Documentation et Guide de l'utilisateur
Bienvenue dans la documentation officielle de DataSynth Pro. Ce manuel exhaustif vous guide pas à pas dans la configuration des paramètres de nos différents modules statistiques afin de synthétiser des ensembles de données robustes, scientifiquement valides et statistiquement viables, le tout de manière entièrement hors ligne.
1. Génération simultanée de plusieurs indicateurs
1.1 Prérequis et lancement
Double-cliquez sur le fichier exécutable pour lancer l'application. Le logiciel nécessite la plateforme d'exécution Microsoft .NET 8.0 Desktop Runtime. Si celle-ci n'est pas installée sur votre ordinateur, veuillez suivre les instructions pour la télécharger et l'installer, puis relancez le programme.
Avis de sécurité : Si votre logiciel antivirus signale l'exécutable comme un faux positif, veuillez ajouter l'application à la liste d'exclusions ou liste blanche locale pour assurer un fonctionnement sans interruption.
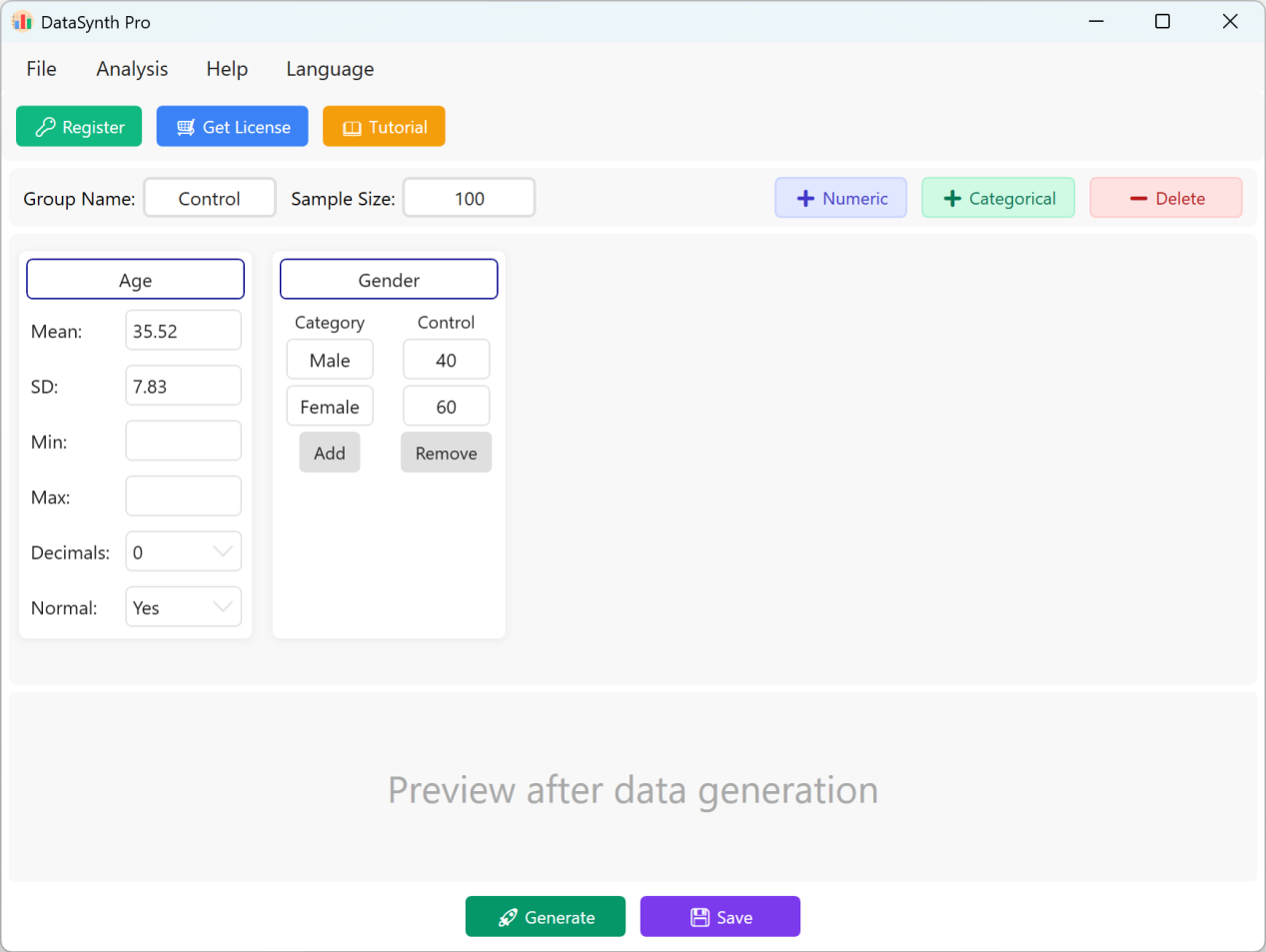
Figure 1.1 : Interface utilisateur / Opérations (Interface principale)
1.2 Configuration des paramètres
Par défaut, l'application pré-remplit deux variables continues, « Age » (Âge) et « Gender » (Genre), servant de références rapides. La désignation du groupe est définie par défaut sur « Control Group » (Groupe témoin) et la taille de l'échantillon est fixée à « 100 » cas. Si votre étude nécessite plusieurs groupes, vous pouvez générer et exporter successivement l'ensemble de données de chaque groupe en mettant à jour les paramètres à chaque exécution.
- Ajouter des variables numériques continues : Pour ajouter une nouvelle variable quantitative, cliquez sur le bouton + Numeric. Vous pouvez ensuite spécifier le nom de l'indicateur (ex. « Body Mass Index » ou « BMI »), la Moyenne, l'Écart-type et le Nombre de décimales. Les champs de limite minimale et maximale sont optionnels et peuvent rester vides si vous n'avez pas de contraintes de valeurs spécifiques.
- Paramètres de distribution des données : Par défaut, les mesures numériques générées suivent une distribution normale. Si vous avez besoin de données non distribuées normalement, désactivez simplement l'option Normal Distribution en choisissant No.
Ajustement de la distribution : Une distribution normale repose sur un intervalle de variance naturel. Restreindre de manière trop stricte les limites minimale et maximale tronquera la courbe normale et pourra engendrer des valeurs non distribuées normalement. Si cela se produit, essayez d'élargir ces limites ou supprimez complètement les valeurs min/max.
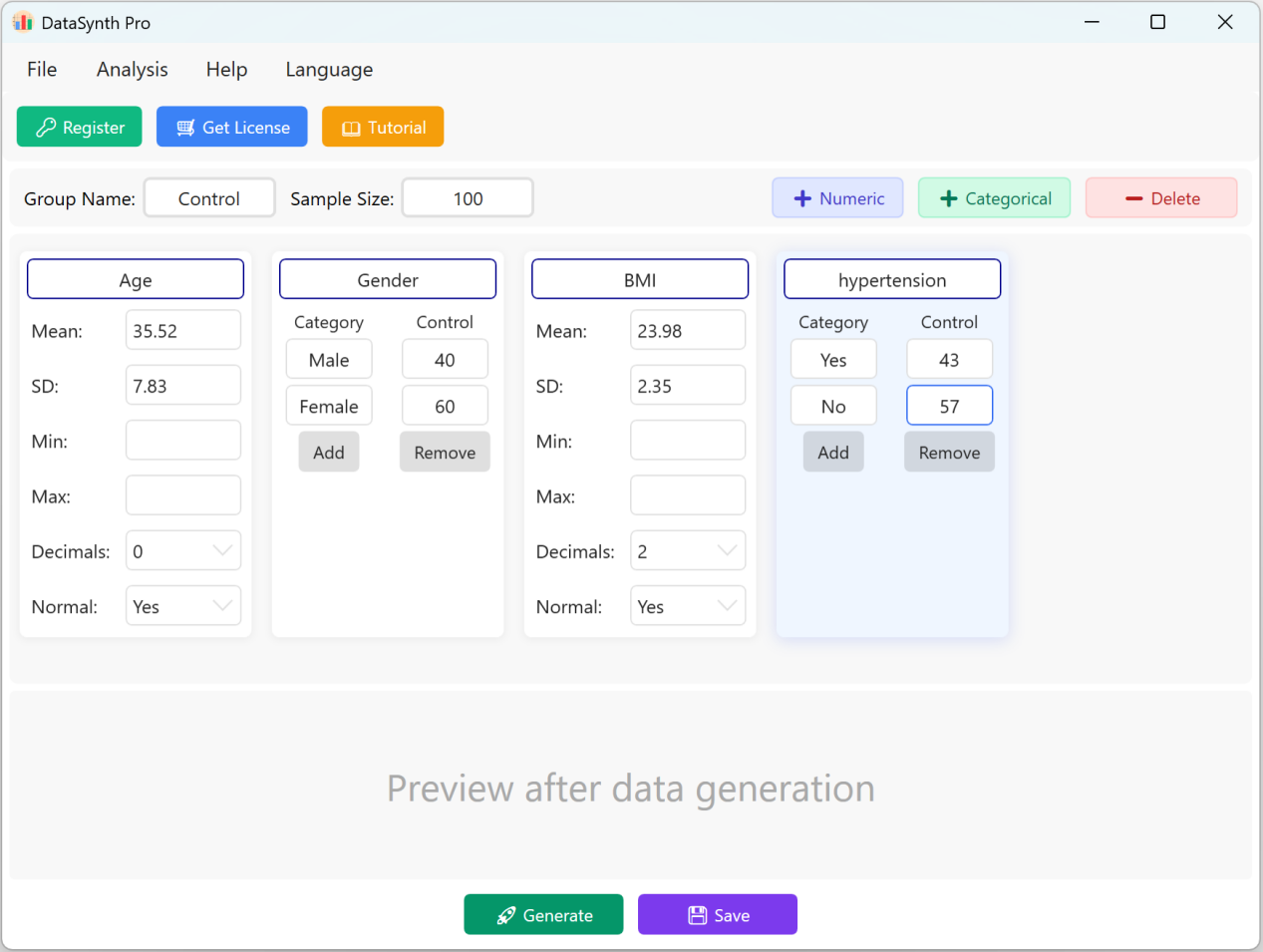
Figure 1.2 : Opérations de l'interface utilisateur pour l'ajout de variables
1.3 Ajouter des variables catégorielles
Cliquez sur le bouton + Categorical pour ajouter des variables qualitatives (ex. « Hypertension »). Vous pouvez saisir les noms des catégories et leurs distributions ou proportions cibles correspondantes. La somme des proportions catégorielles sera automatiquement ajustée à l'échelle de la taille d'échantillon configurée.
1.4 Exécution de la génération
Cliquez sur le bouton Generate pour synthétiser le nombre d'enregistrements demandé. Une fois le calcul terminé, une fenêtre récapitulative des statistiques descriptives s'affichera pour vous permettre de vérifier si les valeurs réelles générées correspondent bien aux paramètres que vous avez définis.
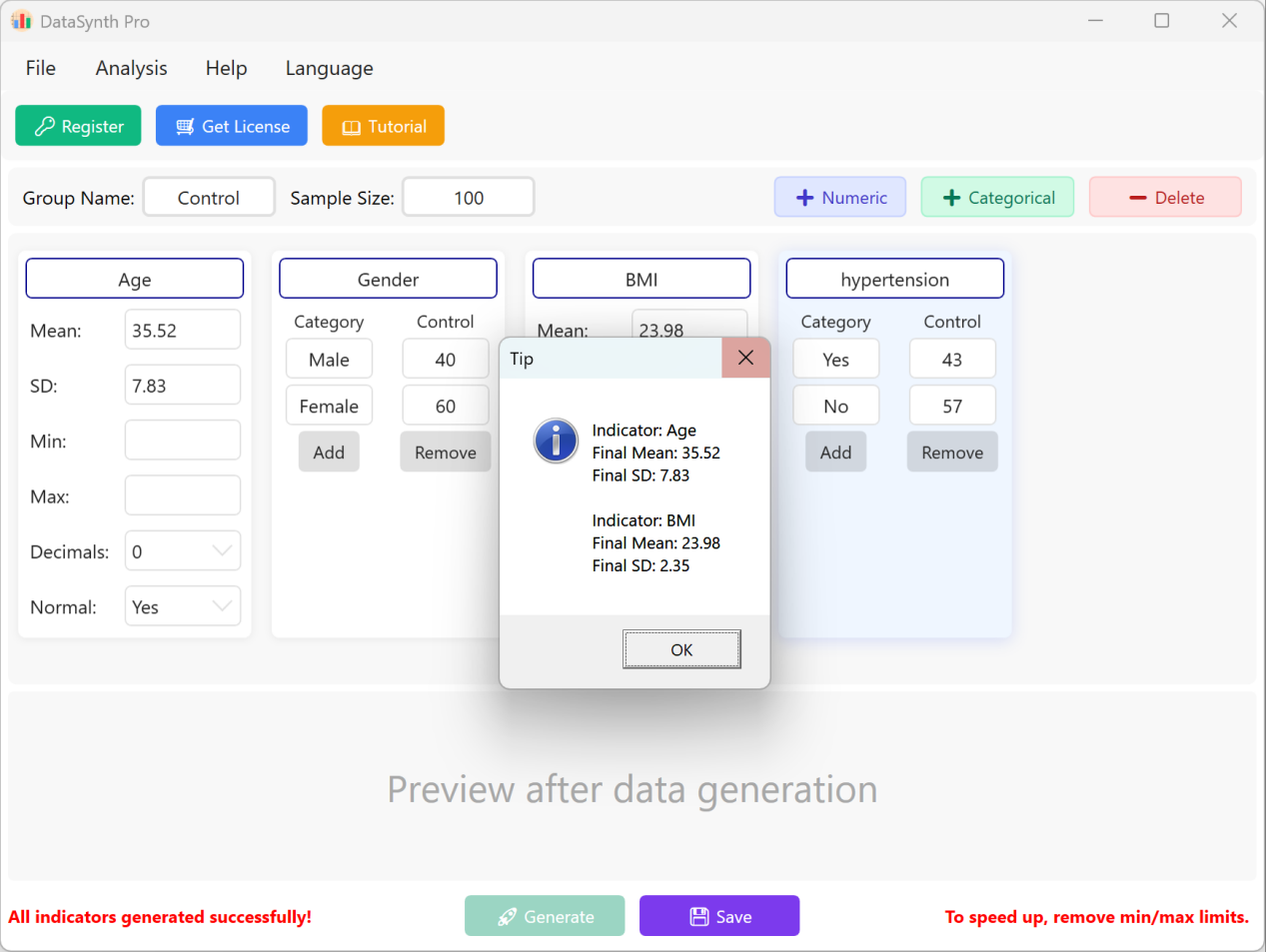
Figure 1.3 : Interface utilisateur / Opérations pour exécuter la génération
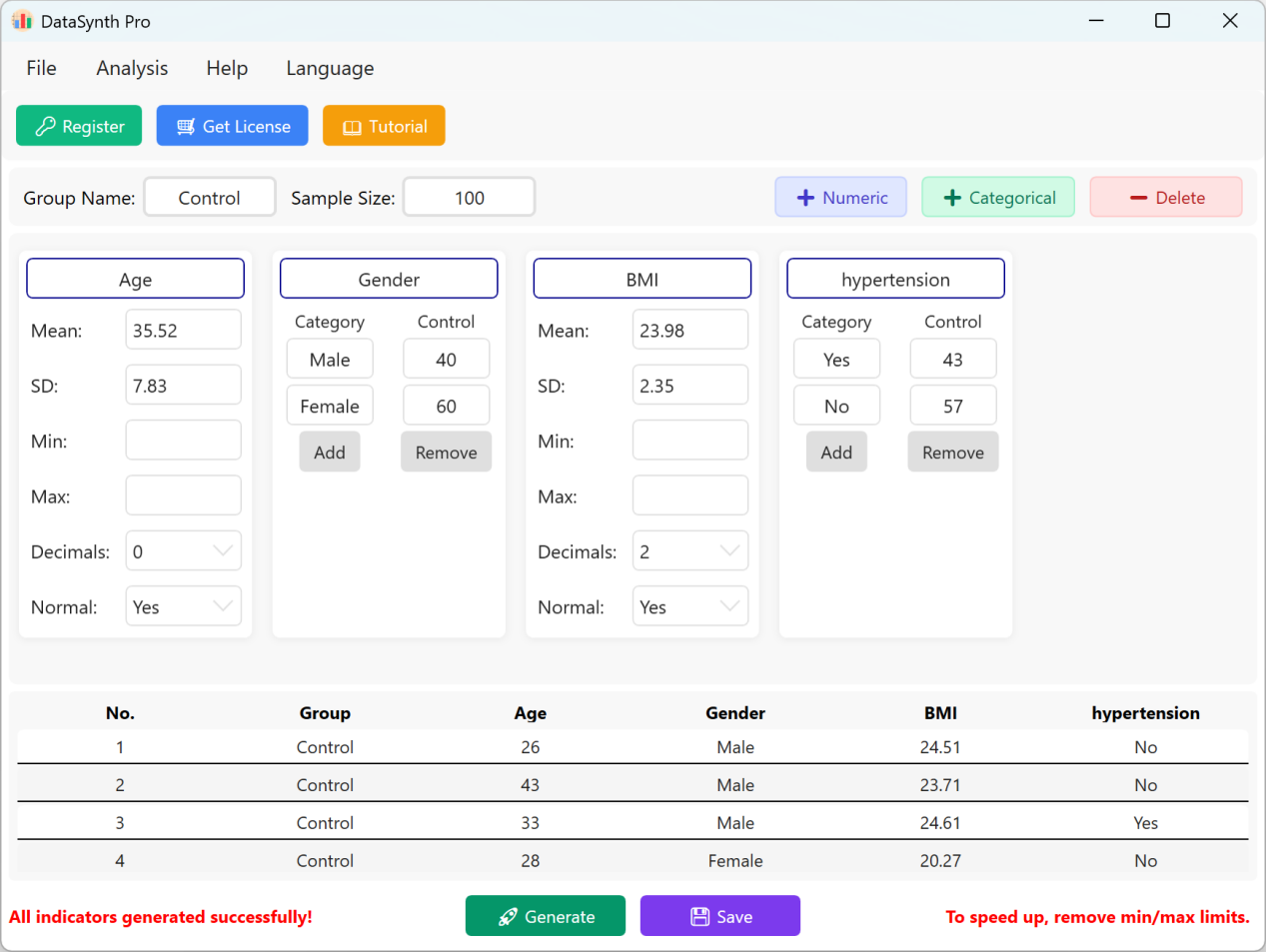
Figure 1.4 : Interface utilisateur / Opérations pour afficher les données
1.5 Exportation et vérification
Cliquez sur le bouton Save pour exporter l'ensemble de données généré sous forme de fichier Excel standard. Si vous ouvrez le classeur exporté et calculez les statistiques descriptives pour la variable « Age » (arrondie à deux décimales) à l'aide des formules Excel standards, la moyenne et l'écart-type réels correspondront parfaitement à vos paramètres initiaux.
