Documentación y Guía del Usuario
Bienvenido a la documentación oficial de DataSynth Pro. Este manual exhaustivo le guía paso a paso en la configuración de los parámetros de nuestros diferentes módulos estadísticos para sintetizar conjuntos de datos robustos, científicamente válidos y estadísticamente viables, todo de forma totalmente offline.
1. Generación simultánea de varios indicadores
1.1 Requisitos previos y lanzamiento
Haga doble clic en el archivo ejecutable para iniciar la aplicación. El software requiere la plataforma de ejecución Microsoft .NET 8.0 Desktop Runtime. Si no está instalada en su ordenador, siga las instrucciones para descargarla e instalarla, y luego reinicie el programa.
Aviso de seguridad: Si su software antivirus señala el ejecutable como un falso positivo, añada la aplicación a la lista de exclusiones o lista blanca local para asegurar un funcionamiento sin interrupciones.
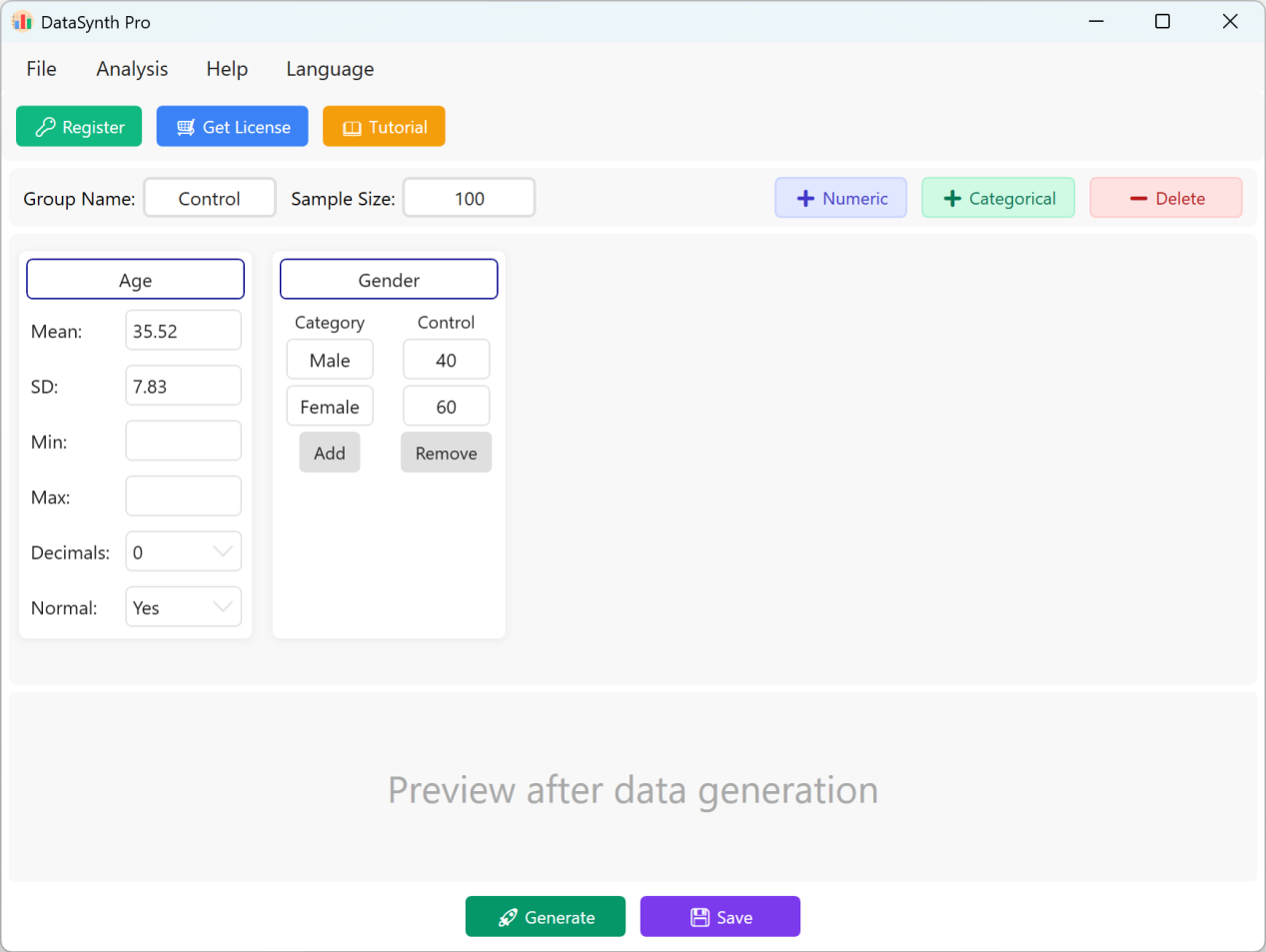
Figure 1.1 : Interfaz de Usuario / Operaciones (Interfaz Principal)
1.2 Configuración de parámetros
Por defecto, la aplicación rellena previamente dos variables continuas, "Age" (Edad) y "Gender" (Género), que sirven como referencias rápidas. La designación del grupo está definida por defecto como "Control Group" (Grupo de Control) y el tamaño de la muestra se fija en "100" casos. Si su estudio requiere varios grupos, puede generar y exportar sucesivamente el conjunto de datos de cada grupo actualizando los parámetros en cada ejecución.
- Ajouter des variables numériques continues : Para añadir una nueva variable cuantitativa, haga clic en el botón + Numeric. A continuación, puede especificar el nombre del indicador (ej. "Body Mass Index" o "BMI"), la Media, la Desviación Estándar y el Número de decimales. Los campos de límite mínimo y máximo son opcionales y pueden permanecer vacíos si no tiene restricciones de valores específicas.
- Paramètres de distribution des données : Por defecto, las medidas numéricas generadas siguen una distribución normal. Si necesita datos que no se distribuyan normalmente, simplemente desactive la opción Normal Distribution seleccionando No.
Ajuste de distribución: Una distribución normal se basa en un intervalo de varianza natural. Restringir de manera demasiado estricta los límites mínimo y máximo truncará la curva normal y puede generar valores no distribuidos normalmente. Si esto sucede, intente ampliar estos límites o elimine por completo los valores mín/máx.
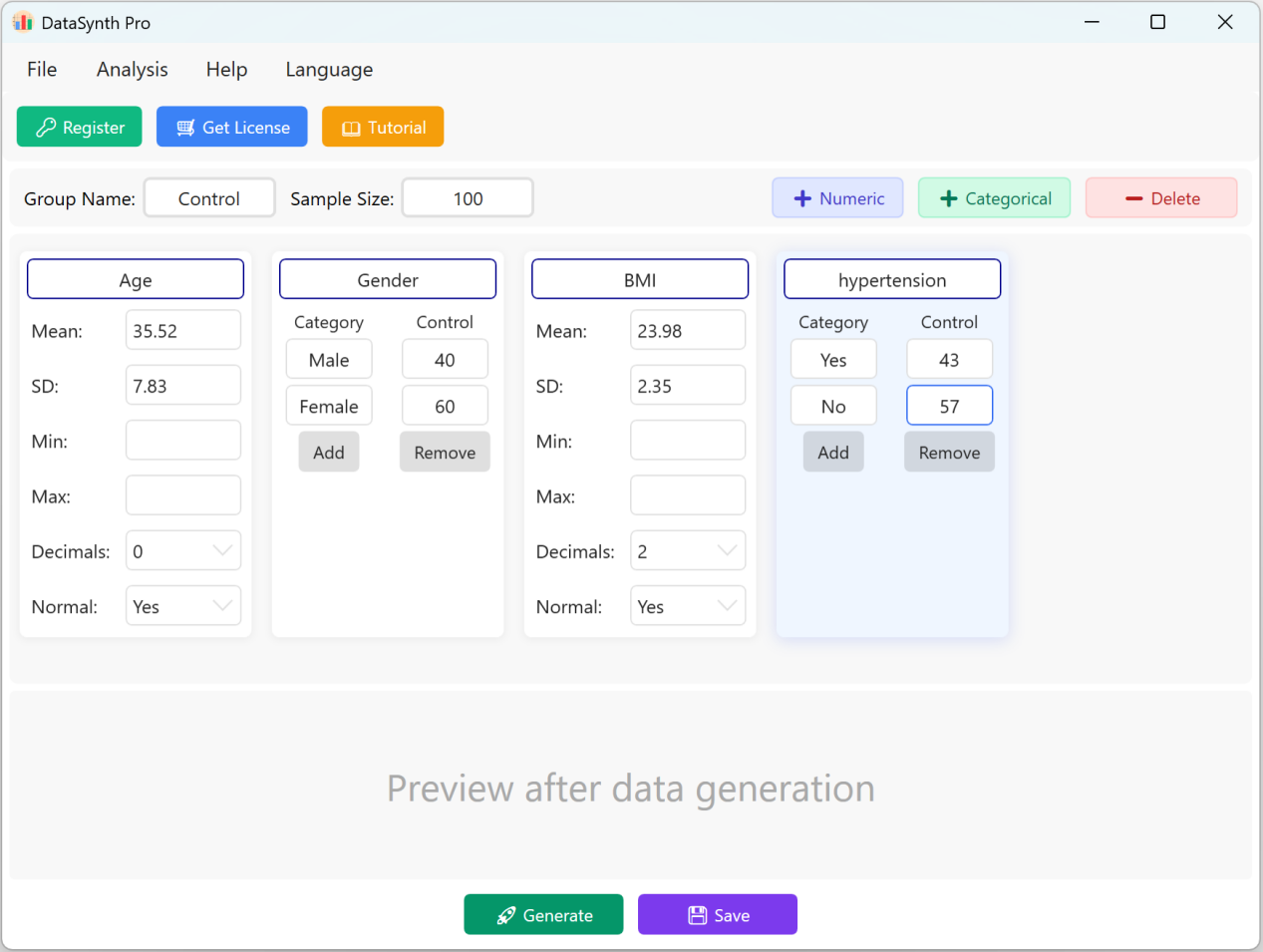
Figure 1.2 : Operaciones de la interfaz de usuario para añadir variables
1.3 Añadir variables categóricas
Haga clic en el botón + Categorical para añadir variables cualitativas (ej. "Hypertension"). Puede introducir los nombres de las categorías y sus distribuciones o proporciones objetivo correspondientes. La suma de las proporciones categóricas se ajustará automáticamente a la escala del tamaño de muestra configurado.
1.4 Ejecución de la generación
Haga clic en el botón Generate para sintetizar el número de registros solicitado. Una vez completado el cálculo, se mostrará una ventana de resumen de estadísticas descriptivas para permitirle verificar si los valores reales generados corresponden a los parámetros definidos.
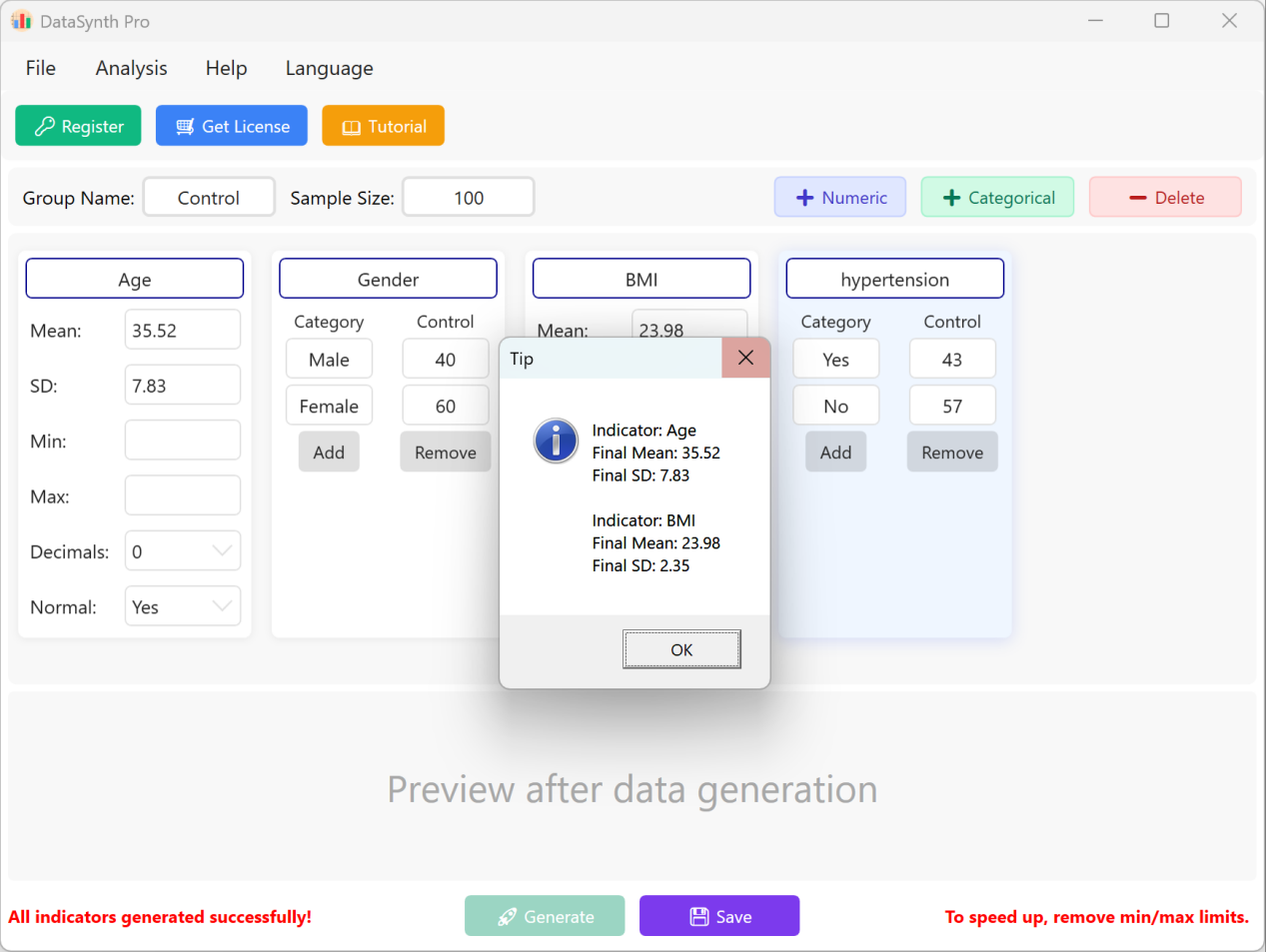
Figure 1.3 : Interfaz de usuario / Operaciones para ejecutar la generación
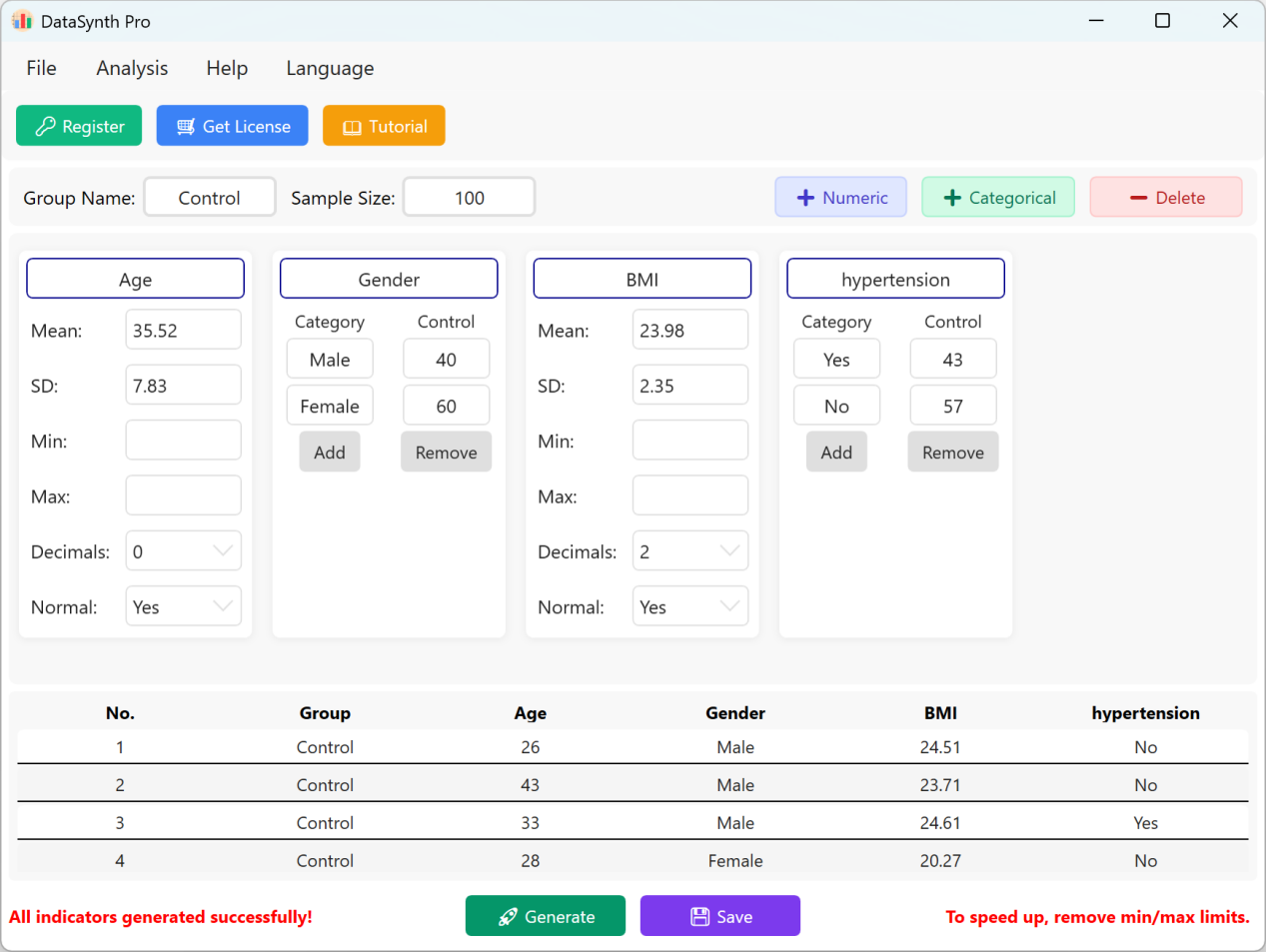
Figure 1.4 : Interfaz de usuario / Operaciones para mostrar los datos
1.5 Exportación y verificación
Haga clic en el botón Save para exportar el conjunto de datos generado como un archivo Excel estándar. Si abre el libro exportado y calcula las estadísticas descriptivas para la variable "Age" (redondeada a dos decimales) utilizando las fórmulas estándar de Excel, la media y la desviación estándar reales corresponderán perfectamente a sus parámetros iniciales.
