Documentação e Guia do Utilizador
Bem-vindo à documentação oficial do DataSynth Pro. Este manual abrangente fornece orientações detalhadas sobre a configuração de parâmetros para vários módulos estatísticos para sintetizar conjuntos de dados robustos, academicamente viáveis e estatisticamente válidos totalmente offline.
1. Gerar Múltiplos Indicadores Simultaneamente
1.1 Pré-requisitos e Inicialização
Clique duas vezes no ficheiro executável para iniciar a aplicação. O software requer o Microsoft .NET 8.0 Runtime Framework. Se este não estiver instalado no seu computador, siga as instruções para o descarregar e instalar, e depois reabra o programa.
Aviso de Segurança: Se o seu software antivírus sinalizar o executável como um falso positivo, adicione-o à sua lista de exclusão ou de permissões locais para garantir o funcionamento ininterrupto.
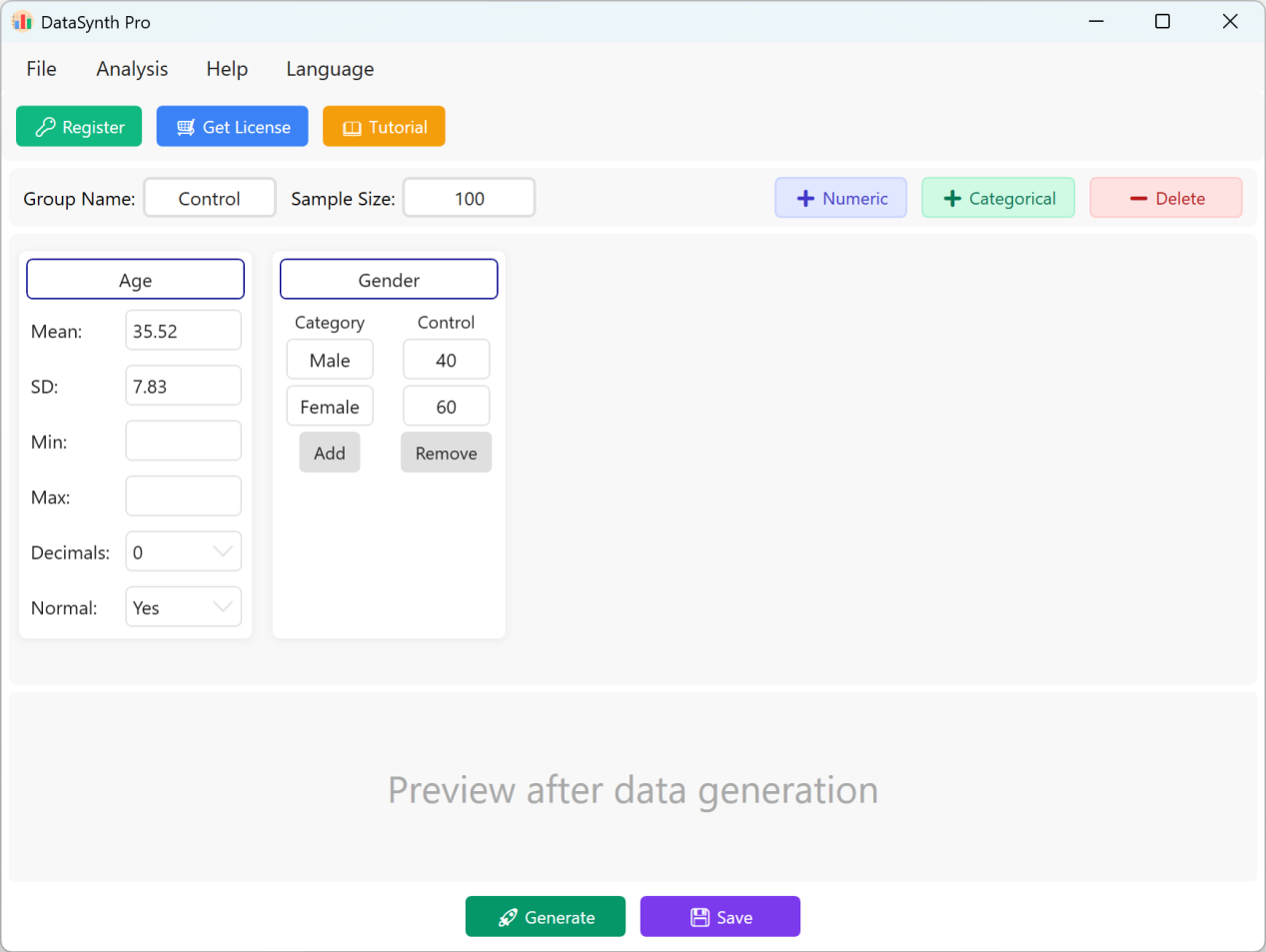
Figura 1.1: Interface do Utilizador / Operações (Interface Principal)
1.2 Configuração de Parâmetros
Por padrão, a aplicação pré-preenche duas variáveis contínuas, 'Age' (Idade) e 'Gender' (Género), para servir como referências rápidas. A designação do grupo padrão é 'Control Group' (Grupo de Controlo), e o tamanho da amostra é definido para '100' casos. Se o seu estudo necessitar de múltiplos grupos, pode gerar e exportar sequencialmente o conjunto de dados de cada grupo atualizando os parâmetros em cada execução.
- Adicionar Variáveis Numéricas Contínuas: Para adicionar uma nova variável quantitativa, clique no botão + Numeric. Pode então especificar o Nome do Indicador (ex: 'Body Mass Index' ou 'BMI'), Média, Desvio Padrão e Casas Decimais. Os campos de limites Mínimo e Máximo são opcionais e podem ser deixados em branco se não tiver limitações de valores específicas.
- Definições de Distribuição de Dados: Por padrão, as métricas numéricas geradas seguem uma distribuição normal. Se necessitar de dados não distribuídos normalmente, basta definir a opção Normal Distribution como No.
Ajuste da Distribuição: Uma distribuição normal baseia-se num intervalo de variância natural; restringir os limites Mínimo e Máximo demasiado estreitamente truncará a curva normal e poderá resultar em valores não distribuídos normalmente. Se isto ocorrer, tente alargar os limites ou remover os limites Mín/Máx inteiramente.
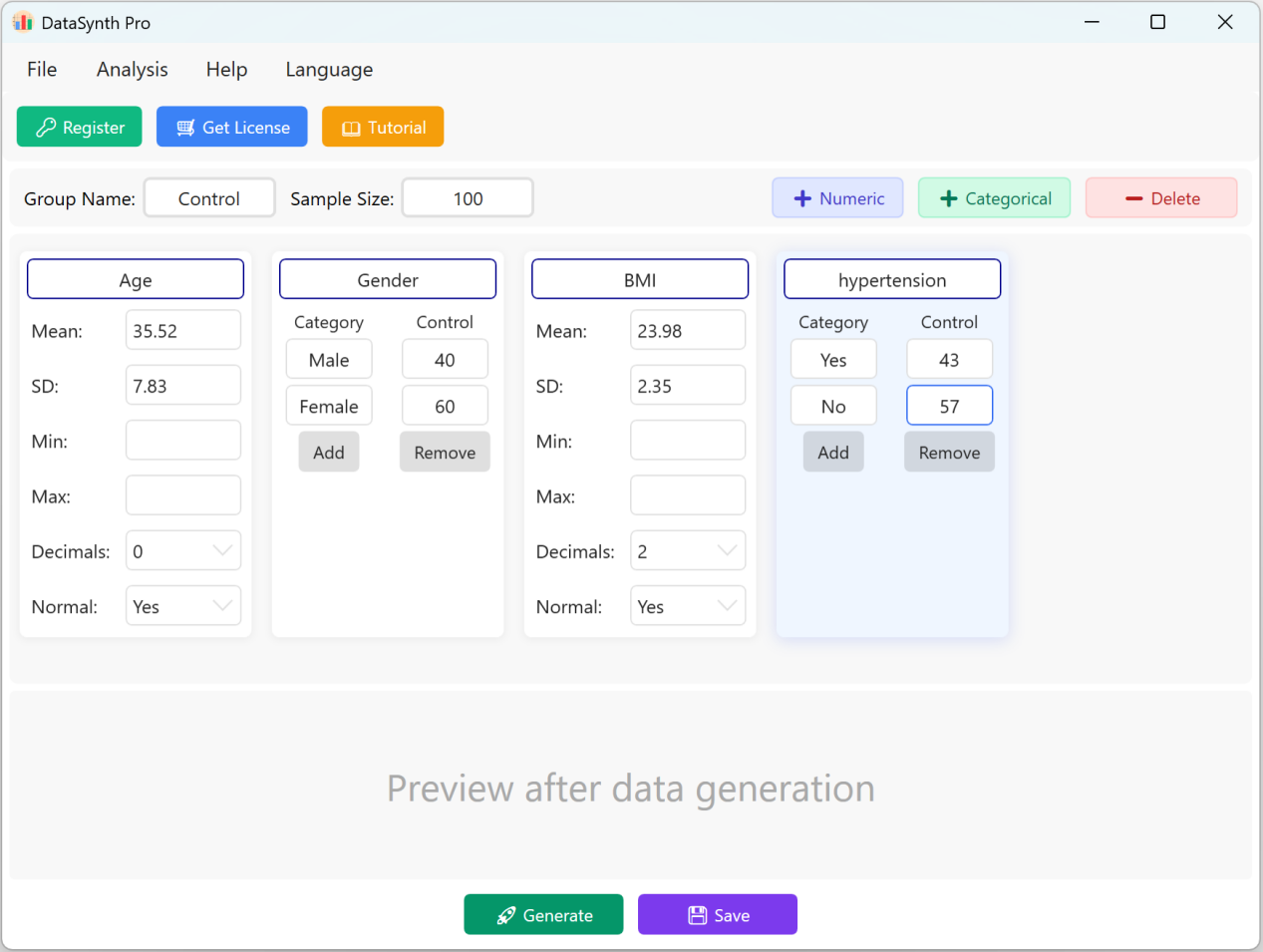
Figura 1.2: Interface do Utilizador / Operações para Adicionar Variáveis
1.3 Adicionar Variáveis Categóricas
Clique no botão + Categorical para continuar a adicionar variáveis qualitativas (ex: 'Hipertensão'). Pode introduzir nomes de categorias e as suas respetivas distribuições ou proporções alvo. A soma das proporções categóricas será redimensionada dinamicamente para corresponder ao tamanho da amostra configurado.
1.4 Executar Geração
Clique no botão Generate para sintetizar o número de registos solicitado. Uma vez calculado, surgirá uma janela de resumo de estatísticas descritivas, permitindo-lhe verificar se os valores gerados reais se alinham com os parâmetros configurados.
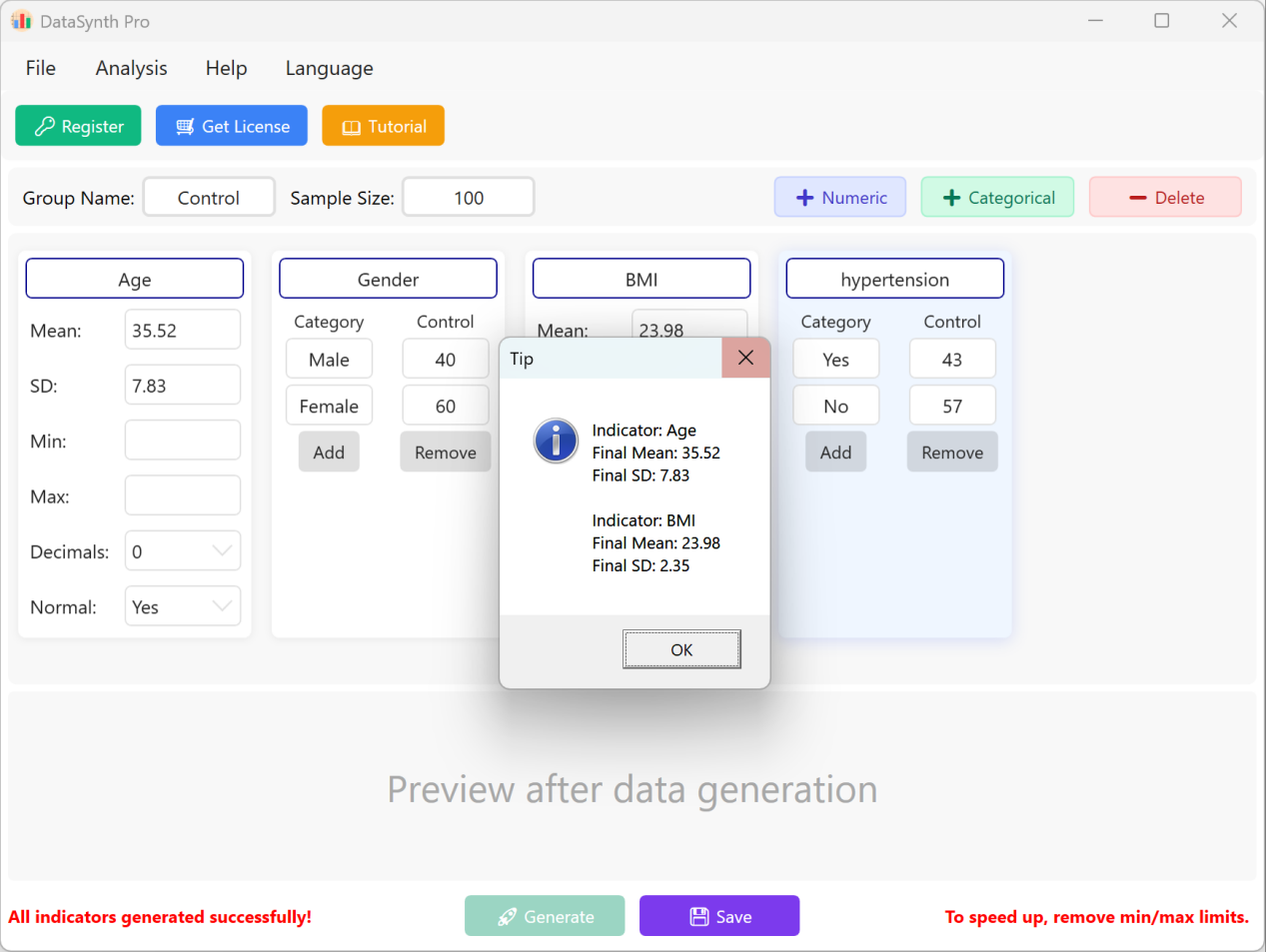
Figura 1.3: Interface do Utilizador / Operações para Executar Geração
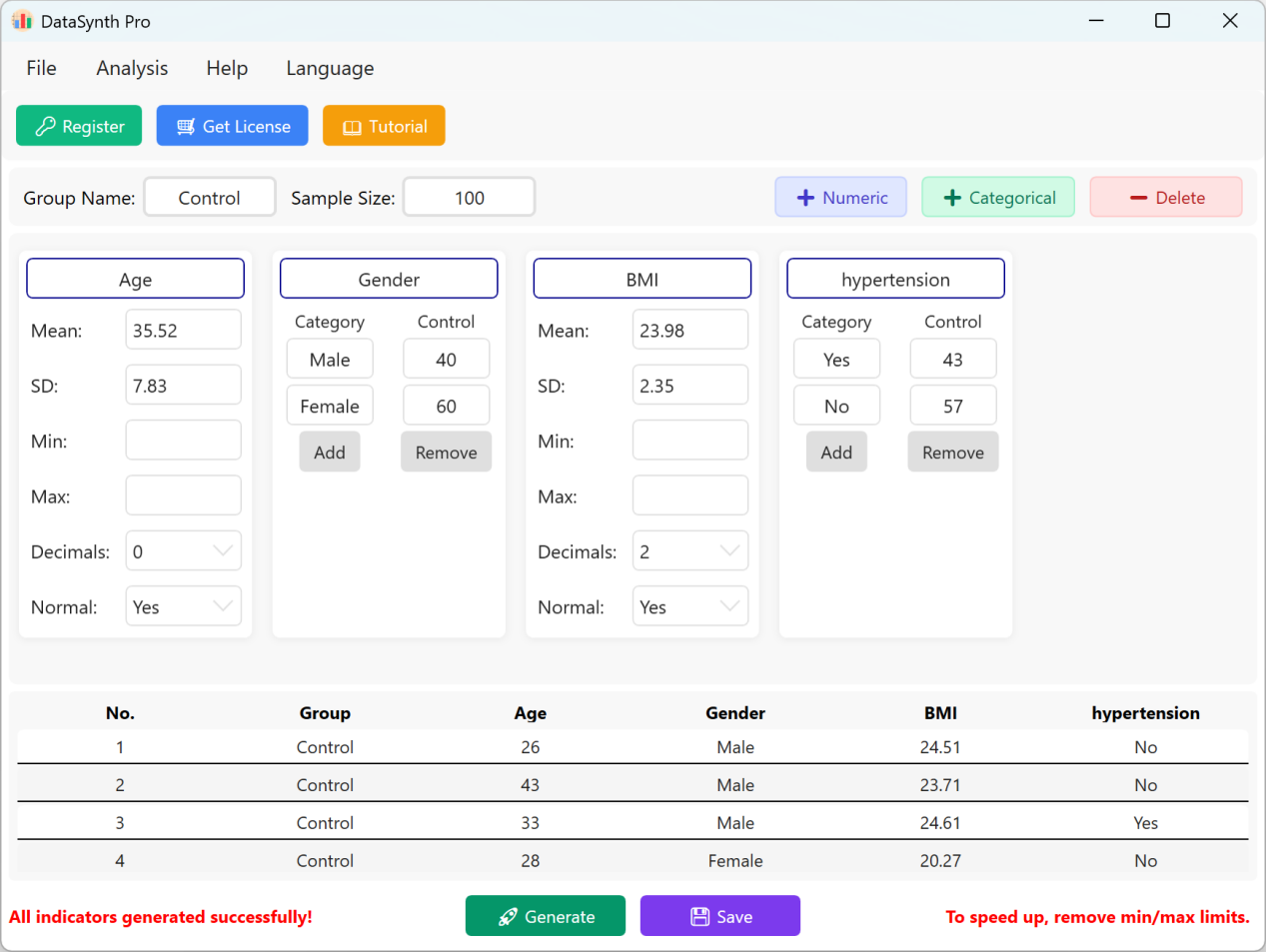
Figura 1.4: Interface do Utilizador / Operações para Apresentar Dados
1.5 Exportar e Verificar
Clique no botão Save para exportar o conjunto de dados gerado como um ficheiro Excel padrão. Se abrir a folha de cálculo exportada e calcular as estatísticas descritivas para a variável 'Age' (arredondada a duas casas decimais) usando fórmulas padrão do Excel, a média e o desvio padrão gerados reais corresponderão perfeitamente aos seus parâmetros configurados.