Figure 1.5 : Exportation des tableaux générés vers Excel
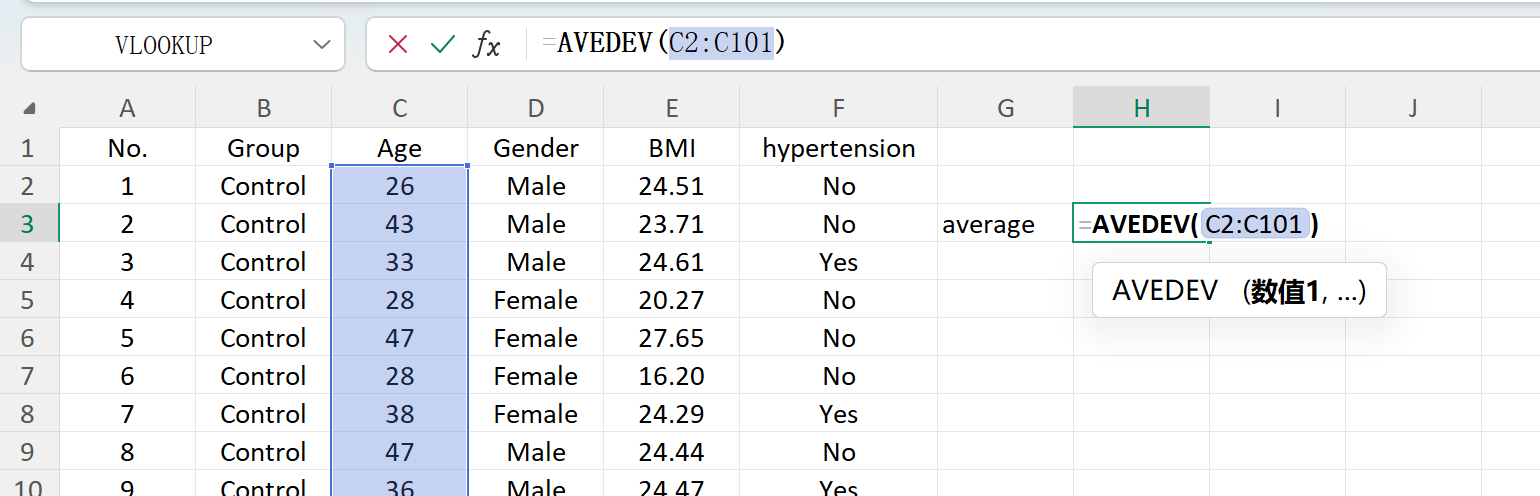
Figure 1.6 : Calcul de la moyenne dans Excel
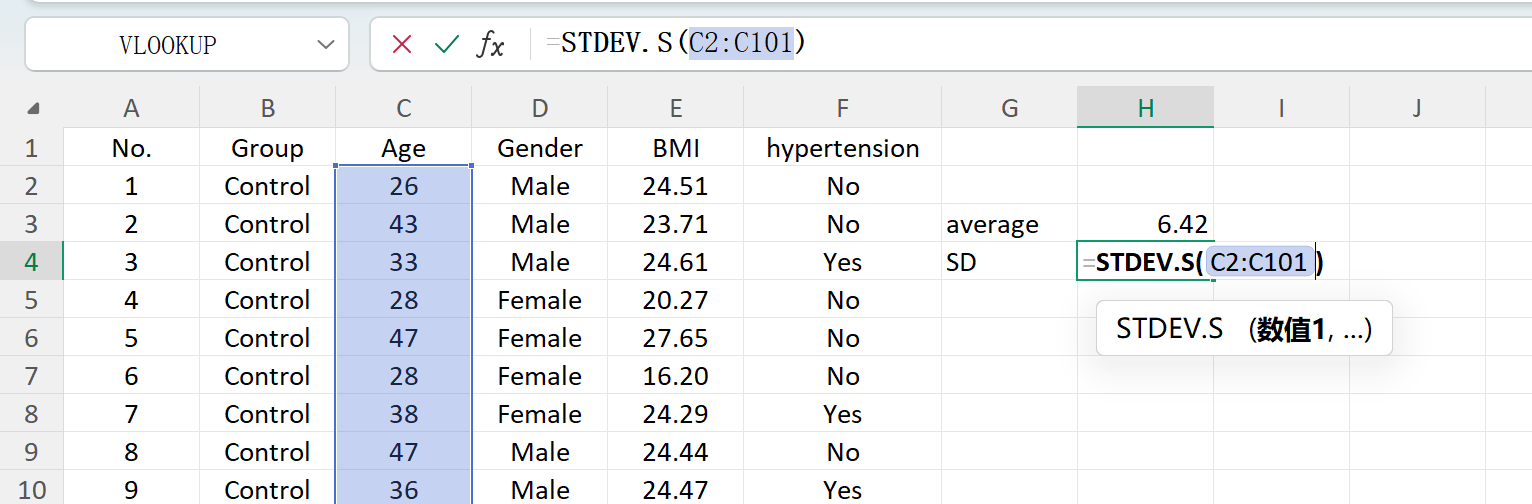
Figure 1.7 : Calcul de l'écart-type dans Excel
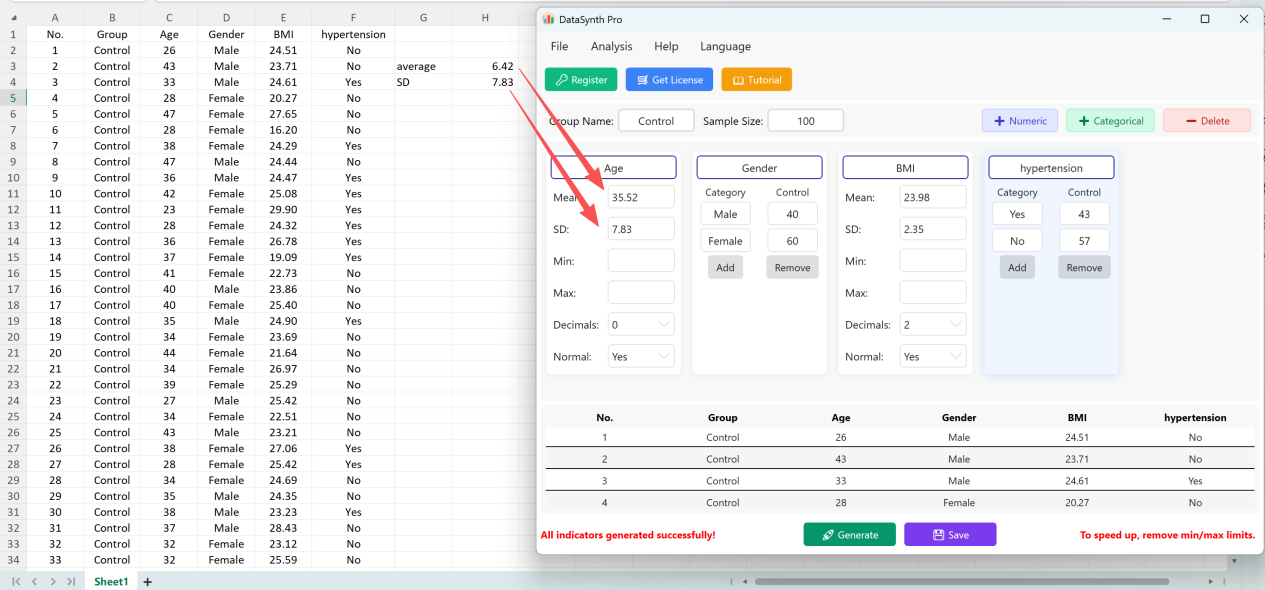
Figure 1.8 : Résultats de vérification identiques aux paramètres initiaux
1.6 Efficacité algorithmique
Équipé d'un moteur d'optimisation haute performance, le logiciel peut générer des ensembles de données contenant des milliers ou des dizaines de milliers d'enregistrements en quelques secondes seulement. Si le système ne parvient pas à converger après le nombre maximal d'itérations, veuillez vérifier la cohérence statistique de votre configuration, ou essayez d'exécuter la génération sans limites Min/Max. Le programme prend en charge une précision décimale allant jusqu'à 8 chiffres pour répondre aux besoins de recherche scientifique spécialisée.
Conseils et recommandations :
• Préférence pour la distribution normale : Par défaut, les données suivent une distribution normale pour une analyse en aval fluide (ex. Tests t pour échantillons indépendants). Si vous préférez des ensembles de données non paramétriques ou à distribution personnalisée, changez simplement le paramètre Normal Distribution sur No.
2. Test t pour échantillons indépendants
Conçu pour les études transversales comparant les moyennes de deux groupes distincts. Très utilisé dans les essais cliniques (ex. comparaison de l'efficacité d'un traitement entre un groupe Traitement et un groupe Placebo) et les enquêtes sociologiques.
2.1 Flux de travail
Accédez à Analyze → Independent T-Test. La fenêtre de configuration se présente comme suit :
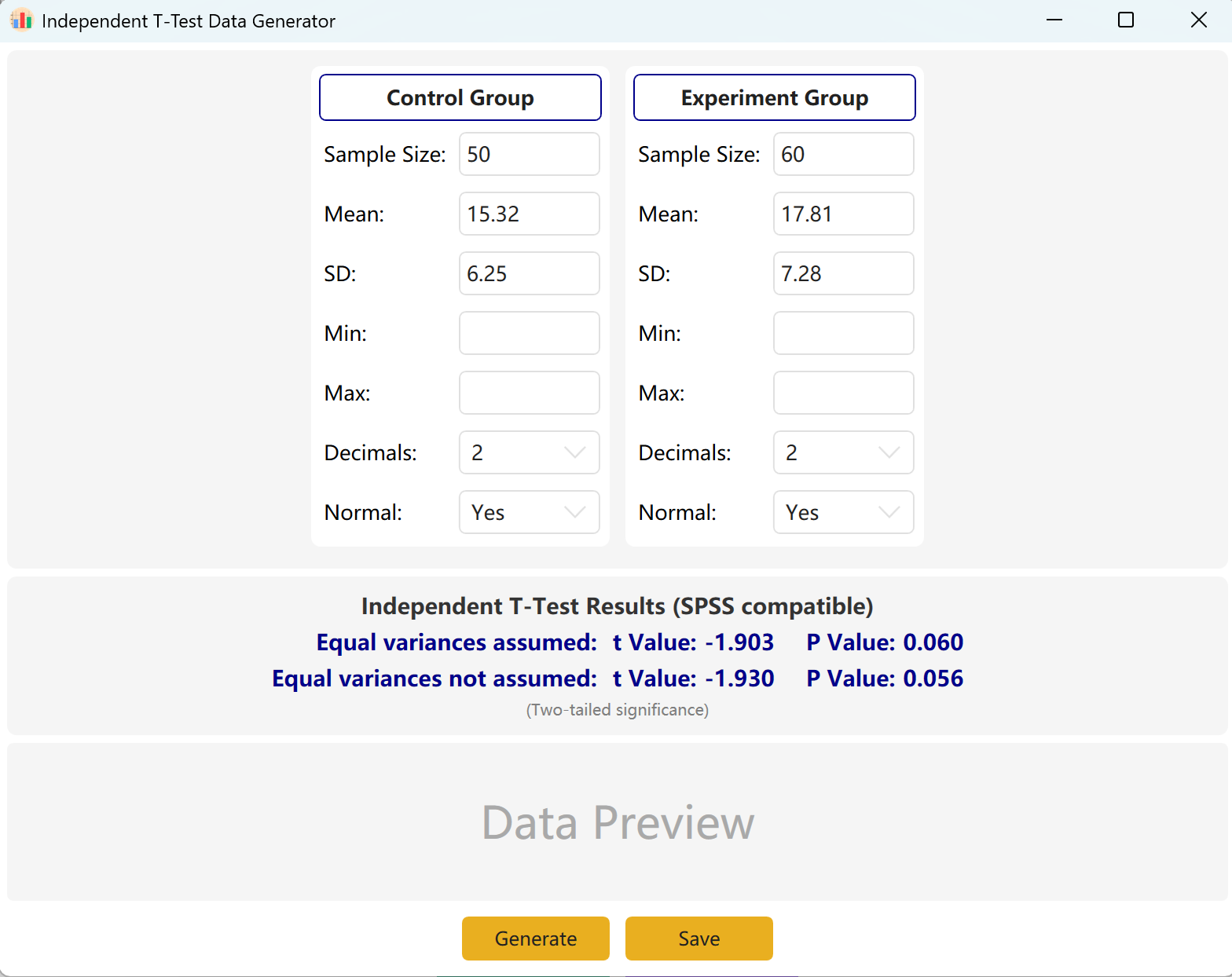
Figure 2.1 : Interface utilisateur / Opérations pour le Test t indépendant
2.2 Paramètres
Le programme pré-remplit des exemples pour un « Control Group » (Groupe témoin) et un « Experimental Group » (Groupe expérimental) à titre de référence. Saisissez la taille de l'échantillon, la moyenne et l'écart-type de chaque groupe pour prévisualiser instantanément la valeur t et la valeur p en temps réel. Les paramètres de Min et Max sont facultatifs.
Cliquez sur le bouton Generate pour créer les jeux de données bruts des deux groupes dans la table de prévisualisation ci-dessous. Les valeurs t et p finales seront automatiquement ajustées pour refléter les données réellement générées en utilisant le test d'égalité des variances de Levene.
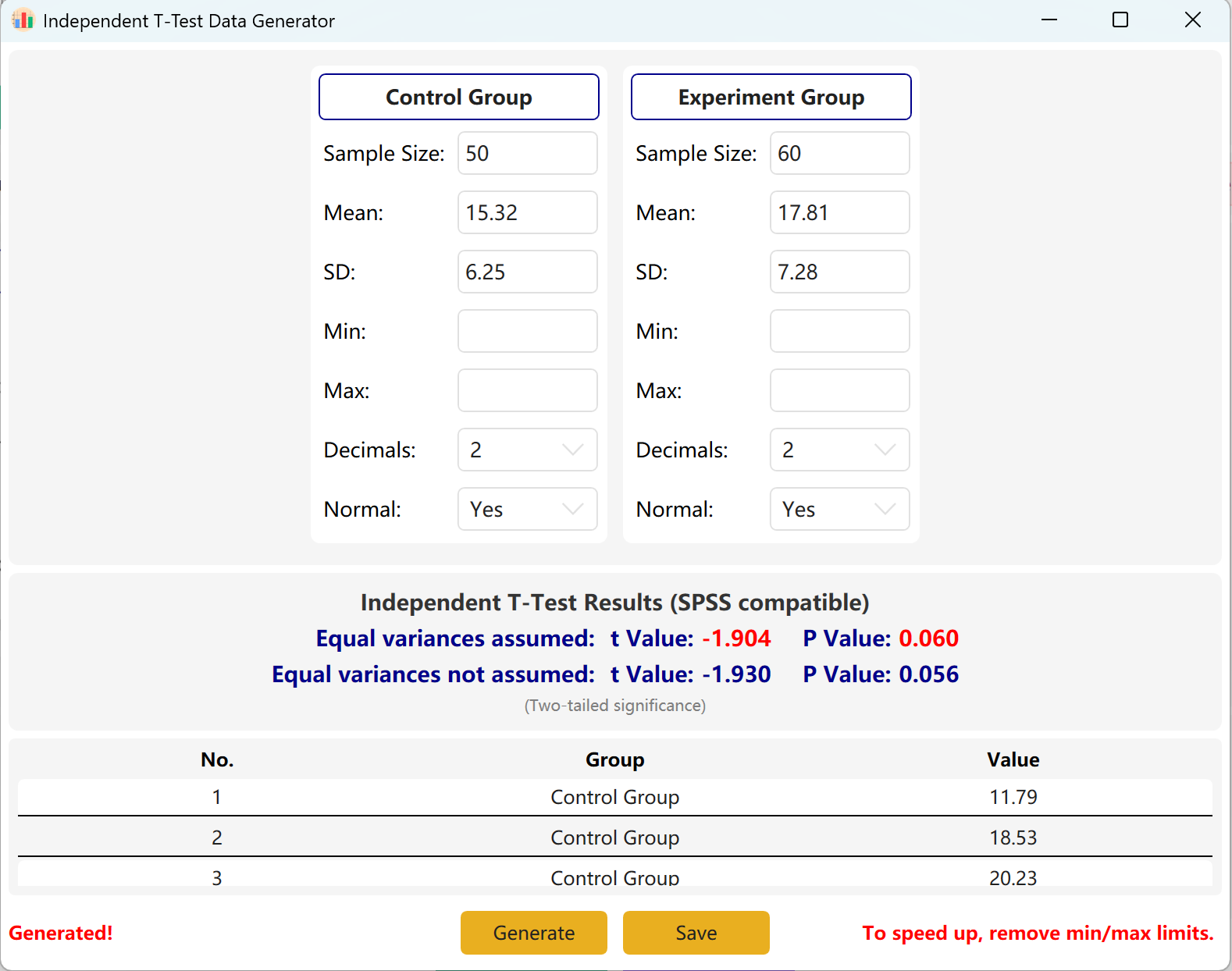
Figure 2.2 : Interface utilisateur / Affichage des données du Test t pour échantillons indépendants
3. Test t pour échantillons appariés
Employé pour les études longitudinales ou croisées où les mêmes sujets sont mesurés deux fois (ex. Pré-test vs Post-test). Se concentre sur la synthèse de la différence moyenne entre les observations appariées.