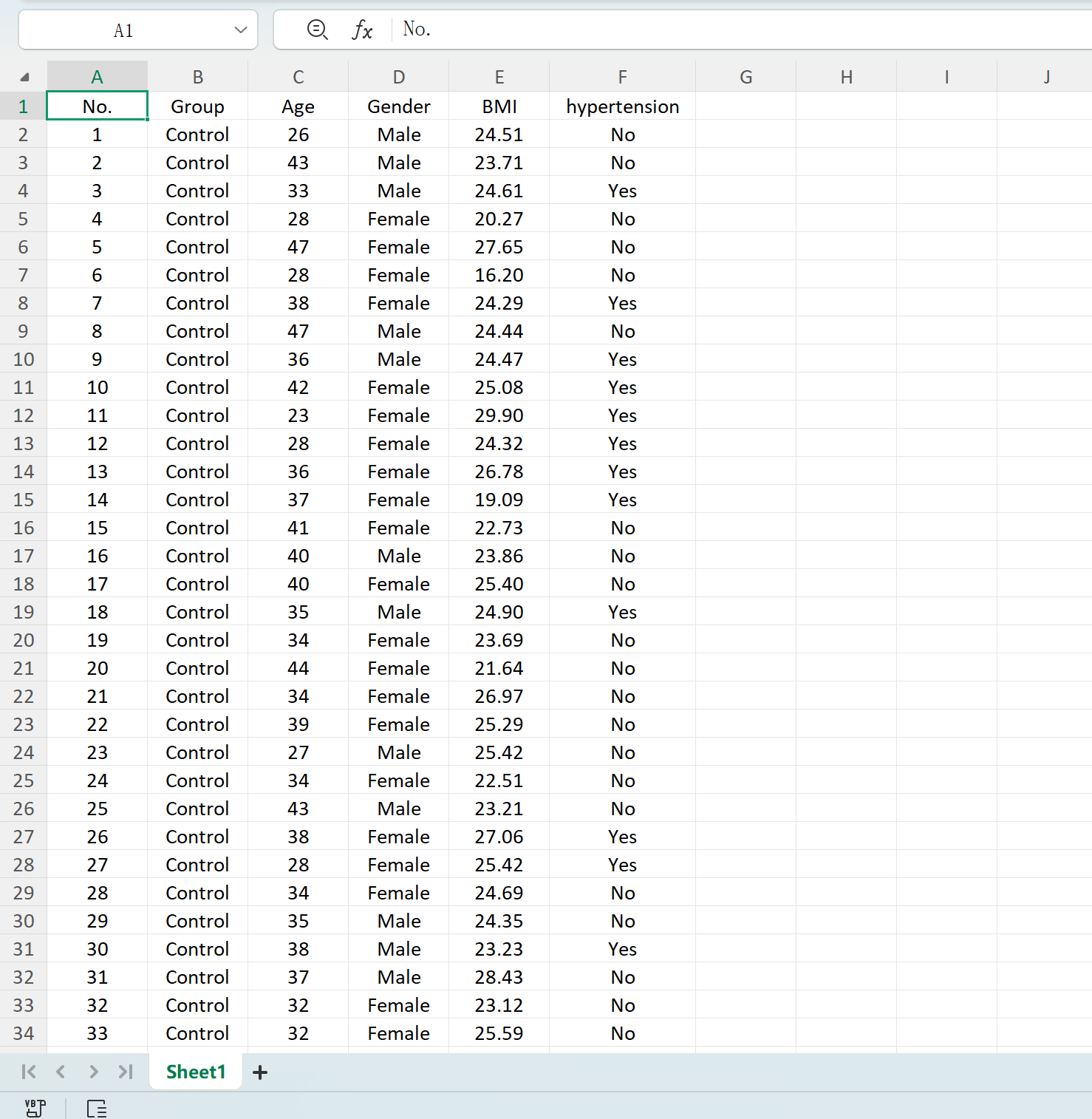
Figure 1.5 : Exportación de tablas generadas a Excel
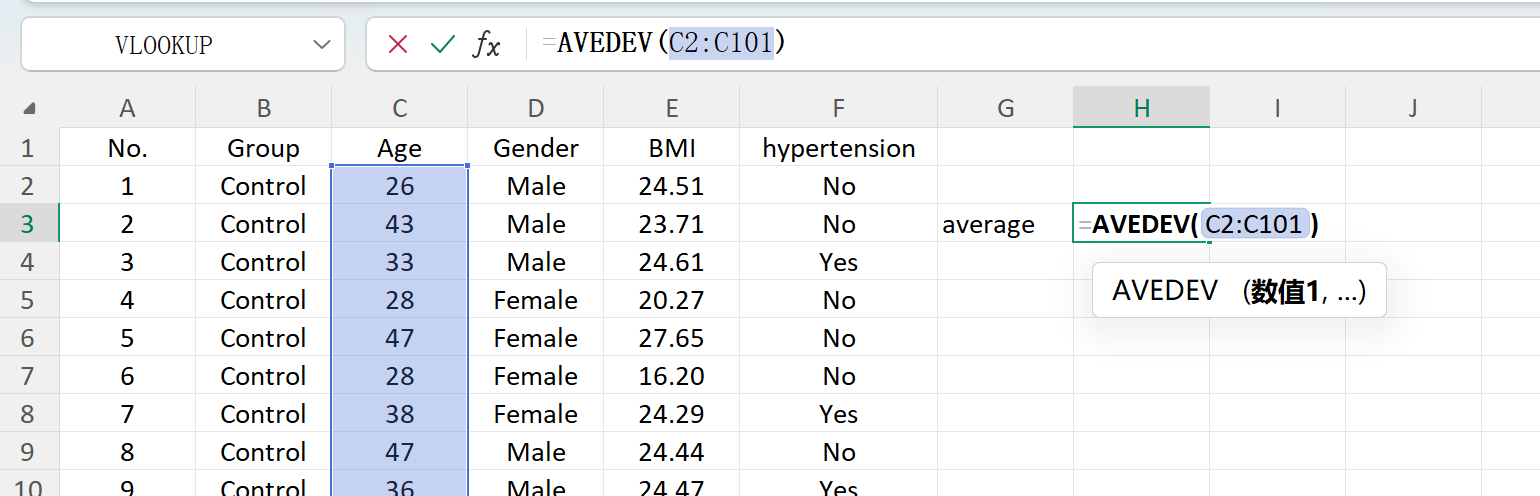
Figure 1.6 : Cálculo de la media en Excel
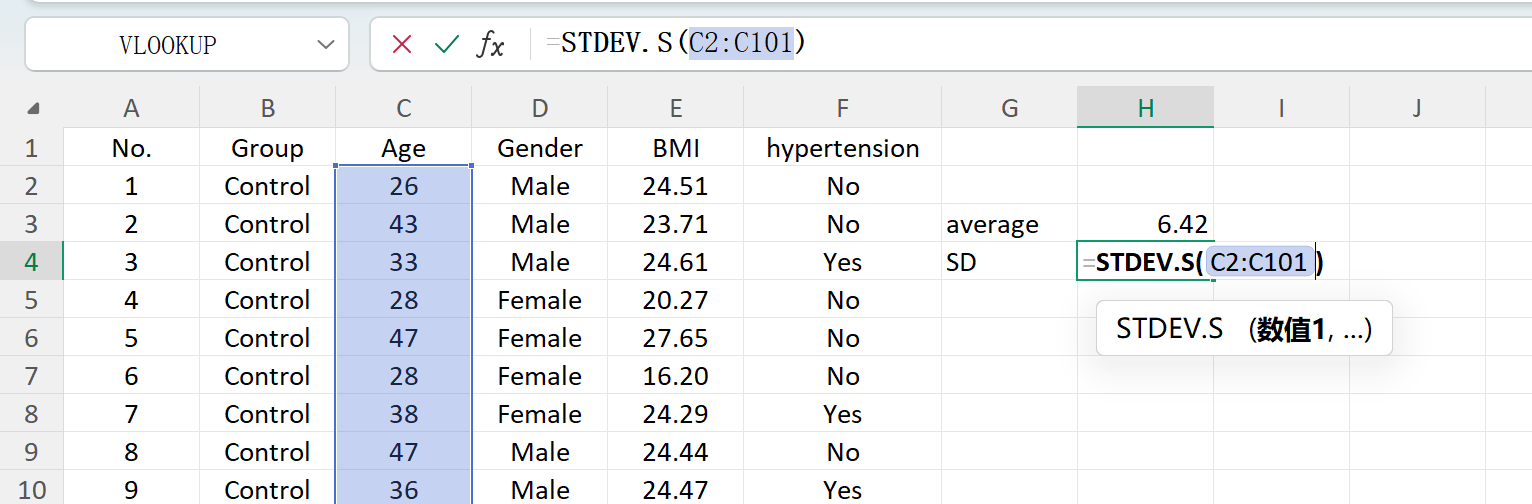
Figure 1.7 : Cálculo de la desviación estándar en Excel
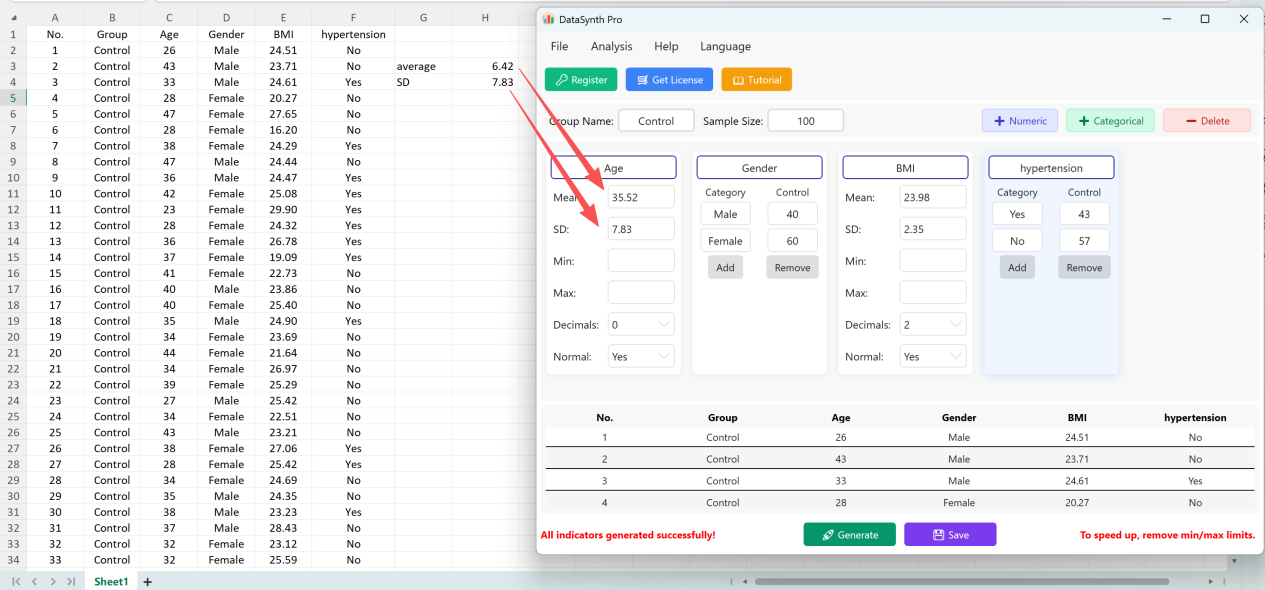
Figure 1.8 : Resultados de verificación idénticos a los parámetros iniciales
1.6 Eficiencia algorítmica
Equipado con un motor de optimización de alto rendimiento, el software puede generar conjuntos de datos que contienen miles o decenas de miles de registros en pocos segundos. Si el sistema no logra converger después del número máximo de iteraciones, verifique la coherencia estadística de su configuración o intente ejecutar la generación sin límites Mín/Máx. El programa admite una precisión decimal de hasta 8 dígitos para satisfacer las necesidades de investigación científica especializada.
Consejos y recomendaciones:
• Preferencia por la distribución normal: Por defecto, los datos siguen una distribución normal para un análisis posterior fluido (ej. Pruebas t para muestras independientes). Si prefiere conjuntos de datos no paramétricos o con distribución personalizada, simplemente cambie el parámetro Normal Distribution a No.
2. Prueba t para muestras independientes
Diseñado para estudios transversales que comparan las medias de dos grupos distintos. Muy utilizado en ensayos clínicos (ej. comparación de la eficacia de un tratamiento entre un grupo Tratamiento y un grupo Placebo) y encuestas sociológicas.
2.1 Flujo de trabajo
Acceda a Analyze → Independent T-Test. La ventana de configuración se presenta de la siguiente manera:
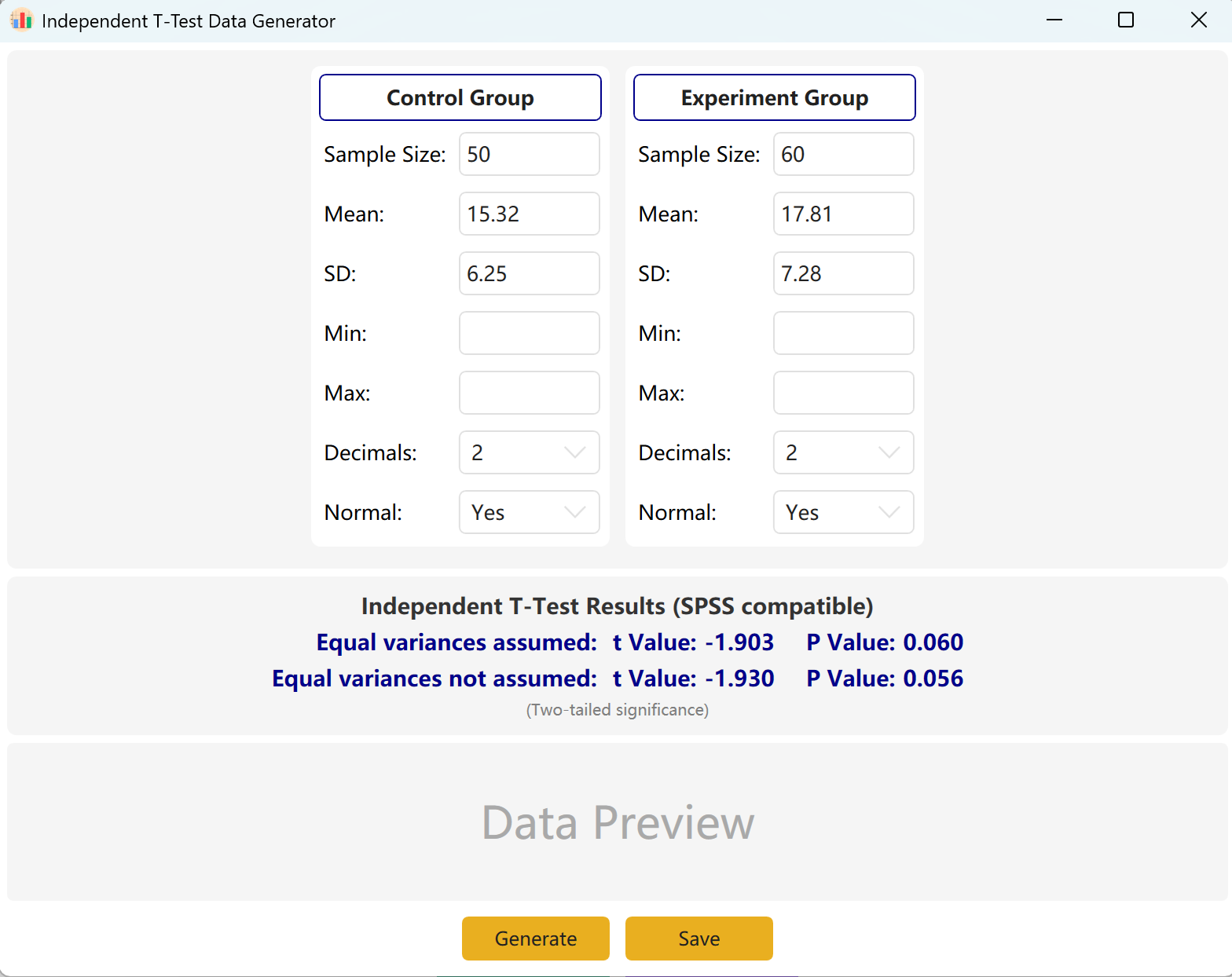
Figure 2.1 : Interfaz de usuario / Operaciones para la Prueba t independiente
2.2 Paramètres
El programa rellena previamente ejemplos para un "Control Group" (Grupo de Control) y un "Experimental Group" (Grupo Experimental) a modo de referencia. Introduzca el tamaño de la muestra, la media y la desviación estándar de cada grupo para previsualizar instantáneamente el valor t y el valor p en tiempo real. Los parámetros de Mín y Máx son opcionales.
Haga clic en el botón Generate para crear los conjuntos de datos brutos de los dos grupos en la tabla de vista previa a continuación. Los valores t y p finales se ajustarán automáticamente para reflejar los datos realmente generados utilizando la prueba de igualdad de varianzas de Levene.