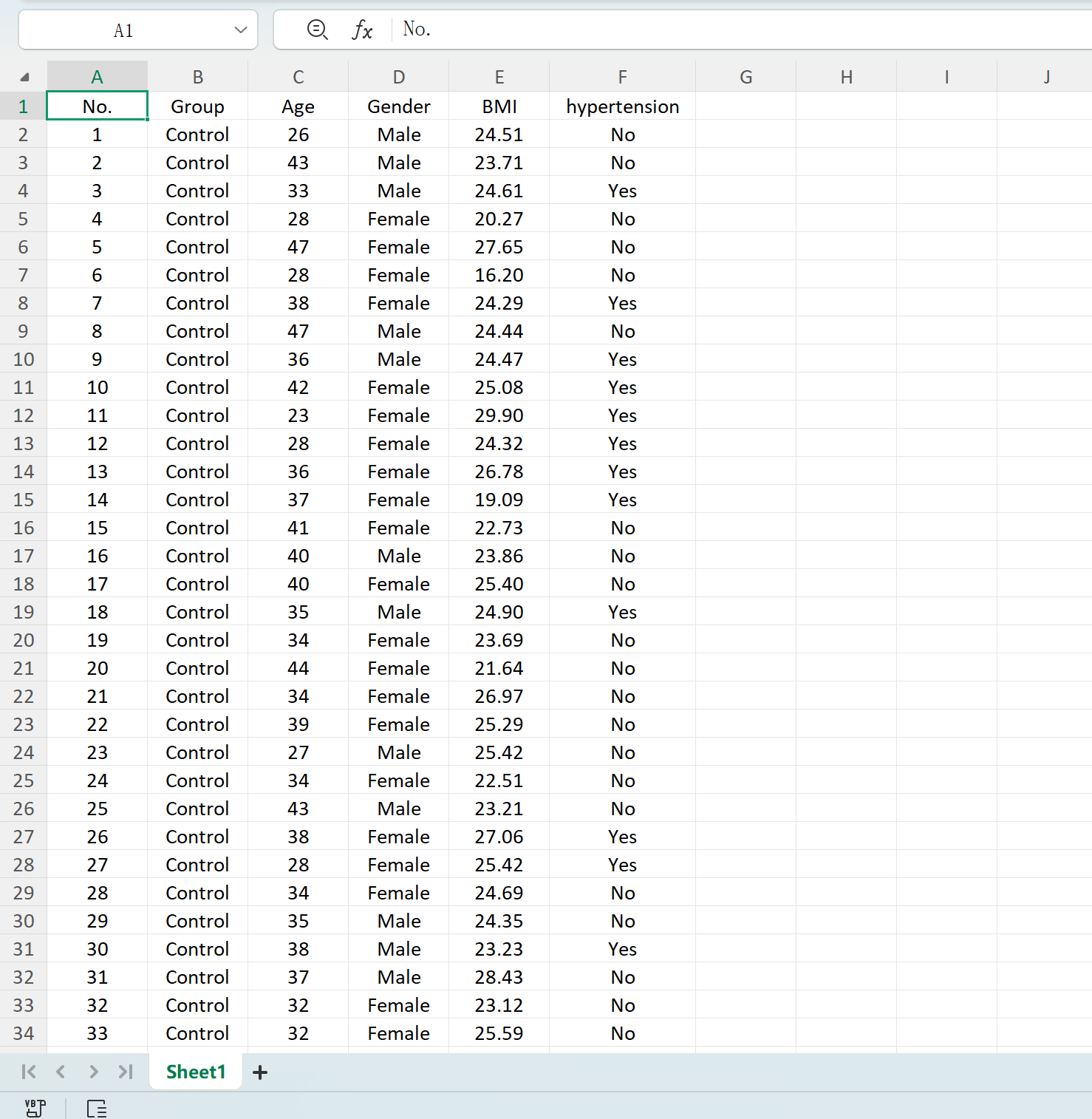
Figura 1.5: Exportar Tabelas Geradas para o Excel
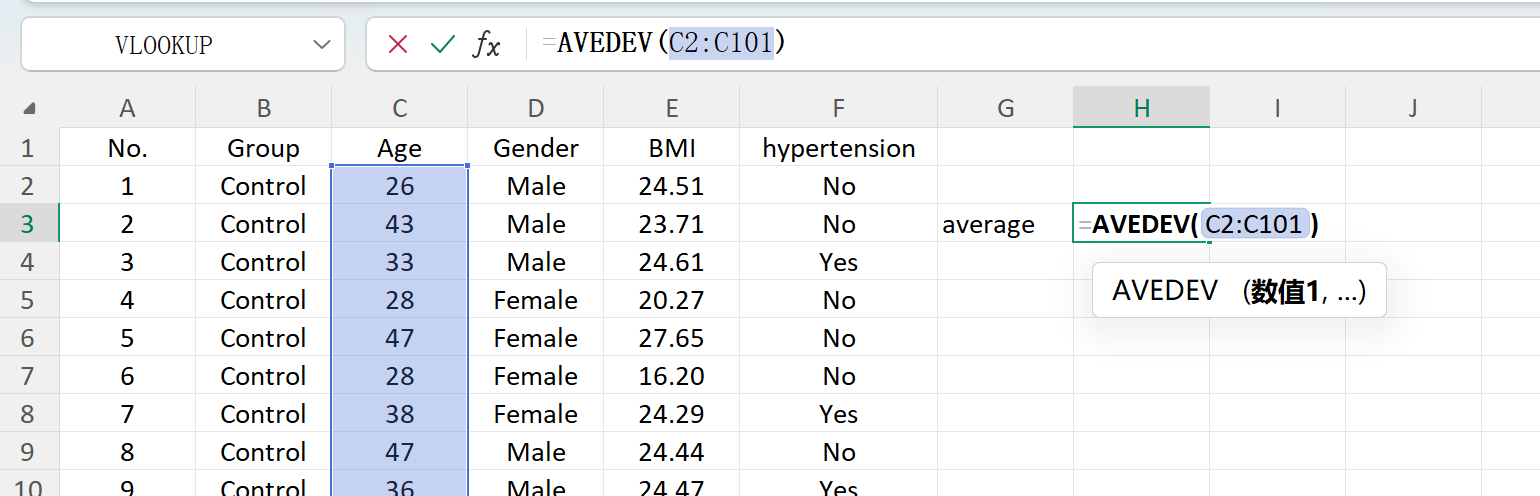
Figura 1.6: Calcular a Média no Excel
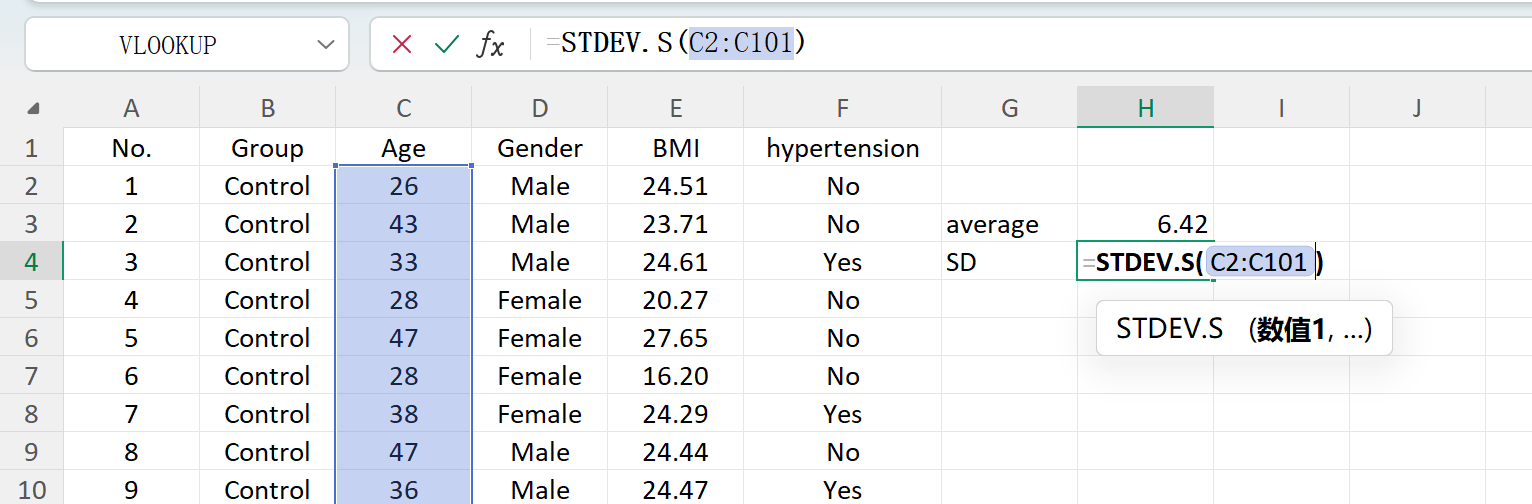
Figura 1.7: Calcular o Desvio Padrão no Excel
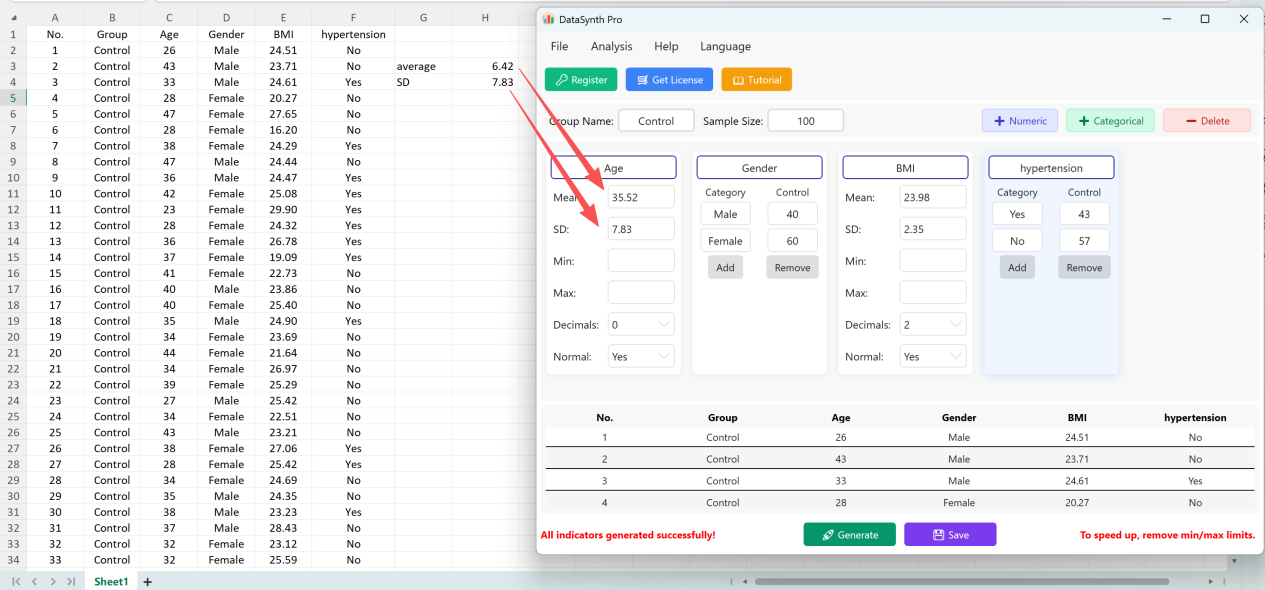
Figura 1.8: Resultados de Verificação Identificados com os Parâmetros Iniciais
1.6 Eficiência Algorítmica
Equipado com um motor de otimização de alto desempenho, o software pode gerar conjuntos de dados contendo milhares ou dezenas de milhares de registos em apenas alguns segundos. Se o sistema não convergir após o número máximo de iterações, verifique a consistência estatística da sua configuração ou tente executar a geração sem limites Mín/Máx. O programa suporta precisão decimal de até 8 dígitos para atender a necessidades especializadas de investigação científica.
Conselhos e recomendações:
• Preferência de Distribuição Normal: Por padrão, os dados seguem uma distribuição normal para análise subsequente fluida (ex: Testes t para amostras independentes). Se preferir conjuntos de dados não paramétricos ou de distribuição personalizada, basta alterar o parâmetro Normal Distribution para No.
2. Teste t para Amostras Independentes
Concebido para estudos transversais que comparam as médias de dois grupos distintos. Amplamente utilizado em ensaios clínicos (ex: comparar a eficácia de um tratamento entre um grupo de Tratamento e um grupo de Placebo) e inquéritos sociológicos.
2.1 Fluxo de Trabalho
Aceda a Analyze → Independent T-Test. A janela de configuração é apresentada da seguinte forma:
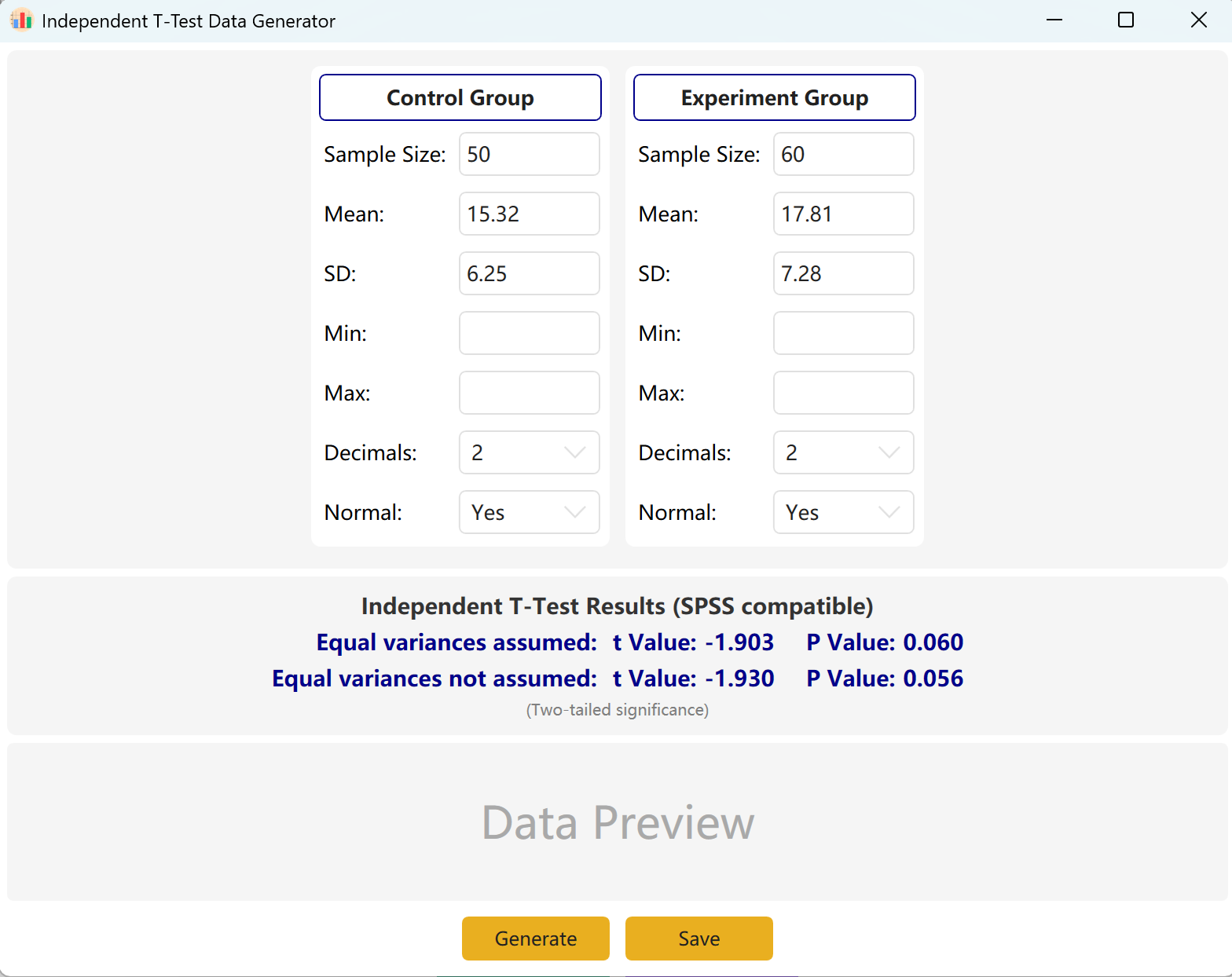
Figura 2.1: Interface do Utilizador / Operações para o Teste t Independente
2.2 Parâmetros
O programa pré-preenche exemplos para um 'Control Group' (Grupo de Controlo) e um 'Experimental Group' (Grupo Experimental) para referência rápida. Introduza o tamanho da amostra, média e desvio padrão de cada grupo para pré-visualizar instantaneamente o valor t e o valor p em tempo real. Os parâmetros de Mín e Máx são opcionais.
Clique no botão Generate para criar os conjuntos de dados brutos de ambos os grupos na tabela de pré-visualização abaixo. Os valores finais de t e p serão ajustados automaticamente para refletir os dados gerados de facto usando o teste de igualdade de variâncias de Levene.
