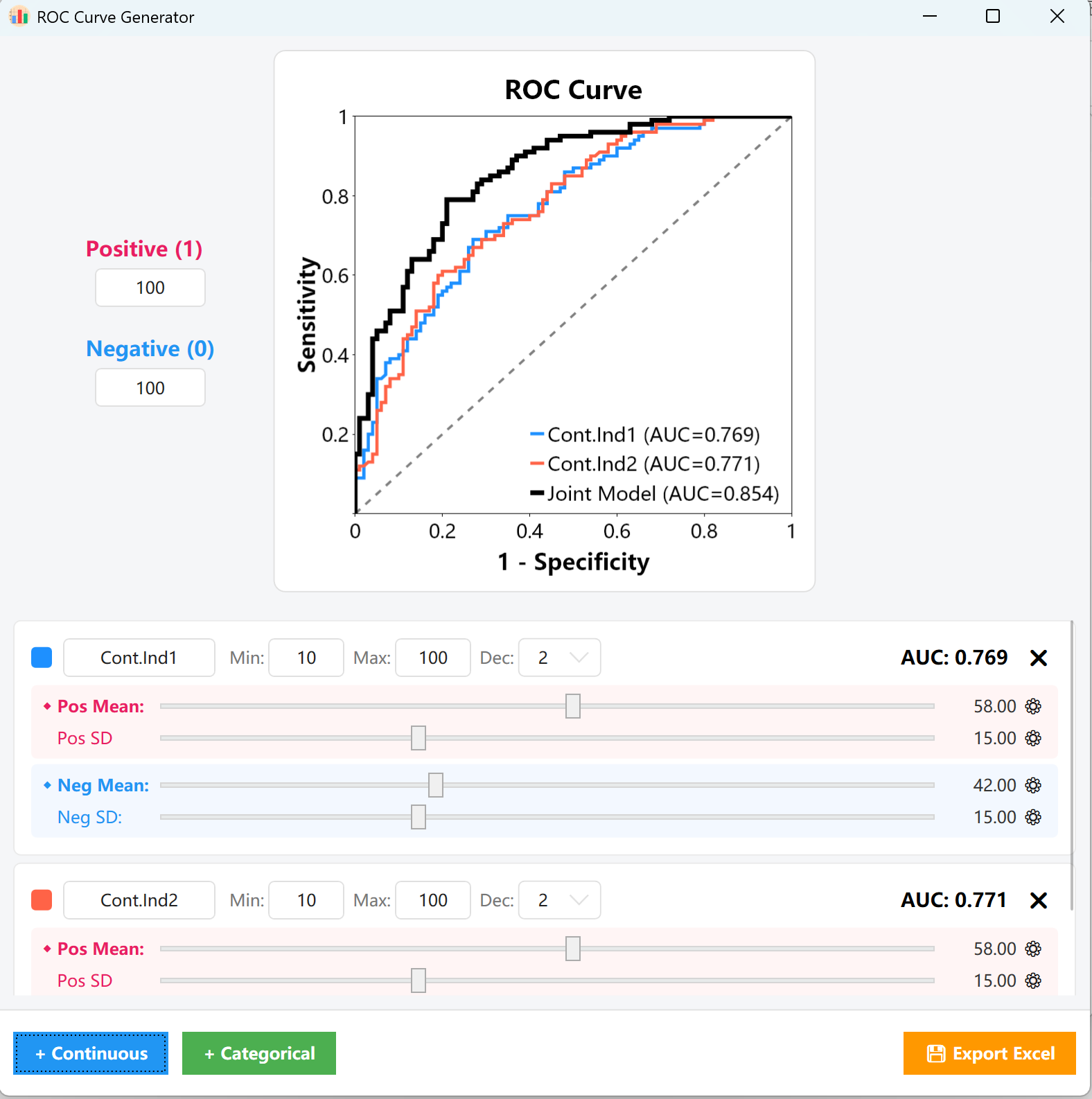
14. ROC 曲线分析
用于评估连续型检验变量在区分两种状态(如阳性 vs. 阴性诊断)时的诊断效能与准确度。
- 可视化反馈: 实时绘制灵敏度 (Sensitivity) 与 1-特异度 (1-Specificity) 的曲线。
- AUC 精确控制: 直接拖拽调节阳性组与阴性组的均值和标准差,从而动态命中目标曲线下面积 (AUC),例如 0.769。