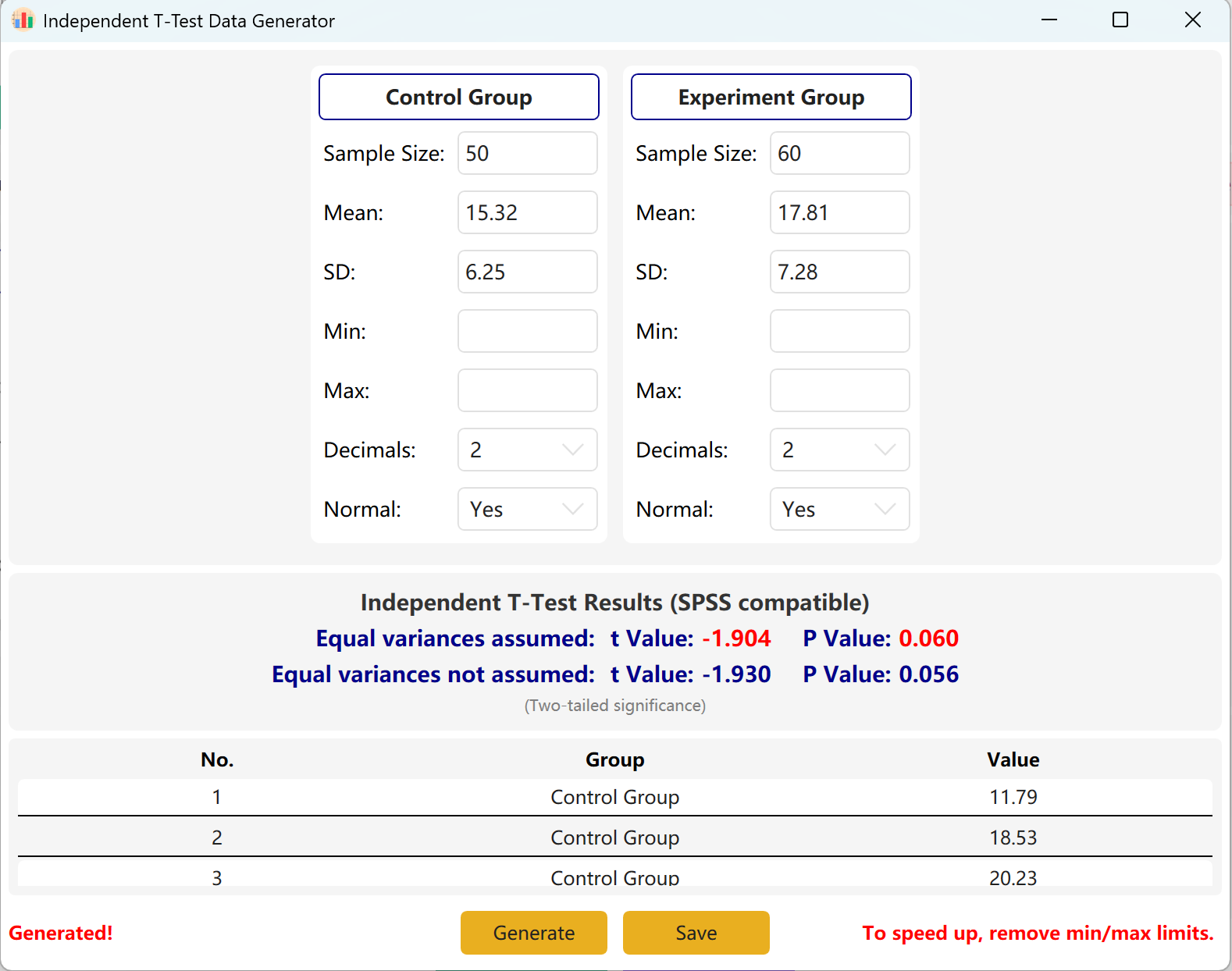
Figure 2.2 : Interfaz de usuario / Mostrar datos de la Prueba t para muestras independientes
3. Prueba t para muestras emparejadas
Empleado para estudios longitudinales o cruzados donde los mismos sujetos son medidos dos veces (ej. Pre-test vs Post-test). Se centra en la síntesis de la diferencia media entre las observaciones emparejadas.
3.1 Flujo de trabajo
Acceda a Analyze → Paired T-Test. El espacio de trabajo está estructurado de la siguiente manera:
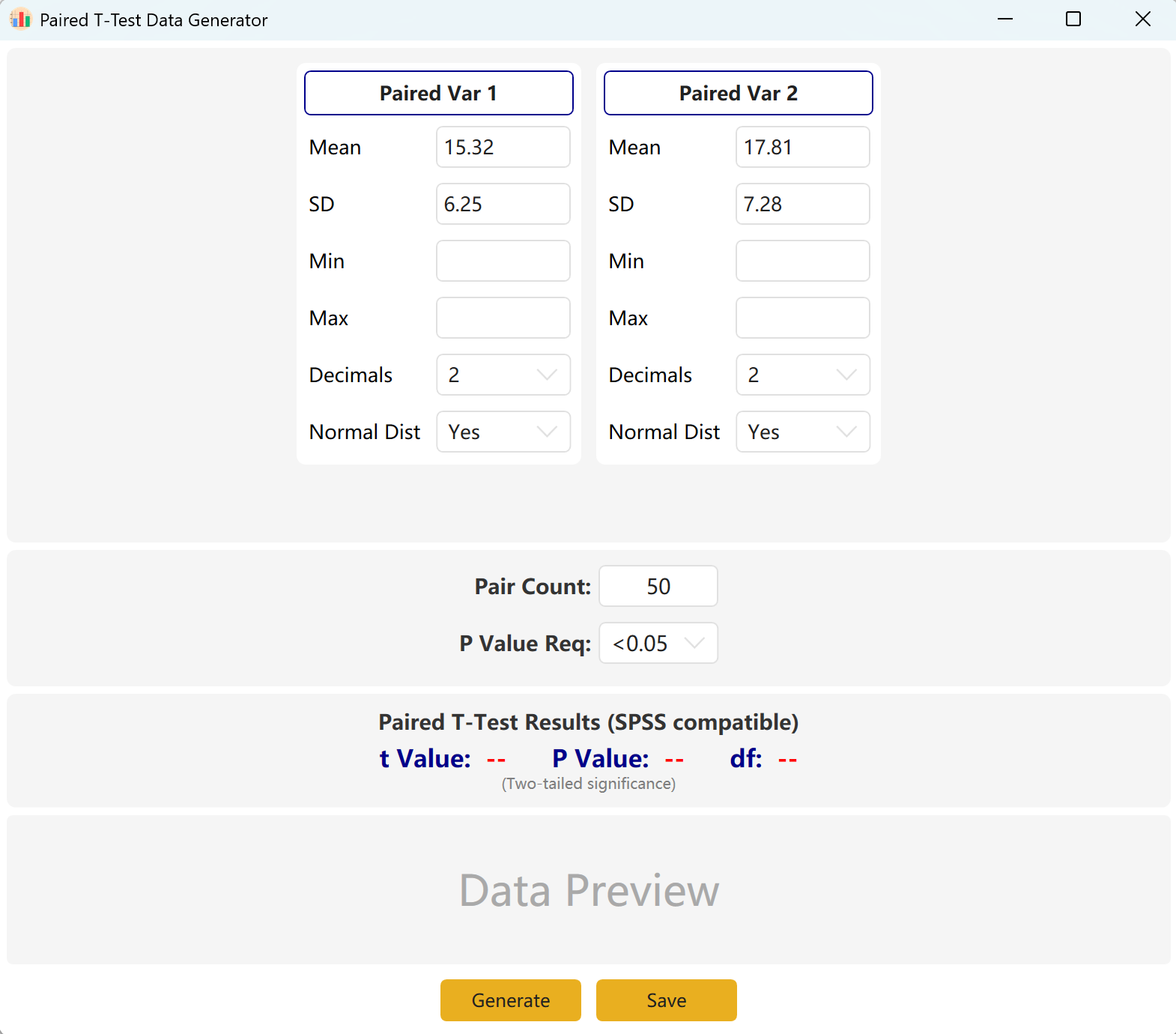
Figure 3.1 : Interfaz de usuario / Operaciones para la Prueba t emparejada
3.2 Lógica de simulación
El software configura por defecto dos variables emparejadas, Paired Var1 y Paired Var2. Puede definir la media y la desviación estándar de cada variable, fijar el tamaño global de la muestra y establecer un intervalo objetivo de p-value para la prueba t emparejada. El motor calculará luego de forma interactiva un conjunto de datos conforme.
Adaptación de convergencia: Si las medias configuradas son matemáticamente incompatibles con el p-value objetivo (por ejemplo, si las dos medias están muy alejadas pero solicita un p-value no significativo p > 0,05), el programa mantendrá los parámetros del primer grupo y ajustará dinámicamente la media del segundo grupo para alcanzar el p-value objetivo.
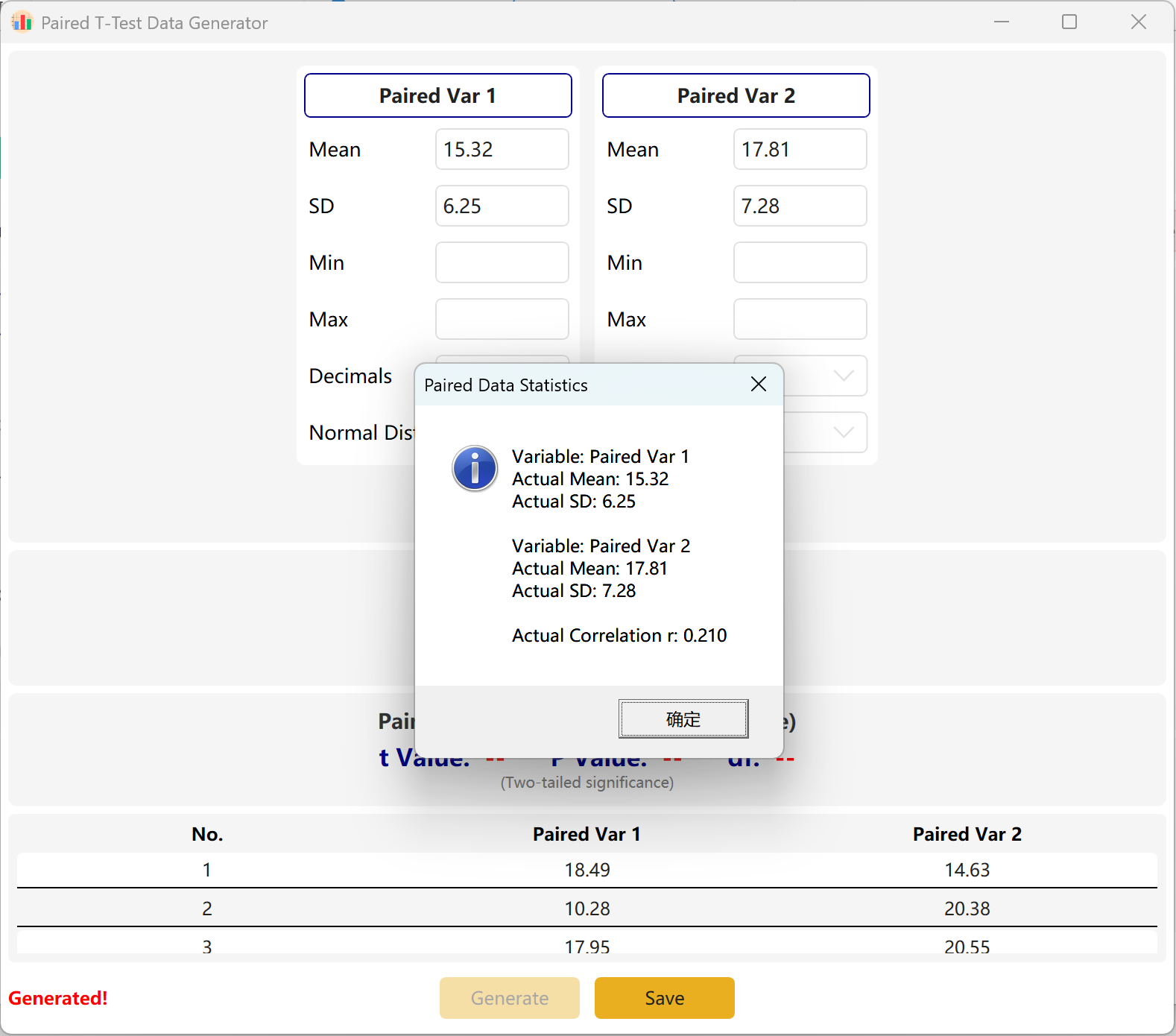
Figure 3.2 : Interfaz de usuario / Mostrar datos de la Prueba t para muestras emparejadas
4. Prueba de Chi-cuadrado
Permite determinar si existe una asociación significativa entre dos variables categóricas. Muy utilizado para cruces de datos demográficos.
4.1 Flujo de trabajo
Acceda a Analyze → Chi-Square Test. El panel de configuración se presenta de la siguiente manera:
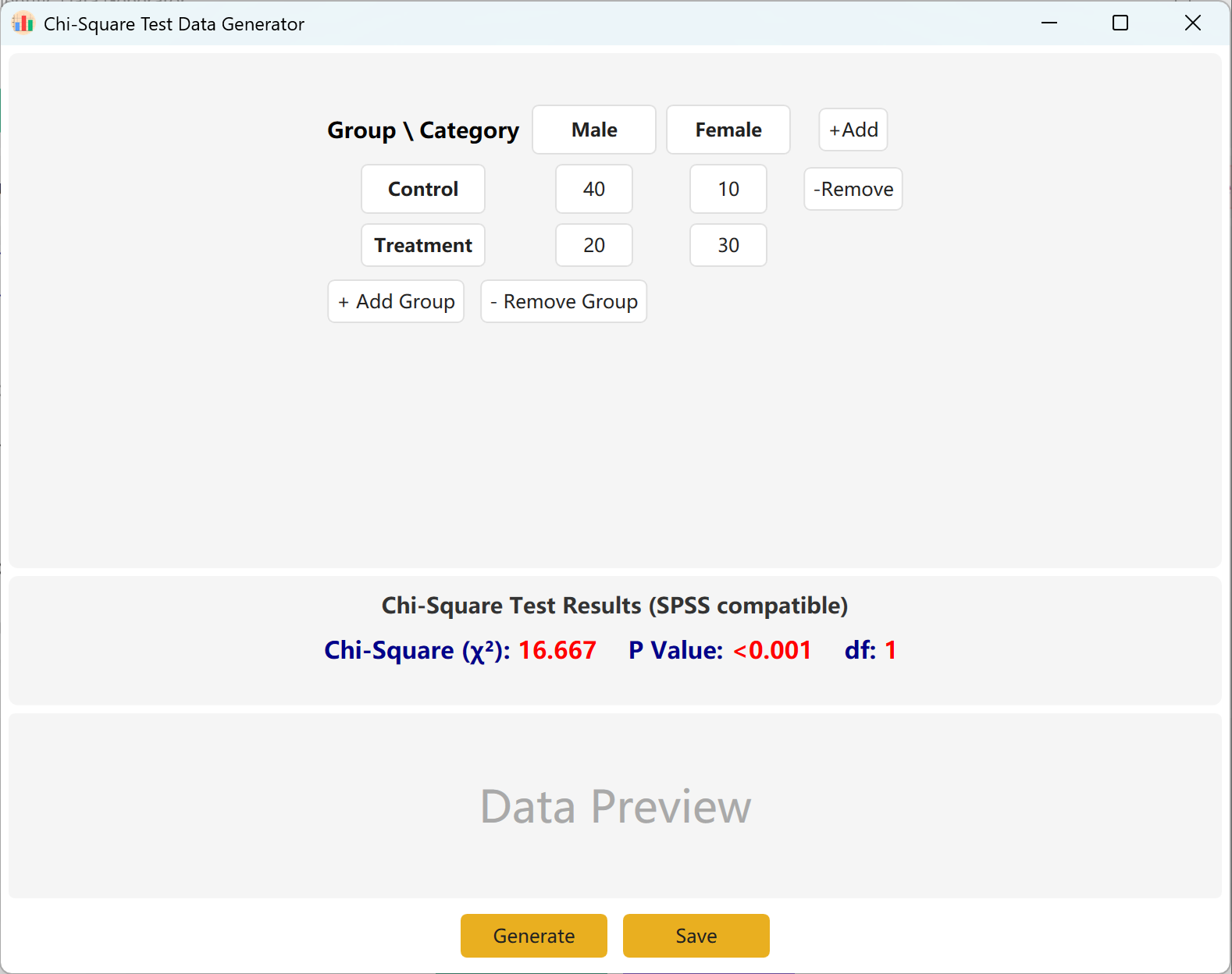
Figure 4.1 : Interfaz de usuario / Operaciones para la Prueba de Chi-cuadrado
4.2 Tabla de contingencia
La interfaz ofrece por defecto una tabla de contingencia estándar 2x2 para el cálculo del Chi-cuadrado, donde los nombres de los grupos y las categorías son completamente editables. Rellene los efectivos observados (conteos) para cada celda, y el valor calculado de Chi-cuadrado así como el p-value se actualizarán en tiempo real.
Puede añadir dinámicamente grupos (filas) o categorías (columnas) para adaptar modelos más complejos. Haga clic en el botón Generate para producir los registros individuales correspondientes a estos efectivos, y luego haga clic en Save para exportar el conjunto de datos a Excel.