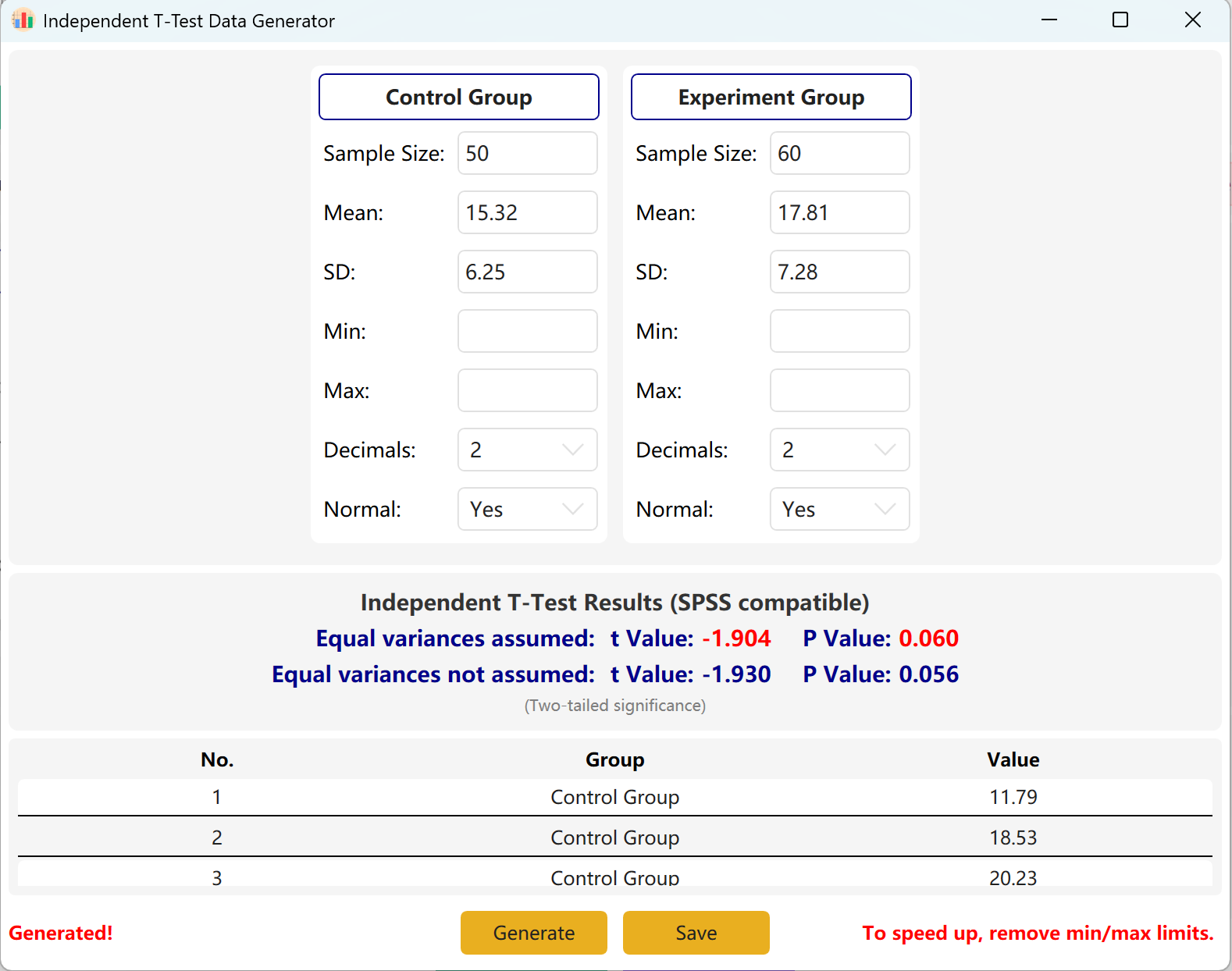
Figura 2.2: Interface do Utilizador / Apresentação de Dados do Teste t para Amostras Independentes
3. Teste t para Amostras Emparelhadas
Empregado em estudos longitudinais ou cruzados onde os mesmos sujeitos são medidos vezes (ex: Pré-teste vs Pós-teste). Foca-se em sintetizar a diferença média entre observações emparelhadas.
3.1 Fluxo de Trabalho
Aceda a Analyze → Paired T-Test. O espaço de trabalho está estruturado da seguinte forma:
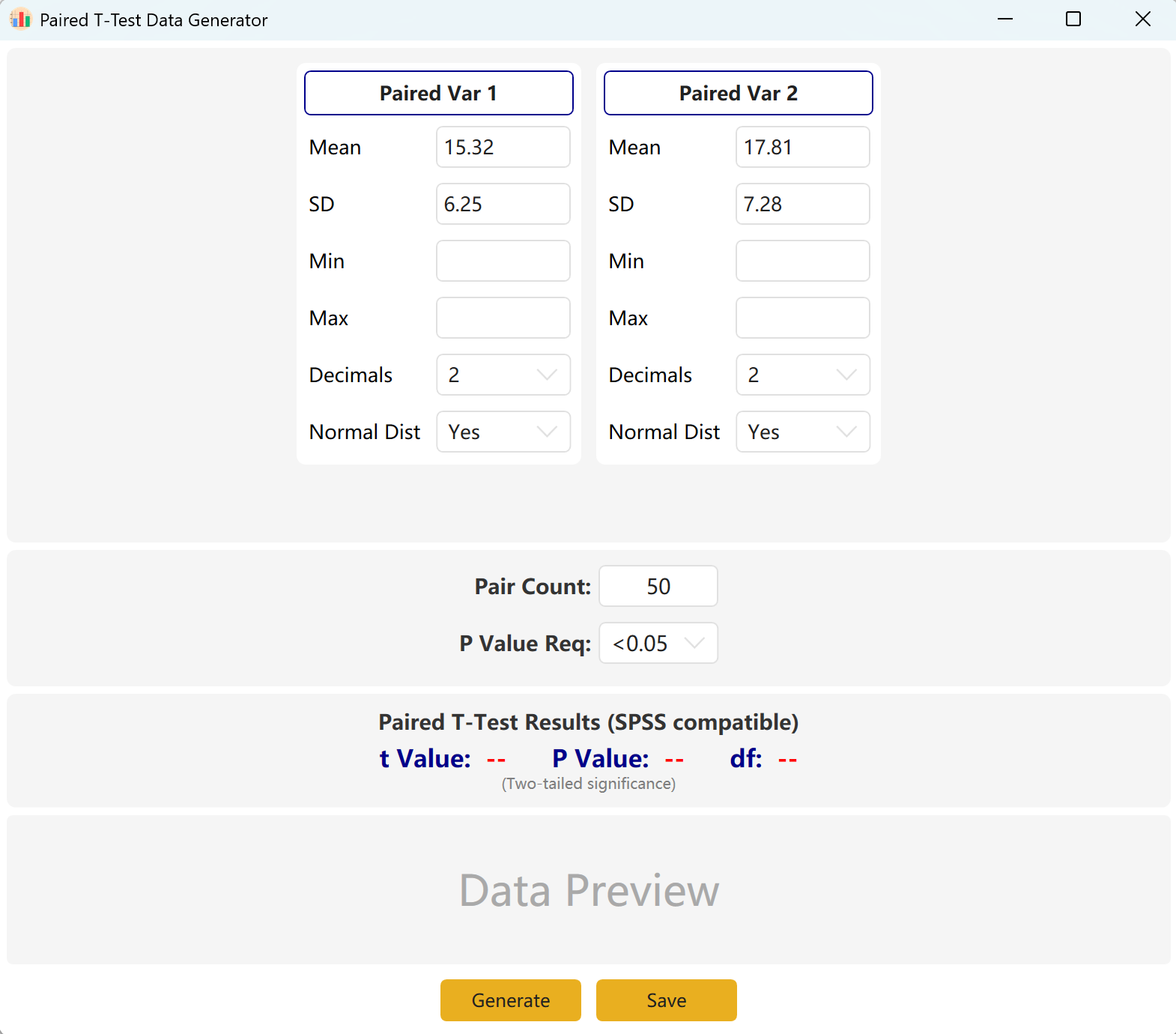
Figura 3.1: Interface do Utilizador / Operações para o Teste t Emparelhado
3.2 Lógica de Simulação
O software configura por padrão duas variáveis emparelhadas, Paired Var1 e Paired Var2. Pode definir a média e o desvio padrão de cada variável, definir o tamanho global da amostra e estabelecer um intervalo de valor p alvo para o teste t emparelhado. O motor calculará então iterativamente um conjunto de dados em conformidade.
Adaptação de Convergência: Se as médias configuradas forem matematicamente incompatíveis com o valor p alvo (por exemplo, se as duas médias estiverem muito distantes, mas solicitar um valor p não significativo p > 0,05), o programa manterá os parâmetros do primeiro grupo e ajustará dinamicamente a média do segundo grupo para atingir o valor p pretendido.
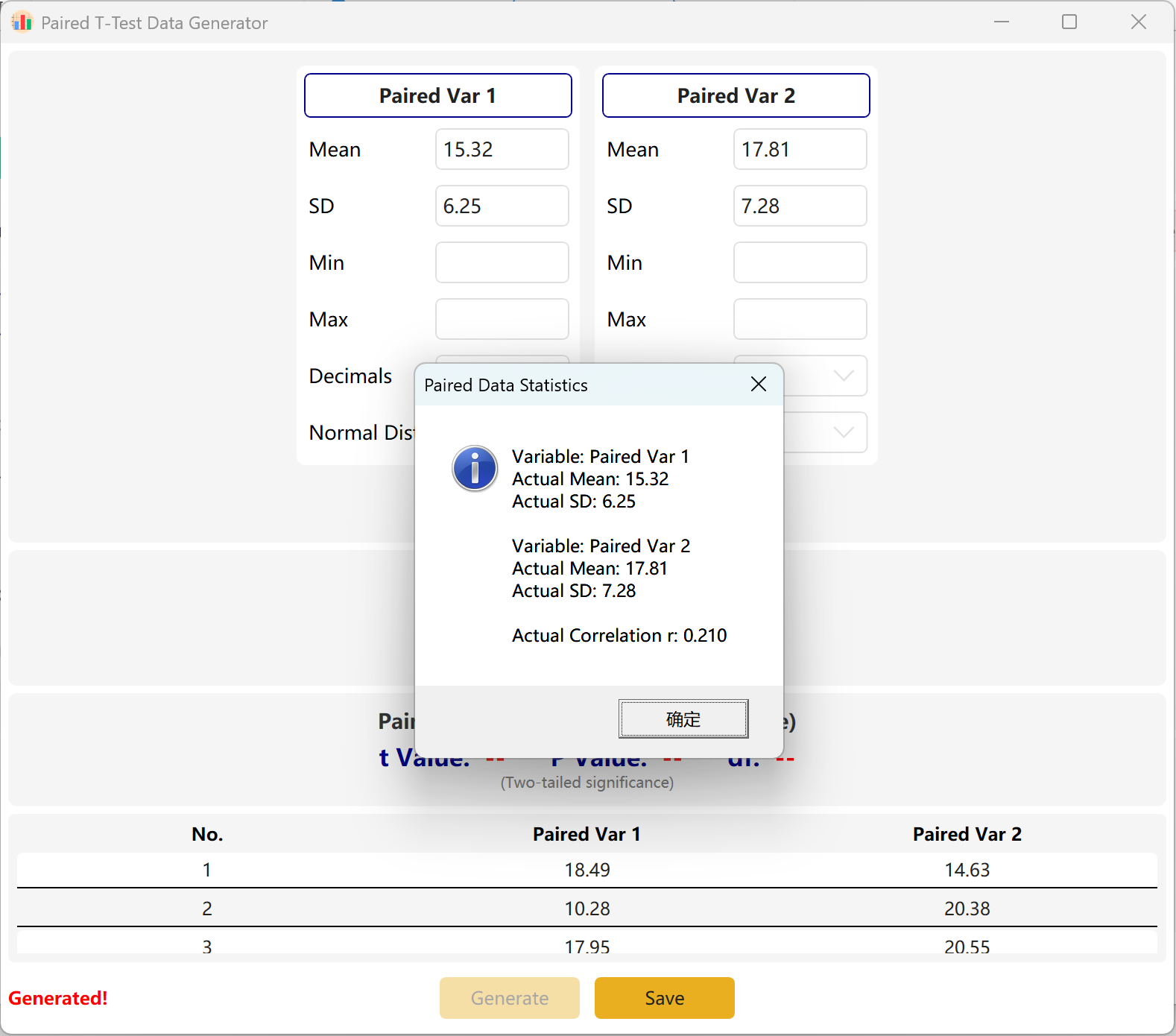
Figura 3.2: Interface do Utilizador / Apresentação de Dados do Teste t para Amostras Emparelhadas
4. Teste do Qui-Quadrado
Permite determinar se existe uma associação significativa entre duas variáveis categóricas. Amplamente utilizado em cruzamentos de dados demográficos.
4.1 Fluxo de Trabalho
Aceda a Analyze → Chi-Square Test. O painel de configuração apresenta-se da seguinte forma:
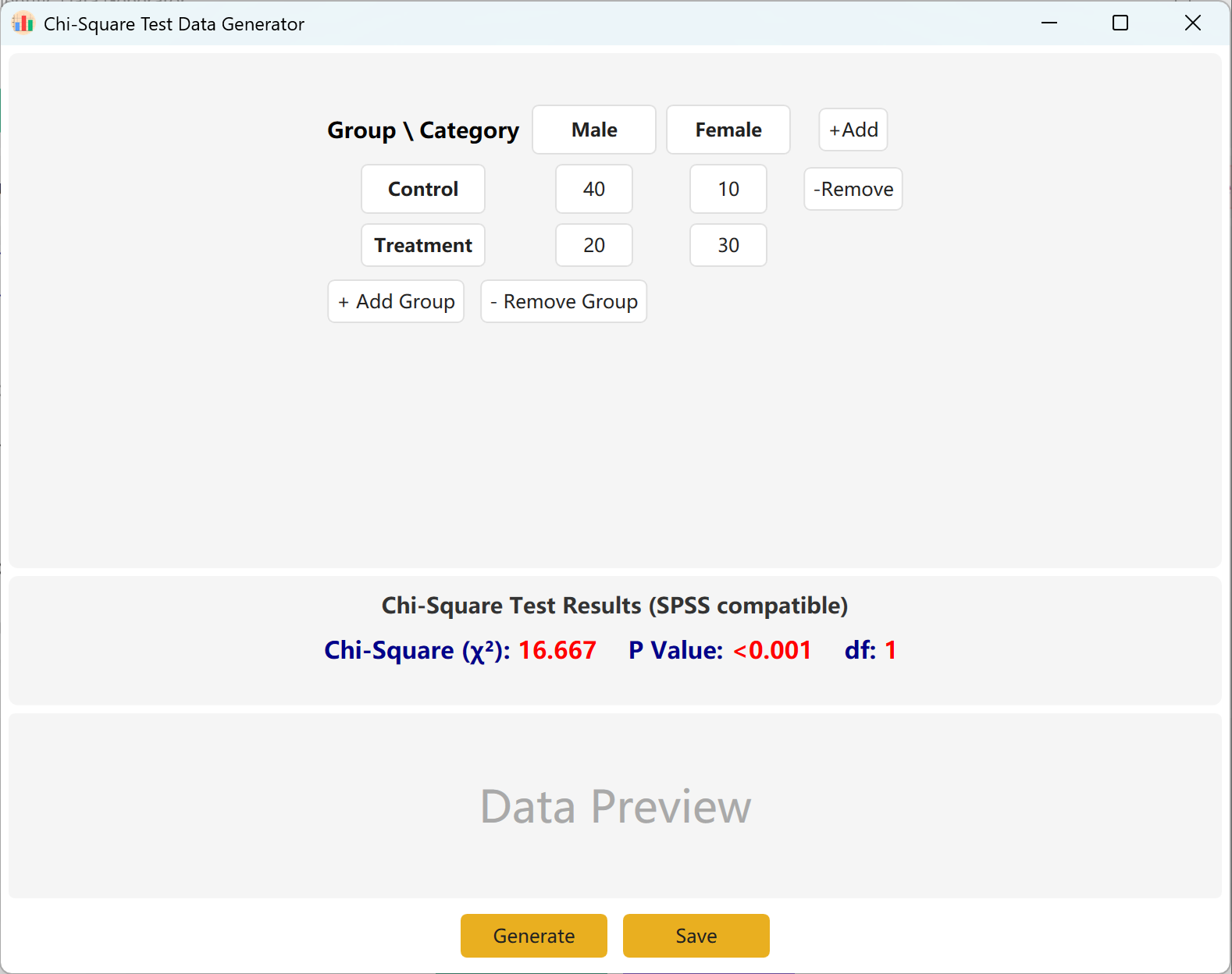
Figura 4.1: Interface do Utilizador / Operações para o Teste do Qui-Quadrado
4.2 Tabela de Contingência
A interface oferece por padrão uma tabela de contingência 2x2 padrão para o cálculo do Qui-Quadrado, onde os nomes dos grupos e categorias são totalmente editáveis. Preencha as frequências observadas (contagens) para cada célula, e o valor calculado do Qui-Quadrado e o valor p serão atualizados em tempo real.
Pode adicionar dinamicamente grupos (linhas) ou categorias (colunas) para adaptar modelos mais complexos. Clique no botão Generate para produzir os registos individuais correspondentes a essas frequências, e depois clique em Save para exportar o conjunto de dados para o Excel.