3.1 Flux de travail
Accédez à Analyze → Paired T-Test. L'espace de travail est structuré ainsi :
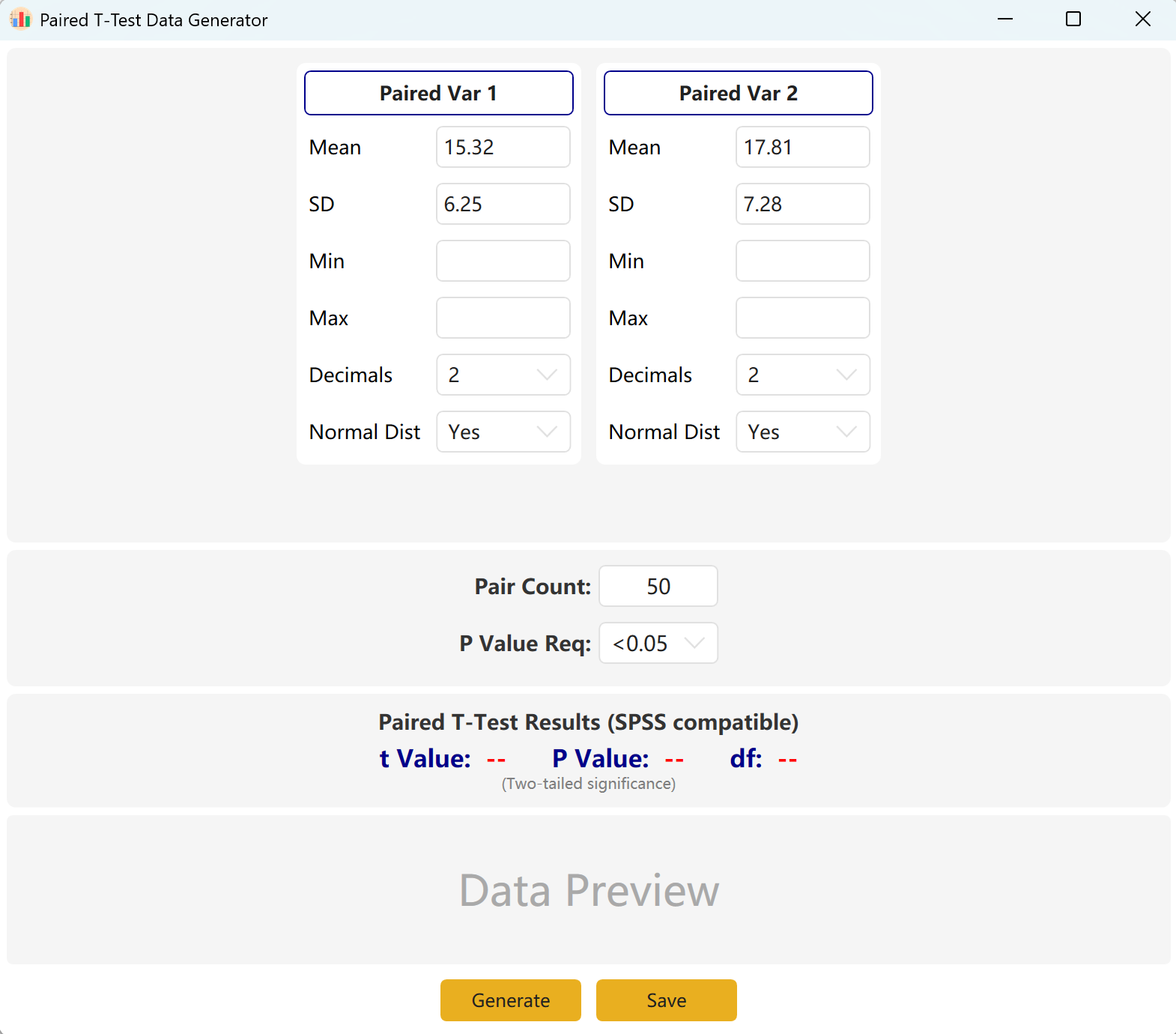
Figure 3.1 : Interface utilisateur / Opérations pour le Test t apparié
3.2 Logique de simulation
Le logiciel configure par défaut deux variables appariées, Paired Var1 et Paired Var2. Vous pouvez définir la moyenne et l'écart-type de chaque variable, fixer la taille globale de l'échantillon et établir un intervalle cible de p-value pour le test t apparié. Le moteur calculera ensuite de manière itérative un ensemble de données conforme.
Adaptation de convergence : Si les moyennes configurées sont mathématiquement incompatibles avec la p-value ciblée (par exemple, si les deux moyennes sont très éloignées mais que vous demandez une p-value non significative p > 0,05), le programme conservera les paramètres du premier groupe et ajustera dynamiquement la moyenne du second groupe afin d'atteindre la p-value ciblée.
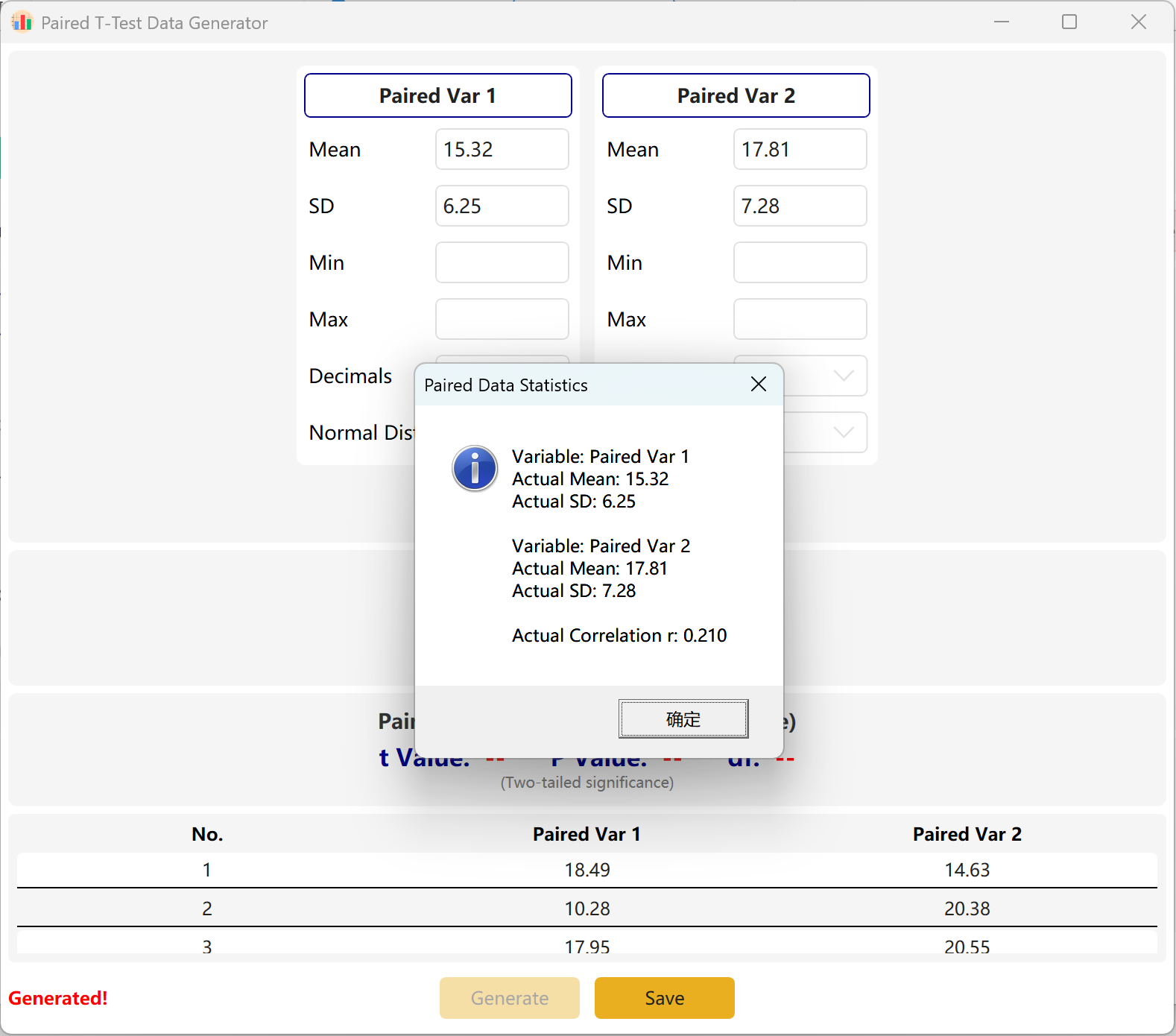
Figure 3.2 : Interface utilisateur / Affichage des données du Test t pour échantillons appariés
4. Test du Khi-deux
Permet de déterminer s'il existe une association significative entre deux variables catégorielles. Très utilisé pour les croisements de données démographiques.
4.1 Flux de travail
Accédez à Analyze → Chi-Square Test. Le panneau de configuration se présente ainsi :
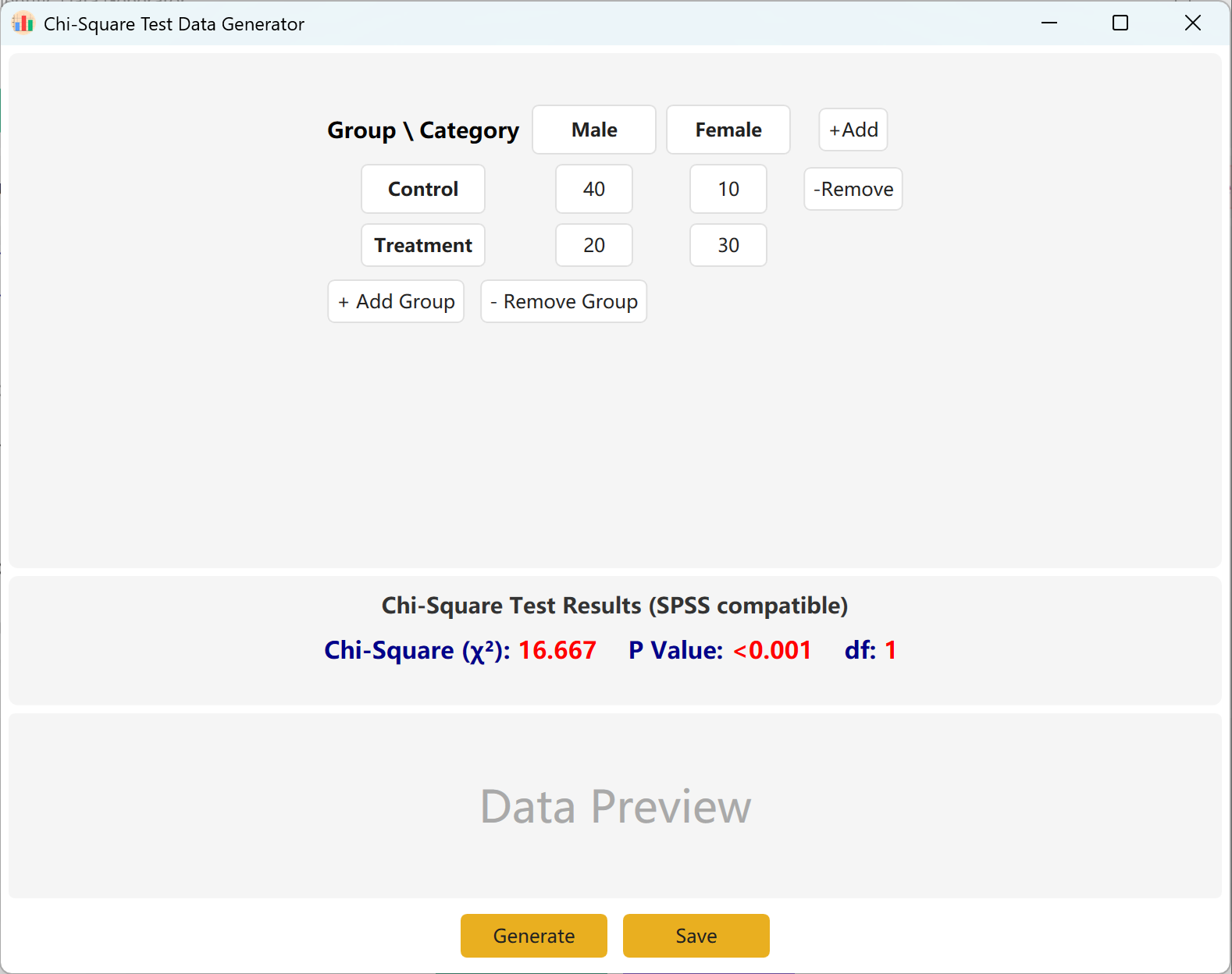
Figure 4.1 : Interface utilisateur / Opérations pour le Test du Khi-deux
4.2 Tableau de contingence
L'interface propose par défaut un tableau de contingence standard 2x2 pour le calcul du Khi-deux, où les noms des groupes et des catégories sont entièrement modifiables. Remplissez les effectifs observés (comptages) pour chaque cellule, et la valeur calculée du Khi-deux ainsi que la p-value se mettront à jour en temps réel.
Vous pouvez ajouter dynamiquement des groupes (lignes) ou des catégories (colonnes) pour adapter des modèles plus complexes. Cliquez sur le bouton Generate pour produire les enregistrements individuels correspondants à ces effectifs, puis cliquez sur Save pour exporter l'ensemble de données vers Excel.
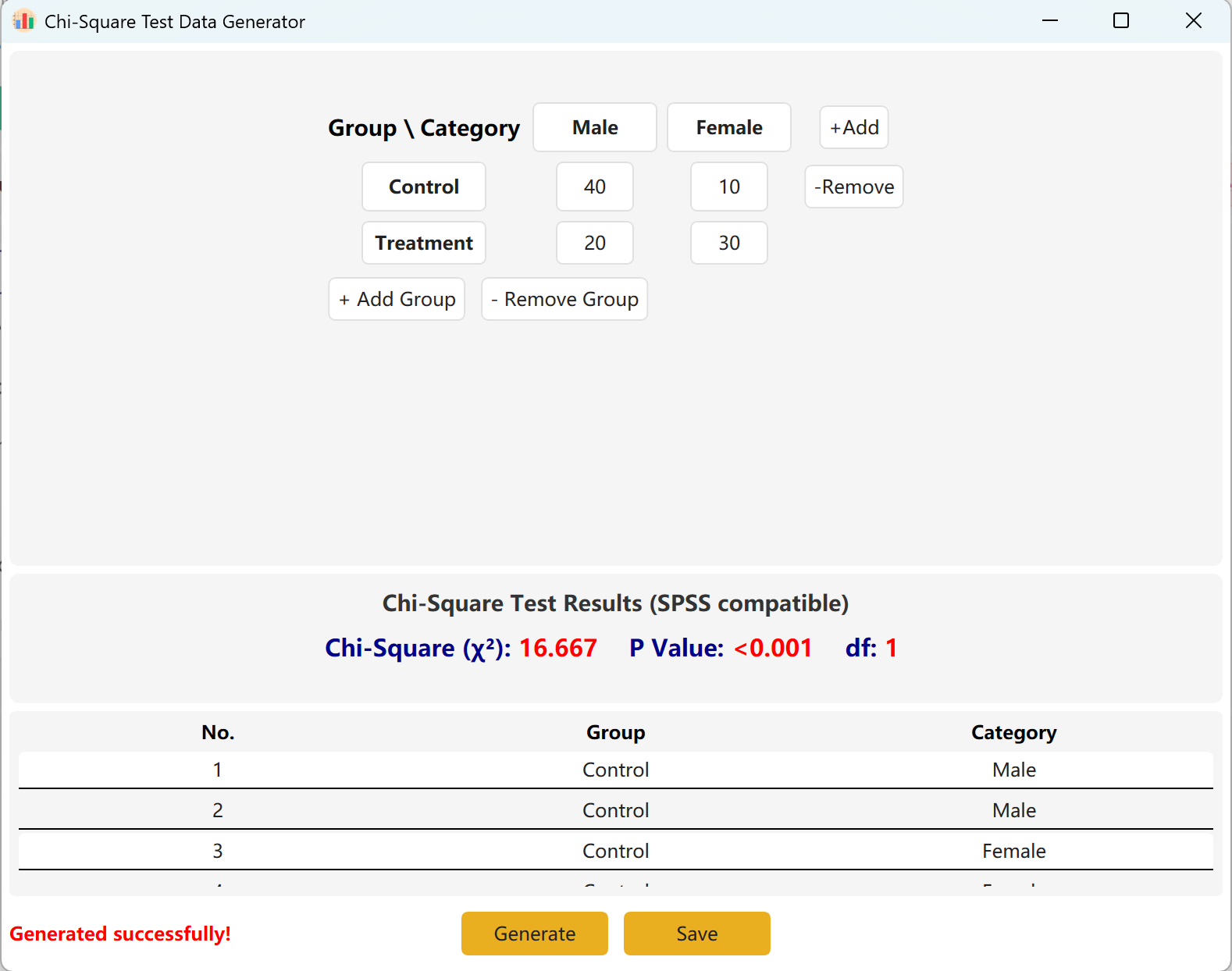
Figure 4.2 : Interface utilisateur / Affichage des données du Test du Khi-deux
5. ANOVA à un facteur
Utilisé lors de la comparaison des moyennes de trois groupes indépendants ou plus. L'algorithme synthétise la variance intra-groupe et les différences inter-groupes afin de respecter les valeurs de F cibles.