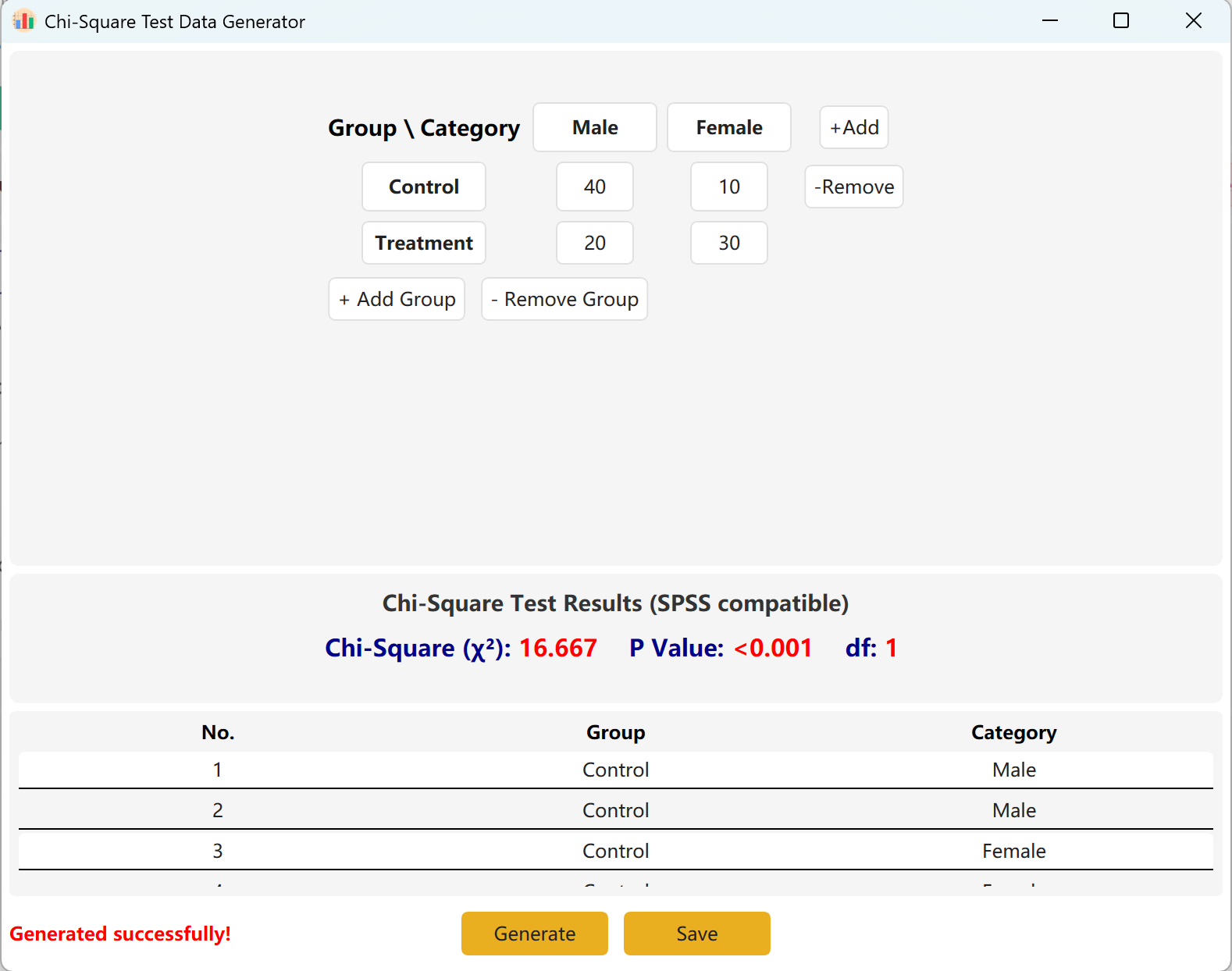
Figure 4.2 : Interfaz de usuario / Mostrar datos de la Prueba de Chi-cuadrado
5. ANOVA de un factor
Utilizado al comparar las medias de tres o más grupos independientes. El algoritmo sintetiza la varianza intra-grupo y las diferencias inter-grupos para respetar los valores F objetivo.
5.1 Flujo de trabajo
Acceda a Analyze → ANOVA → One-Way ANOVA. El espacio de trabajo se presenta a continuación:
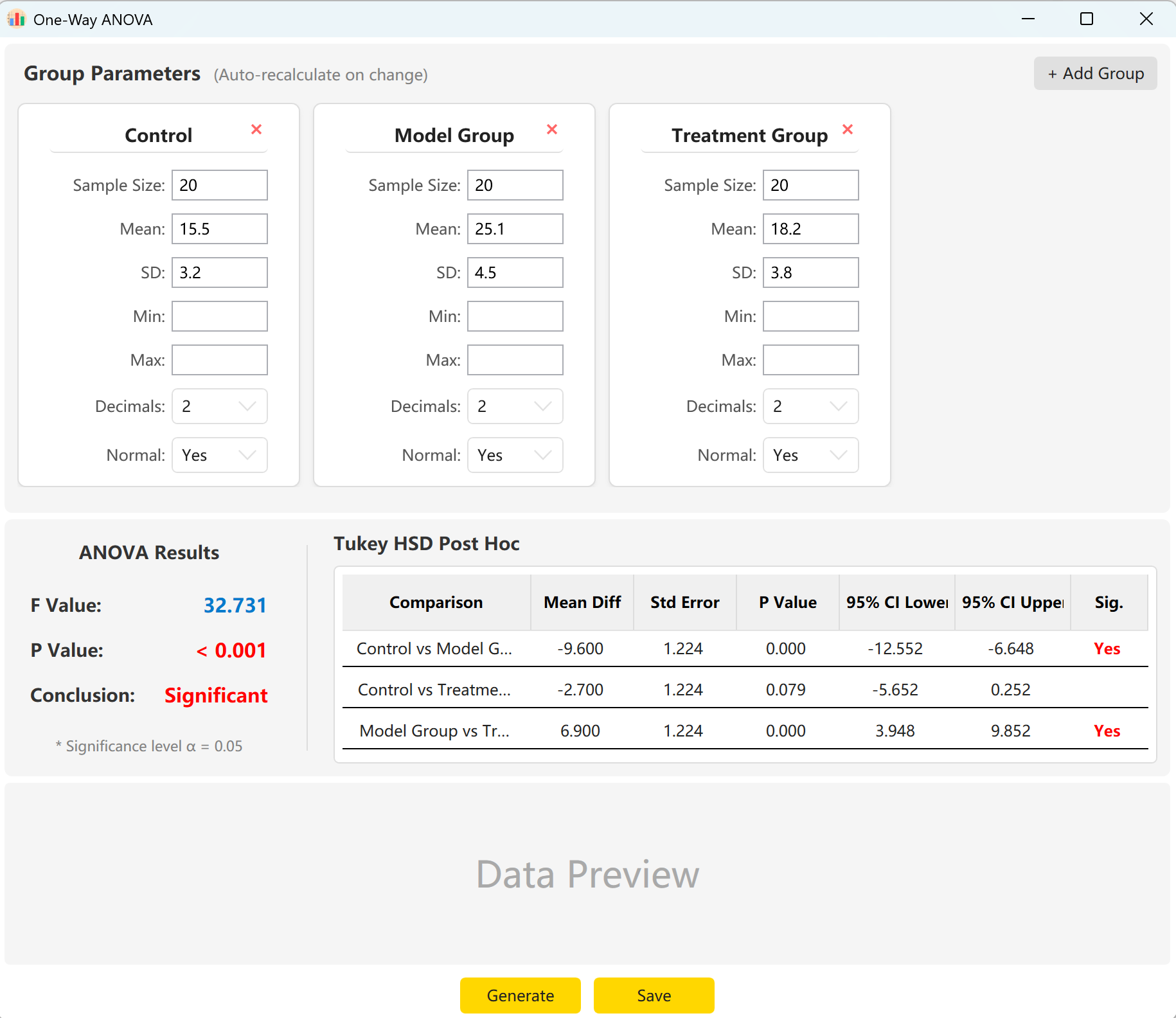
Figure 5.1 : Interfaz de usuario / Operaciones para el ANOVA de un factor
5.2 Configuración
El sistema carga previamente los parámetros de tres grupos: "Control Group" (Grupo de Control), "Experimental Group" (Grupo Experimental) y "Treatment Group" (Grupo de Tratamiento). Simplemente introduzca el tamaño de la muestra, la media y la desviación estándar de cada grupo para visualizar instantáneamente el estadístico global F, el p-value y los resultados de la comparación múltiple post-hoc HSD de Tukey.
Haga clic en el botón Generate para calcular y previsualizar los registros brutos individuales a continuación. Los valores F y p globales se actualizarán automáticamente para reflejar los datos realmente generados.
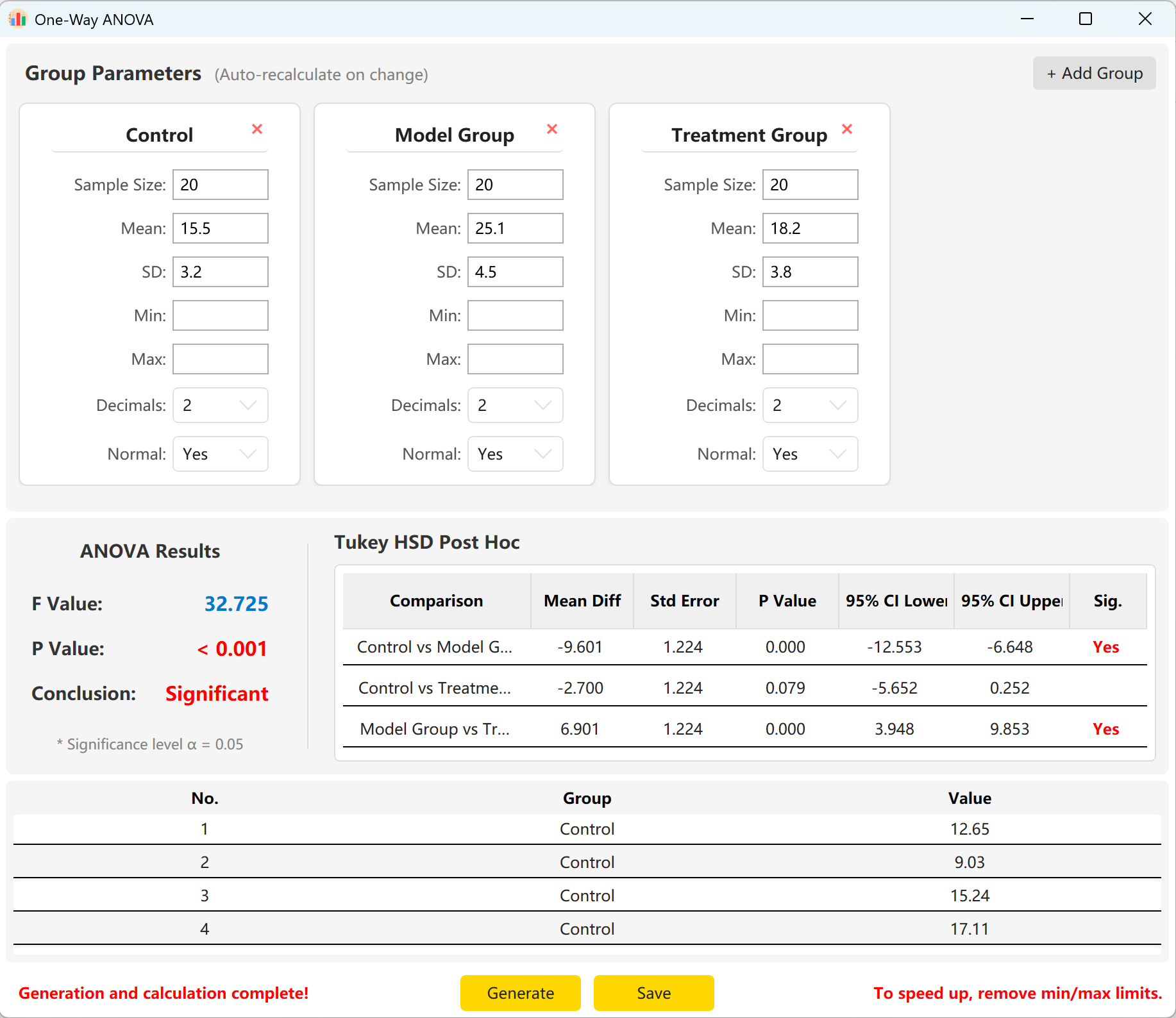
Figure 5.2 : Interfaz de usuario / Mostrar datos del ANOVA de un factor
6. ANOVA de dos factores
Examina la influencia de dos variables independientes categóricas en una variable de resultado continua. Esencial para los diseños factoriales para evaluar los efectos principales y los efectos de interacción.
6.1 Flujo de trabajo
Acceda a Analyze → ANOVA → Two-Way ANOVA. El panel de configuración se presenta de la siguiente manera:
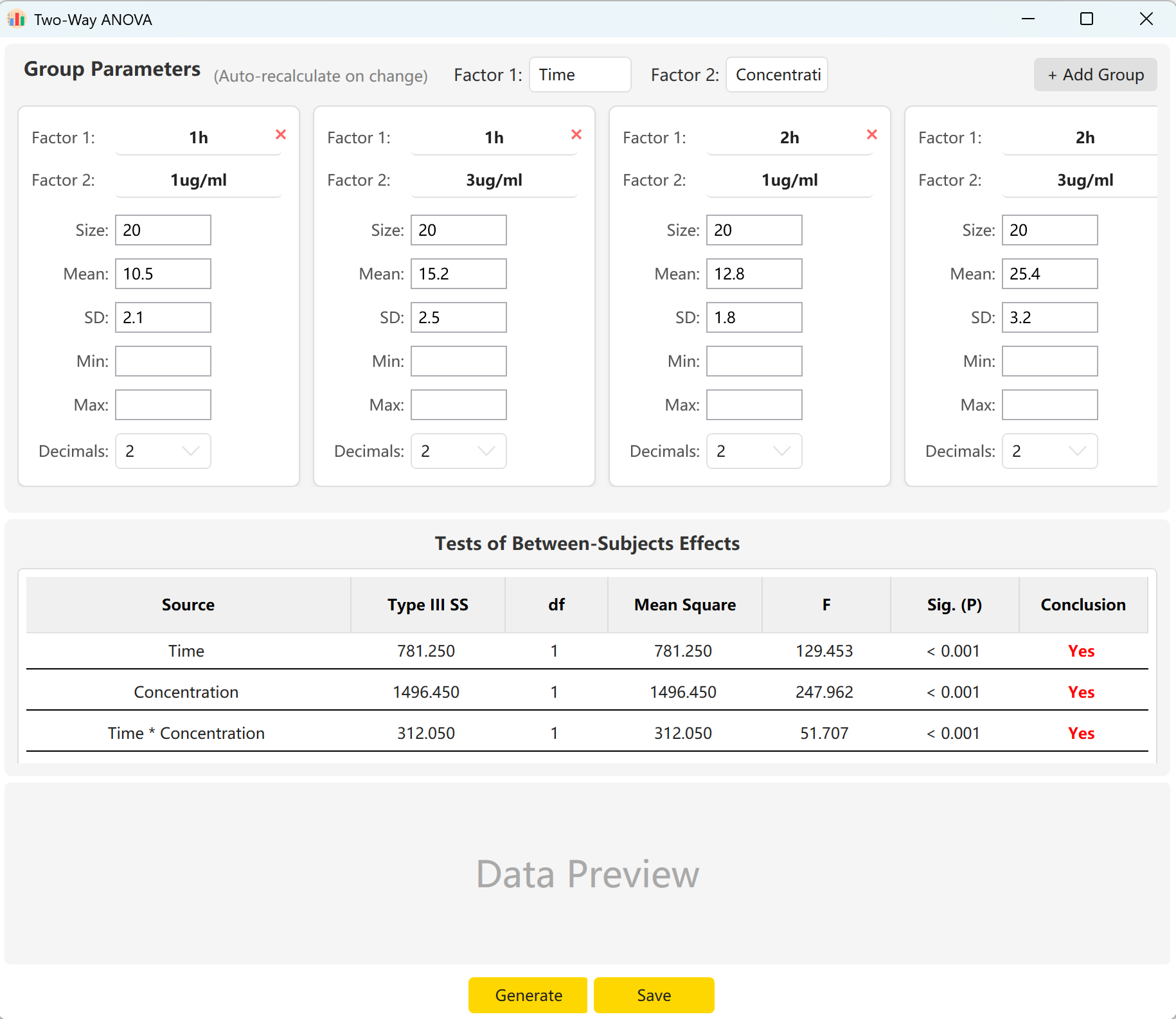
Figure 6.1 : Interfaz de usuario / Operaciones para el ANOVA de dos factores
6.2 Factores e interacciones
La herramienta está configurada por defecto con dos factores: "Time" (Tiempo - 2 niveles) y "Concentration" (Concentración - 2 niveles). Haga clic en Add Group para configurar más niveles si uno de sus factores contiene varias categorías.
Al introducir el tamaño de la muestra, la media y la desviación estándar de cada celda, puede obtener una vista previa en tiempo real de los estadísticos F y los p-values para el efecto principal del Tiempo, el efecto principal de la Concentración y su efecto de interacción (Tiempo × Concentración). Haga clic en el botón Generate para elaborar los registros brutos correspondientes en el panel de vista previa.