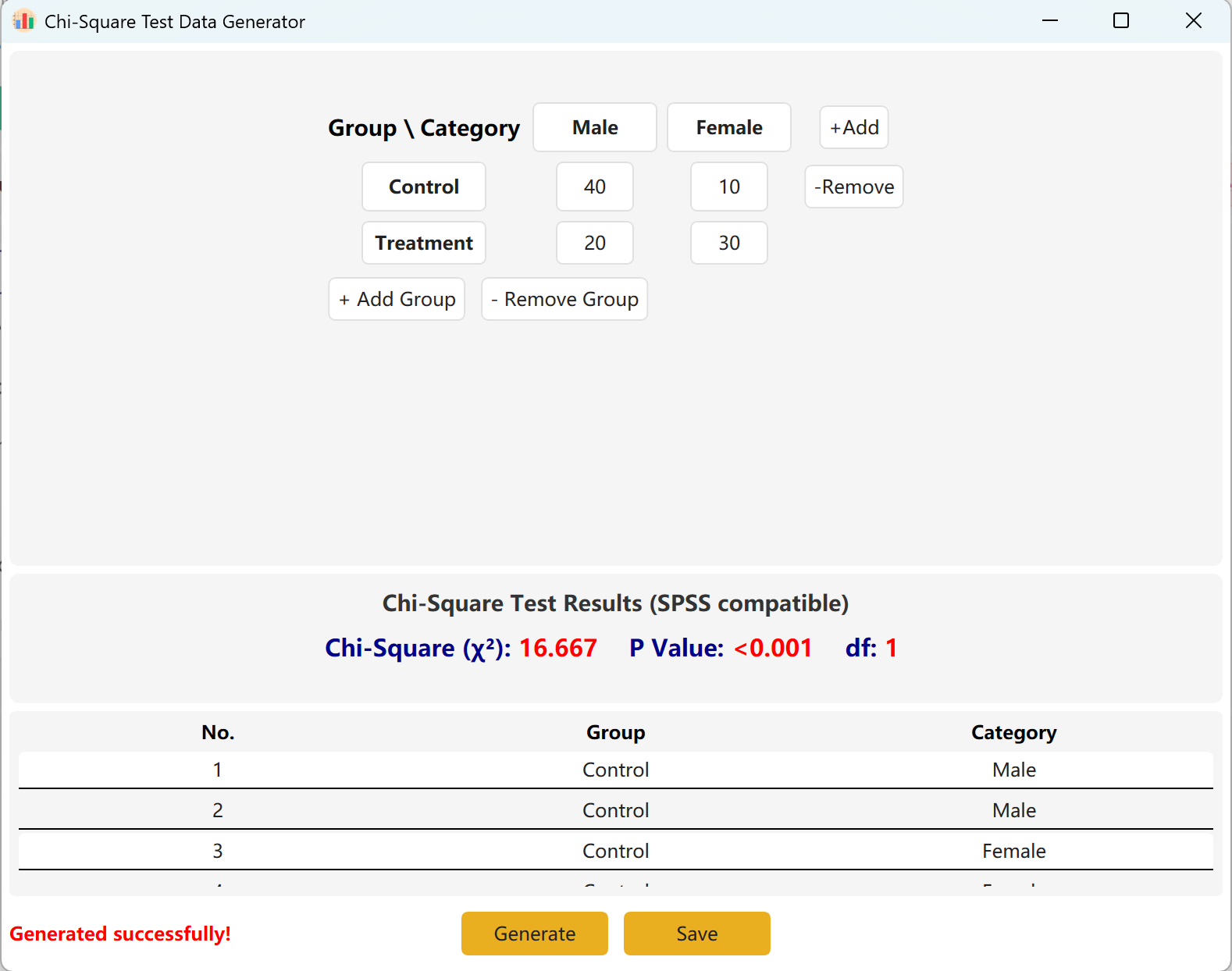
Figura 4.2: Interface do Utilizador / Apresentação de Dados do Teste do Qui-Quadrado
5. ANOVA de uma via
Utilizado para comparar as médias de três ou mais grupos independentes. O algoritmo sintetiza a variância dentro do grupo e as diferenças entre grupos para cumprir os valores F alvo.
5.1 Fluxo de Trabalho
Aceda a Analyze → ANOVA → One-Way ANOVA. O espaço de trabalho é apresentado abaixo:
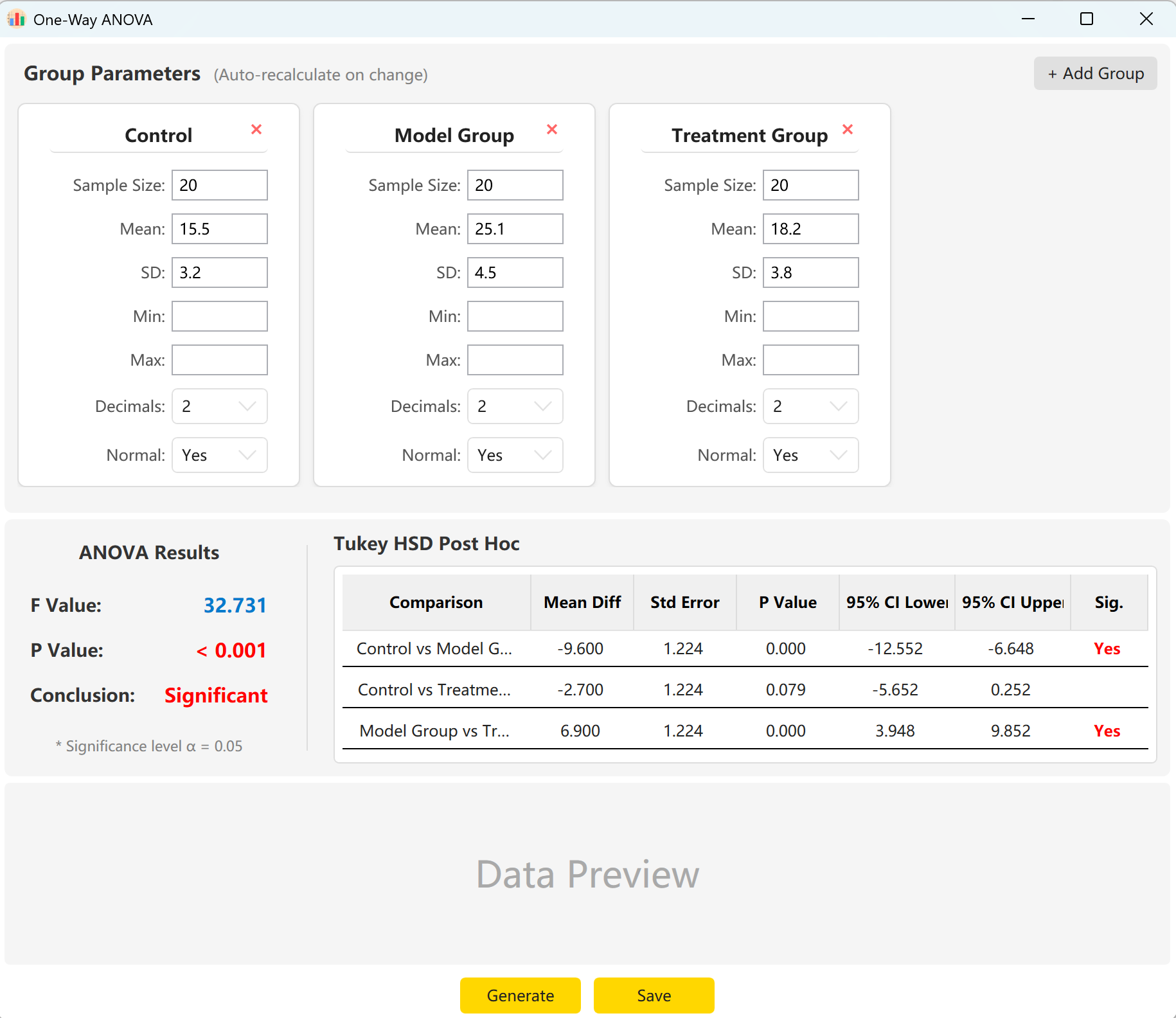
Figura 5.1: Interface do Utilizador / Operações para a ANOVA de uma via
5.2 Configuração
O sistema pré-carrega os parâmetros de três grupos: 'Control Group' (Grupo de Controlo), 'Experimental Group' (Grupo Experimental) e 'Treatment Group' (Grupo de Tratamento). Basta introduzir o tamanho da amostra, média e desvio padrão de cada grupo para visualizar instantaneamente a estatística global F, o valor p e os resultados da comparação múltipla post-hoc HSD de Tukey.
Clique no botão Generate para calcular e pré-visualizar os registos brutos individuais abaixo. Os valores globais F e p serão atualizados automaticamente para refletir os dados de facto gerados.
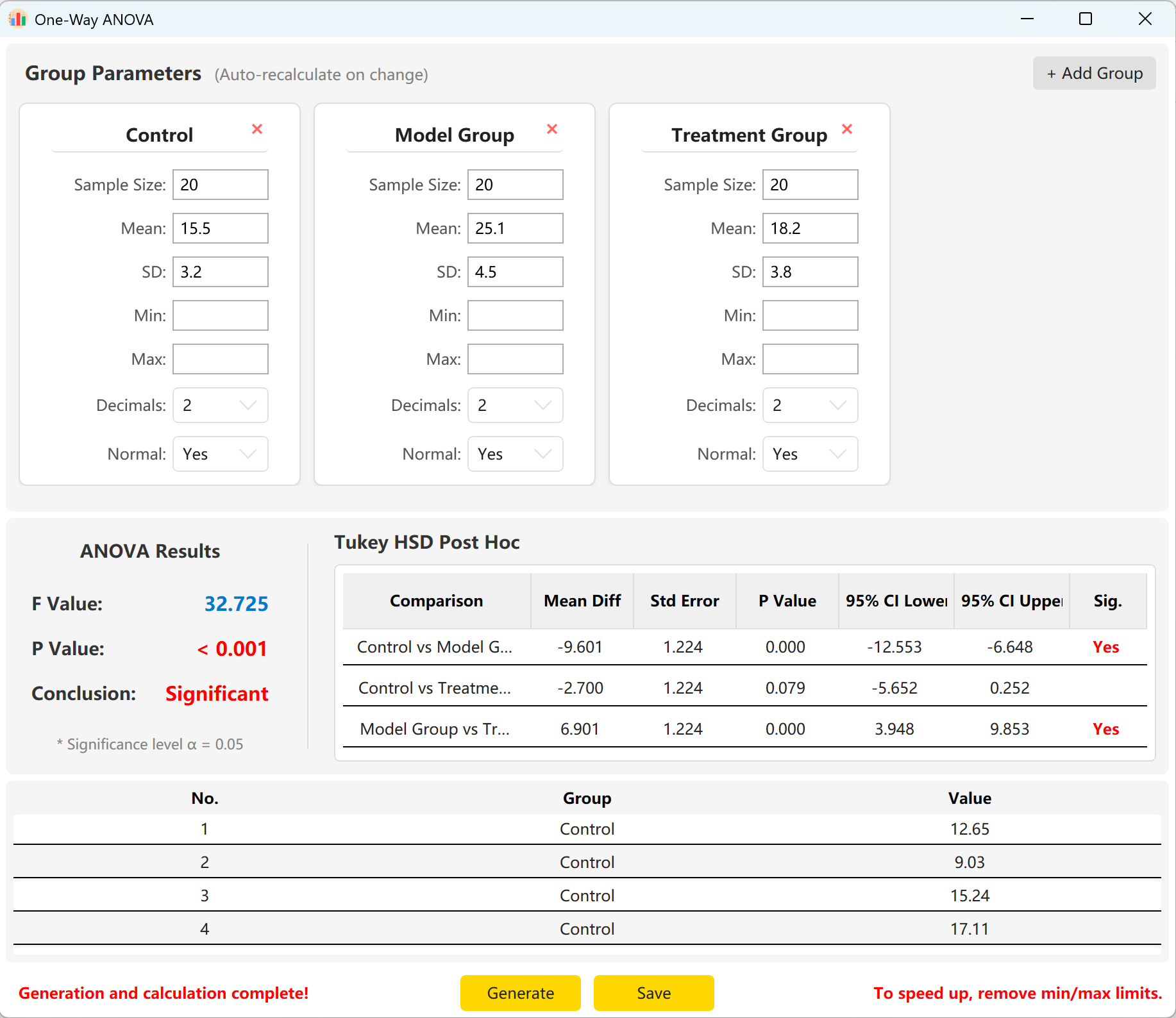
Figura 5.2: Interface do Utilizador / Apresentação de Dados da ANOVA de uma via
6. ANOVA de duas vias
Examina a influência de duas variáveis independentes categóricas numa variável dependente contínua. Essencial para desenhos fatoriais para avaliar os efeitos principais bem como os efeitos de interação.
6.1 Fluxo de Trabalho
Aceda a Analyze → ANOVA → Two-Way ANOVA. O painel de configuração apresenta-se da seguinte forma:
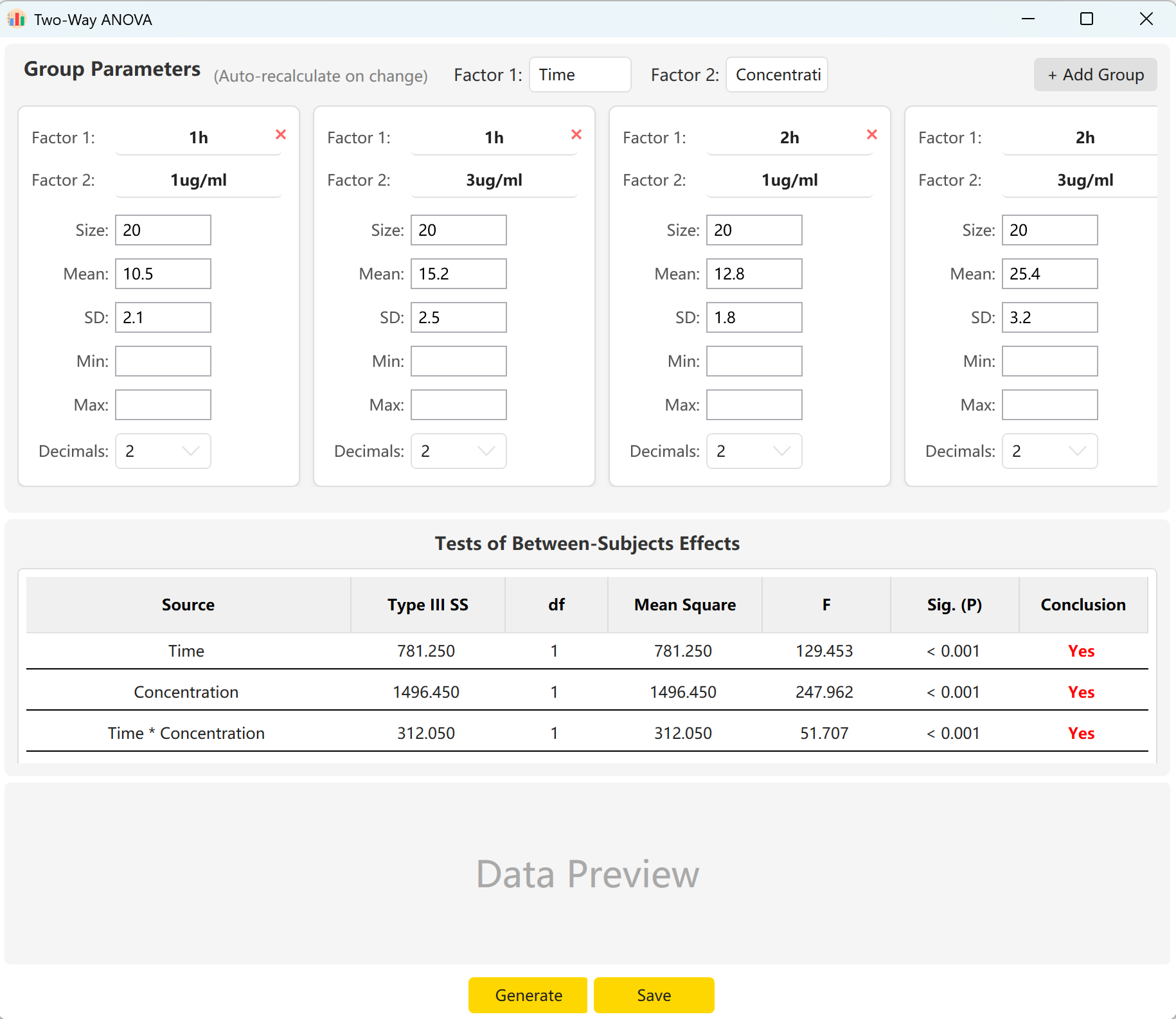
Figura 6.1: Interface do Utilizador / Operações para a ANOVA de duas vias
6.2 Fatores e Interações
A ferramenta vem configurada por padrão com dois fatores: 'Time' (Tempo - 2 níveis) e 'Concentration' (Concentração - 2 níveis). Clique em Add Group para configurar mais níveis se um dos seus fatores contiver múltiplas categorias.
Ao introduzir o tamanho da amostra, média e desvio padrão de cada célula, pode obter uma pré-visualização em tempo real das estatísticas F e valores p para o efeito principal do Tempo, o efeito principal da Concentração e o seu efeito de interação (Tempo × Concentração). Clique no botão Generate para criar os registos brutos correspondentes no painel de pré-visualização.
