الوثائق ودليل المستخدم
مرحباً بك في الوثائق الرسمية لـ DataSynth Pro. يقدم هذا الدليل الشامل إرشادات تفصيلية حول إعداد معلمات الوحدات الإحصائية المختلفة لتركيب مجموعات بيانات قوية وصالحة أكاديمياً وإحصائياً بالكامل دون اتصال.
1. توليد مؤشرات متعددة في الوقت نفسه
1.1 المتطلبات المسبقة والتشغيل
انقر نقراً مزدوجاً على الملف التنفيذي لتشغيل التطبيق. يتطلب البرنامج إطار تشغيل Microsoft .NET 8.0. إذا لم يكن مثبتاً على جهازك، فاتبع التعليمات لتنزيله وتثبيته، ثم أعد فتح البرنامج.
ملاحظة أمنية: إذا اعتبر برنامج مكافحة الفيروسات الملف التنفيذي تهديداً بالخطأ، فأضفه إلى قائمة الاستثناءات أو القائمة البيضاء المحلية لضمان عمله دون انقطاع.
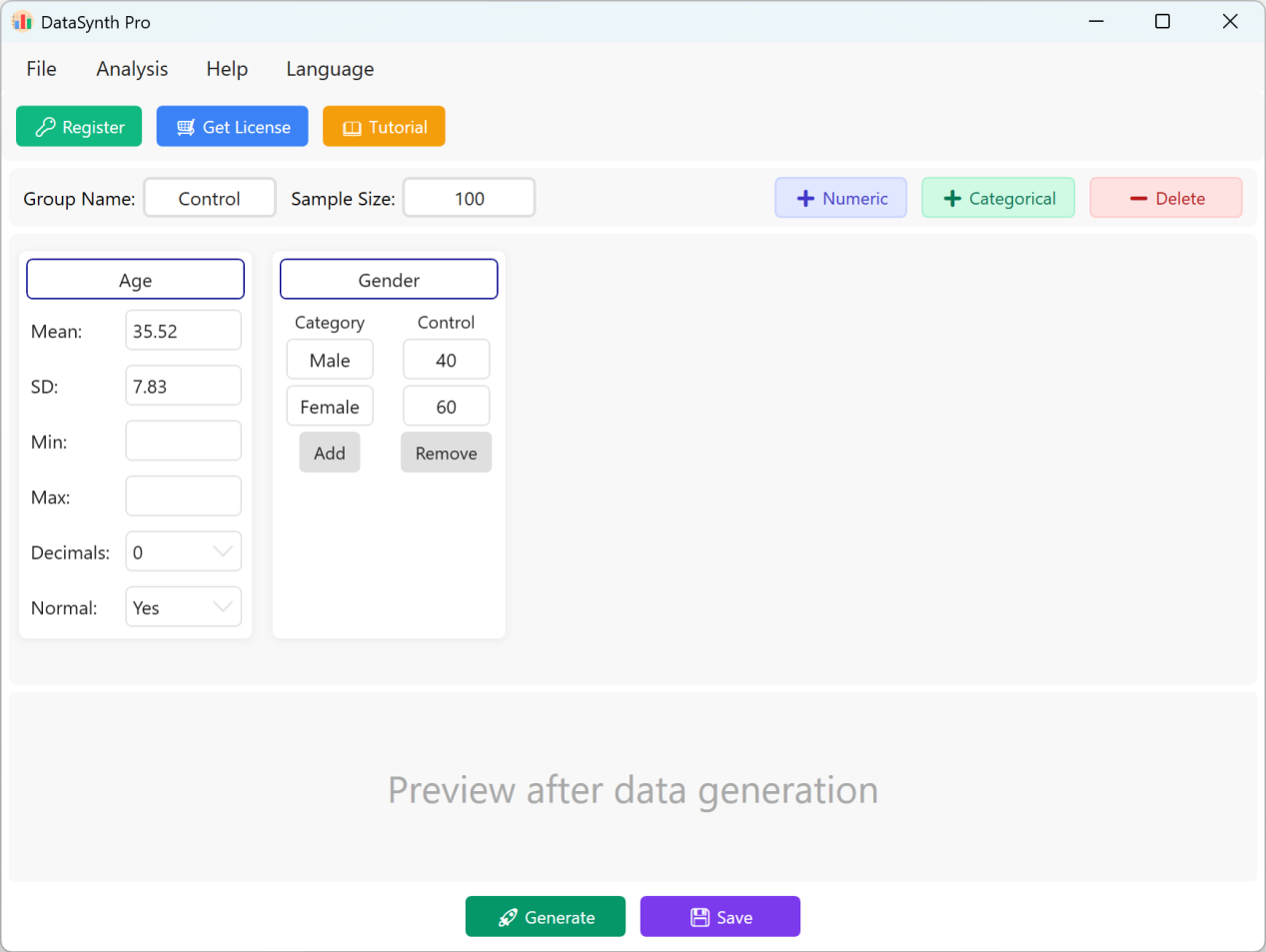
الشكل 1.1: واجهة المستخدم / العمليات (الواجهة الرئيسية)
1.2 إعداد المعلمات
بشكل افتراضي، يملأ التطبيق متغيرين مستمرين هما 'Age' و'Gender' كمرجع سريع. يكون تعيين المجموعة افتراضياً 'Control Group'، ويُضبط حجم العينة على 100 حالة. إذا كانت دراستك تتطلب مجموعات متعددة، يمكنك توليد وتصدير بيانات كل مجموعة تباعاً عبر تحديث المعلمات لكل تشغيل.