5.1 Flux de travail
Accédez à Analyze → ANOVA → One-Way ANOVA. L'espace de travail est présenté ci-dessous :
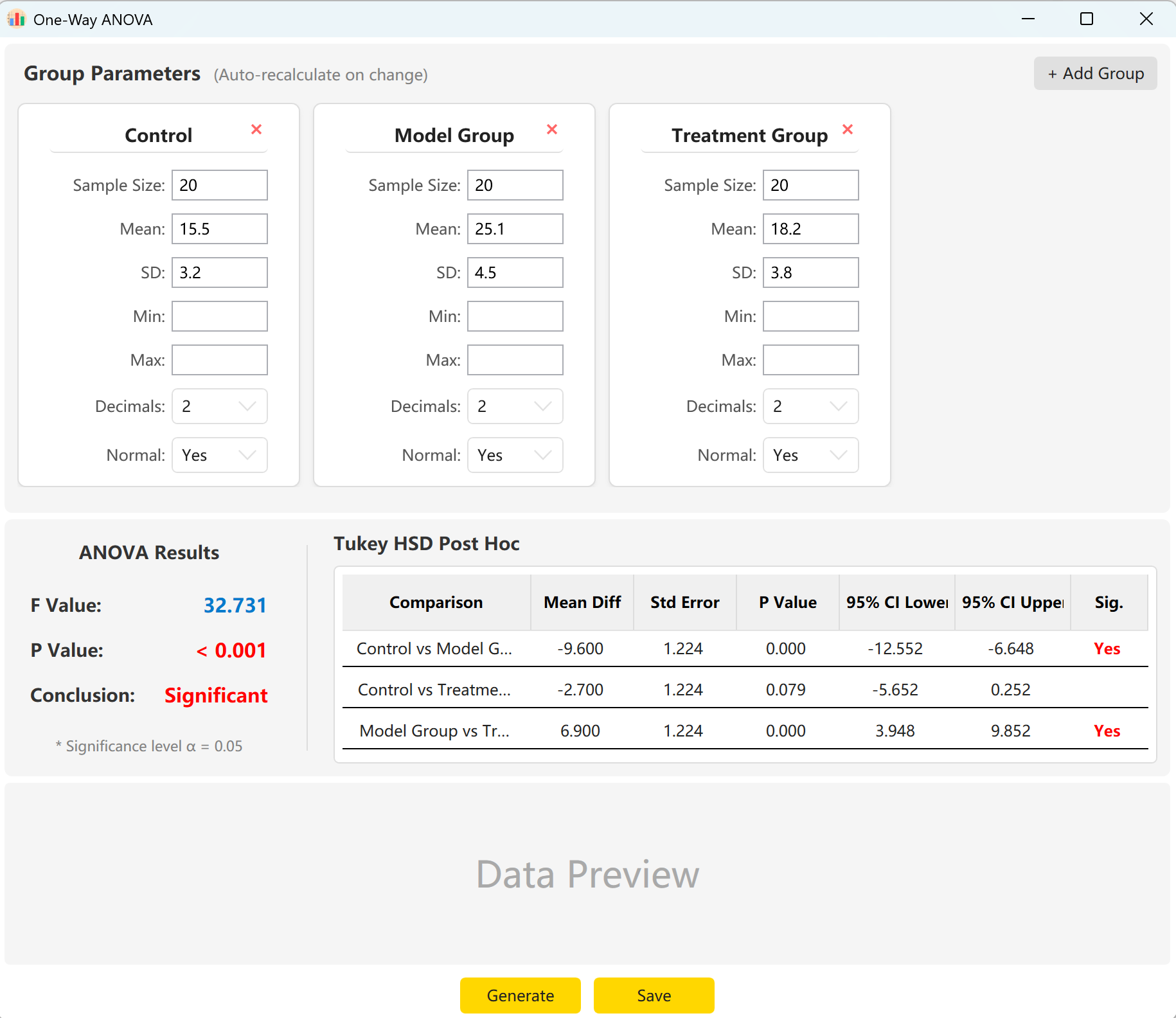
Figure 5.1 : Interface utilisateur / Opérations pour l'ANOVA à un facteur
5.2 Configuration
Le système pré-charge les paramètres de trois groupes : « Control Group » (Groupe témoin), « Experimental Group » (Groupe expérimental) et « Treatment Group » (Groupe sous traitement). Saisissez simplement la taille de l'échantillon, la moyenne et l'écart-type de chaque groupe pour visualiser instantanément la statistique globale F, la p-value et les résultats de comparaison multiple post-hoc HSD de Tukey.
Cliquez sur le bouton Generate pour calculer et prévisualiser les enregistrements bruts individuels ci-dessous. Les valeurs F et p globales se mettront automatiquement à jour pour refléter les données réellement générées.
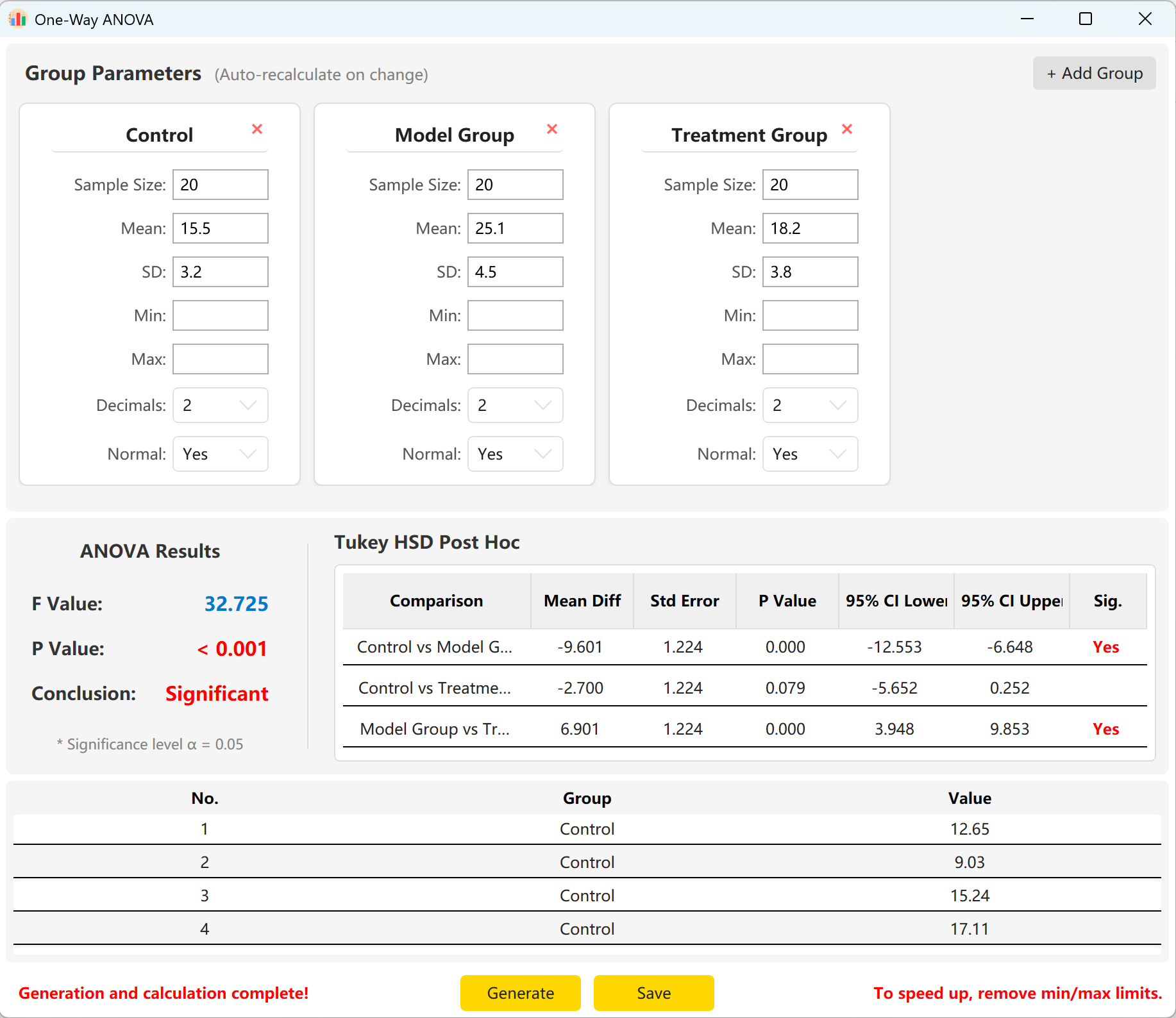
Figure 5.2 : Interface utilisateur / Affichage des données de l'ANOVA à un facteur
6. ANOVA à deux facteurs
Examine l'influence de deux variables indépendantes catégorielles sur une variable dépendante continue. Essentiel pour les plans factoriels afin d'évaluer les effets principaux ainsi que les effets d'interaction.
6.1 Flux de travail
Accédez à Analyze → ANOVA → Two-Way ANOVA. Le panneau de configuration s'affiche ainsi :
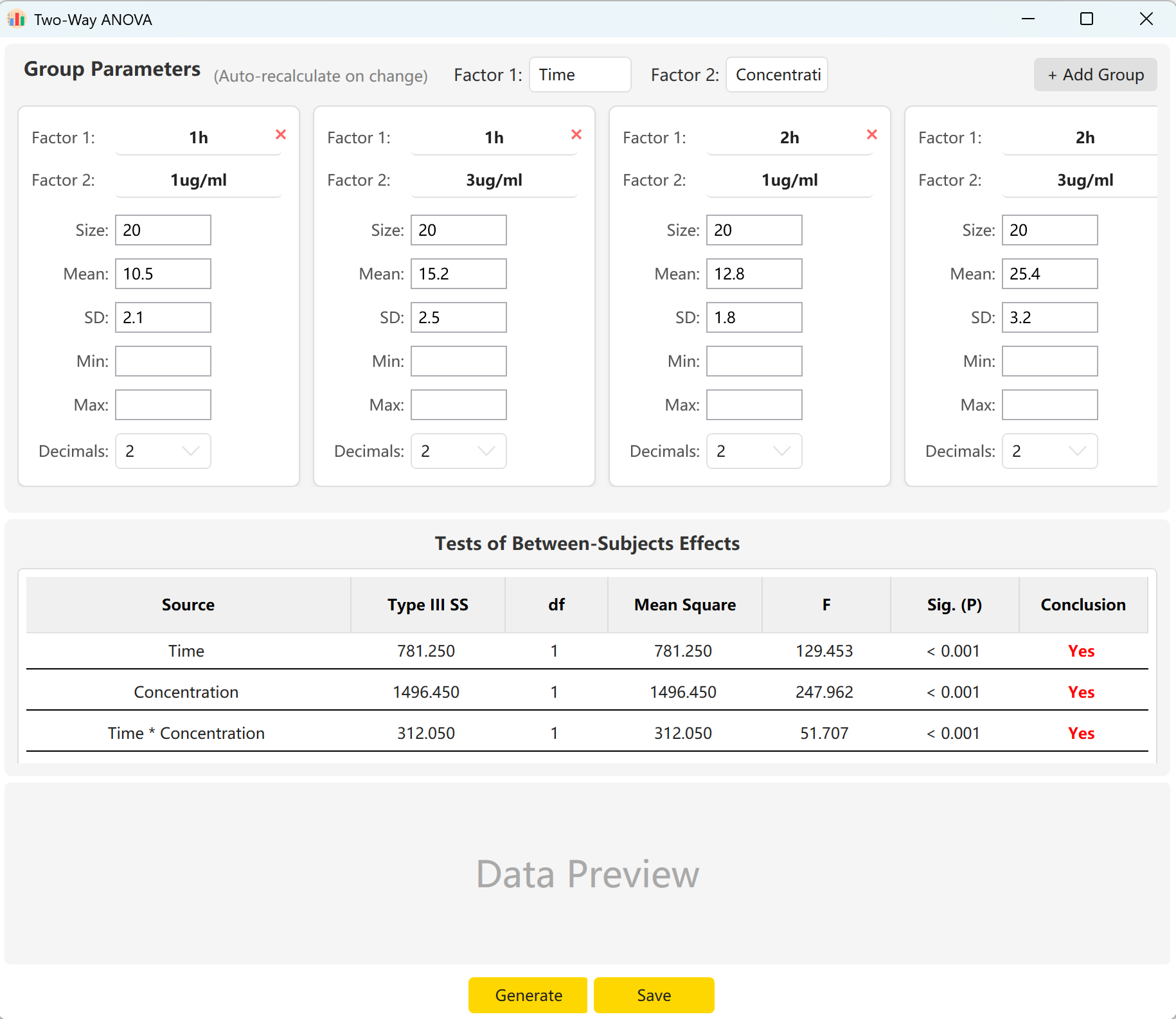
Figure 6.1 : Interface utilisateur / Opérations pour l'ANOVA à deux facteurs
6.2 Facteurs et interactions
L'outil est configuré par défaut avec deux facteurs : « Time » (Temps - 2 niveaux) et « Concentration » (Concentration - 2 niveaux). Cliquez sur Add Group pour configurer davantage de niveaux si l'un de vos facteurs contient plusieurs catégories.
En saisissant la taille d'échantillon, la moyenne et l'écart-type de chaque cellule, vous pouvez obtenir un aperçu en temps réel des statistiques F et des p-values pour l'effet principal du Temps, l'effet principal de la Concentration ainsi que leur effet d'interaction (Temps × Concentration). Cliquez sur le bouton Generate pour élaborer les enregistrements bruts correspondants dans le volet de prévisualisation.
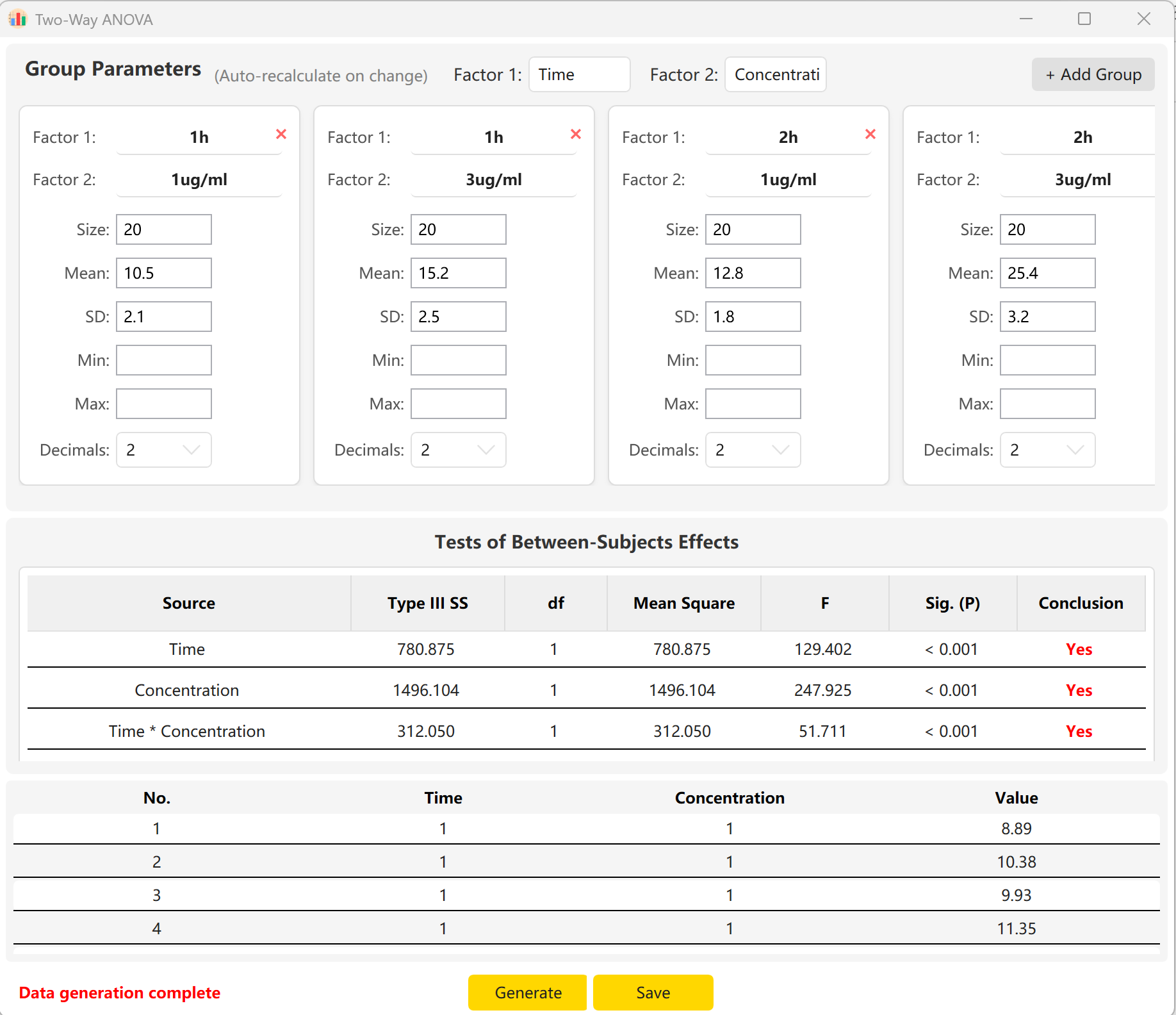
Figure 6.2 : Interface utilisateur / Affichage des données de l'ANOVA à deux facteurs
7. ANOVA à mesures répétées à un facteur
L'extension du Test t apparié à trois points d'observation ou plus. Idéal pour le suivi longitudinal sur des périodes prolongées (ex. mesure initiale, mois 1, mois 3).