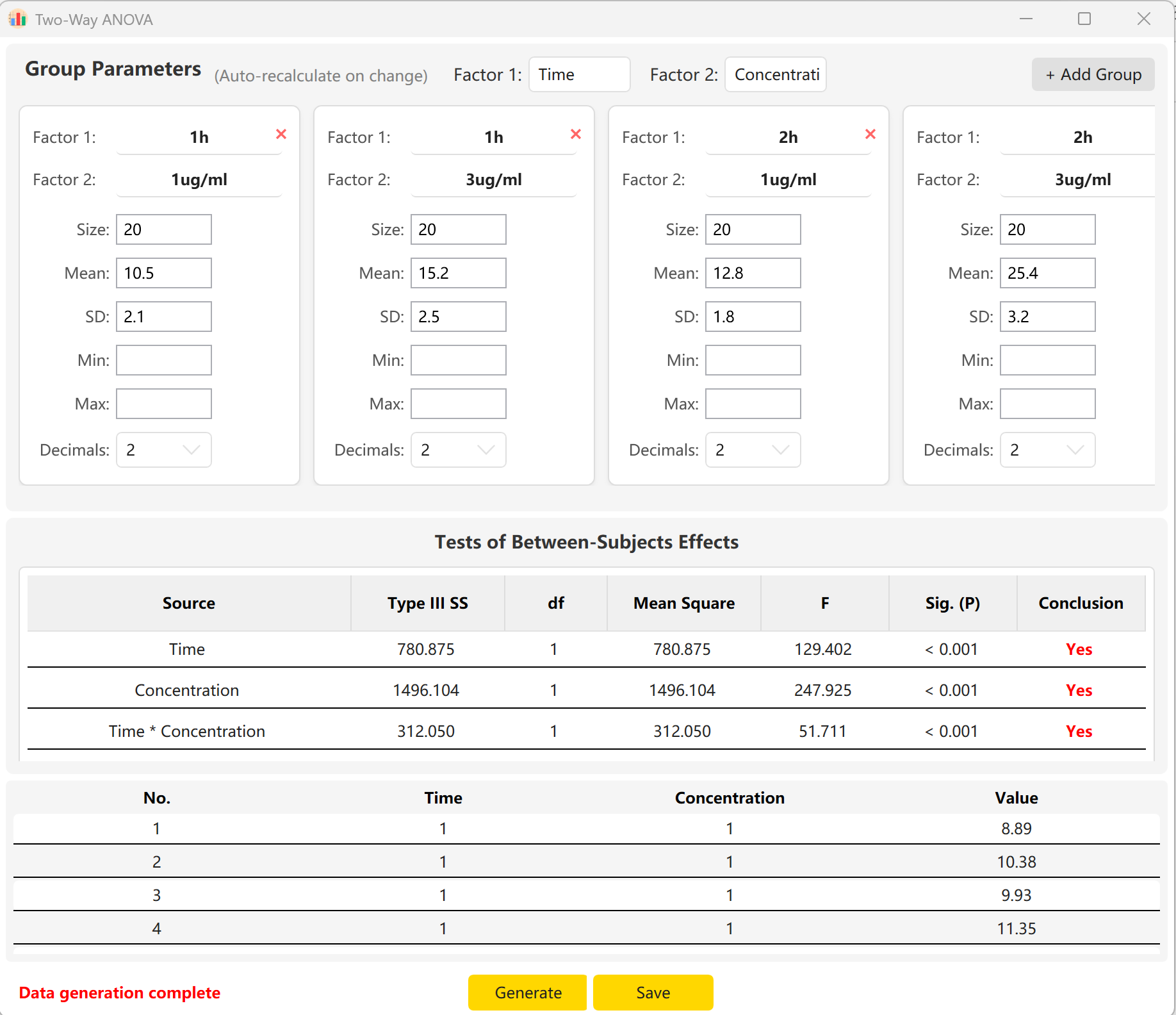
Figura 6.2: Interface do Utilizador / Apresentação de Dados da ANOVA de duas vias
7. ANOVA de Medidas Repetidas de uma via
A extensão do Teste t emparelhado para três ou mais pontos de observação. Ideal para monitorização longitudinal ao longo de períodos prolongados (ex: linha de base, mês 1, mês 3).
7.1 Fluxo de Trabalho
Aceda a Analyze → ANOVA → Repeated Measures ANOVA. O espaço de trabalho é apresentado abaixo:
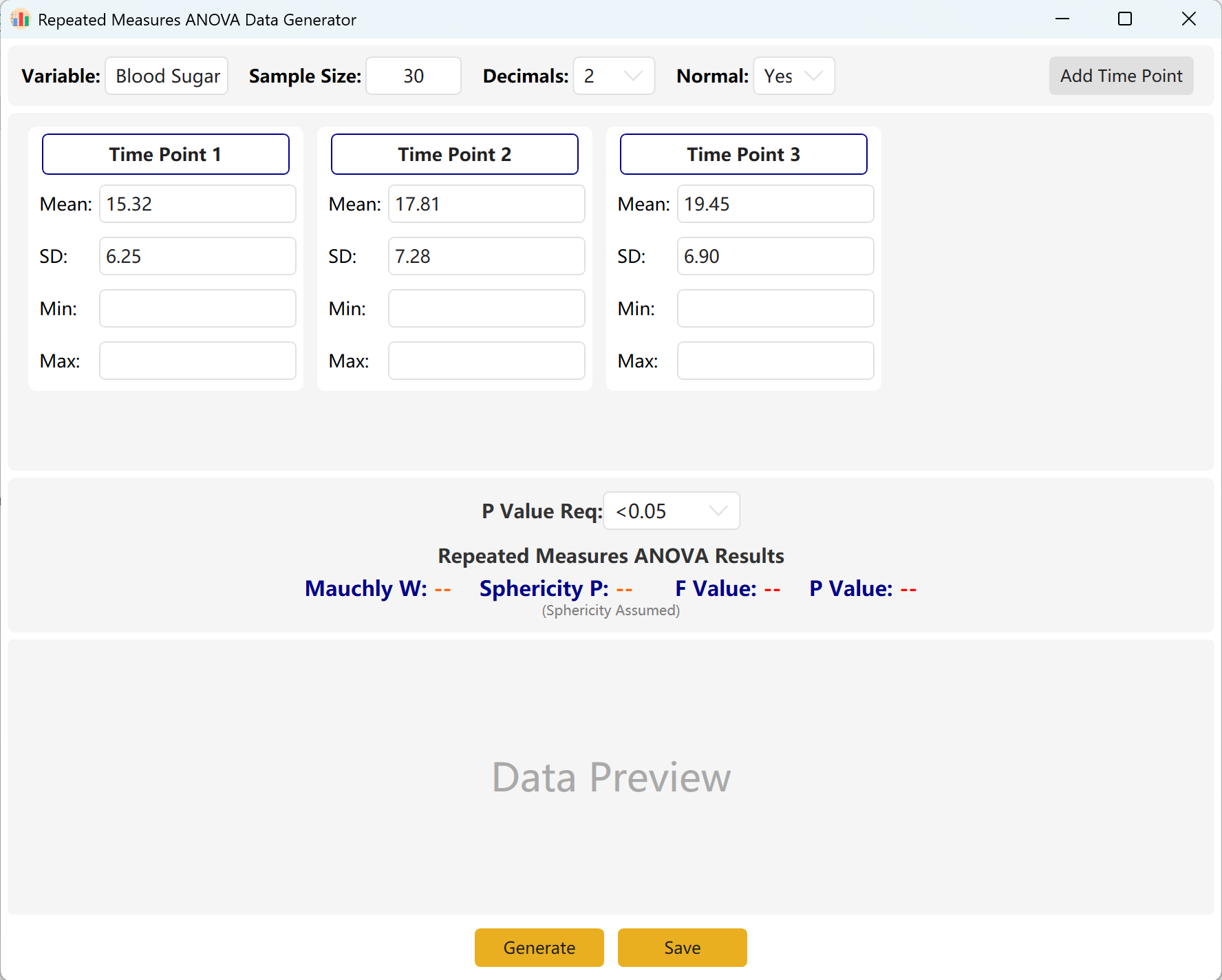
Figura 7.1: Interface do Utilizador / Operações para a ANOVA de Medidas Repetidas de uma via
7.2 Observações Repetidas
O sistema está configurado por padrão com três pontos de observação temporais. Pode facilmente aumentar este número clicando no botão Add Time Point. Introduza a média e o desvio padrão de cada ponto de observação e defina o seu intervalo de valor p alvo.
Clique no botão Generate para sintetizar valores em conformidade.
Adaptação de Variância do Motor: Se a diferença entre os pontos de observação for matematicamente enorme (indicando um valor p extremamente significativo) enquanto o seu alvo for p > 0,05, o motor comprimirá automaticamente as variâncias e diferenças de médias entre os pontos temporais para atingir precisamente o seu alvo. Uma caixa de diálogo exibirá as estatísticas reais obtidas.
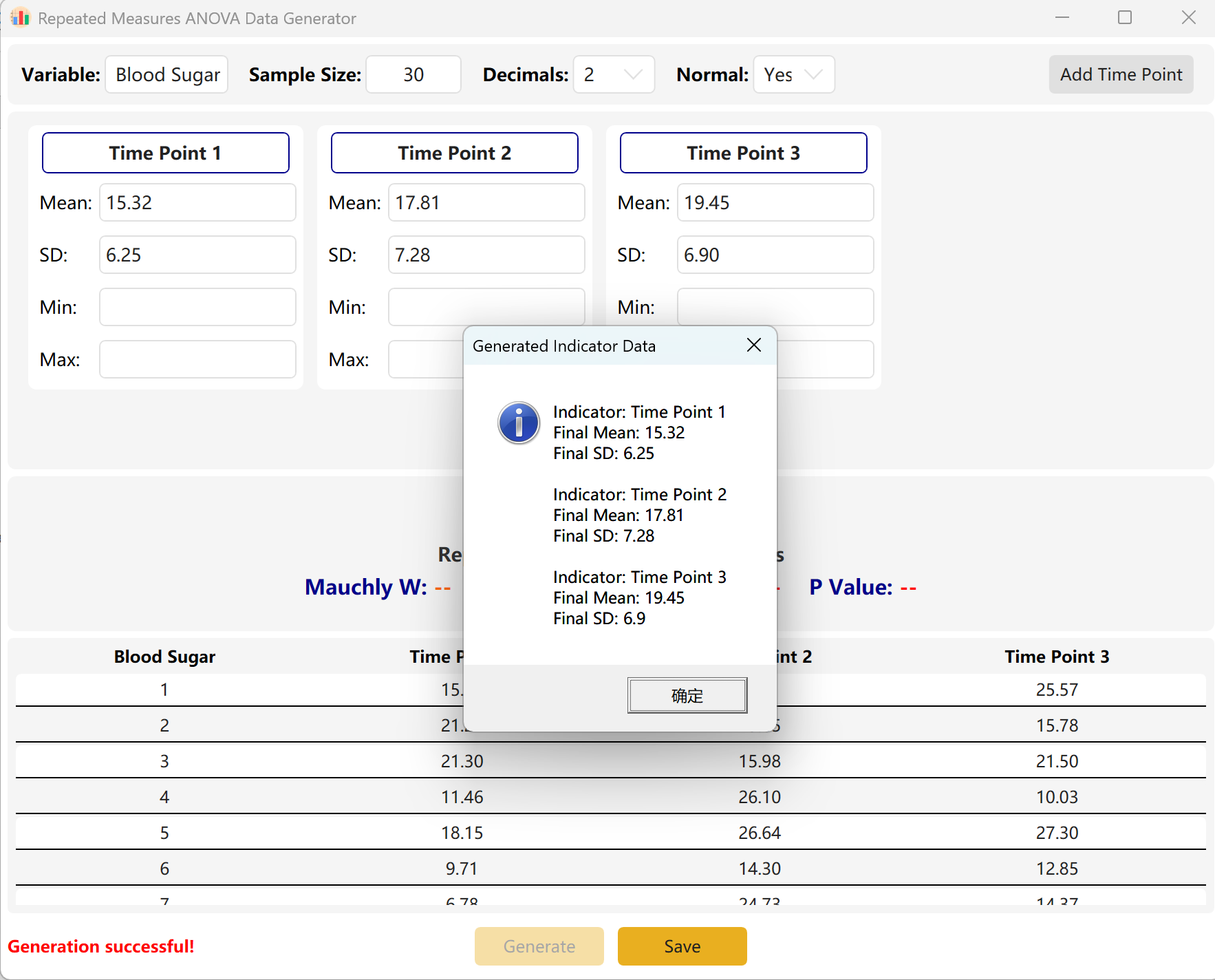
Figura 7.2: Interface do Utilizador / Apresentação de Dados da ANOVA de Medidas Repetidas
8. Teste de Soma de Postos para Duas Amostras Independentes (Não Paramétrico)
O equivalente ao teste U de Mann-Whitney quando os dados não cumprem os pressupostos de normalidade. Avalia as diferenças de medianas de acordo com a lógica de ordenação por postos em variáveis contínuas ou ordinais.
8.1 Fluxo de Trabalho
Aceda a Analyze → Non-parametric → 2 Independent Samples. O espaço de configuração apresenta-se da seguinte forma:
1.png)
Figura 8.1: Interface do Utilizador / Operações para o Teste de Soma de Postos para Duas Amostras Independentes
8.2 Configuração
O programa oferece por padrão dois grupos de referência. Uma vez que os métodos não paramétricos são destinados a dados que não seguem uma distribuição normal, a opção Normal Distribution está definida como No por padrão. Com base no teste U de Mann-Whitney, pode definir um valor p alvo. Clique no botão Generate para sintetizar observações brutas que respeitem este limiar estatístico.
Lógica de Geração por Soma de Postos: Os testes não paramétricos analisam as diferenças de grupo ao agrupar todas as observações e atribuir-lhes postos (ranks). Portanto, se os parâmetros configurados para os seus dois grupos apresentarem grandes divergências (o que resultaria naturalmente num valor p minúsculo) enquanto solicita um alvo de p > 0,05, o motor reduzirá por si mesmo a divergência entre grupos. As médias e desvios padrões finais calculados serão exibidos numa caixa de diálogo.
2.png)
Figura 8.2: Interface do Utilizador / Apresentação de Dados do Teste de Soma de Postos para Duas Amostras Independentes
9. Teste de Kruskal-Wallis (K Amostras Independentes Não Paramétricas)
Equivalente ao teste H de Kruskal-Wallis. Gera dados ordinais ou dados contínuos não normais distribuídos por três ou mais grupos independentes.
9.1 Fluxo de Trabalho
Aceda a Analyze → Non-parametric → K Independent Samples. O espaço de configuração é apresentado abaixo:
1.png)
Figura 9.1: Interface do Utilizador / Operações para o Teste de Kruskal-Wallis
9.2 Ordenação Multi-Grupo
O programa oferece por padrão três grupos de referência e realiza um teste de Kruskal-Wallis. Tal como no teste de dois grupos, uma vez que os cálculos se baseiam nos postos (ranks) de uma amostra global fundida, se os parâmetros configurados para os seus vários grupos apresentarem grandes divergências (resultando em valores p altamente significativos) enquanto solicita um alvo de p > 0,05, o motor de simulação atenuará automaticamente as diferenças inter-grupos. As estatísticas correspondentes serão exibidas numa janela pop-up.
2.png)
Figura 9.2: Interface do Utilizador / Apresentação de Dados do Teste de Kruskal-Wallis
10. Geração de Dados por Quartis
Divide um conjunto de dados ordenados em quatro partes iguais. Útil para avaliar a dispersão e tendência central dos dados, destacar a mediana e detetar valores atípicos (outliers).
10.1 Fluxo de Trabalho
Aceda a Analyze → Quartile Data. O layout apresenta-se da seguinte forma:
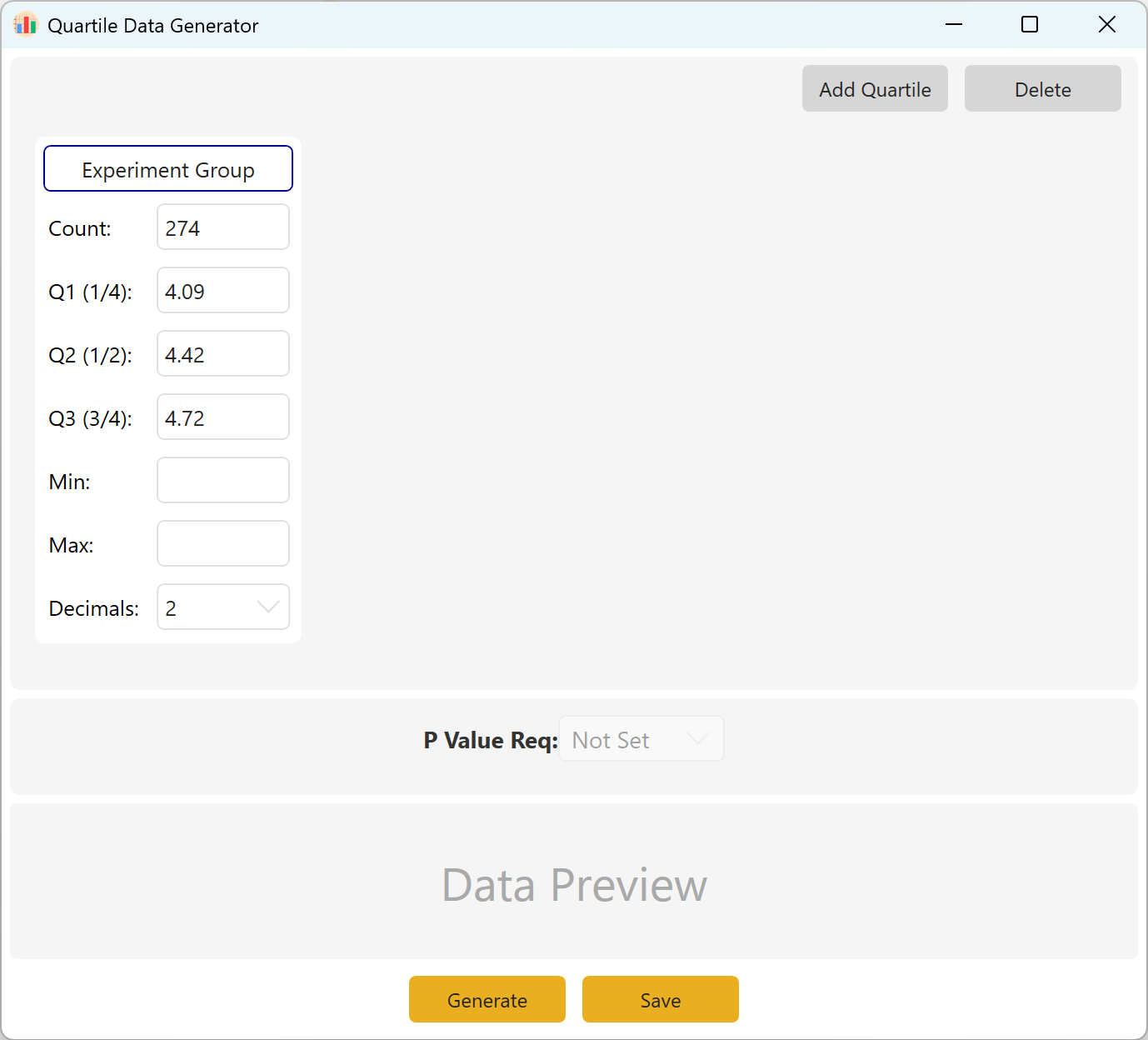
Figura 10.1: Interface do Utilizador / Operações para Dados por Quartis
10.2 Definição de Parâmetros
Defina o tamanho da amostra alvo, o primeiro quartil Q1 (percentil 25), a mediana Q2 (percentil 50) e o terceiro quartil Q3 (percentil 75). Os campos Mín/Máx podem permanecer vazios se nenhuma limitação específica se aplicar. Escolha o número de casas decimais e clique no botão Generate para produzir as observações que cumprem exatamente esses limites de quartil.