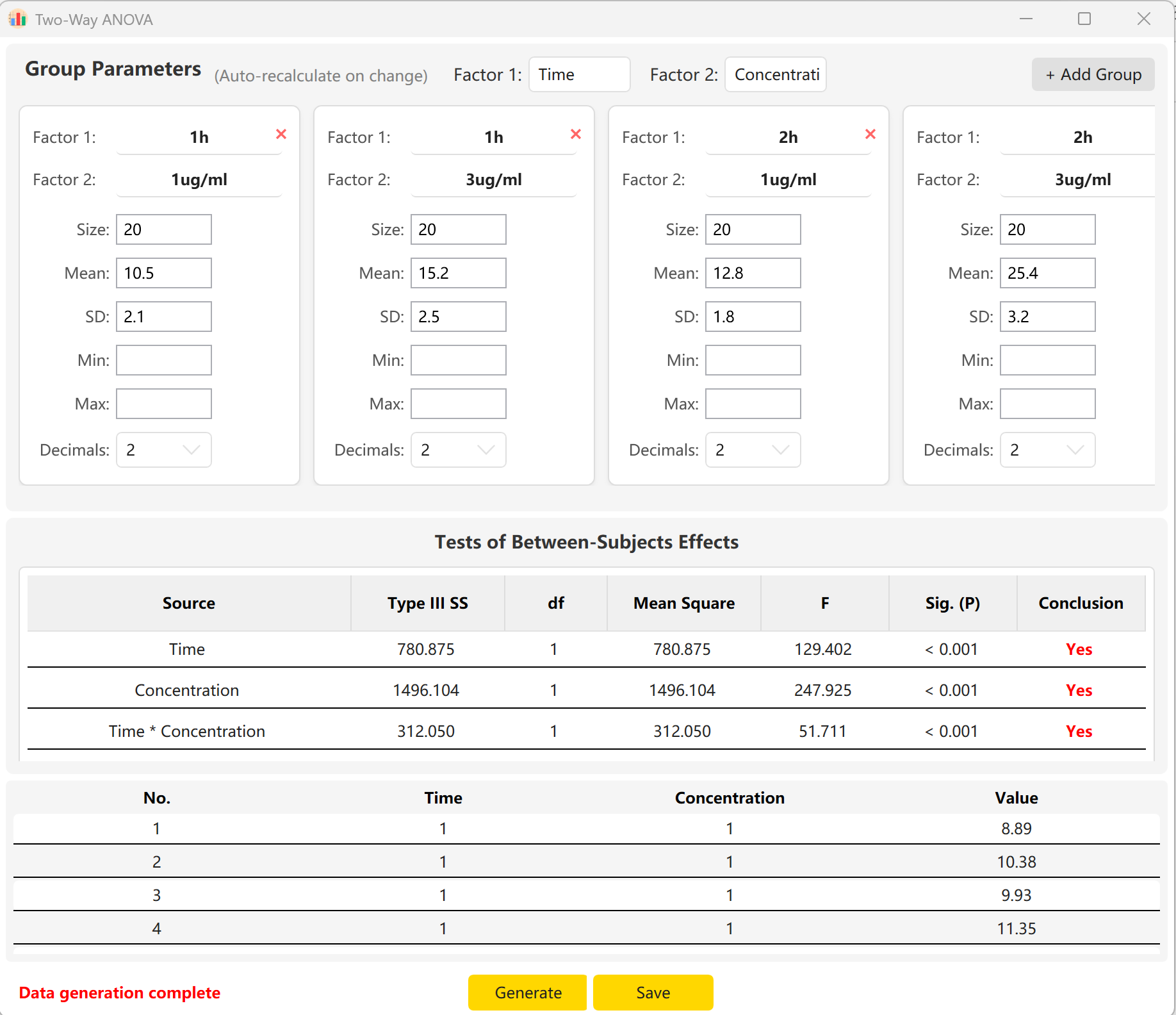
Figure 6.2 : Interfaz de usuario / Mostrar datos del ANOVA de dos factores
7. ANOVA de medidas repetidas de un factor
La extensión de la prueba t emparejada a tres o más puntos de observación. Ideal para el seguimiento longitudinal durante períodos prolongados (ej. medición inicial, mes 1, mes 3).
7.1 Flujo de trabajo
Acceda a Analyze → ANOVA → Repeated Measures ANOVA. El espacio de trabajo se presenta a continuación:
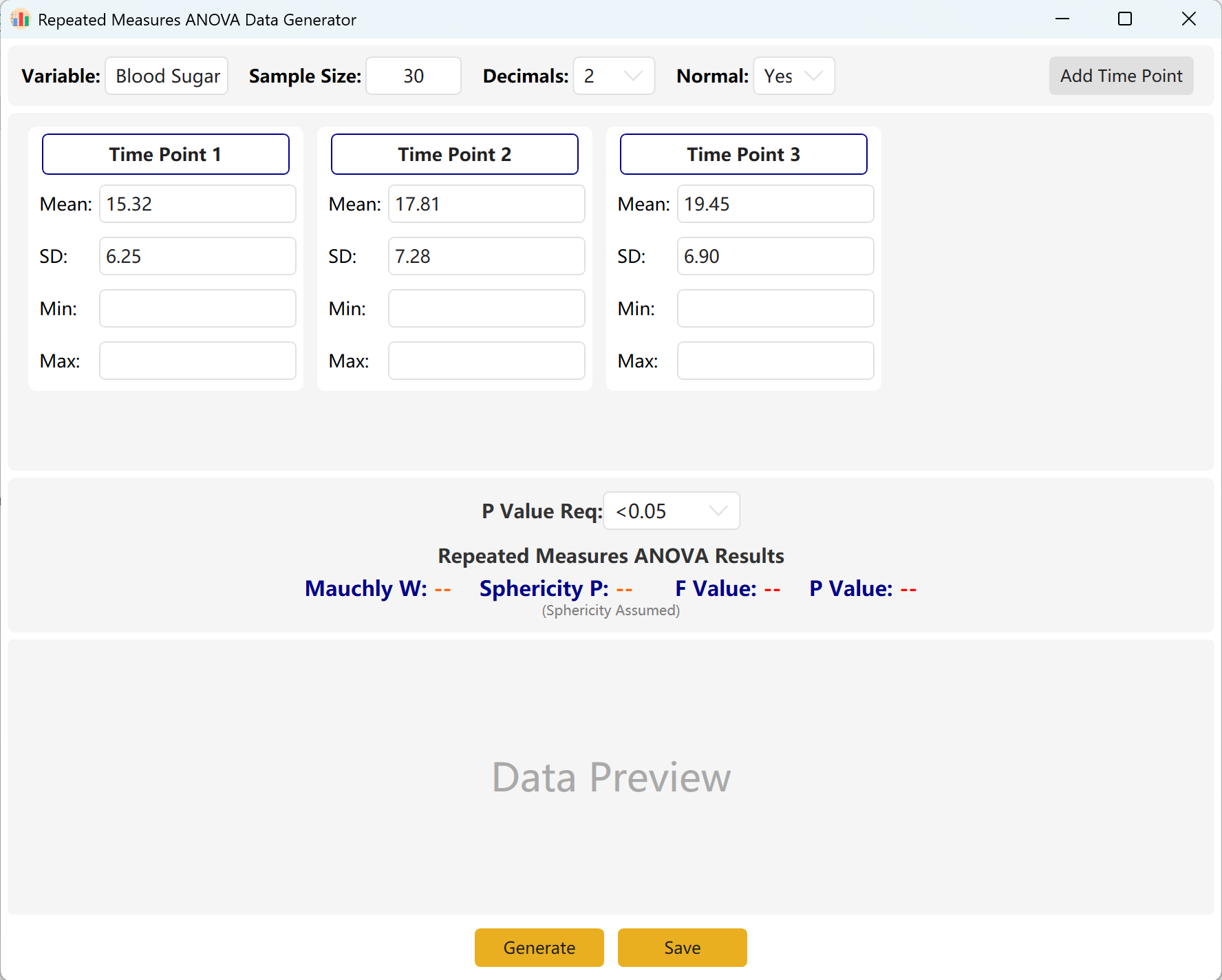
Figure 7.1 : Interfaz de usuario / Operaciones para el ANOVA de medidas repetidas de un factor
7.2 Observaciones repetidas
El sistema está configurado por defecto con tres puntos de observación temporales. Puede aumentar fácilmente este número haciendo clic en el botón Add Time Point. Introduzca la media y la desviación estándar de cada punto de observación y defina su intervalo de p-value objetivo.
Haga clic en el botón Generate para sintetizar los valores conformes.
Adaptación de varianza del motor: Si la diferencia entre los puntos de observación es matemáticamente enorme (lo que indica un p-value extremadamente significativo) mientras que su intervalo objetivo está fijado en p > 0,05, el motor comprimirá automáticamente las varianzas y las desviaciones de medias entre los puntos temporales para alcanzar precisamente su objetivo. Un cuadro de diálogo mostrará las estadísticas reales obtenidas.
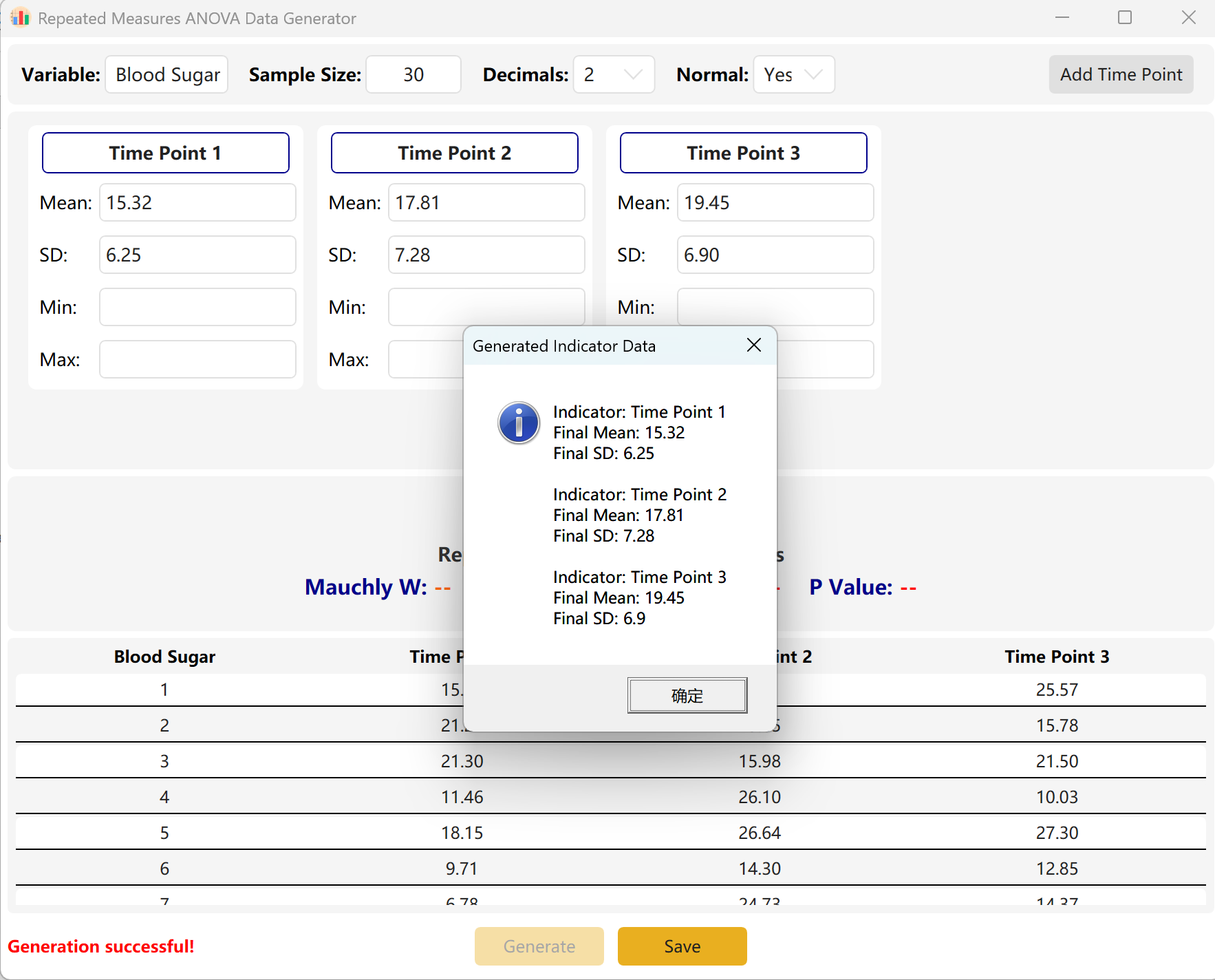
Figure 7.2 : Interfaz de usuario / Mostrar datos del ANOVA de medidas repetidas
8. Prueba de suma de rangos para dos muestras independientes (No Paramétrica)
El equivalente a la prueba U de Mann-Whitney cuando los datos no cumplen los supuestos de normalidad. Evalúa las diferencias de medianas según una lógica de ordenación por rangos en variables continuas u ordinales.
8.1 Flujo de trabajo
Acceda a Analyze → Non-parametric → 2 Independent Samples. El espacio de configuración se presenta de la siguiente manera:
1.png)
Figure 8.1 : Interfaz de usuario / Operaciones para la Prueba de suma de rangos para dos muestras independientes
8.2 Configuración
El programa ofrece por defecto dos grupos de referencia. Dado que los métodos no paramétricos están destinados a datos que no siguen una distribución normal, la opción Normal Distribution está establecida en No por defecto. Con base en la prueba U de Mann-Whitney, puede definir un p-value objetivo. Haga clic en el botón Generate para sintetizar observaciones brutas que respeten este umbral estadístico.
Lógica de generación por suma de rangos: Las pruebas no paramétricas analizan las diferencias de grupos agrupando todas las observaciones y asignándoles rangos. Por lo tanto, si los parámetros configurados para sus dos grupos presentan grandes diferencias (lo que daría naturalmente un p-value minúsculo) mientras que solicita un objetivo p > 0,05, el motor reducirá por sí mismo la divergencia entre los grupos. Las medias y desviaciones estándar finales calculadas se mostrarán en un cuadro de diálogo.
2.png)
Figure 8.2 : Interfaz de usuario / Mostrar datos de la Prueba de suma de rangos para dos muestras independientes
9. Prueba de Kruskal-Wallis (K muestras independientes no paramétricas)
Equivalente a la prueba H de Kruskal-Wallis. Genera datos ordinales o datos continuos no normales distribuidos en tres o más grupos independientes.
9.1 Flujo de trabajo
Acceda a Analyze → Non-parametric → K Independent Samples. El espacio de configuración se ilustra a continuación:
1.png)
Figure 9.1 : Interfaz de usuario / Operaciones para la Prueba de Kruskal-Wallis
9.2 Clasificación multi-grupo
El programa ofrece por defecto tres grupos de referencia y realiza una prueba de Kruskal-Wallis. Al igual que en la prueba de dos grupos, dado que los cálculos se basan en los rangos de una muestra global fusionada, si los parámetros configurados para sus diferentes grupos muestran diferencias masivas (lo que da p-values altamente significativos) mientras que solicita un objetivo p > 0,05, el motor de simulación mitigará automáticamente las diferencias inter-grupos. Las estadísticas correspondientes se mostrarán en una ventana emergente.
2.png)
Figure 9.2 : Interfaz de usuario / Mostrar datos de la Prueba de Kruskal-Wallis
10. Generación de datos por cuartiles
Divide un conjunto de datos ordenados en cuatro partes iguales. Útil para evaluar la dispersión y la tendencia central de los datos, resaltar la mediana y detectar valores atípicos (outliers).
10.1 Flujo de trabajo
Acceda a Analyze → Quartile Data. El diseño se presenta de la siguiente manera:
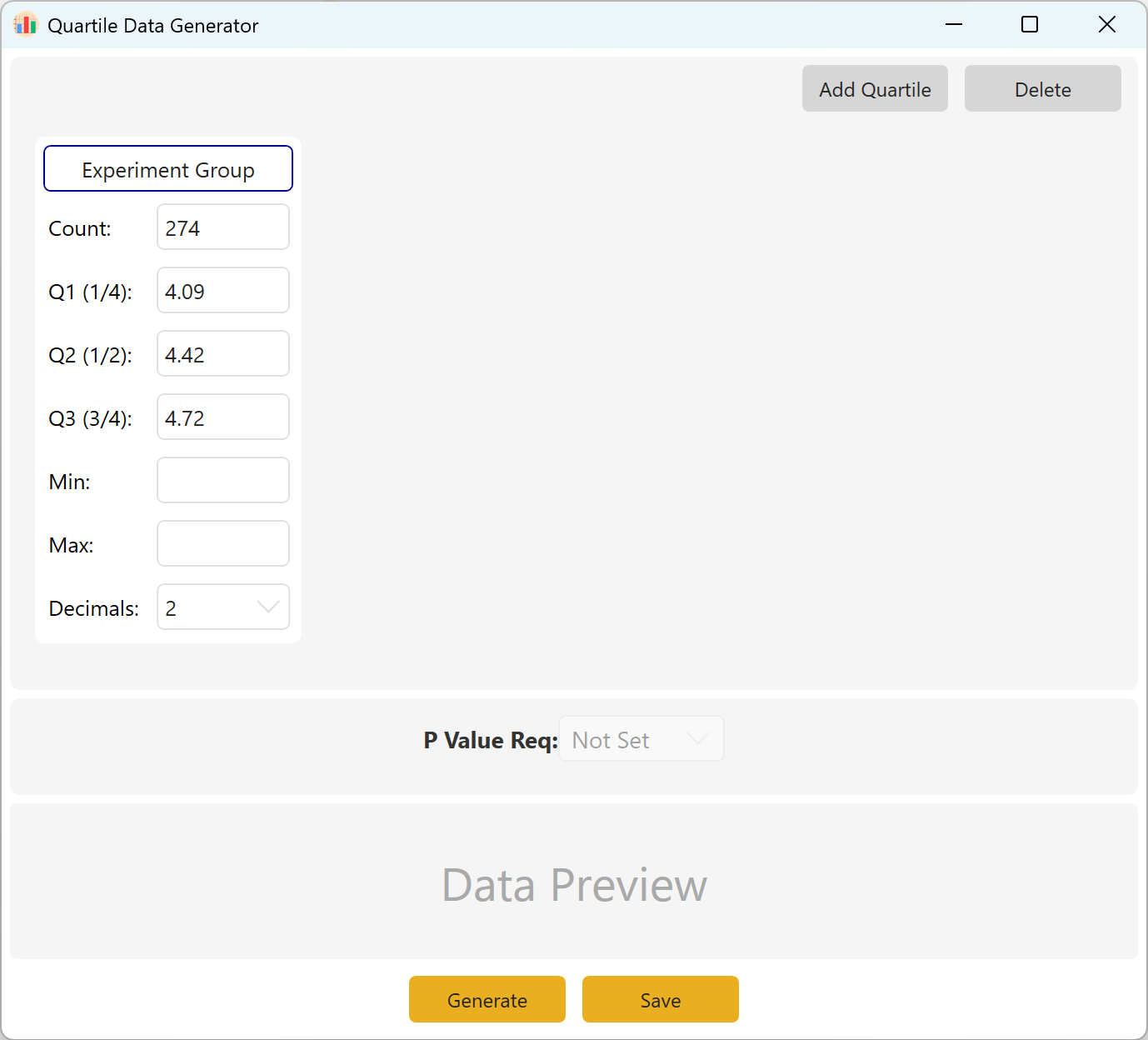
Figure 10.1 : Interfaz de usuario / Operaciones para Datos por cuartiles
10.2 Definición de parámetros
Defina el tamaño de la muestra objetivo, el primer cuartil Q1 (percentil 25), la mediana Q2 (percentil 50) y el tercer cuartil Q3 (percentil 75). Los campos Mín/Máx pueden permanecer vacíos si no se aplica ninguna limitación específica. Elija el número de decimales y haga clic en el botón Generate para producir las observaciones que cumplen exactamente con estos límites de cuartiles.