7.1 Flux de travail
Accédez à Analyze → ANOVA → Repeated Measures ANOVA. L'espace de travail est présenté ci-dessous :
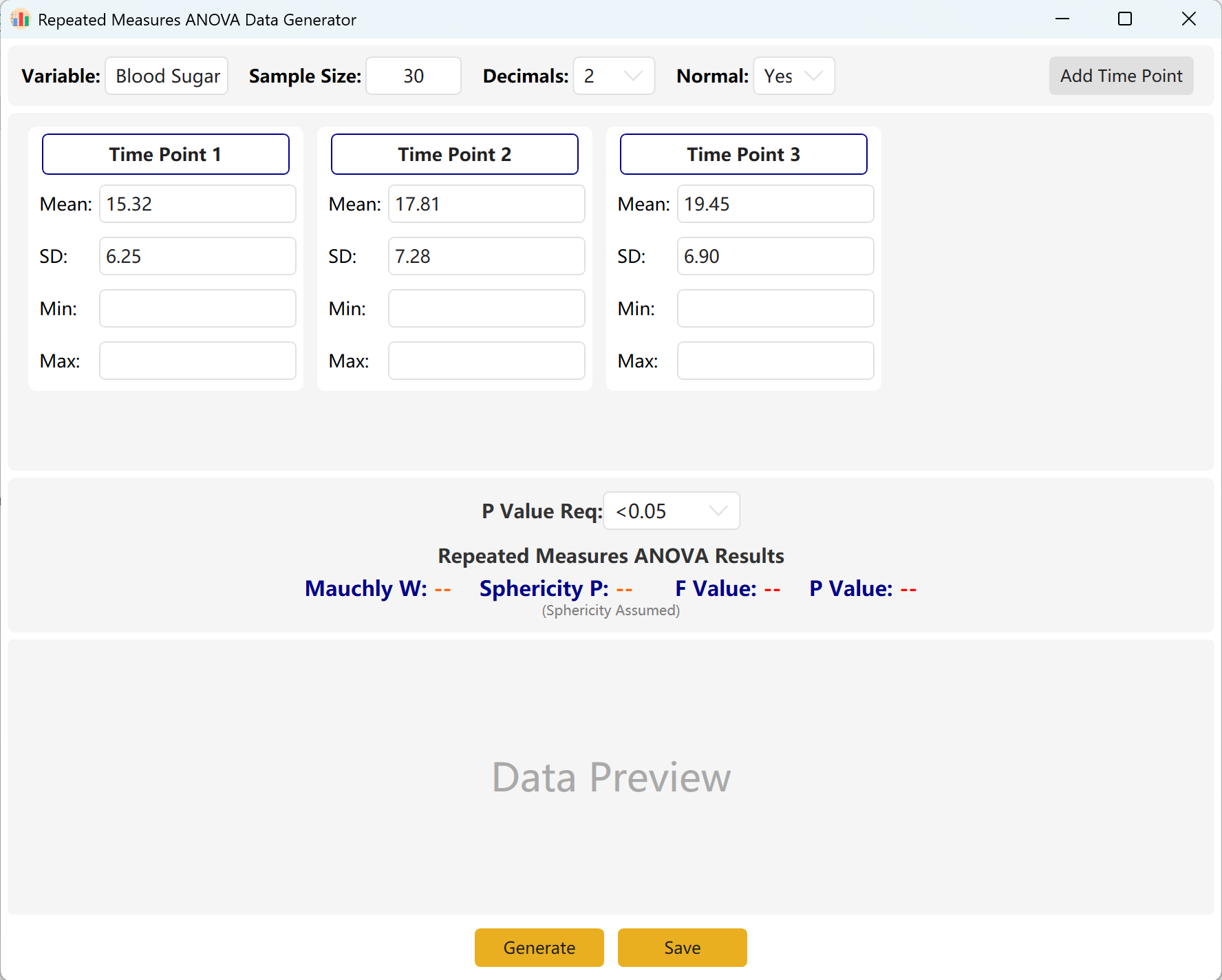
Figure 7.1 : Interface utilisateur / Opérations pour l'ANOVA à mesures répétées à un facteur
7.2 Observations répétées
Le système est configuré par défaut avec trois points d'observation temporels. Vous pouvez facilement augmenter ce nombre en cliquant sur le bouton Add Time Point. Saisissez la moyenne et l'écart-type de chaque point d'observation et définissez votre intervalle de p-value cible.
Cliquez sur le bouton Generate pour synthétiser des valeurs conformes.
Adaptation de variance du moteur : Si la différence entre les points d'observation est mathématiquement énorme (indiquant une p-value extrêmement significative) alors que votre intervalle cible est fixé à p > 0,05, le moteur comprimera automatiquement les variances et les écarts de moyennes entre les points temporels pour atteindre précisément votre cible. Une boîte de dialogue affichera les statistiques réelles obtenues.
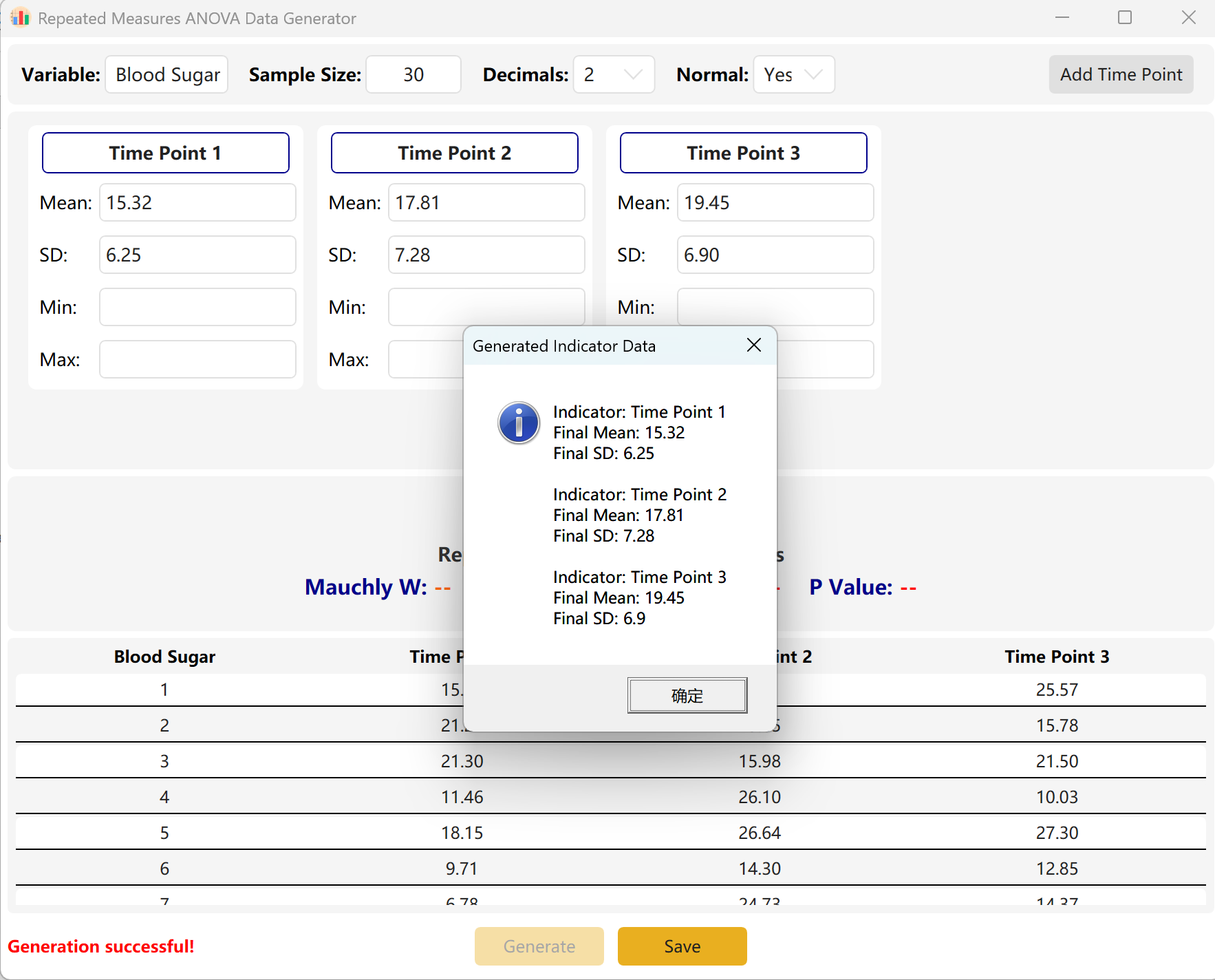
Figure 7.2 : Interface utilisateur / Affichage des données de l'ANOVA à mesures répétées
8. Test de somme des rangs pour deux échantillons indépendants (Non paramétrique)
L'équivalent du test U de Mann-Whitney lorsque les données ne satisfont pas aux hypothèses de normalité. Évalue les différences de médianes selon une logique d'ordonnancement par rangs sur des variables continues ou ordinales.
8.1 Flux de travail
Accédez à Analyze → Non-parametric → 2 Independent Samples. L'espace de configuration se présente ainsi :
1.png)
Figure 8.1 : Interface utilisateur / Opérations pour le Test de somme des rangs pour deux échantillons indépendants
8.2 Configuration
Le programme propose par défaut deux groupes de référence. Étant donné que les méthodes non paramétriques sont destinées aux données qui ne suivent pas une distribution normale, l'option Normal Distribution est définie sur No par défaut. En vous basant sur le test U de Mann-Whitney, vous pouvez définir une p-value cible. Cliquez sur le bouton Generate pour synthétiser des observations brutes qui respectent ce seuil statistique.
Logique de génération par somme des rangs : Les tests non paramétriques analysent les différences de groupes en regroupant toutes les observations et en leur attribuant des rangs. Par conséquent, si les paramètres configurés pour vos deux groupes présentent de grands écarts (ce qui donnerait naturellement une p-value minuscule) alors que vous demandez une cible p > 0,05, le moteur réduira de lui-même la divergence entre les groupes. Les moyennes et écarts-types finaux calculés s'afficheront dans une boîte de dialogue.
2.png)
Figure 8.2 : Interface utilisateur / Affichage des données du Test de somme des rangs pour deux échantillons indépendants
9. Test de Kruskal-Wallis (K échantillons indépendants non paramétriques)
Équivalent du test H de Kruskal-Wallis. Génère des données ordinales ou des données continues non normales réparties sur trois groupes indépendants ou plus.
9.1 Flux de travail
Accédez à Analyze → Non-parametric → K Independent Samples. L'espace de configuration est illustré ci-dessous :
1.png)
Figure 9.1 : Interface utilisateur / Opérations pour le Test de Kruskal-Wallis
9.2 Classement multi-groupe
Le programme propose par défaut trois groupes de référence et exécute un test de Kruskal-Wallis. Tout comme le test à deux groupes, puisque les calculs reposent sur les rangs d'un échantillon global fusionné, si les paramètres configurés pour vos différents groupes montrent des écarts massifs (donnant des p-values hautement significatives) alors que vous demandez une cible p > 0,05, le moteur de simulation atténuera automatiquement les différences inter-groupes. Les statistiques correspondantes s'afficheront dans une fenêtre pop-up.
2.png)
Figure 9.2 : Interface utilisateur / Affichage des données du Test de Kruskal-Wallis
10. Génération de données par quartiles
Divise un ensemble de données ordonnées en quatre parties égales. Utile pour évaluer la dispersion et la tendance centrale des données, mettre en évidence la médiane et détecter les valeurs aberrantes.
10.1 Flux de travail
Accédez à Analyze → Quartile Data. La mise en page se présente comme suit :
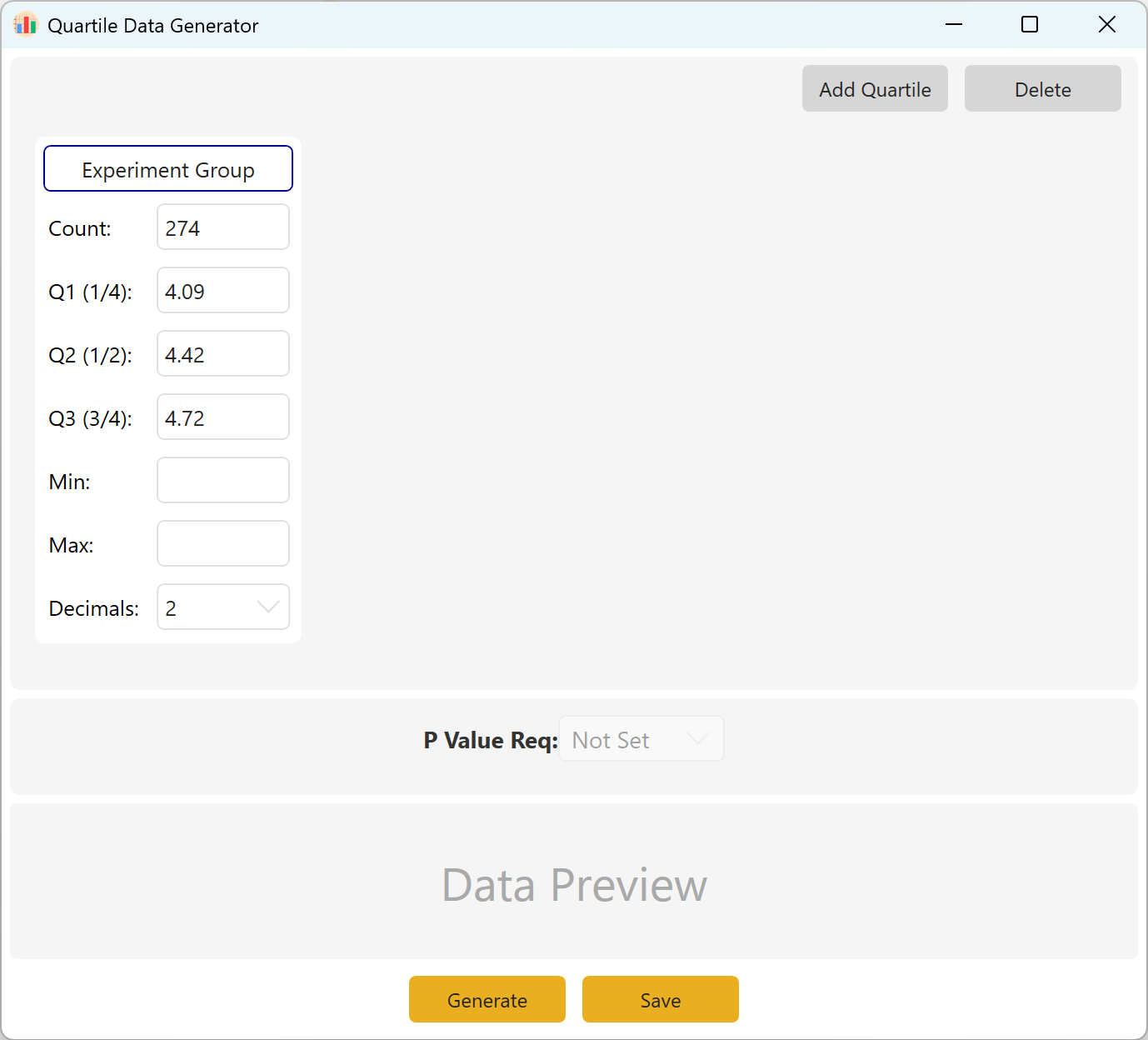
Figure 10.1 : Interface utilisateur / Opérations pour les Données par quartiles
10.2 Définition des paramètres
Définissez la taille d'échantillon ciblée, le premier quartile Q1 (25e percentile), la médiane Q2 (50e percentile) et le troisième quartile Q3 (75e percentile). Les champs Min/Max peuvent rester vides si aucune contrainte spécifique ne s'applique. Choisissez votre nombre de décimales puis cliquez sur le bouton Generate pour produire les observations répondant exactement à ces limites de quartiles.