Resumo: Configure o tamanho da amostra bem como os valores-alvo para Q1, Q2 e Q3. Os parâmetros opcionais incluem o Mínimo, o Máximo e as Casas Decimais. Clique no botão Generate para calcular e exibir as observações brutas correspondentes à estrutura de quartis desejada. Para configurações de múltiplos grupos, também pode definir um intervalo de valor p alvo inter-grupo.
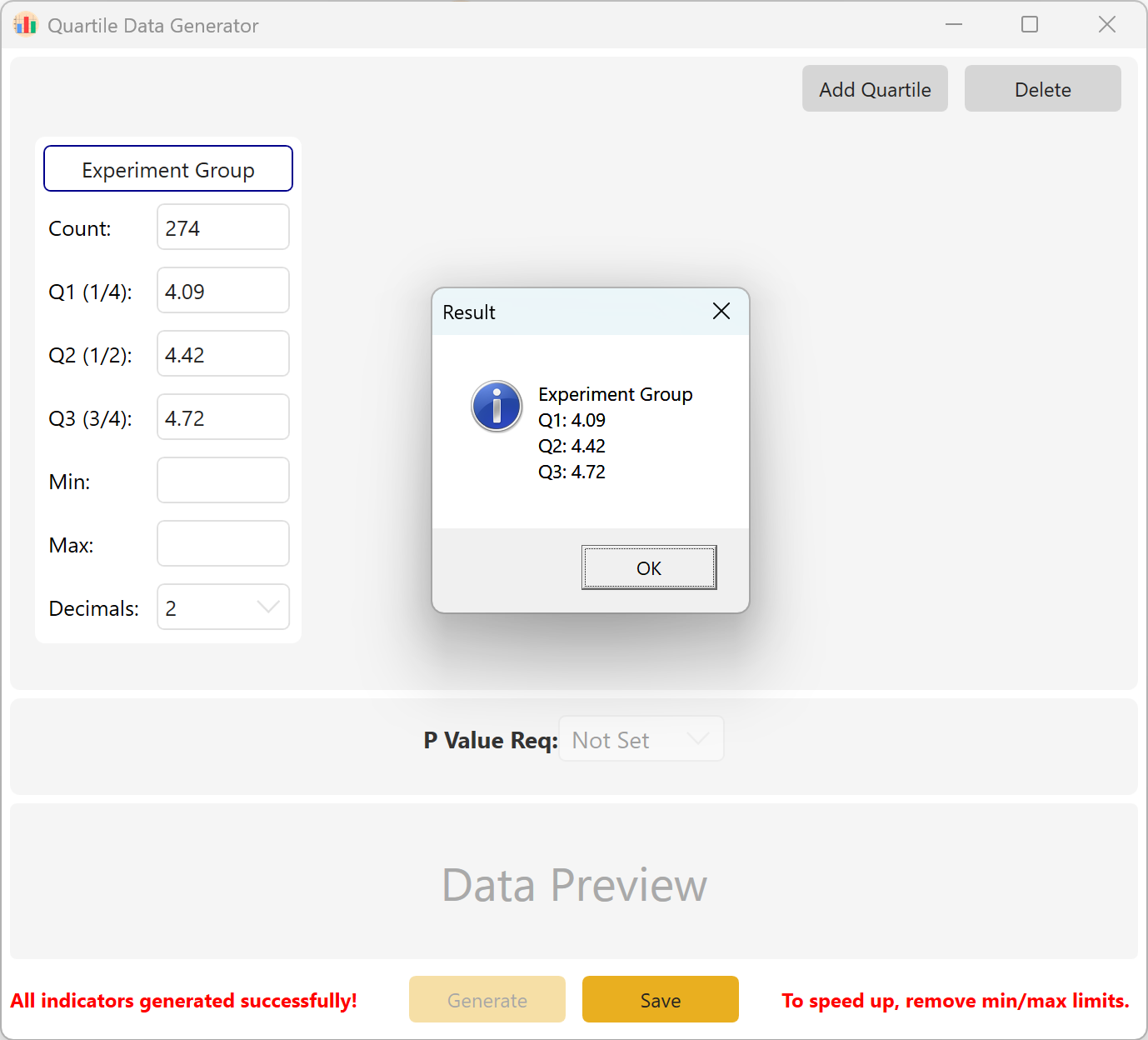
Figura 10.2: Interface do Utilizador / Apresentação de Dados por Quartis
11. Geração de Dados de Regressão Logística Binária
Essencial para problemas de classificação onde a variável de resultado é dicotómica (VD=0 ou VD=1). Muito comum em epidemiologia para identificação de fatores de risco (ex: Doente vs Saudável).
11.1 Fluxo de Trabalho
Aceda a Analyze → Regression → Binary Logistic.
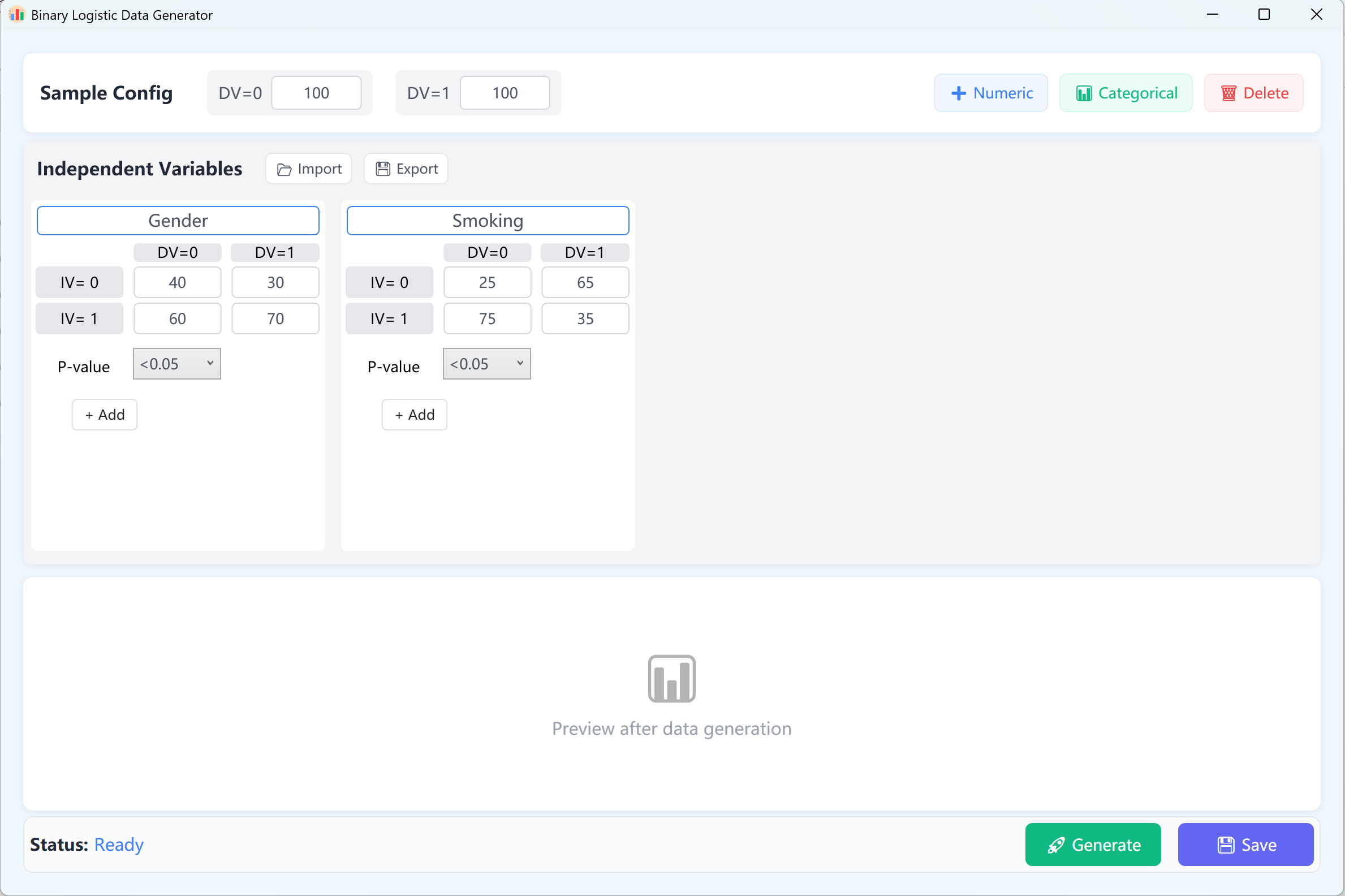
Figura 11.1: Interface do Utilizador / Operações para a Regressão Logística Binária
11.2 Conceção
Por predefinição, duas variáveis independentes contínuas são configuradas a título de exemplo. Num modelo logístico binário, a variável dependente possui apenas dois estados possíveis (0 e 1). Assim, a variável dependente é estruturada nos grupos 0 e 1, com um tamanho de amostra predefinido de 100 casos por categoria (personalizável).
- Configuration des variables : Clique em + Numeric para adicionar variáveis independentes contínuas (ex. "Age", "BMI"). Indique o nome da variável, a sua Média, o seu Desvio Padrão, o Número de casas decimais e o intervalo alvo do p-value (este parâmetro define o nível de significância desejado para esta variável no modelo final de regressão logística). Os limites Mín/Máx são opcionais.
- Génération et validation : Clique no botão Generate para iniciar o algoritmo de síntese. O sistema calculará iterativamente um conjunto de dados para o qual o modelo de regressão logística fornece p-values em conformidade com a sua configuração.
Um relatório detalhado de análise de regressão que replica exatamente o formato de saída do IBM SPSS será exibido automaticamente numa janela pop-up. Fechar este relatório revelará os dados brutos na tabela de pré-visualização, prontos para serem exportados para o Excel.
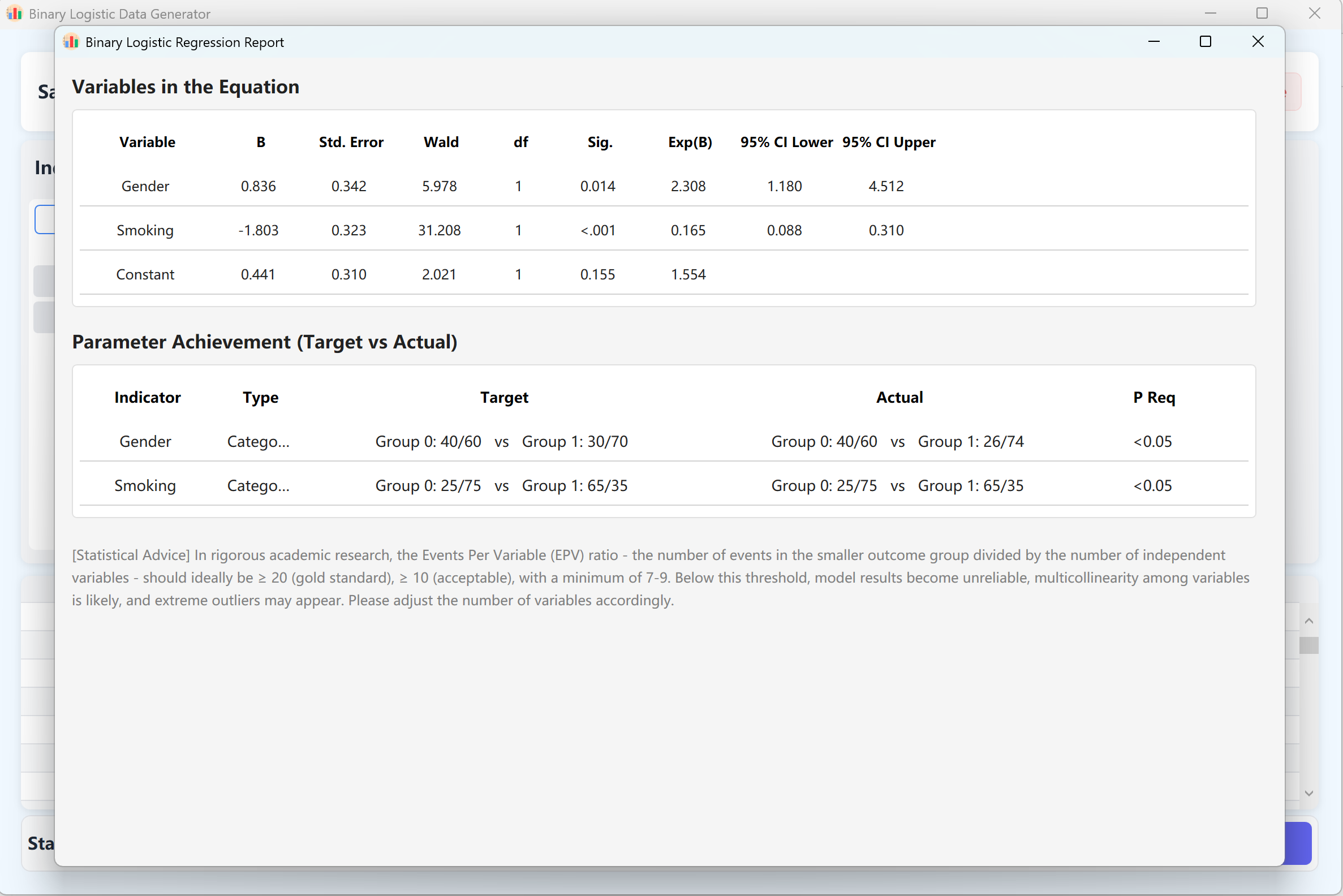
Figura 11.2: Interface do Utilizador / Apresentação de Dados da Regressão Logística Binária
12. Geração de Dados de Regressão Linear Múltipla
Uma ferramenta fundamental de modelagem preditiva. Sintetiza uma variável dependente contínua (Y) influenciada por múltiplas variáveis independentes (X). Estas últimas podem ser de natureza contínua (numérica), por quartis, categóricas ordenadas (ordinais) ou não ordenadas (nominais).
12.1 Fluxo de Trabalho
Aceda a Analyze → Regression → Linear Regression.
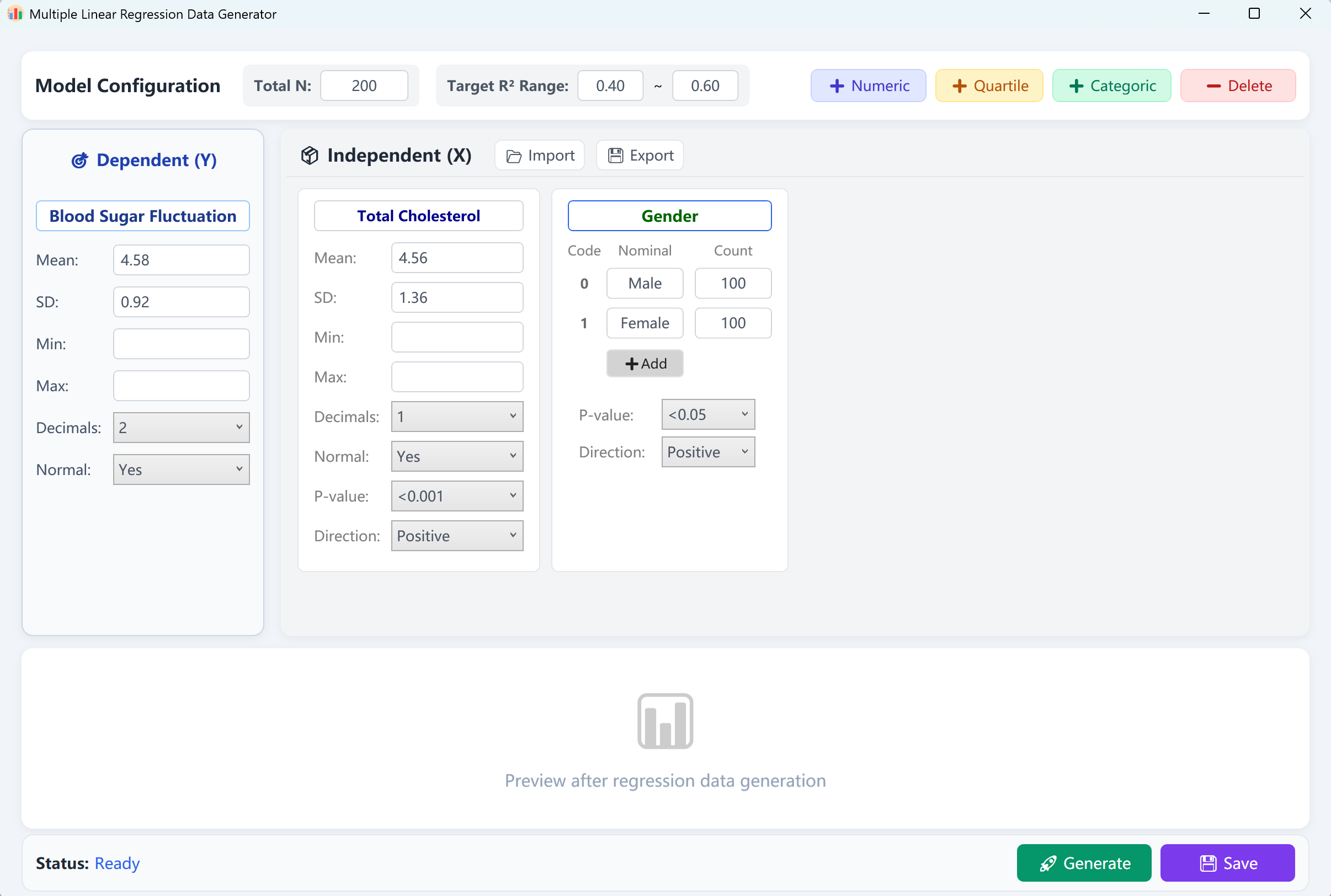
Figura 12.1: Interface do Utilizador / Operações para a Regressão Linear Múltipla
12.2 Parâmetros du modèle
A interface pré-carrega uma variável dependente contínua ("Blood Glucose Fluctuation" - Flutuação da glicose no sangue) e duas variáveis independentes ("Total Cholesterol" - Colesterol total como variável numérica, e "Gender" - Género como variável categórica) com um tamanho de amostra padrão de 200 casos. Pode definir um intervalo alvo para o coeficiente de determinação R-quadrado (R²) (ex. entre 0,4 e 0,6).