Resumen: Configure el tamaño de la muestra así como los valores objetivo para Q1, Q2 y Q3. Los parámetros opcionales incluyen el Mínimo, el Máximo y el Número de decimales. Haga clic en el botón Generate para calcular y mostrar las observaciones brutas correspondientes a la estructura de cuartiles deseada. Para configuraciones de varios grupos, también puede definir un intervalo de p-value objetivo inter-grupo.
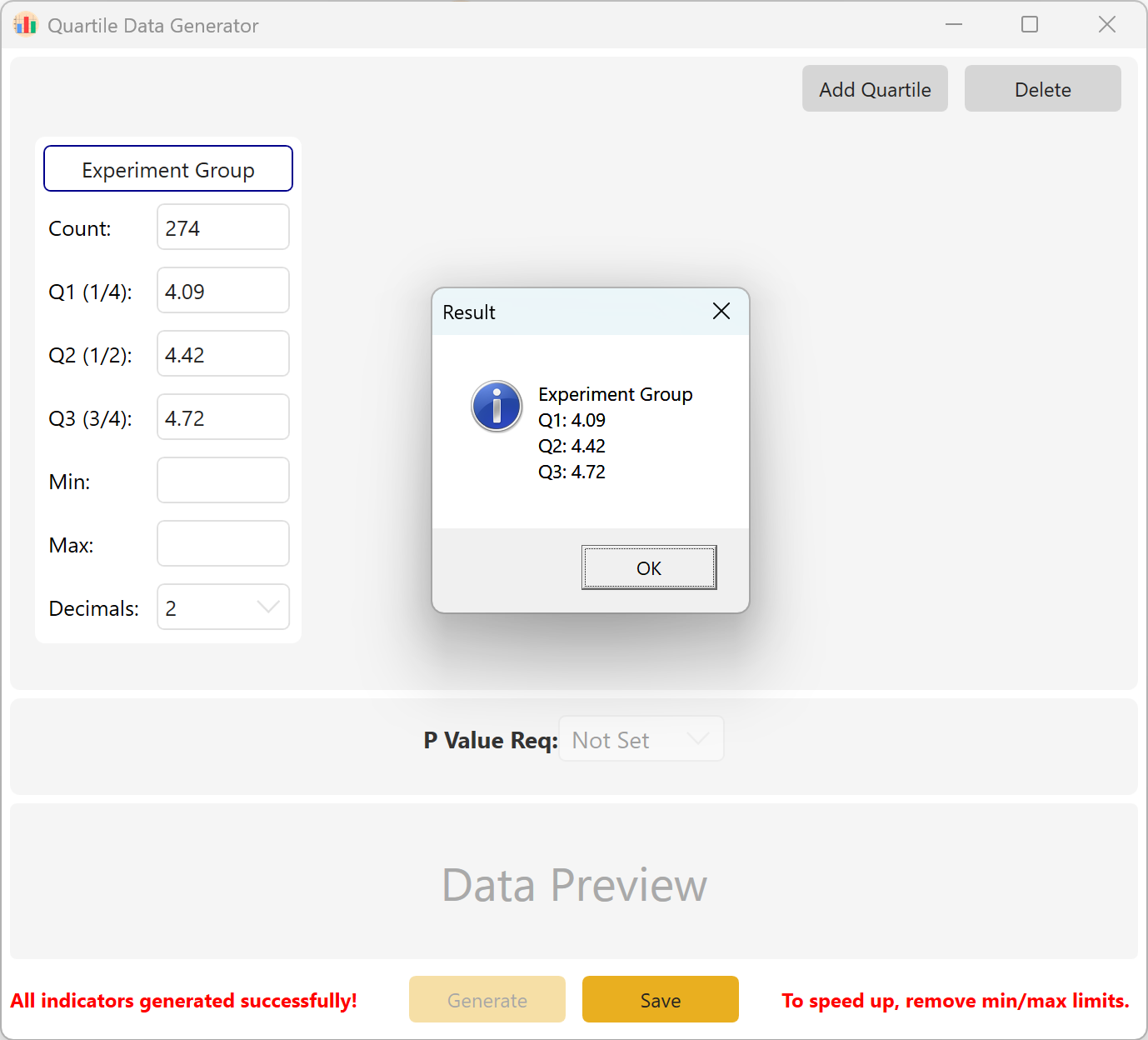
Figure 10.2 : Interfaz de usuario / Mostrar datos por cuartiles
11. Generación de datos de regresión logística binaria
Esencial para problemas de clasificación donde la variable de resultado es dicotómica (VD=0 o VD=1). Muy común en epidemiología para la identificación de factores de riesgo (ej. Enfermo vs Sano).
11.1 Flujo de trabajo
Acceda a Analyze → Regression → Binary Logistic.
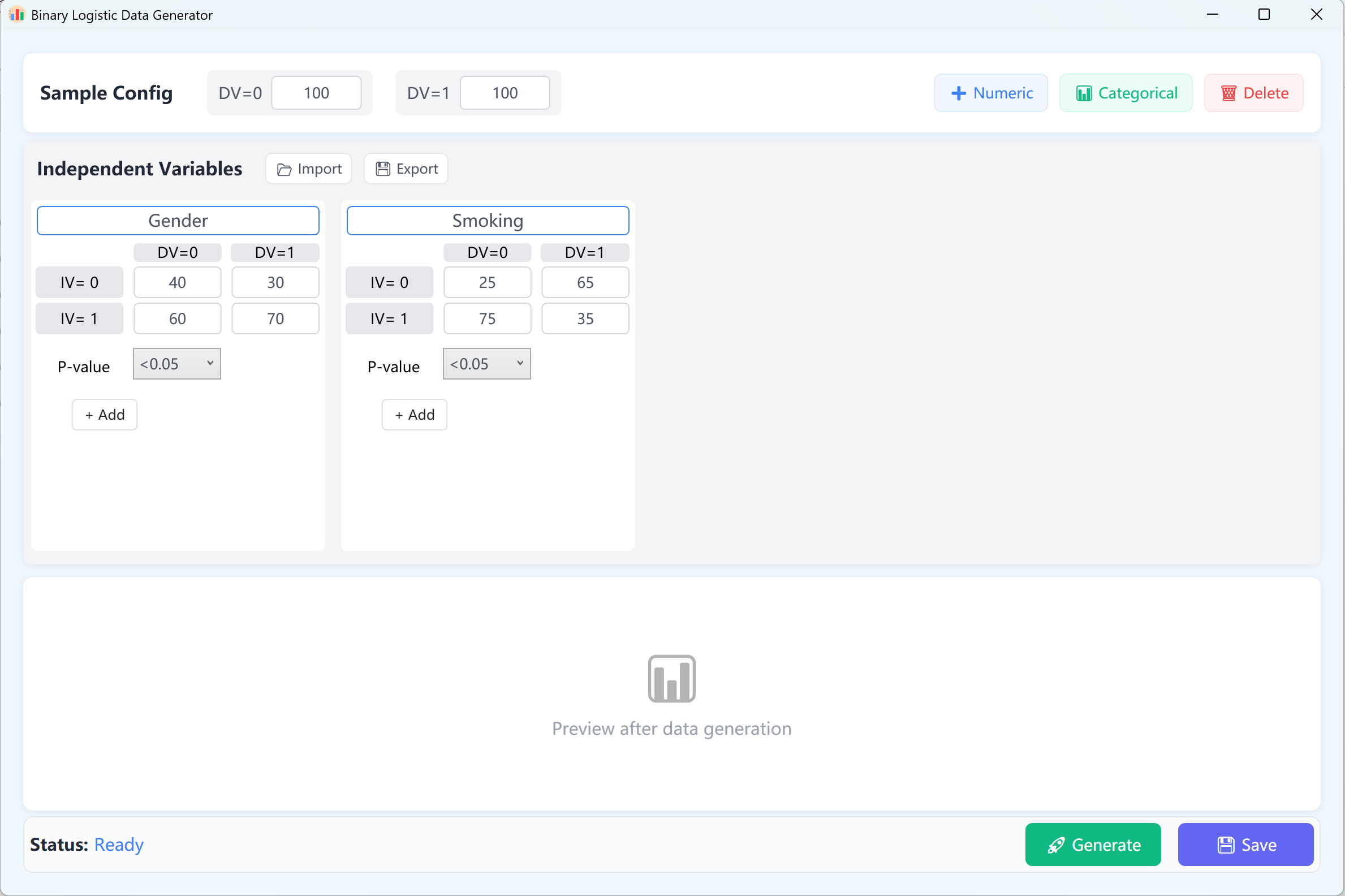
Figure 11.1 : Interfaz de usuario / Operaciones para la Regresión logística binaria
11.2 Diseño
Por defecto, se configuran dos variables independientes continuas a modo de ejemplo. En un modelo logístico binario, la variable dependiente tiene solo dos estados posibles (0 y 1). De este modo, la variable dependiente se estructura en los grupos 0 y 1, con un tamaño de muestra por defecto de 100 casos por categoría (personalizable).
- Configuration des variables : Haga clic en + Numeric para añadir variables independientes continuas (ej. "Age", "BMI"). Indique el nombre de la variable, su Media, su Desviación Estándar, el Número de decimales y el intervalo objetivo del p-value (este parámetro define el nivel de significación deseado para esta variable dentro del modelo final de regresión logística). Los límites Mín/Máx son opcionales.
- Génération et validation : Haga clic en el botón Generate para iniciar el algoritmo de síntesis. El sistema calculará de forma iterativa un conjunto de datos para el cual el modelo de regresión logística proporcione p-values de acuerdo con su configuración.
Un informe detallado de análisis de regresión que replica exactamente el formato de salida de IBM SPSS se mostrará automáticamente en una ventana emergente. Al cerrar este informe se revelan los datos brutos en la tabla de vista previa, listos para ser exportados a Excel.
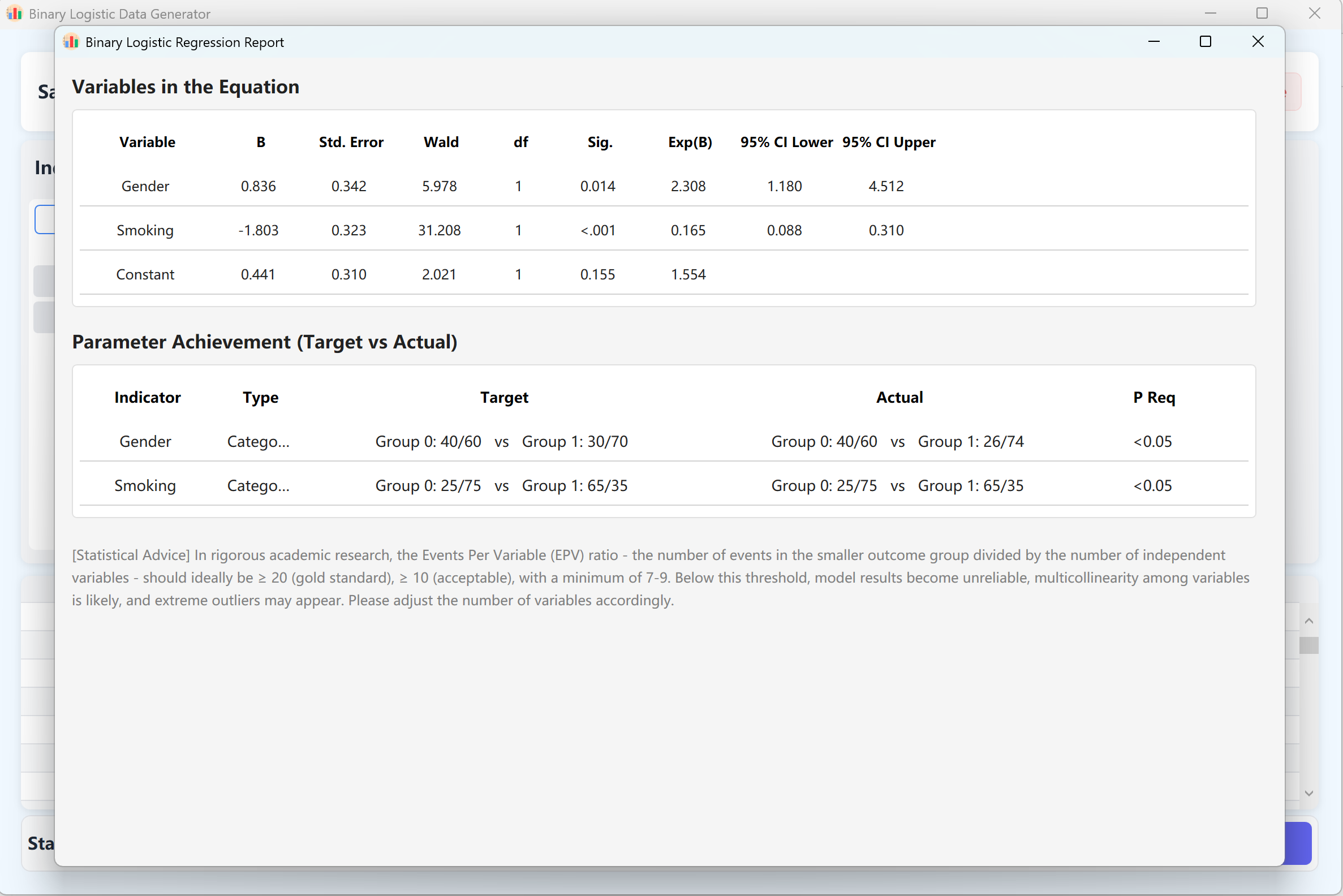
Figure 11.2 : Interfaz de usuario / Mostrar datos de la Regresión logística binaria
12. Generación de datos de regresión lineal múltiple
Una herramienta fundamental de modelado predictivo. Sintetiza una variable dependiente continua (Y) influenciada por varias variables independientes (X). Estas últimas pueden ser de naturaleza continua (numérica), por cuartiles, categóricas ordenadas (ordinales) o no ordenadas (nominales).
12.1 Flujo de trabajo
Acceda a Analyze → Regression → Linear Regression.
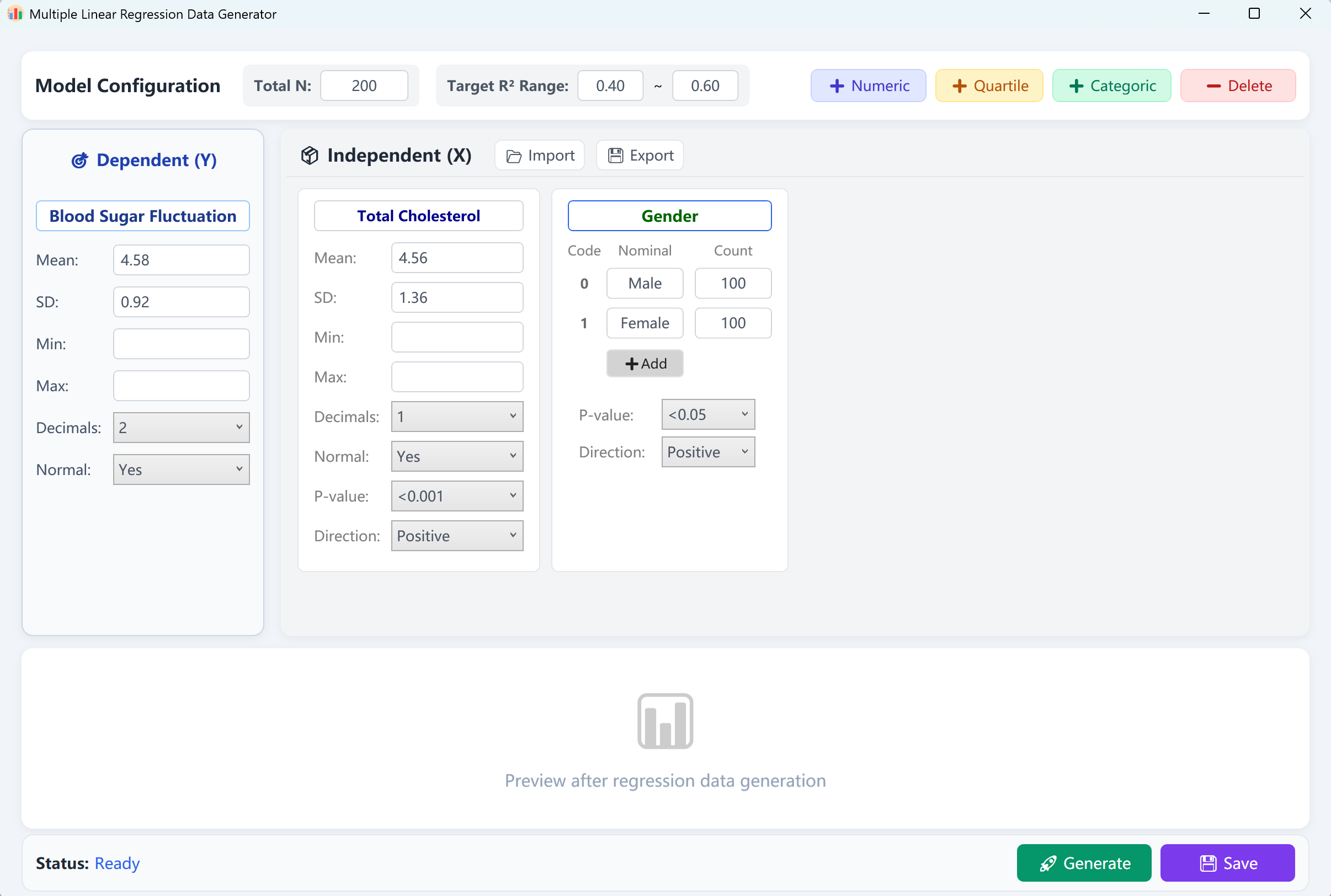
Figure 12.1 : Interfaz de usuario / Operaciones para la Regresión lineal múltiple
12.2 Parámetros del modelo
La interfaz carga previamente una variable dependiente continua ("Blood Glucose Fluctuation" - Fluctuación de la glucemia) y dos variables independientes ("Total Cholesterol" - Colesterol total como variable numérica, y "Gender" - Género como variable categórica) con un tamaño de muestra por defecto de 200 casos. Puede definir un intervalo objetivo para el coeficiente de determinación R-cuadrado (R²) (ej. entre 0,4 y 0,6).