Résumé : Configurez la taille de l'échantillon ainsi que les valeurs cibles pour Q1, Q2 et Q3. Les paramètres facultatifs comprennent le Minimum, le Maximum et le Nombre de décimales. Cliquez sur le bouton Generate pour calculer et afficher les observations brutes correspondant à la structure de quartiles souhaitée. Pour les configurations multi-groupes, vous pouvez également définir un intervalle cible pour la p-value inter-groupe.
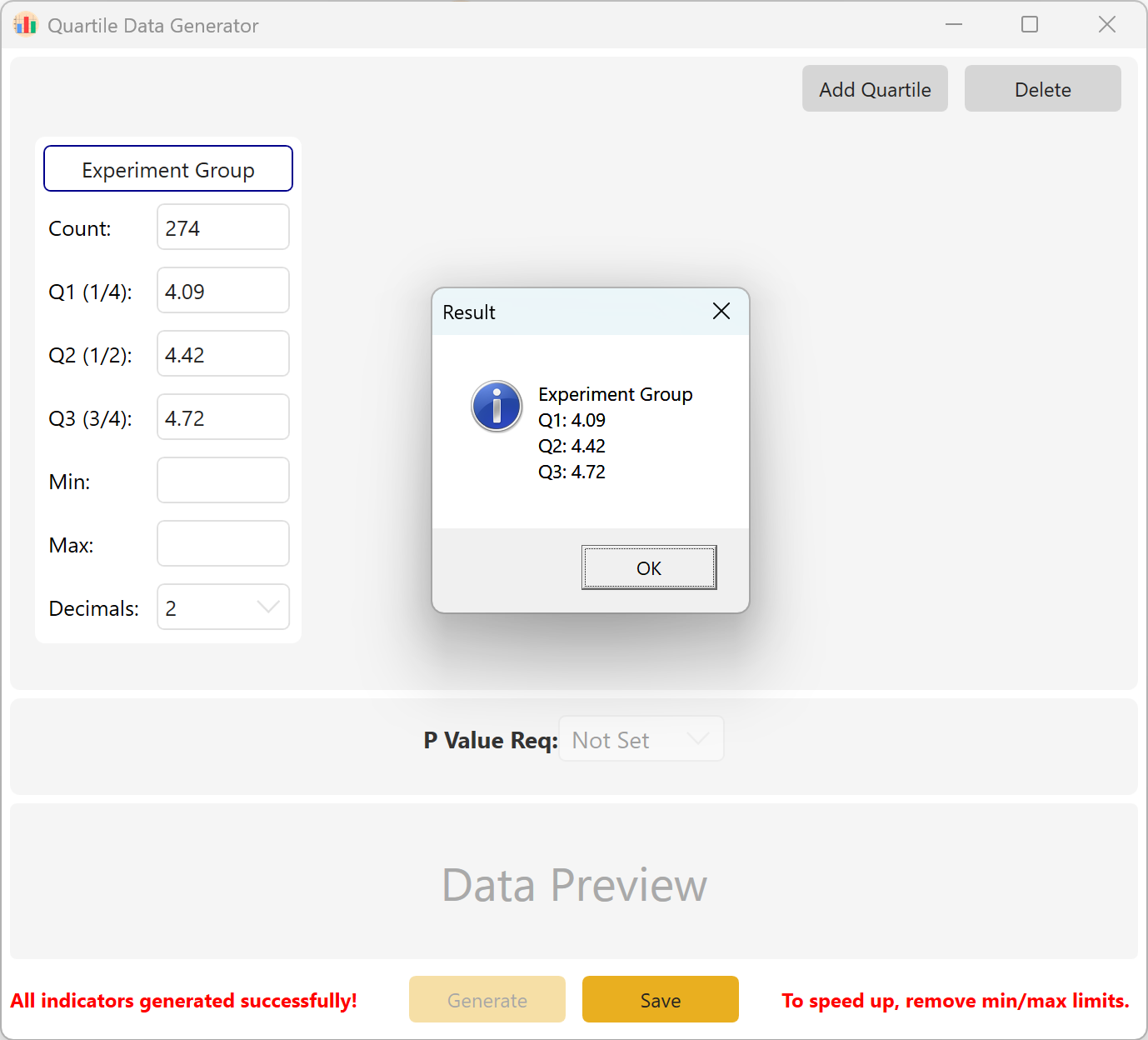
Figure 10.2 : Interface utilisateur / Affichage des données par quartiles
11. Génération de données de régression logistique binaire
Essentiel pour les problèmes de classification où la variable de résultat est dichotomique (VD=0 ou VD=1). Très courant en épidémiologie pour l'identification des facteurs de risque (ex. Malade vs Sain).
11.1 Flux de travail
Accédez à Analyze → Regression → Binary Logistic.
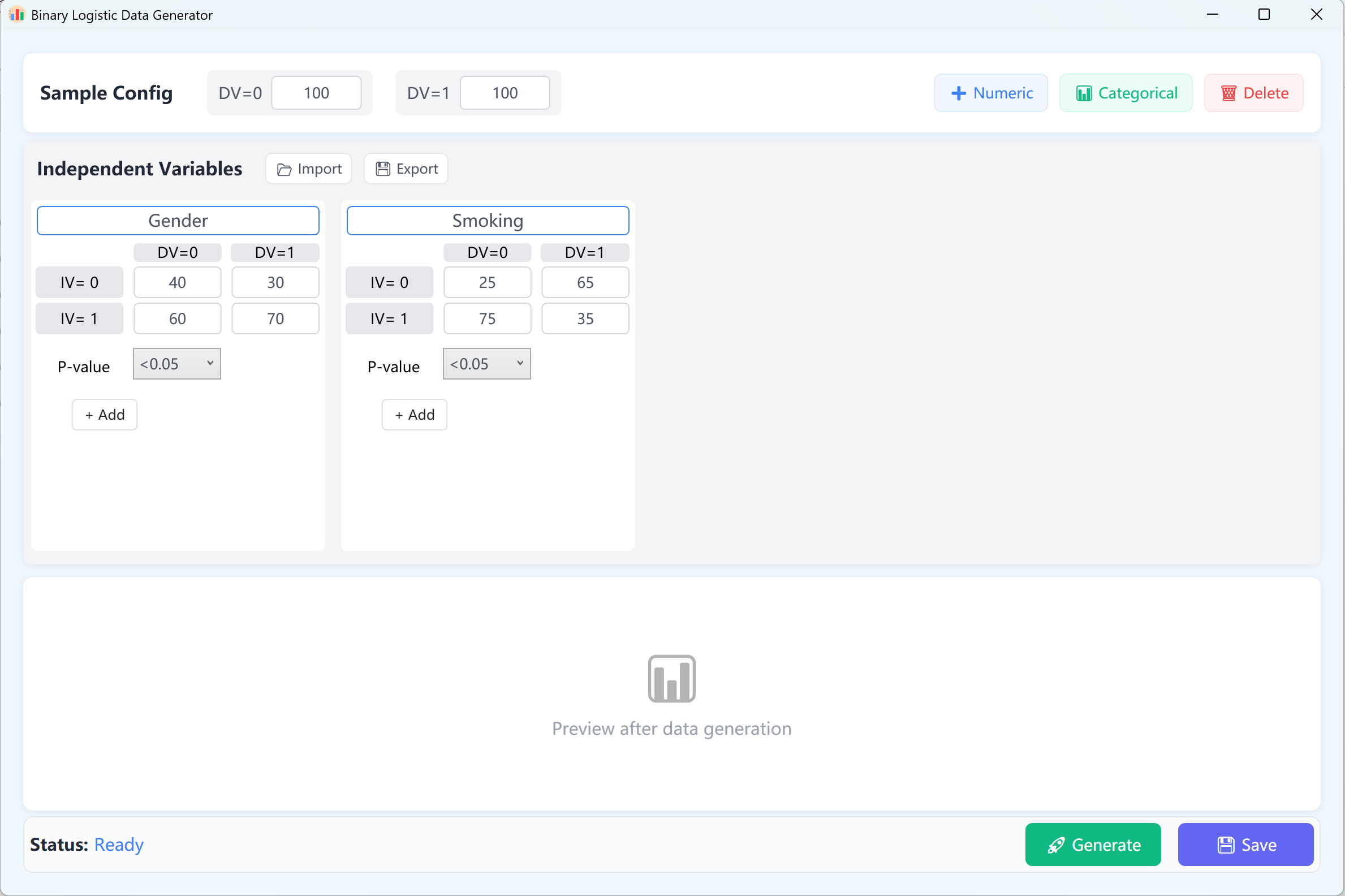
Figure 11.1 : Interface utilisateur / Opérations pour la Régression logistique binaire
11.2 Conception
Par défaut, deux variables indépendantes continues sont configurées à titre d'exemples. Dans un modèle logistique binaire, la variable dépendante ne possède que deux états possibles (0 et 1). Ainsi, la variable dépendante est structurée en groupes 0 et 1, avec par défaut une taille d'échantillon de 100 cas par catégorie (personnalisable).
- Configuration des variables : Cliquez sur + Numeric pour ajouter des variables indépendantes continues (ex. « Age », « BMI »). Indiquez le nom de la variable, sa Moyenne, son Écart-type, le Nombre de décimales et l'intervalle cible de la p-value (ce paramètre définit le niveau de significativité souhaité pour cette variable au sein du modèle final de régression logistique). Les limites Min/Max sont facultatives.
- Génération et validation : Cliquez sur le bouton Generate pour lancer l'algorithme de synthèse. Le système calculera de façon itérative un jeu de données pour lequel le modèle de régression logistique fournit des p-values conformes à votre configuration.
Un rapport d'analyse de régression détaillé reprenant exactement le format de sortie d'IBM SPSS s'affichera automatiquement dans une fenêtre contextuelle. La fermeture de ce rapport révèle les données brutes dans la table de prévisualisation, prêtes à être exportées dans Excel.
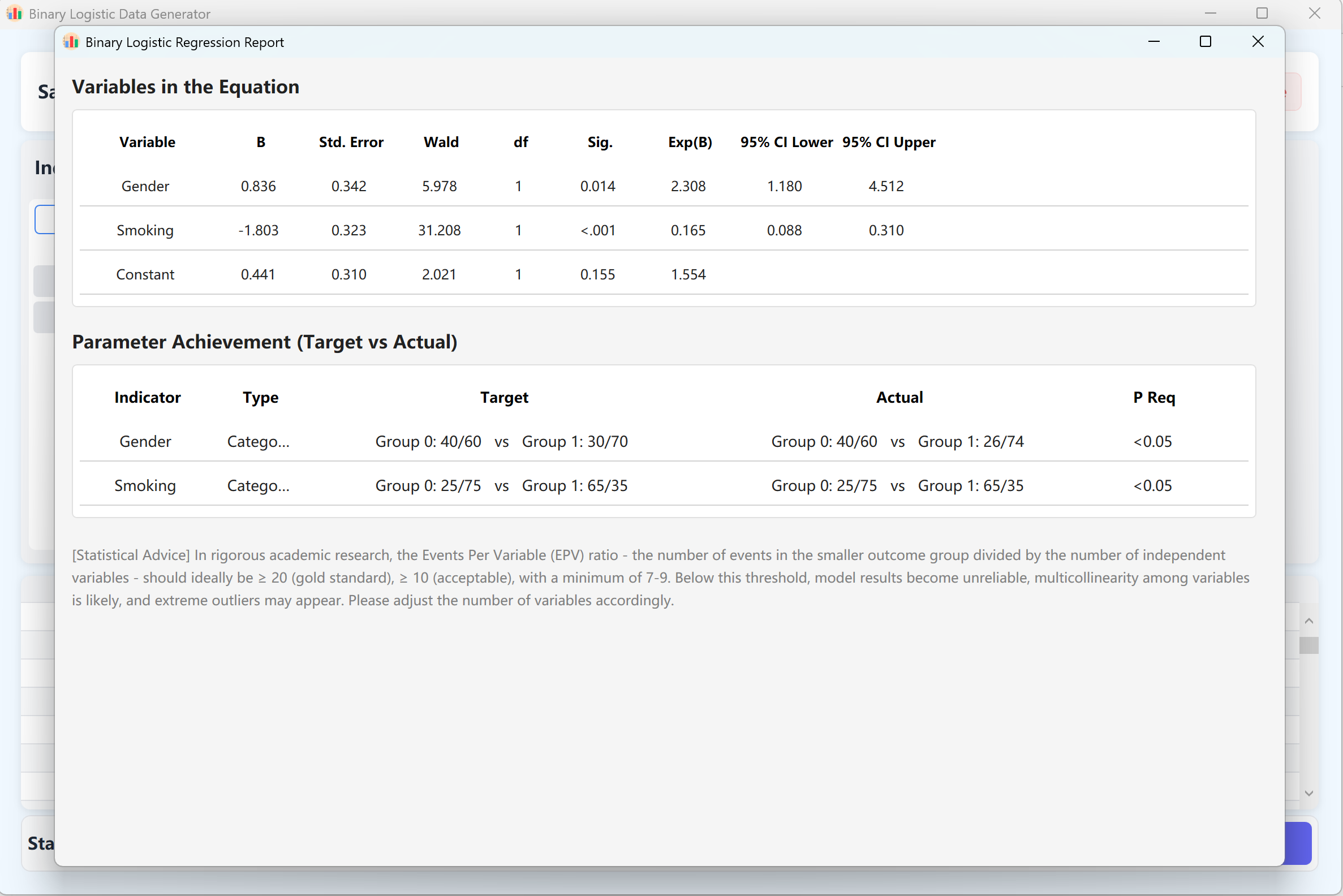
Figure 11.2 : Interface utilisateur / Affichage des données de la Régression logistique binaire
12. Génération de données de régression linéaire multiple
Un outil fondamental de modélisation prédictive. Il synthétise une variable dépendante continue (Y) influencée par plusieurs variables indépendantes (X). Ces dernières peuvent être de nature continue (numérique), par quartiles, catégorielles ordonnées (ordinales) ou non ordonnées (nominales).
12.1 Flux de travail
Accédez à Analyze → Regression → Linear Regression.
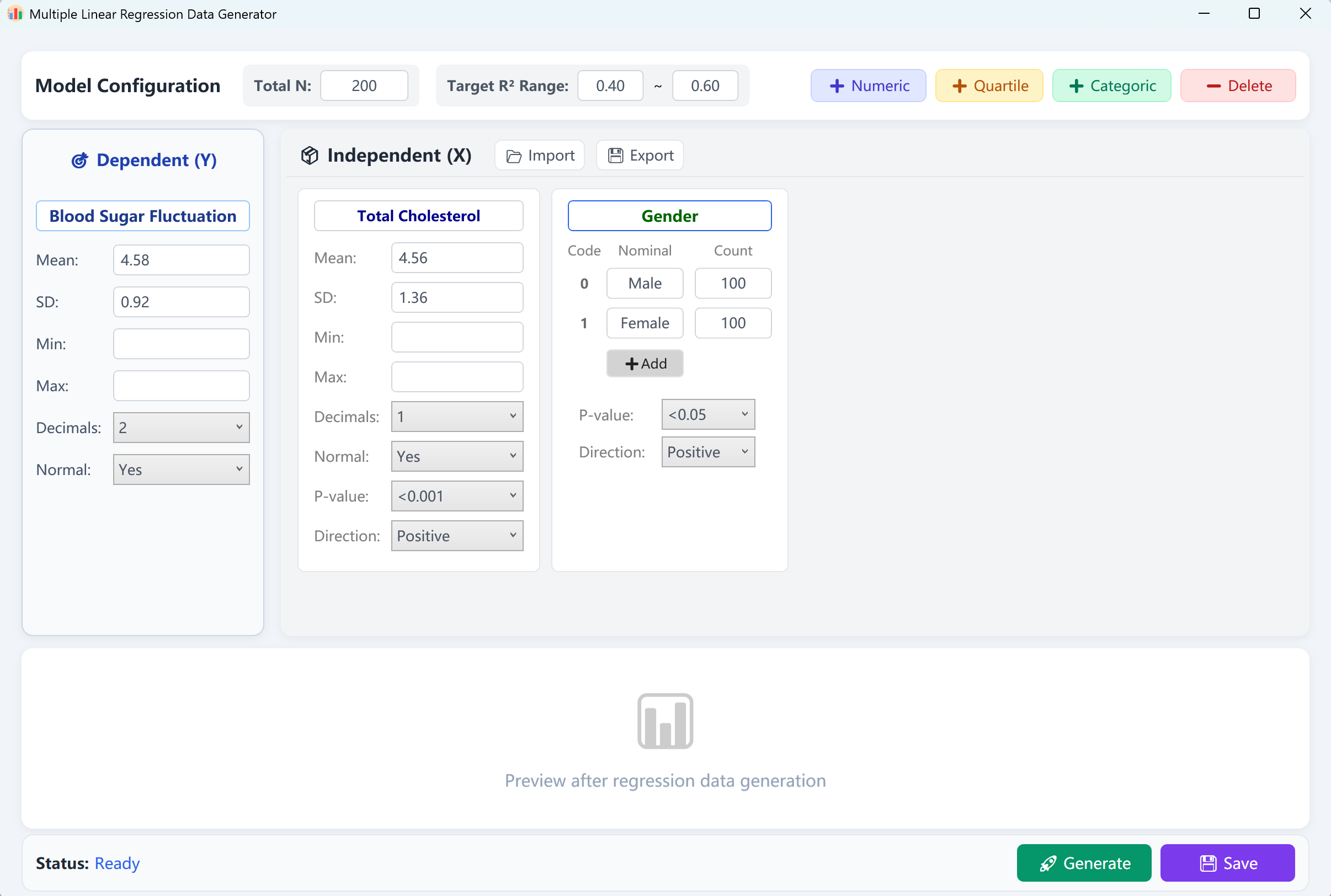
Figure 12.1 : Interface utilisateur / Opérations pour la Régression linéaire multiple
12.2 Paramètres du modèle
L'interface pré-charge une variable dépendante continue (« Blood Glucose Fluctuation » - Fluctuation de la glycémie) et deux variables indépendantes (« Total Cholesterol » - Cholestérol total en variable numérique, et « Gender » - Genre en variable catégorielle) avec une taille d'échantillon par défaut de 200 cas. Vous pouvez définir un intervalle cible pour le coefficient de détermination R-deux (R²) (ex. entre 0,4 et 0,6).