Clique no botão Generate para executar o modelo de regressão. Um relatório de validação semelhante aos resultados do SPSS aparecerá. Ao fechar este relatório, encontrará a tabela de pré-visualização de dados brutos, pronta para ser guardada no formato Excel.
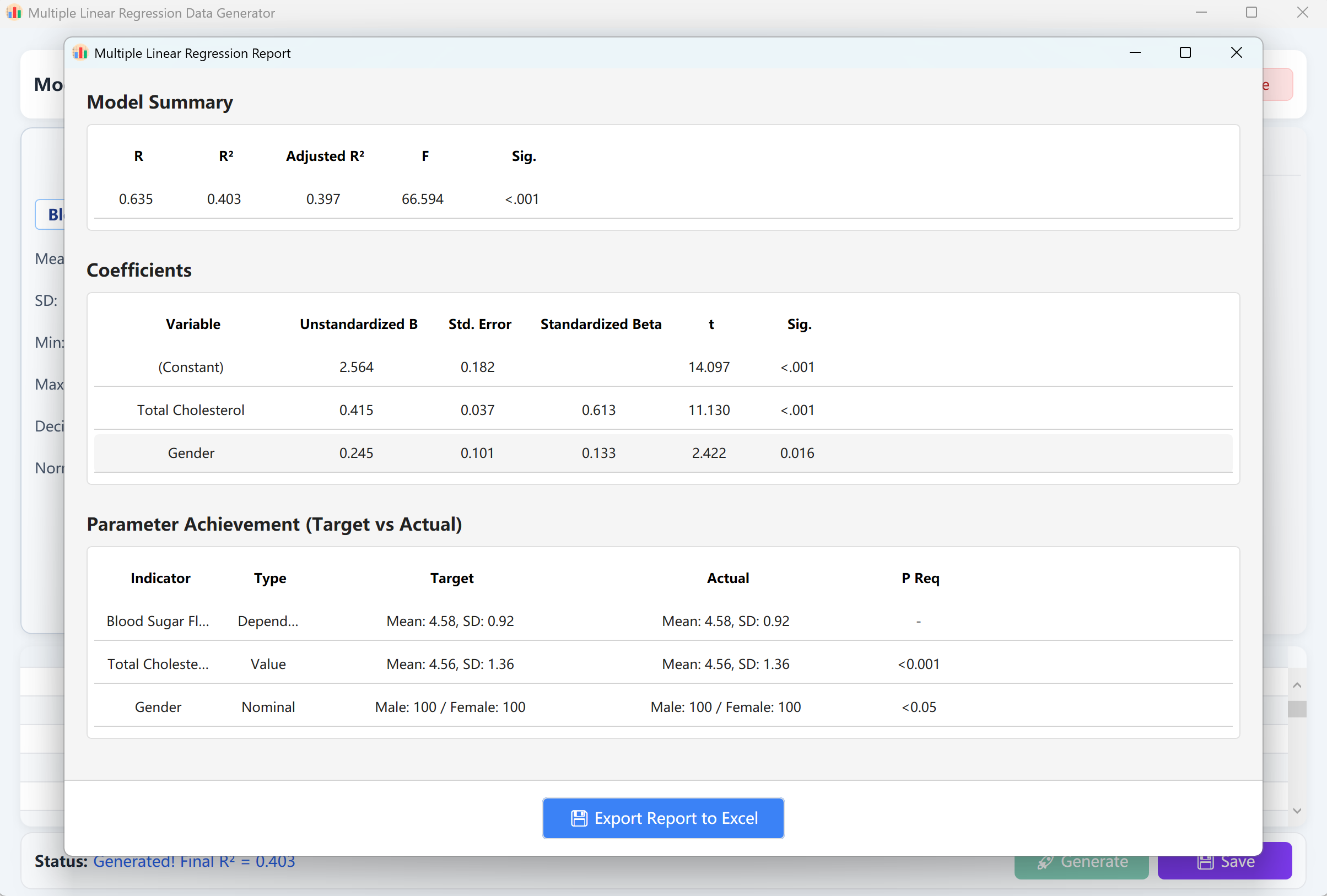
Figura 12.2: Interface do Utilizador / Apresentação de Dados da Regressão Linear Múltipla
13. Geração de dados de regressão de riscos proporcionais de Cox
A referência absoluta na análise de sobrevivência. Simula dados de tempo até ao evento, considerando a censura à direita, permitindo aos investigadores avaliar o impacto das covariáveis nos tempos de sobrevivência.
13.1 Fluxo de Trabalho et directives techniques
Aceda a Analyze → Regression → Cox Regression.
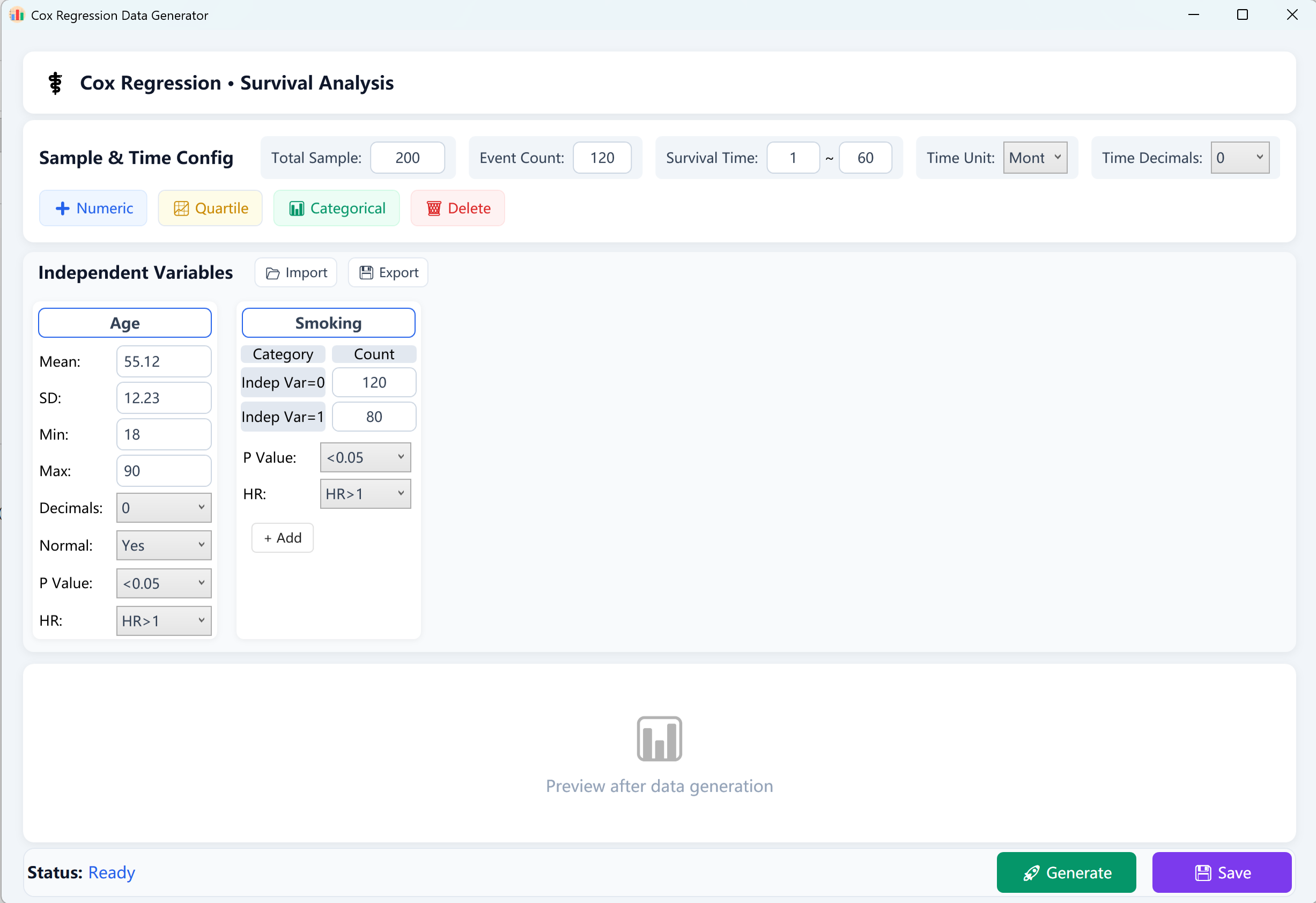
Figura 13.1: Interface do utilizador / Operações para a Regressão de riscos proporcionais de Cox
- Tamanho total da amostra (N): O número global de sujeitos ou doentes (ex. 200 sujeitos).
- Eventos observados (Eventos de interesse): O número de casos positivos que sofreram o evento terminal (ex. óbito, recidiva ou falha) durante o período de acompanhamento. Nota: O número de eventos deve ser estritamente inferior ao tamanho total da amostra.
- Intervalo de tempo de sobrevivência (T): Defina os limites [Min Follow-up] e [Max Follow-up] do tempo de acompanhamento de sobrevivência (ex. 1~60 meses), rotule a unidade de tempo (dias, meses ou anos) e indique o número de casas decimais desejado.
Regra estatística do EPV (Eventos por variável): Para garantir a estabilidade matemática e a confiabilidade de um modelo de riscos proporcionais de Cox, é fortemente recomendado ter uma proporção de eventos observados em relação ao número de variáveis independentes (EPV) de pelo menos 10 a 20. Se o seu modelo não convergir, tente aumentar o tamanho total da amostra ou o número de eventos observados.
13.2 Construção das variáveis de pesquisa
Clique nos botões correspondentes na parte inferior do cartão de variáveis para adicionar covariáveis independentes:
- Variáveis numéricas contínuas: Clique em + Numeric para adicionar covariáveis contínuas (ex. Idade, IMC, biomarcadores clínicos). Indique a Média, o Desvio Padrão (obrigatório) e, opcionalmente, os limites Mín/Máx para restringir valores atípicos, bem como o número de casas decimais.
- Variáveis categóricas: Clique em + Categorical para adicionar covariáveis nominais ou ordinais (ex. Género, pontuação de satisfação). Indique o tamanho alvo exato para cada categoria. Nota: A soma dos tamanhos de todas as categorias deve ser imperativamente igual ao tamanho total da amostra configurado para poder iniciar a geração.
- Variáveis por quartis: Clique em + Quartile para adicionar variáveis estruturadas por quartis, preenchendo os parâmetros alvo de Q1, Q2 (Mediana) e Q3.
Parâmetros alvo: Cada cartão de variável oferece dois parâmetros de direcionamento poderosos na parte inferior da página:
- p-value da regressão: Selecione o limiar de significância alvo (ex. p > 0,05, p < 0,05, p < 0,01 ou p < 0,001).
- Direção do Hazard Ratio (HR): Escolha HR > 1 (fator de risco, indicando um aumento da taxa de risco) ou HR < 1 (fator protetor, indicando uma redução da taxa de risco).
13.3 Execução da geração e salvaguarda
Depois de configurados todos os parâmetros, clique no botão Generate na parte inferior da janela. O motor de execução iniciará simulações iterativas altamente concorrentes. Um relatório oficial e detalhado de análise de regressão de riscos proporcionais de Cox será exibido, reproduzindo fielmente os cálculos e a apresentação do IBM SPSS.
Clique no botão Save para exportar o conjunto de dados brutos gerado para um ficheiro Excel. Este poderá ser importado diretamente para o SPSS ou qualquer outra ferramenta de análise estatística profissional para verificação.
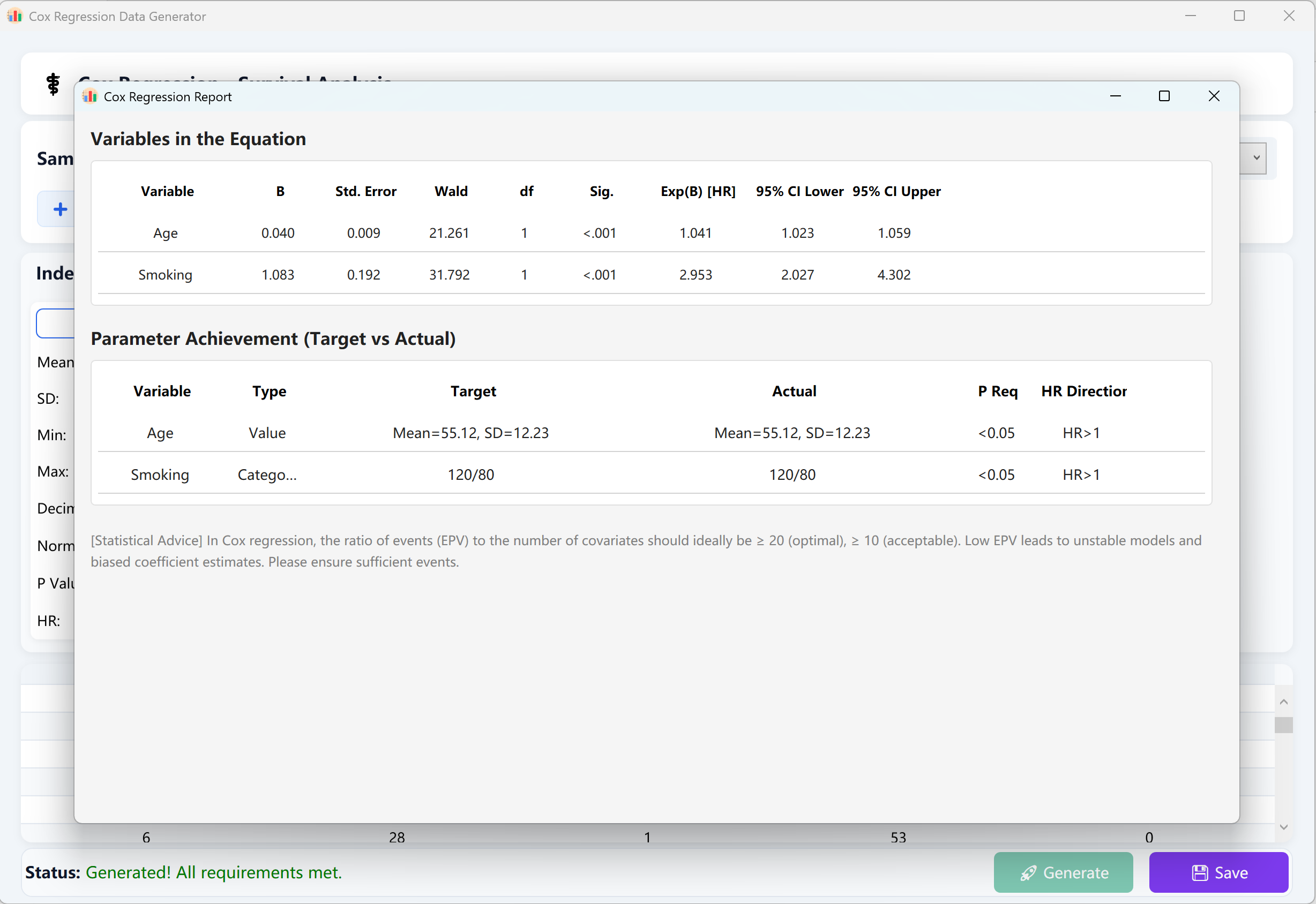
Figura 13.2: Interface do utilizador / Apresentação de dados da Regressão de riscos proporcionais de Cox
14. Geração de dados para análise de correlação
Simula relações bivariadas (Pearson ou Spearman) e correlações parciais, aplicando coeficientes de correlação (valores r) e níveis de significância alvo.
14.1 Fluxo de Trabalho
Accédez à Analyze → Correlação.