Haga clic en el botón Generate para ejecutar el modelo de regresión. Aparecerá un informe de validación similar a los resultados de SPSS. Al cerrar este informe, encontrará la tabla de vista previa de datos brutos, lista para ser guardada en formato Excel.
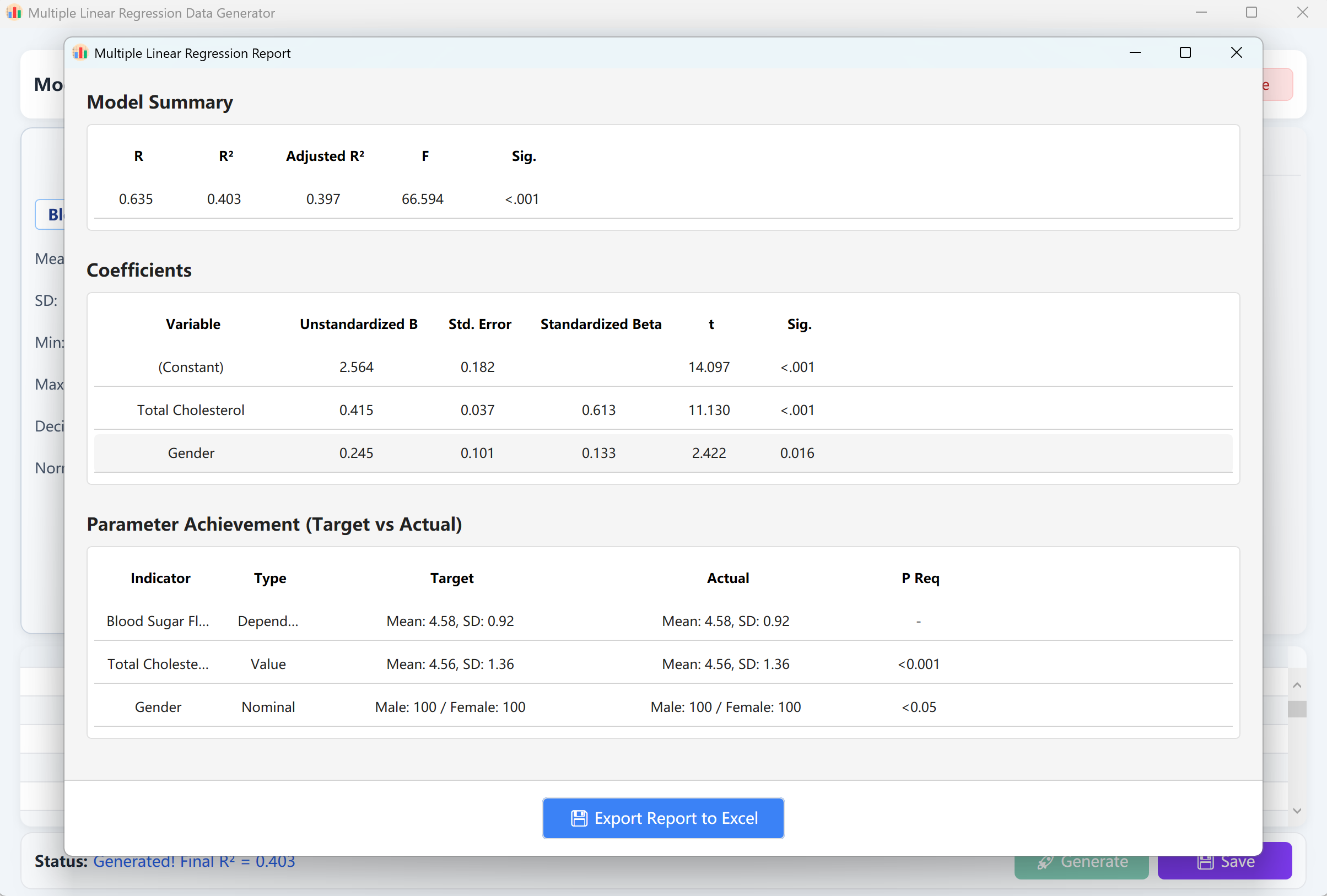
Figure 12.2 : Interfaz de usuario / Mostrar datos de la Regresión lineal múltiple
13. Generación de datos de regresión de riesgos proporcionales de Cox
El estándar de oro en el análisis de supervivencia. Simula datos de tiempo hasta el evento teniendo en cuenta la censura a la derecha, lo que permite a los investigadores evaluar el impacto de las covariables en los tiempos de supervivencia.
13.1 Flujo de trabajo et directives techniques
Acceda a Analyze → Regression → Cox Regression.
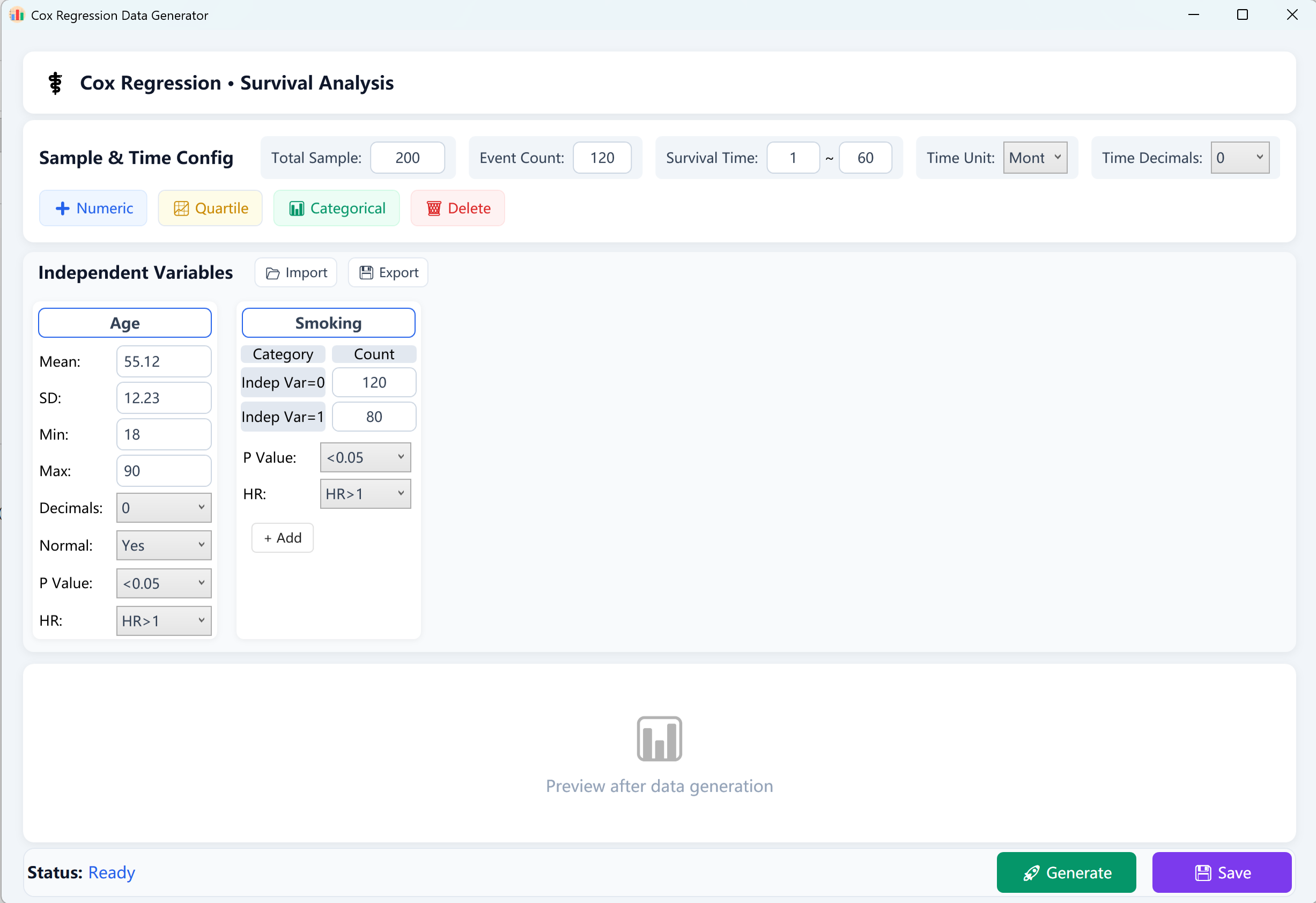
Figure 13.1 : Interfaz de usuario / Operaciones para la Regresión de riesgos proporcionales de Cox
- Tamaño total de la muestra (N): El número global de sujetos o pacientes (ej. 200 sujetos).
- Eventos observados (Eventos de interés): El número de casos positivos que experimentaron el evento terminal (ej. muerte, recaída o fallo) durante el período de seguimiento. Nota: El número de eventos debe ser estrictamente menor que el tamaño total de la muestra.
- Intervalo de tiempo de supervivencia (T): Defina los límites [Min Follow-up] y [Max Follow-up] de la duración del seguimiento de supervivencia (ej. 1~60 meses), etiquete la unidad de tiempo (días, meses o años) e indique el número de decimales deseado.
Regla estadística del EPV (Eventos por variable): Para garantizar la estabilidad matemática y la confiabilidad de un modelo de riesgos proporcionales de Cox, se recomienda encarecidamente tener una proporción de eventos observados en relación con el número de variables independientes (EPV) de al menos 10 a 20. Si su modelo no logra converger, intente aumentar el tamaño total de la muestra o el número de eventos observados.
13.2 Construcción de las variables de investigación
Haga clic en los botones correspondientes en la parte inferior de la tarjeta de variables para añadir covariables independientes:
- Variables numéricas continuas: Haga clic en + Numeric para añadir covariables continuas (ej. Edad, IMC, biomarcadores clínicos). Indique la Media, la Desviación Estándar (obligatorio) y, opcionalmente, los límites Mín/Máx para restringir valores atípicos, así como el número de decimales.
- Variables categóricas: Haga clic en + Categorical para añadir covariables nominales u ordinales (ej. Género, puntuación de satisfacción). Indique el tamaño objetivo exacto para cada categoría. Nota: La suma de los tamaños de todas las categorías debe ser imperativamente igual al tamaño total de la muestra configurado para poder iniciar la generación.
- Variables por cuartiles: Haga clic en + Quartile para añadir variables estructuradas por cuartiles, completando los parámetros objetivo de Q1, Q2 (Mediana) y Q3.
Parámetros objetivo: Cada tarjeta de variable ofrece dos potentes parámetros de direccionamiento en la parte inferior de la página:
- p-value de la regresión: Seleccione el umbral de significación objetivo (ej. p > 0,05, p < 0,05, p < 0,01 o p < 0,001).
- Dirección del Hazard Ratio (HR): Elija HR > 1 (factor de riesgo, que indica un aumento de la tasa de riesgo) o HR < 1 (factor protector, que indica una disminución de la tasa de riesgo).
13.3 Ejecución de la generación y guardado
Una vez configurados todos los parámetros, haga clic en el botón Generate en la parte inferior de la ventana. El motor de ejecución iniciará simulaciones iterativas altamente concurrentes. Se mostrará entonces un informe oficial y detallado de análisis de regresión de riesgos proporcionales de Cox, reproduciendo fielmente los cálculos y la presentación de IBM SPSS.
Haga clic en el botón Save para exportar el conjunto de datos brutos generado a un archivo Excel. Este se podrá importar directamente en SPSS o cualquier otra herramienta de análisis estadístico profesional para su verificación.
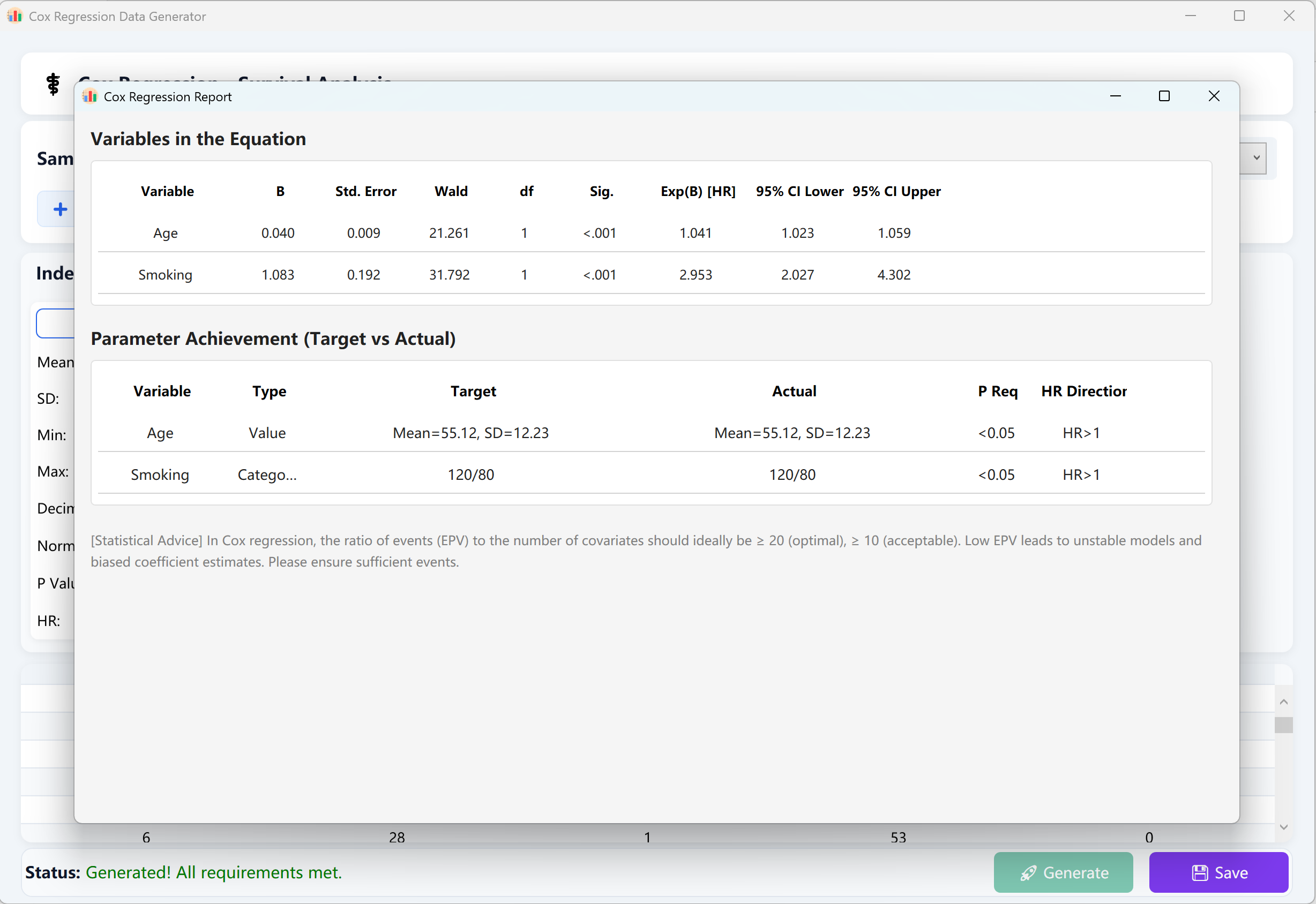
Figure 13.2 : Interfaz de usuario / Mostrar datos de la Regresión de riesgos proporcionales de Cox
14. Generación de datos para el análisis de correlación
Simula relaciones bivariadas (Pearson o Spearman) y correlaciones parciales aplicando coeficientes de correlación (valores de r) y niveles de significación objetivo.
14.1 Flujo de trabajo
Acceda a Analyze → Correlation.