Cliquez sur le bouton Generate pour exécuter le modèle de régression. Un rapport de validation semblable aux résultats SPSS apparaîtra. En fermant ce rapport, vous retrouverez la table de prévisualisation des données brutes, prête à être sauvegardée au format Excel.
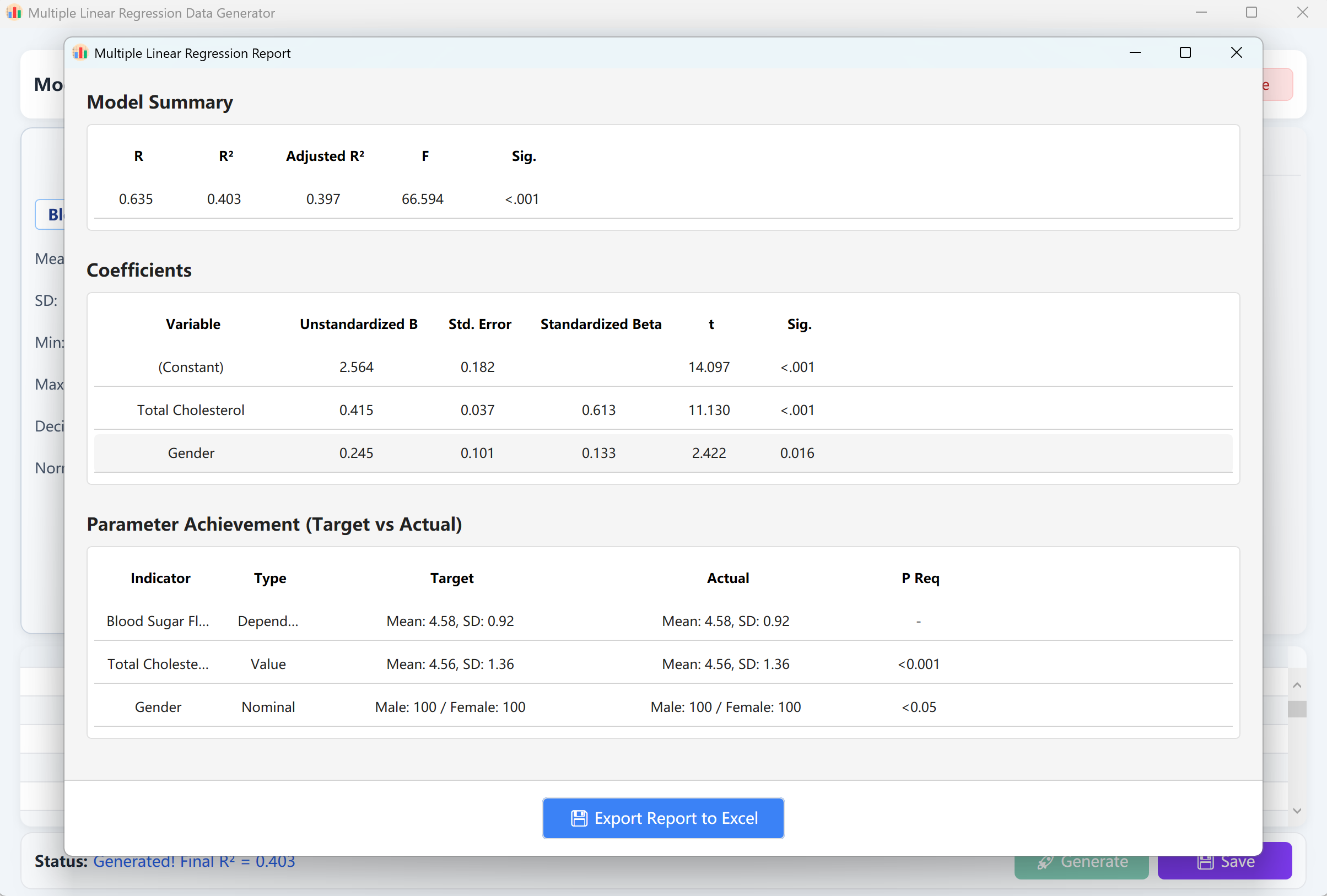
Figure 12.2 : Interface utilisateur / Affichage des données de la Régression linéaire multiple
13. Génération de données de régression des risques proportionnels de Cox
La référence absolue en analyse de survie. Simule des données de temps jusqu'à l'événement tout en tenant compte de la censure à droite, permettant aux chercheurs d'évaluer l'impact des covariables sur les temps de survie.
13.1 Flux de travail et directives techniques
Accédez à Analyze → Regression → Cox Regression.
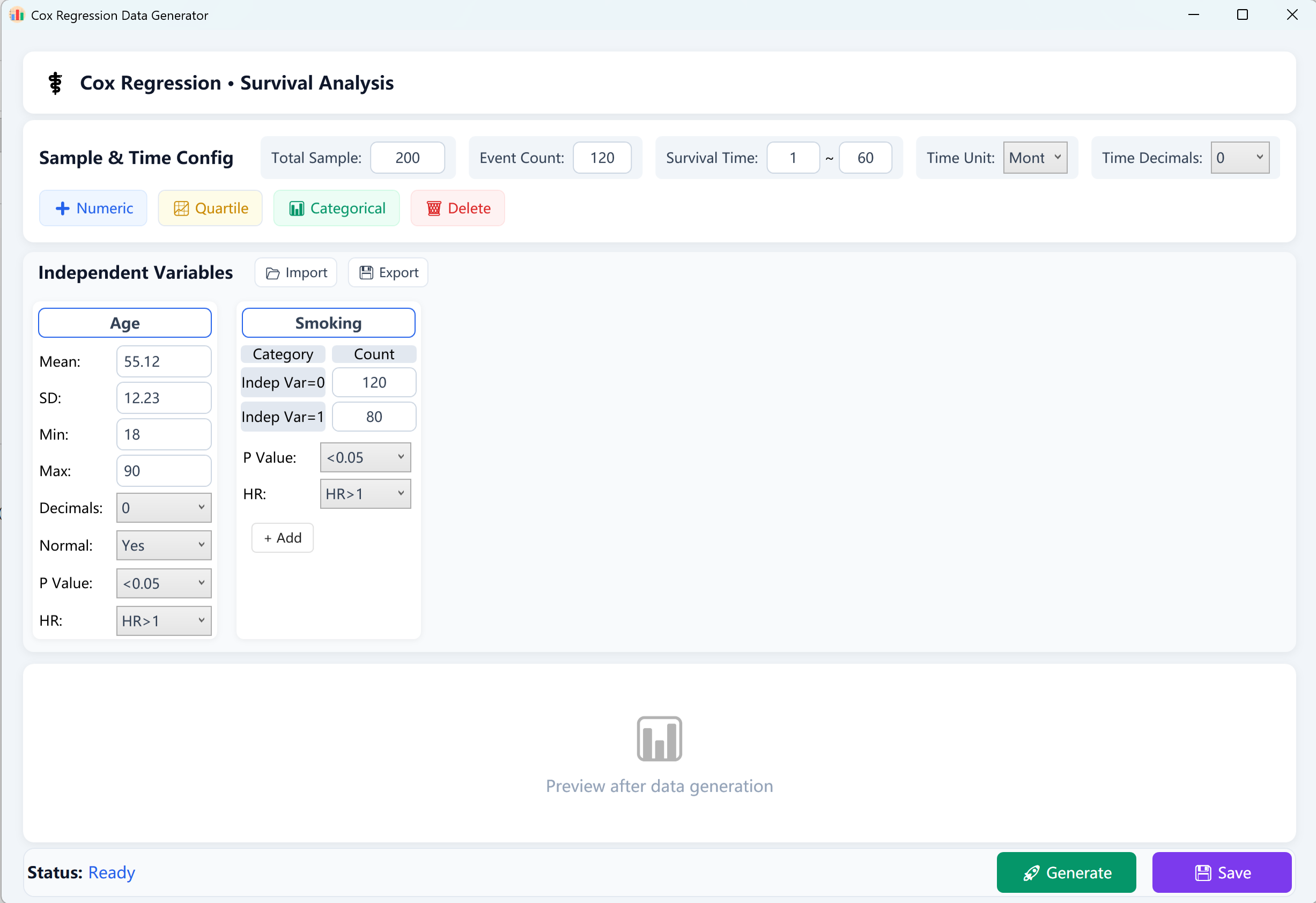
Figure 13.1 : Interface utilisateur / Opérations pour la Régression des risques proportionnels de Cox
- Taille totale de l'échantillon (N) : Le nombre global de sujets ou patients (ex. 200 sujets).
- Événements observés (Événements d'intérêt) : Le nombre de cas positifs ayant subi l'événement terminal (ex. décès, récidive ou échec) au cours de la période de suivi. Remarque : Le nombre d'événements doit être strictement inférieur à la taille totale de l'échantillon.
- Intervalle de temps de survie (T) : Définissez les limites [Min Follow-up] et [Max Follow-up] de la durée de suivi de survie (ex. 1~60 mois), étiquetez l'unité de temps (jours, mois ou années) et indiquez le nombre de décimales souhaité.
Règle statistique de l'EPV (Événements par variable) : Pour garantir la stabilité mathématique et la fiabilité d'un modèle à risques proportionnels de Cox, il est fortement recommandé d'avoir un ratio d'événements observés par rapport au nombre de variables indépendantes (EPV) d'au moins 10 à 20. Si votre modèle ne parvient pas à converger, essayez d'augmenter la taille totale de l'échantillon ou le nombre d'événements observés.
13.2 Construction des variables de recherche
Cliquez sur les boutons correspondants en bas de la carte des variables pour ajouter des covariables indépendantes :
- Variables numériques continues : Cliquez sur + Numeric pour ajouter des covariables continues (ex. Âge, IMC, biomarqueurs cliniques). Indiquez la Moyenne, l'Écart-type (obligatoire), et éventuellement les limites Min/Max pour restreindre les valeurs aberrantes ainsi que le nombre de décimales.
- Variables catégorielles : Cliquez sur + Categorical pour ajouter des covariables nominales ou ordinales (ex. Genre, score de satisfaction). Indiquez l'effectif cible exact pour chaque catégorie. Remarque : La somme des effectifs de toutes les catégories doit impérativement être égale à la taille totale de l'échantillon configurée pour pouvoir lancer la génération.
- Variables par quartiles : Cliquez sur + Quartile pour ajouter des variables structurées par quartiles, en renseignant les paramètres cibles de Q1, Q2 (Médiane) et Q3.
Paramètres cibles : Chaque carte de variable propose deux paramètres de ciblage puissants en bas de page :
- p-value de régression : Sélectionnez le seuil de significativité cible (ex. p > 0,05, p < 0,05, p < 0,01 ou p < 0,001).
- Direction du Hazard Ratio (HR) : Choisissez soit HR > 1 (facteur de risque, indiquant une augmentation du taux de risque) ou HR < 1 (facteur protecteur, indiquant une baisse du taux de risque).
13.3 Exécution de la génération et sauvegarde
Une fois tous les paramètres configurés, cliquez sur le bouton Generate en bas de la fenêtre. Le moteur d'exécution lancera des simulations itératives hautement concurrentes. Un rapport officiel et détaillé d'analyse de régression des risques proportionnels de Cox s'affichera alors, reproduisant fidèlement les calculs et la présentation d'IBM SPSS.
Cliquez sur le bouton Save pour exporter le jeu de données brutes généré dans un fichier Excel. Celui-ci pourra être importé directement dans SPSS ou tout autre outil d'analyse statistique professionnel pour vérification.
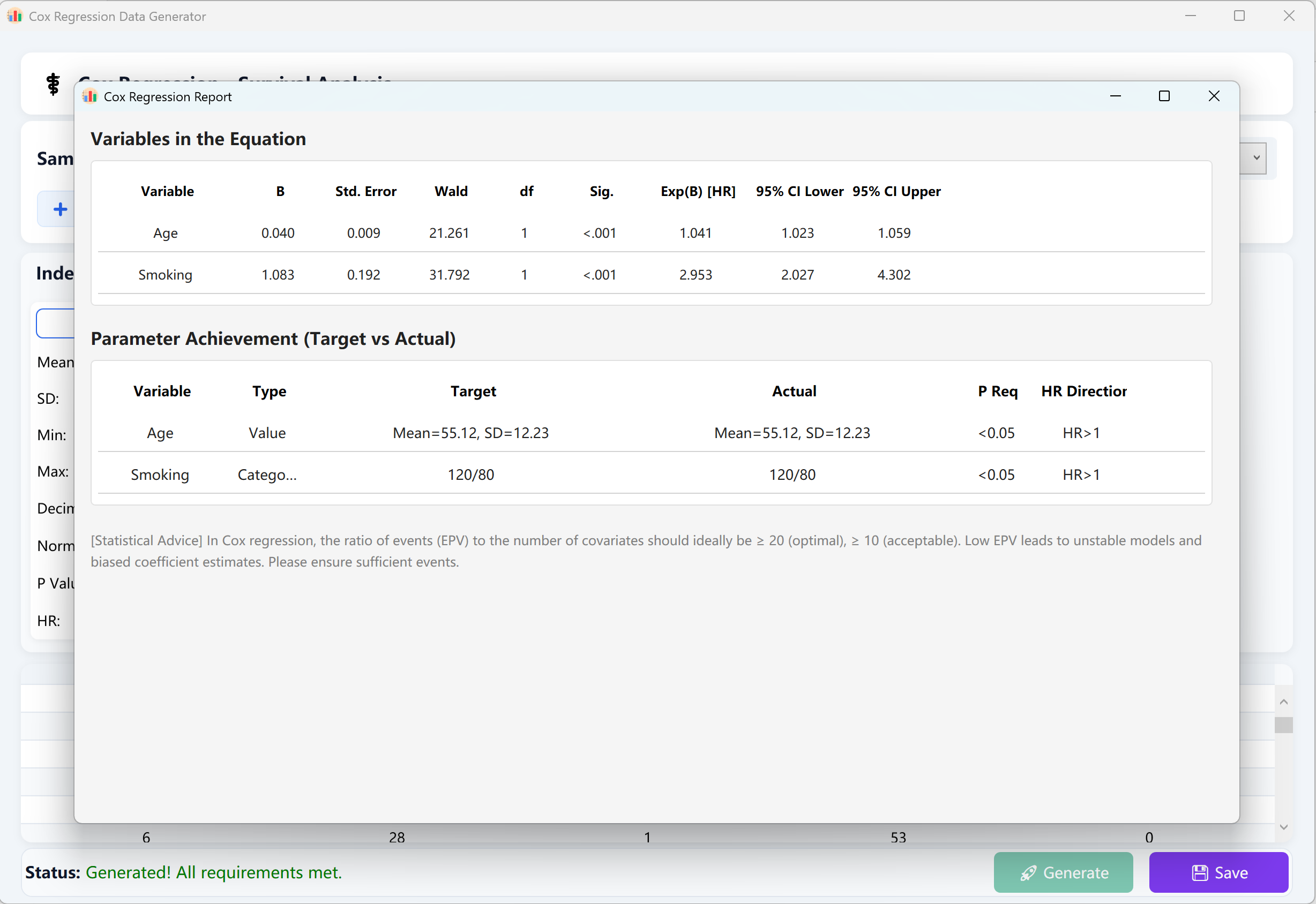
Figure 13.2 : Interface utilisateur / Affichage des données de la Régression des risques proportionnels de Cox
14. Génération de données pour l'analyse de corrélation
Simule des relations bivariées (Pearson ou Spearman) et des corrélations partielles en appliquant des coefficients de corrélation (valeurs de r) et des niveaux de significativité cibles.
14.1 Flux de travail
Accédez à Analyze → Correlation.