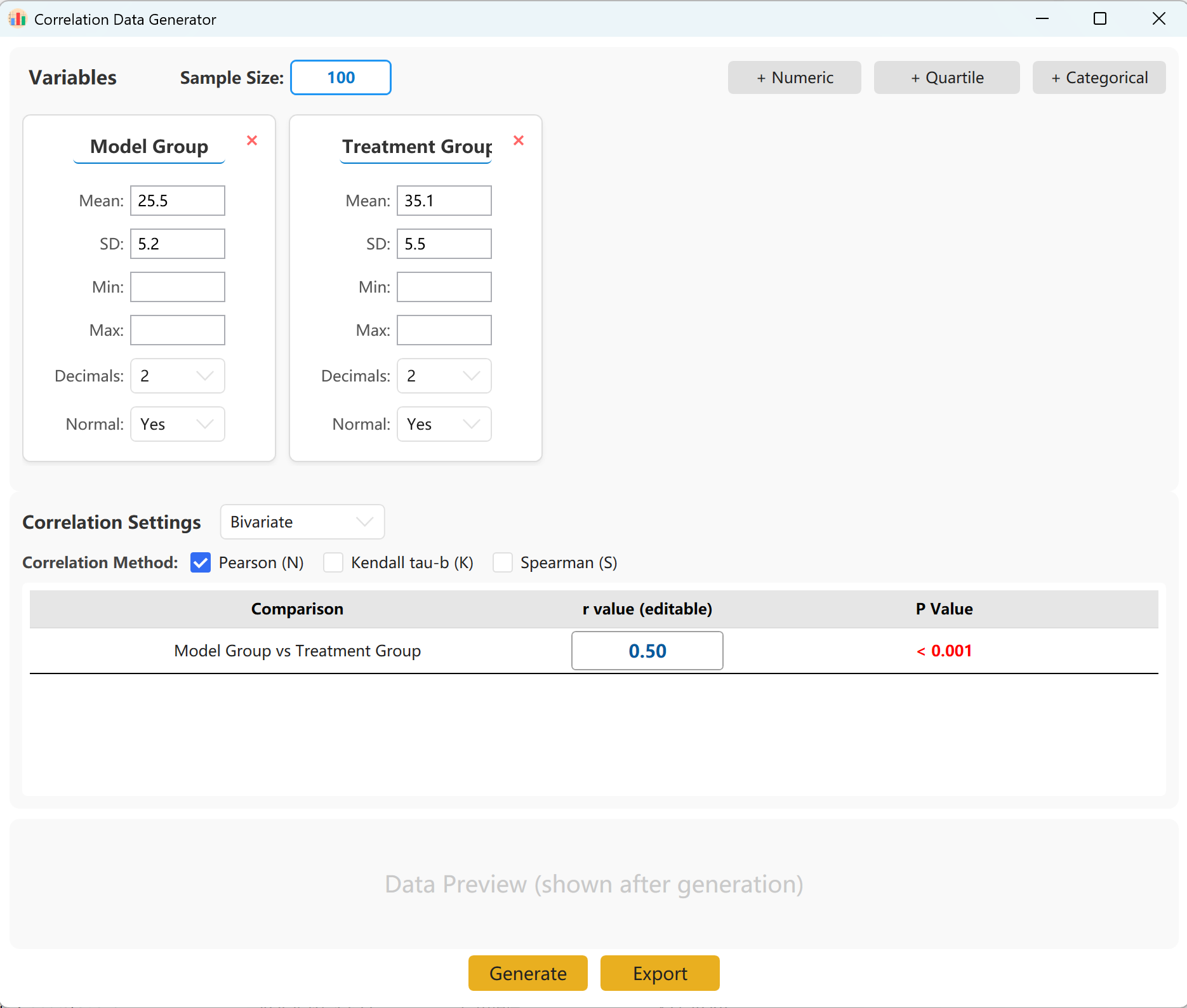
Figure 14.1 : Interface utilisateur / Opérations pour l'Análise de Correlação
14.2 Parâmetros
O sistema pré-carrega dois conjuntos de variáveis para uma referência rápida. Pode facilmente adicionar outras variáveis, sob a forma numérica contínua (média/desvio padrão), por quartis ou categóricas. No painel de configuração, especifique o tamanho da amostra, a média e o desvio padrão de cada indicador (os limites Mín/Máx são opcionais).
Pode especificar o coeficiente de correlação exato (r) alvo entre os grupos. Clique no botão Generate para iniciar a simulação e exibir a matriz de correlação resultante numa janela pop-up, pronta para ser exportada para o formato Excel.
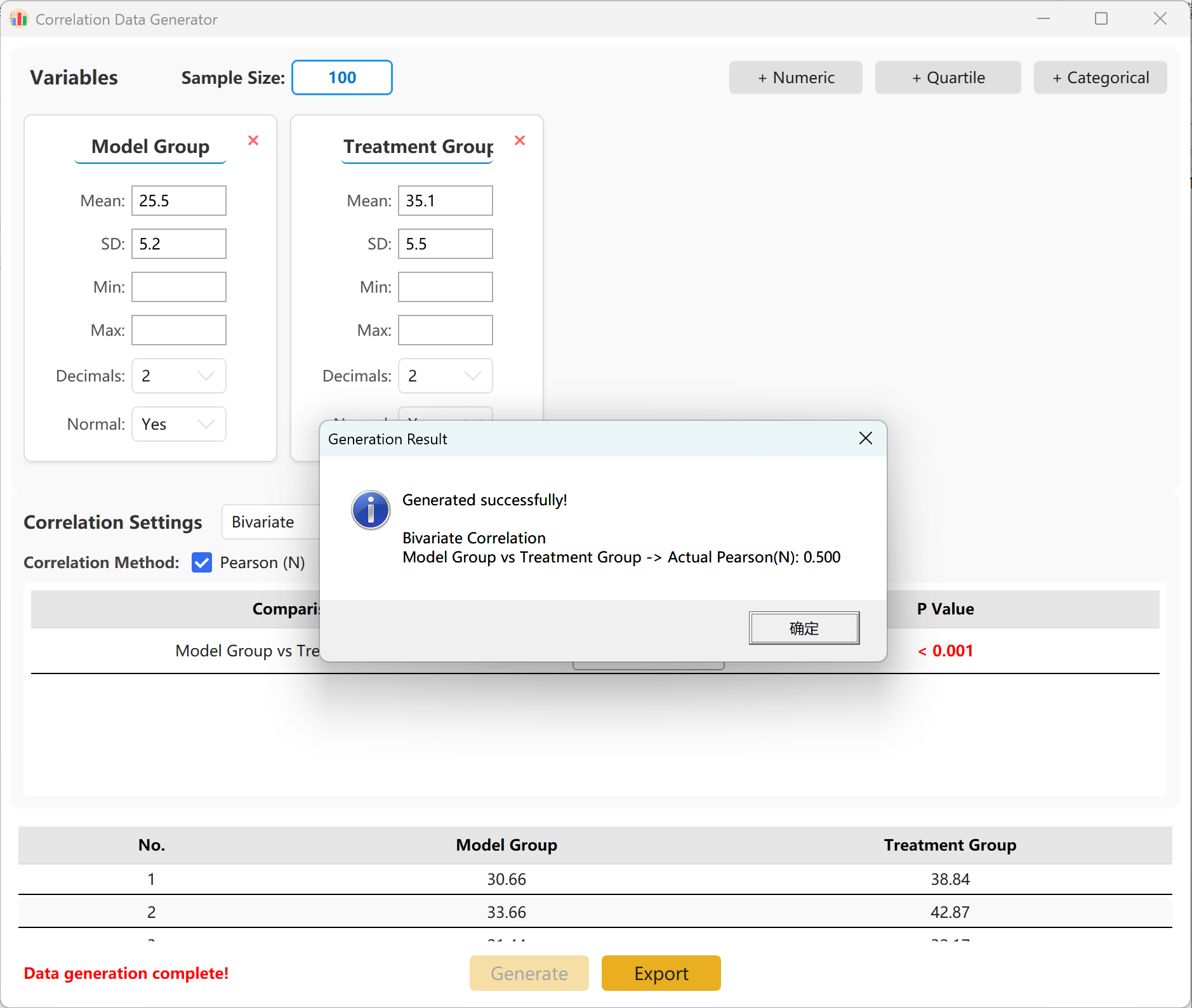
Figure 14.2 : Interface utilisateur / Affichage des données de l'Análise de Correlação
15. Geração de dados para análise de curva ROC
Avalia a capacidade diagnóstica de uma variável de teste contínua ou categórica para distinguir dois estados (ex. Diagnóstico Positivo vs Negativo).
15.1 Fluxo de Trabalho
Accédez à Analyze → Curva ROC.
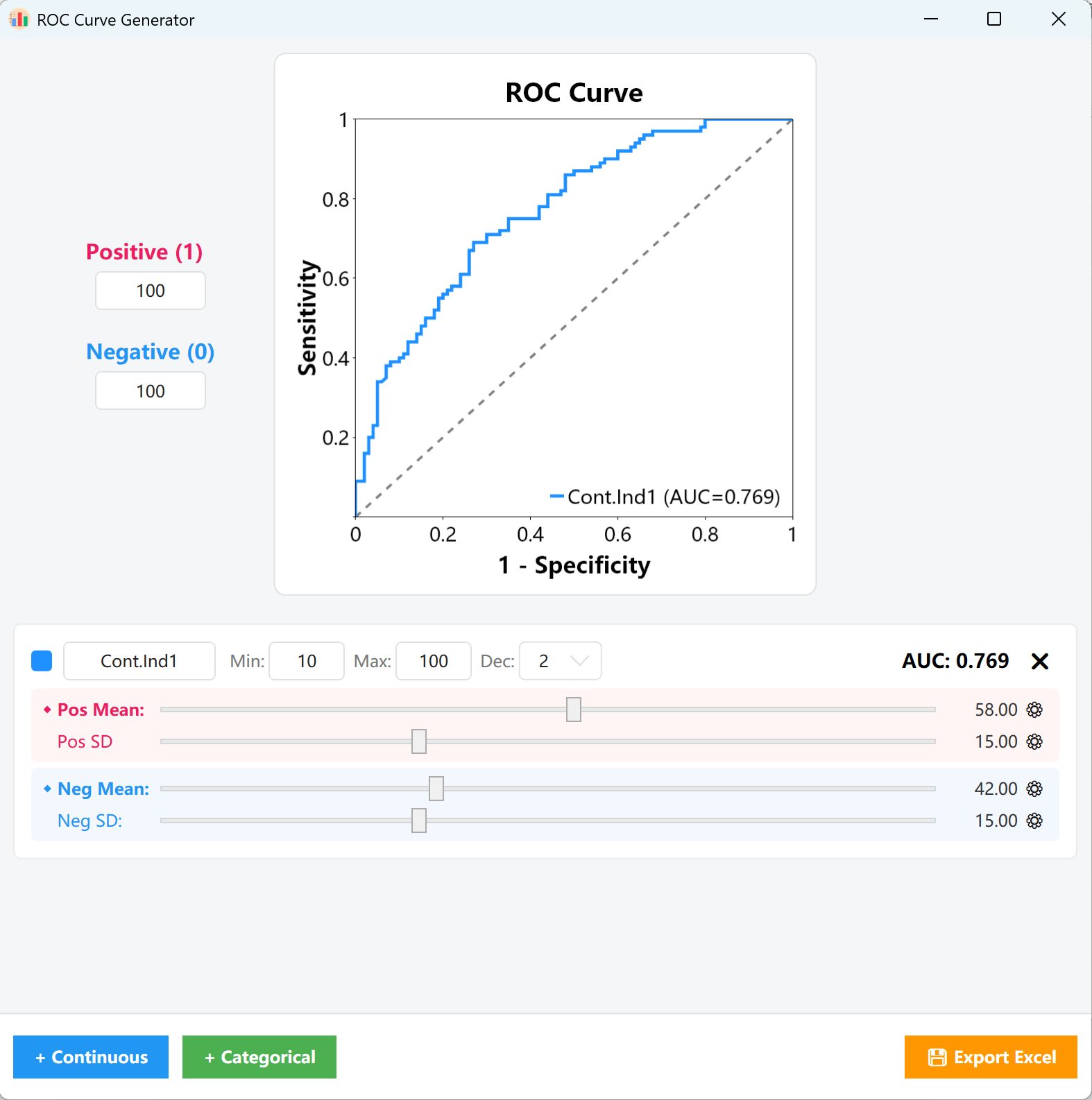
Figure 15.1 : Interface utilisateur / Opérations pour le paramétrage de la 15. Curva ROC
Proporções: No painel de configuração à esquerda, preencha os tamanhos alvo para as Amostras Positivas (1) e Amostras Negativas (0) (ex. 100 casos positivos e 100 casos negativos). O motor de geração construirá a matriz de amostragem básica de acordo com estas proporções.
15.2 Tipos de variáveis
Clique em + Continuous ou + Categorical no canto inferior esquerdo para criar as variáveis correspondentes:
- Variáveis contínuas: Personalize o nome da variável, os limites Mín/Máx e o número de casas decimais no cartão. Arraste o cursor Cor-de-rosa (grupo Positivo) e o cursor Azul (grupo Negativo) para ajustar rapidamente as respetivas distribuições de Média e Desvio Padrão.
- ⚙ Ajuste de precisão: Se os cursores visuais não permitirem atingir a granularidade desejada, clique no ícone de engrenagem (⚙) ao lado do parâmetro para inserir manualmente valores precisos de ponto flutuante.
- Monitorização do AUC: Ao longo destes ajustes, o indicador AUC = 0.XXX no canto superior direito do cartão, bem como o gráfico central, atualizar-se-ão em tempo real, permitindo-lhe alinhar visualmente a curva com o seu valor limite alvo.
- Variáveis categóricas: Defina simplesmente as proporções ou tamanhos exatos para as coortes positivas e negativas. Poderá observar instantaneamente as alterações correspondentes na curva ROC e no valor do AUC.
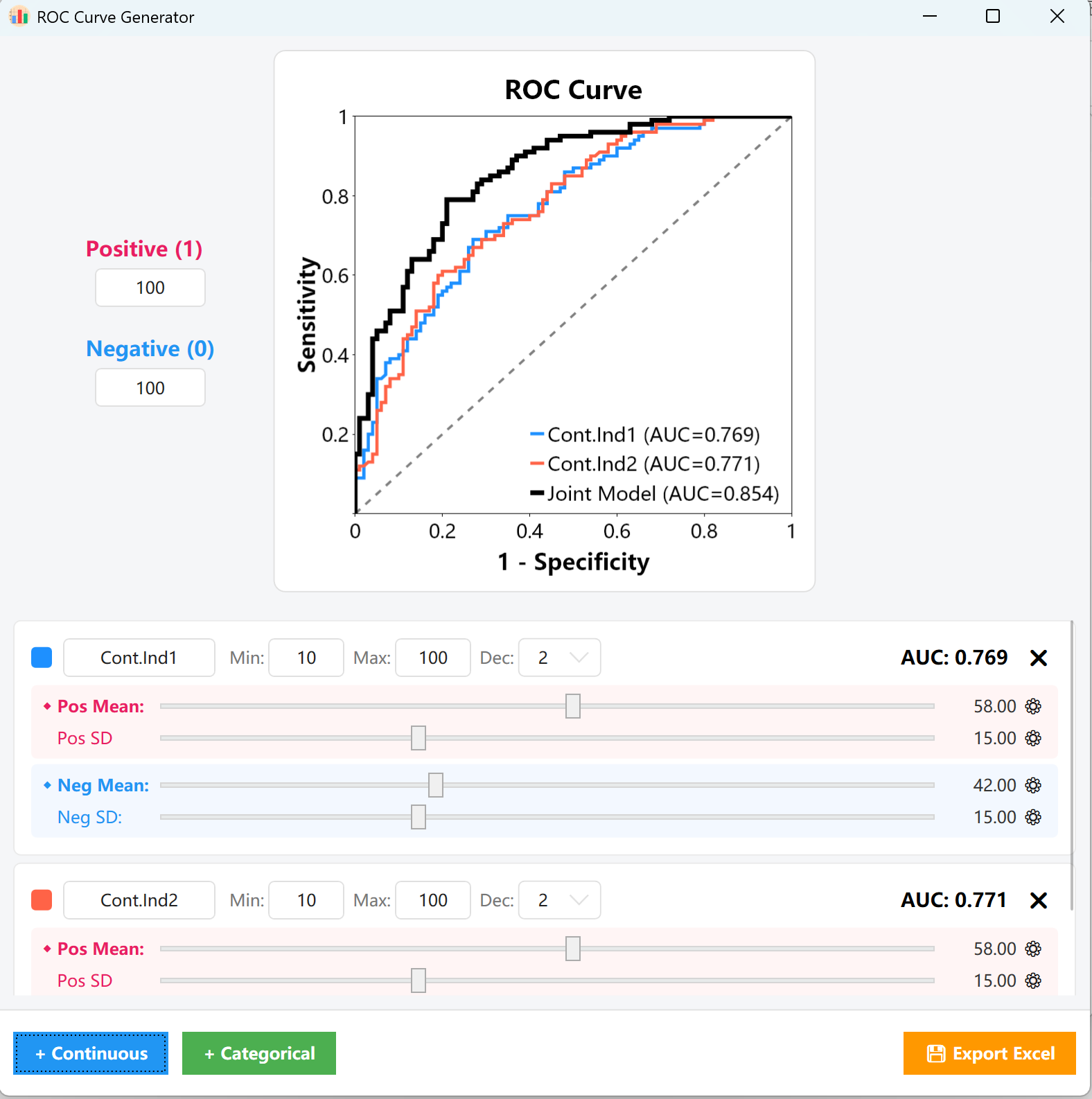
Figure 15.2 : Interface utilisateur / Affichage du tracé de la 15. Curva ROC
16. Guardar e exportar os parâmetros configurados
Para racionalizar as tarefas de modelagem repetitivas e evitar erros de configuração manual, a aplicação oferece um mecanismo poderoso de preservação do estado de configuração.
16.1 Guardar e restaurar
- Exportar a configuração: Vá ao menu File → Export Configuration para guardar todos os seus parâmetros configurados, definições de variáveis, estruturas de grupos e alvos num ficheiro de configuração local no formato .json no seu computador.
- Importar a configuração: Para restaurar o seu ambiente numa sessão futura, vá simplesmente ao menu File → Import Configuration e selecione o seu ficheiro de configuração guardado anteriormente. O espaço de trabalho recarregará imediatamente todos os cartões de variáveis, cursores e valores de parâmetros.