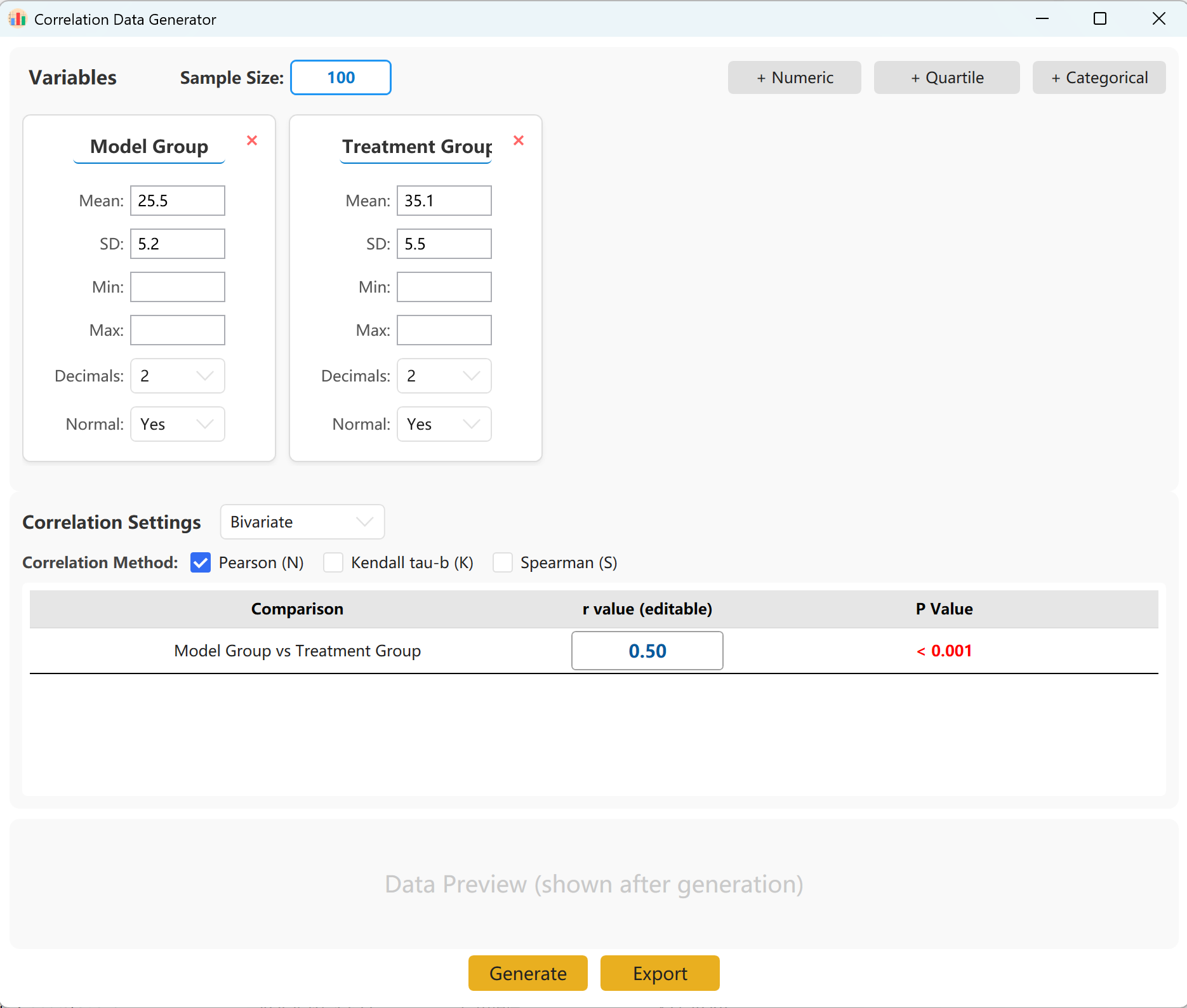
Figure 14.1 : Interfaz de usuario / Operaciones para el Análisis de correlación
14.2 Parámetros
El sistema carga previamente dos conjuntos de variables para una referencia rápida. Puede añadir fácilmente otras variables, en forma numérica continua (media/desviación estándar), por cuartiles o categóricas. En el panel de configuración, especifique el tamaño de la muestra, la media y la desviación estándar de cada indicador (los límites Mín/Máx son opcionales).
Puede especificar el coeficiente de correlación exacto (r) objetivo entre los grupos. Haga clic en el botón Generate para iniciar la simulación y mostrar la matriz de correlación resultante en una ventana emergente, lista para ser exportada a formato Excel.
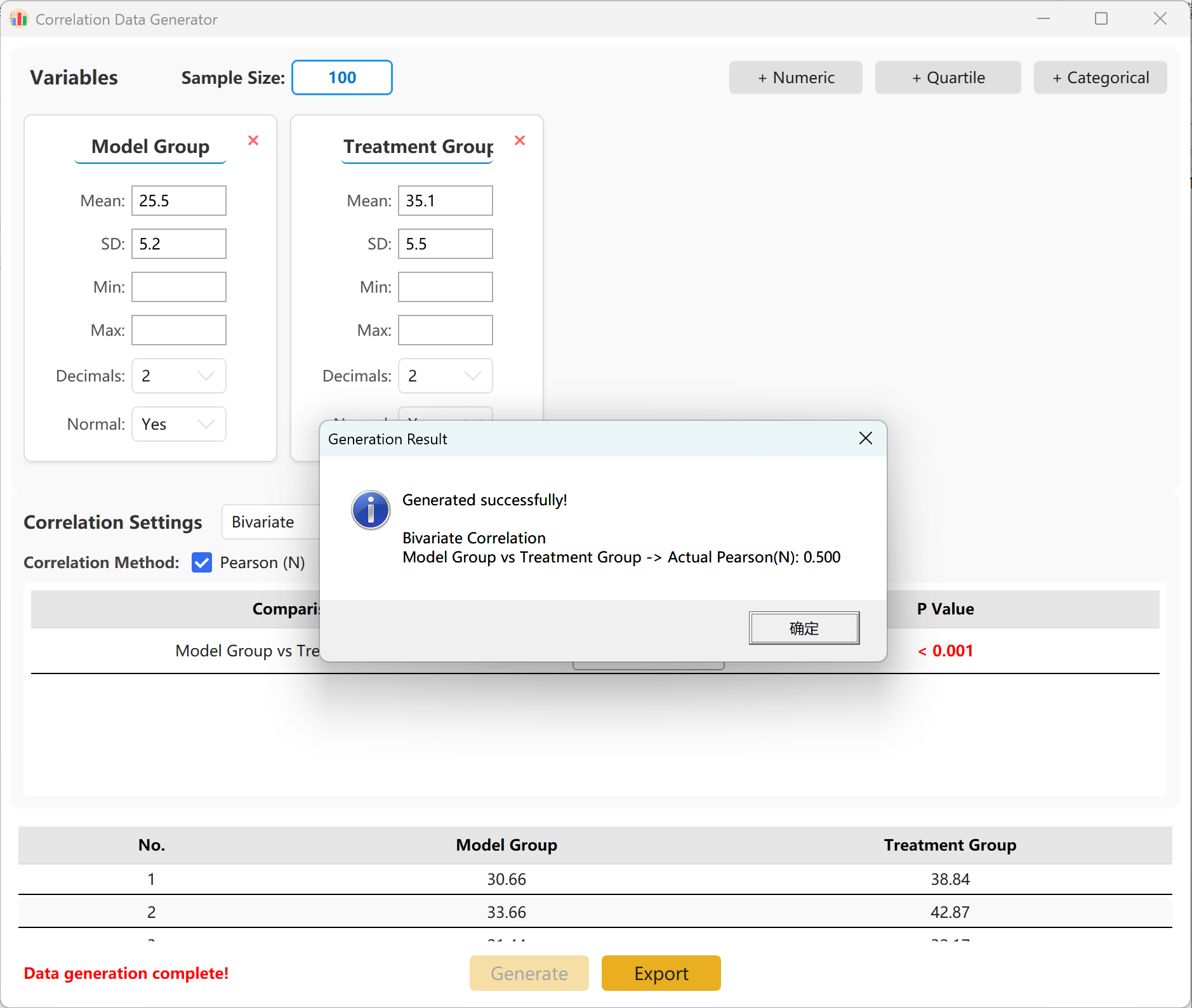
Figure 14.2 : Interfaz de usuario / Mostrar datos del Análisis de correlación
15. Generación de datos para el análisis de curva ROC
Evalúa la capacidad diagnóstica de una variable de prueba continua o categórica para distinguir dos estados (ej. Diagnóstico Positivo vs Negativo).
15.1 Flujo de trabajo
Acceda a Analyze → ROC Curve.
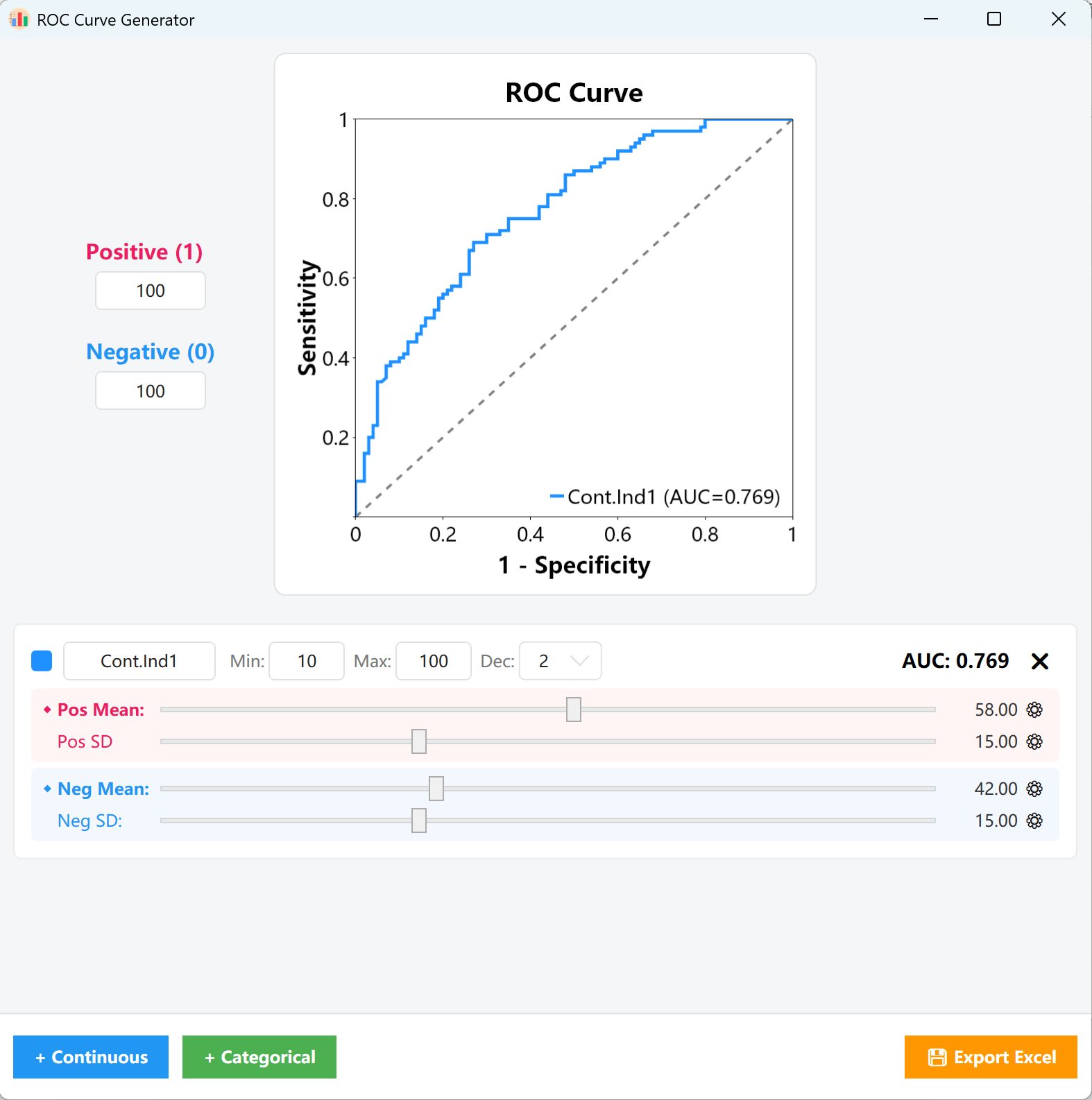
Figure 15.1 : Interfaz de usuario / Operaciones para el parámetro de la curva ROC
Proporciones: En el panel de configuración a la izquierda, complete los tamaños objetivo para las Muestras Positivas (1) y Muestras Negativas (0) (ej. 100 casos positivos y 100 casos negativos). El motor de generación construirá la matriz de muestreo básica de acuerdo con estas proporciones.
15.2 Tipos de variables
Haga clic en + Continuous o + Categorical en la parte inferior izquierda para crear las variables correspondientes:
- Variables continuas: Personalice el nombre de la variable, los límites Mín/Máx y el número de decimales en la tarjeta. Arrastre el control deslizante Rosa (grupo Positivo) y el control deslizante Azul (grupo Negativo) para ajustar rápidamente sus respectivas distribuciones de Media y Desviación Estándar.
- ⚙ Ajuste de precisión: Si los controles deslizantes visuales no permiten alcanzar la granularidad deseada, haga clic en el icono de engranaje (⚙) al lado del parámetro para introducir manualmente valores precisos de punto flotante.
- Seguimiento del AUC: A lo largo de estos de la tarjeta y el gráfico central se actualizarán en tiempo real, lo que le permitirá alinear visualmente la curva con su valor umbral objetivo.
- Variables categóricas: Simplemente defina las proporciones o tamaños exactos para las cohortes positivas y negativas. Podrá observar instantáneamente los cambios correspondientes en la curva ROC y el valor del AUC.
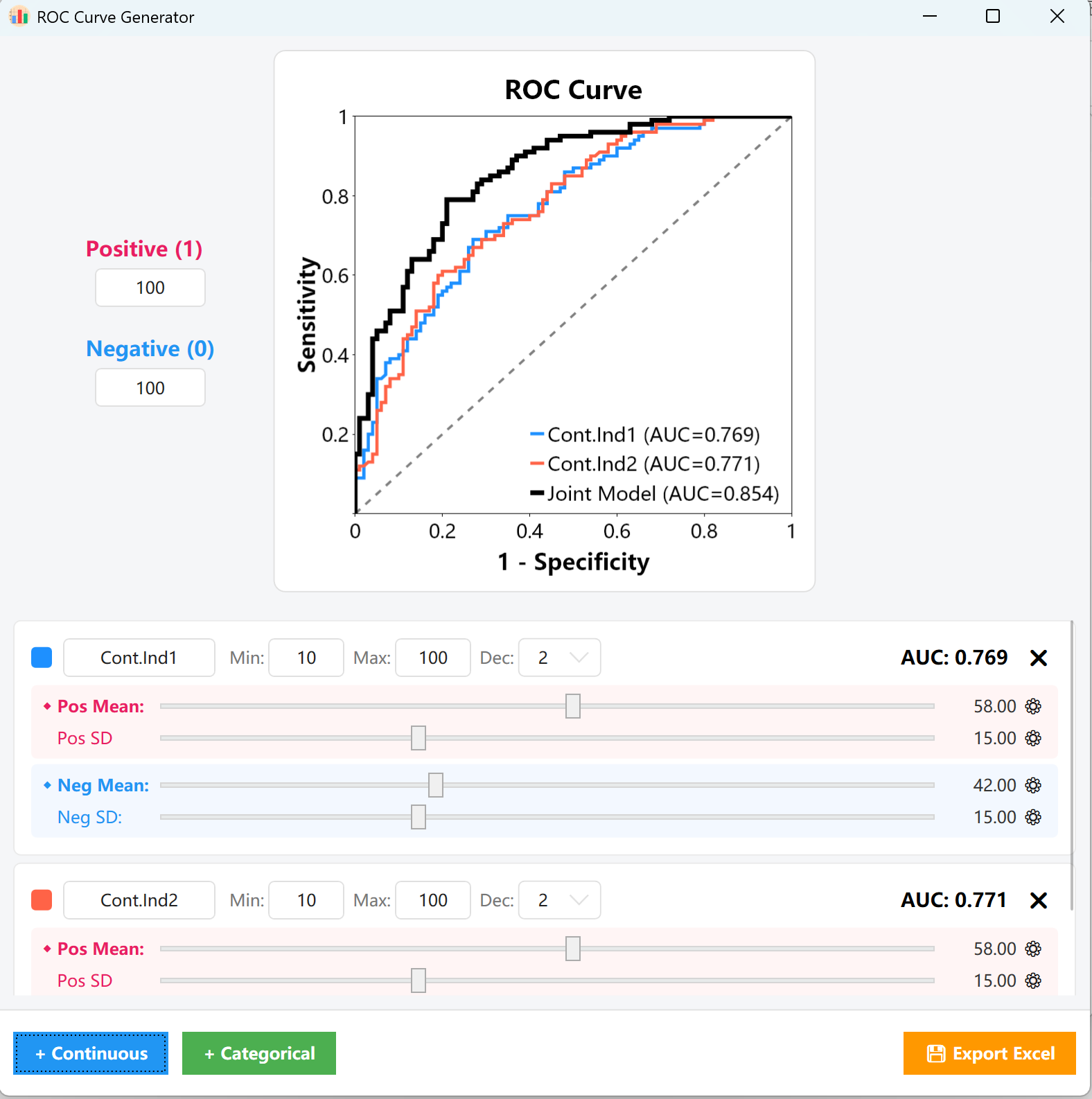
Figure 15.2 : Interfaz de usuario / Mostrar el trazado de la curva ROC
16. Guardado y exportación de los parámetros configurados
Para racionalizar las tareas de modelado repetitivas y evitar errores de configuración manual, la aplicación ofrece un mecanismo potente de preservación del estado de configuración.
16.1 Guardar y restaurar
- Exportar la configuración: Vaya al menú File → Export Configuration para guardar todos sus parámetros configurados, definiciones de variables, estructuras de grupos y objetivos en un archivo de configuración local en formato `.json` en su ordenador.
- Importar la configuración: Para restaurar su entorno en una sesión futura, simplemente vaya al menú File → Import Configuration y seleccione su archivo de configuración guardado previamente. El espacio de trabajo recribirá inmediatamente todas las tarjetas de variables, controles deslizantes y valores de parámetros.