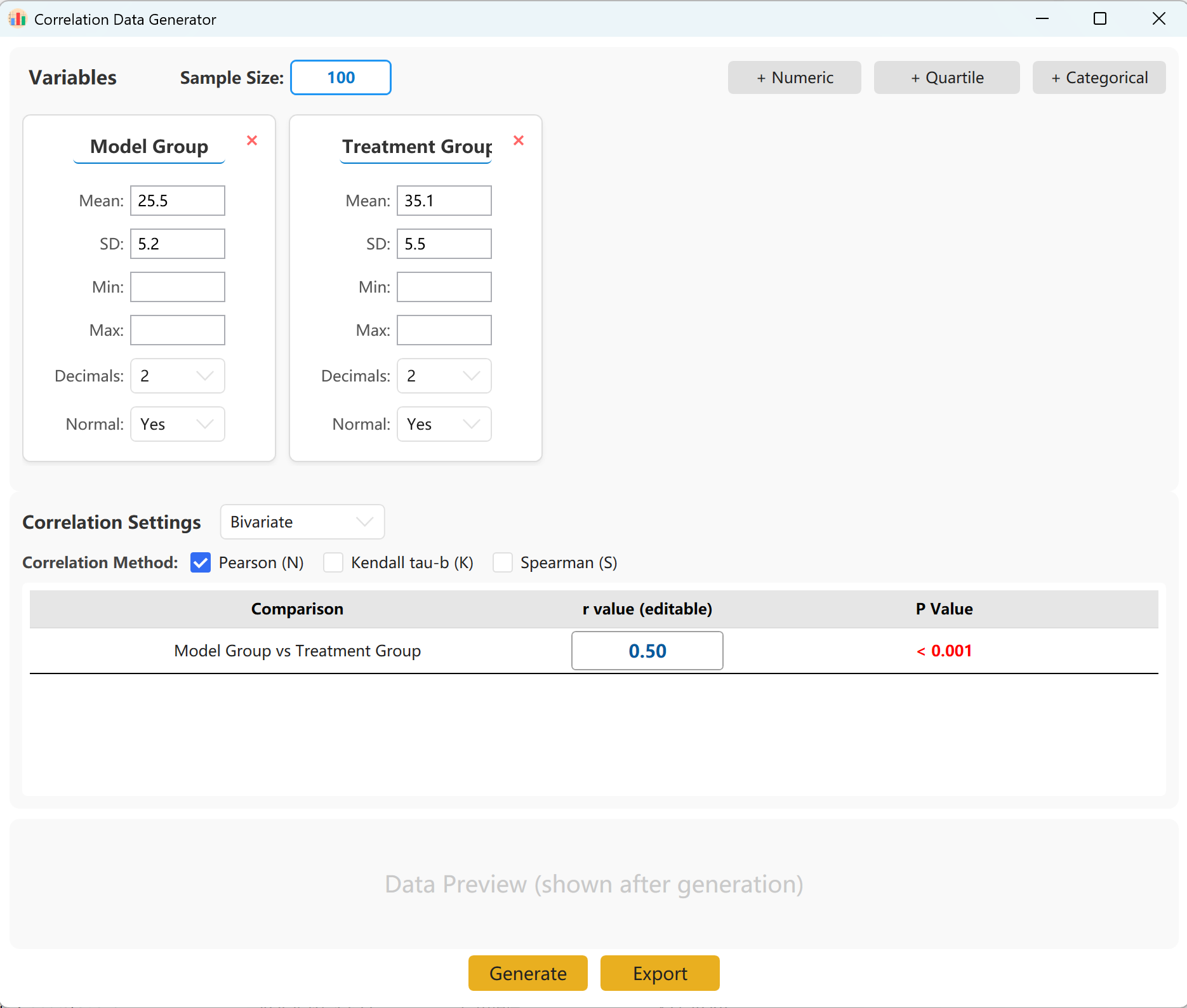
Figure 14.1 : Interface utilisateur / Opérations pour l'Analyse de corrélation
14.2 Paramètres
Le système pré-charge deux ensembles de variables pour une référence rapide. Vous pouvez aisément ajouter d'autres variables, sous forme numérique continue (moyenne/écart-type), par quartiles ou catégorielles. Dans le panneau de configuration, spécifiez la taille de l'échantillon, la moyenne et l'écart-type de chaque indicateur (les limites Min/Max sont facultatives).
Vous pouvez spécifier le coefficient de corrélation exact (r) ciblé entre les groupes. Cliquez sur le bouton Generate pour lancer la simulation et afficher la matrice de corrélation résultante dans une fenêtre contextuelle, prête à être exportée au format Excel.
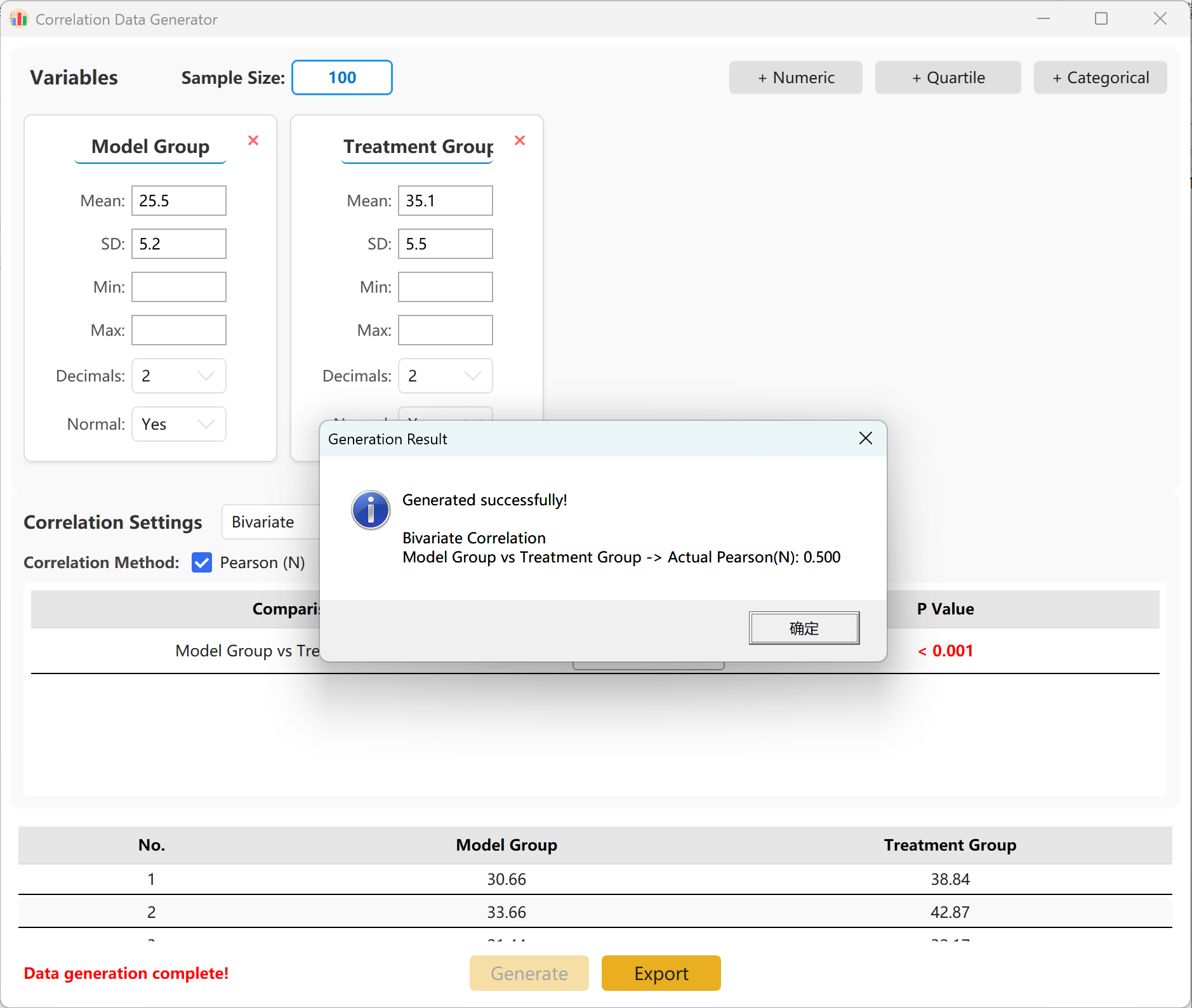
Figure 14.2 : Interface utilisateur / Affichage des données de l'Analyse de corrélation
15. Génération de données pour l'analyse de courbe ROC
Évalue la capacité diagnostique d'une variable de test continue ou catégorielle à distinguer deux états (ex. Diagnostic Positif vs Négatif).
15.1 Flux de travail
Accédez à Analyze → ROC Curve.
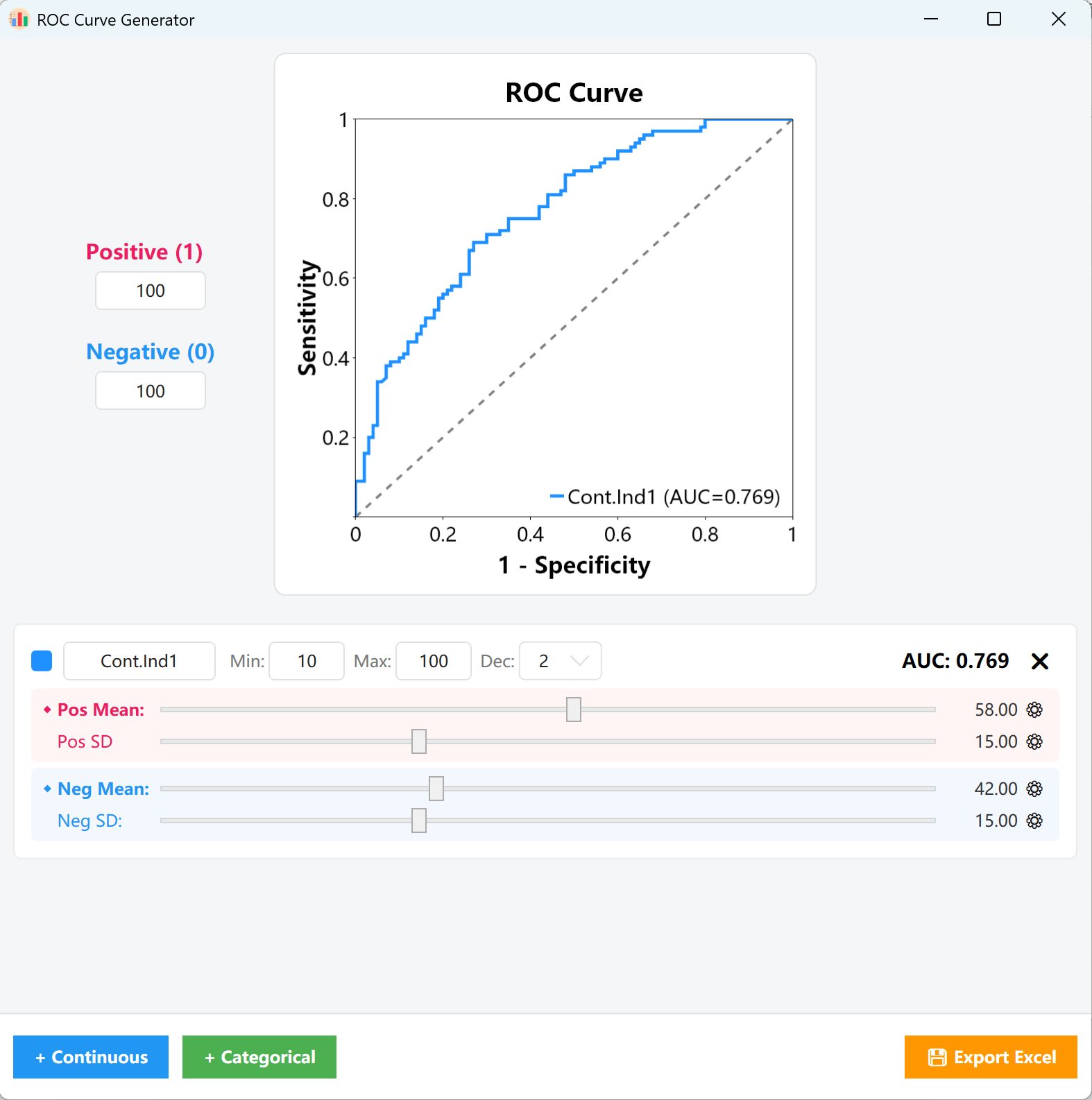
Figure 15.1 : Interface utilisateur / Opérations pour le paramétrage de la Courbe ROC
Proportions : Dans le panneau de configuration à gauche, renseignez les effectifs cibles pour les Échantillons Positifs (1) et les Échantillons Négatifs (0) (ex. 100 cas positifs et 100 cas négatifs). Le moteur de génération construira la matrice d'échantillonnage de base selon ces proportions.
15.2 Types de variables
Cliquez sur + Continuous ou + Categorical en bas à gauche pour créer les variables correspondantes :
- Variables continues : Personnalisez le nom de la variable, les limites Min/Max et le nombre de décimales sur la carte. Faites glisser le curseur Rose (groupe Positif) et le curseur Bleu (groupe Négatif) pour ajuster rapidement leurs distributions respectives de Moyenne et d'Écart-type.
- ⚙ Réglage de précision : Si les curseurs visuels ne permettent pas d'atteindre la granularité souhaitée, cliquez sur l'icône d'engrenage (⚙) à côté du paramètre pour saisir manuellement des valeurs précises à virgule flottante.
- Suivi de l'AUC : Tout au long de ces ajustements, l'indicateur AUC = 0.XXX en haut à droite de la carte ainsi que le graphique central se mettront à jour en temps réel, vous permettant d'aligner visuellement la courbe sur votre valeur seuil cible.
- Variables catégorielles : Définissez simplement les proportions ou effectifs exacts pour les cohortes positives et négatives. Vous pourrez instantanément observer les modifications correspondantes sur la courbe ROC et la valeur de l'AUC.
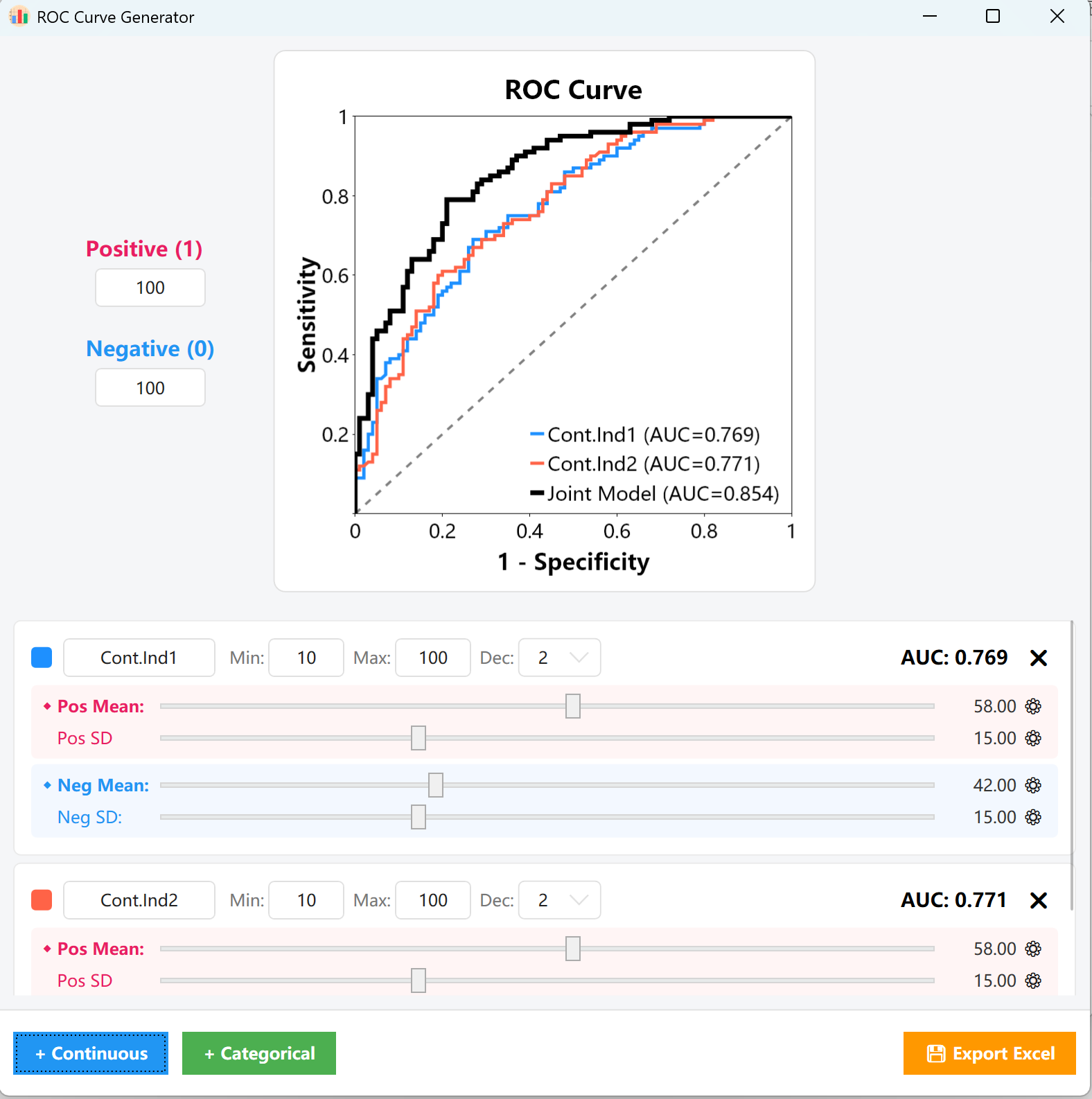
Figure 15.2 : Interface utilisateur / Affichage du tracé de la Courbe ROC
16. Sauvegarde et exportation des paramètres configurés
Pour rationaliser les tâches de modélisation répétitives et éviter les erreurs de configuration manuelles, l'application propose un mécanisme puissant de préservation de l'état de configuration.
16.1 Sauvegarder et restaurer
- Exporter la configuration : Allez dans le menu File → Export Configuration pour sauvegarder tous vos paramètres configurés, définitions de variables, structures de groupes et cibles dans un fichier de configuration local au format `.json` sur votre ordinateur.
- Importer la configuration : Pour restaurer votre environnement lors d'une session future, allez simplement dans le menu File → Import Configuration et sélectionnez votre fichier de configuration précédemment enregistré. L'espace de travail rechargera immédiatement toutes les fiches de variables, curseurs et valeurs de paramètres.