- إضافة متغيرات رقمية مستمرة: لإضافة متغير كمي جديد، انقر زر + رقمي ثم يمكنك تحديد اسم المؤشر (مثل 'Body Mass Index' أو 'BMI') والمتوسط والانحراف المعياري وعدد المنازل العشرية. حقلا الحد الأدنى والحد الأقصى اختياريان ويمكن تركهما فارغين إذا لم تكن لديك حدود قيمة محددة.
- إعدادات توزيع البيانات: افتراضياً، تتبع المقاييس الرقمية المولدة توزيعاً طبيعياً. إذا كنت تحتاج إلى بيانات غير موزعة طبيعياً، فما عليك إلا ضبط خيار التوزيع الطبيعي إلى لا.
ضبط التوزيع: يعتمد التوزيع الطبيعي على مدى طبيعي للتباين؛ لذلك فإن تقييد الحدود الدنيا والعليا بشدة قد يقطع المنحنى الطبيعي وينتج قيماً غير موزعة طبيعياً. إذا حدث ذلك، فجرب توسيع الحدود أو إزالة حدود الحد الأدنى/الأقصى بالكامل.
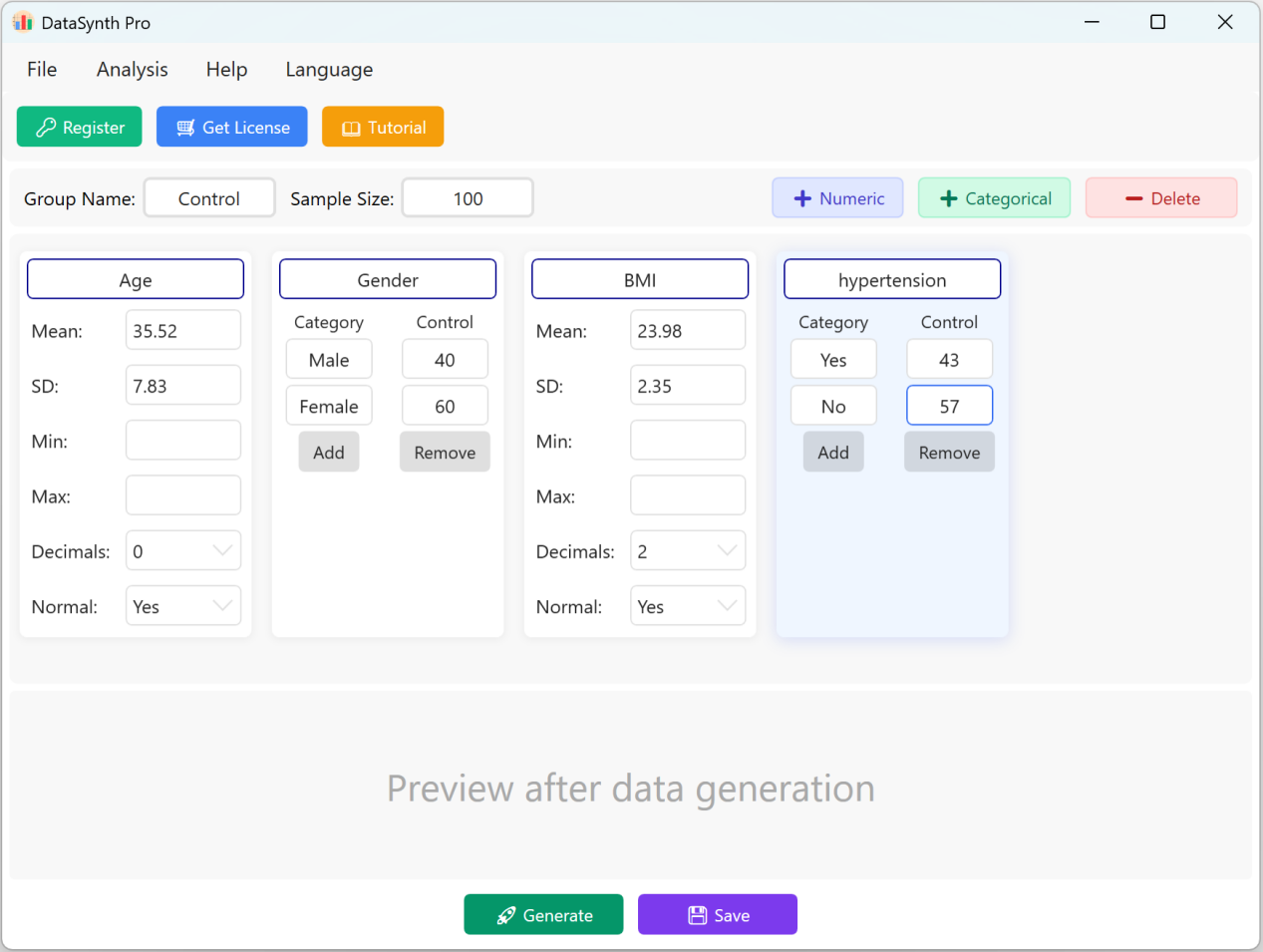
الشكل 1.2: واجهة المستخدم / العمليات لإضافة المتغيرات
1.3 إضافة متغيرات فئوية
انقر زر + فئوي لمتابعة إضافة متغيرات نوعية (مثل 'Hypertension'). يمكنك إدخال أسماء الفئات والتوزيعات أو النسب المستهدفة المقابلة لها. سيُعاد تحجيم مجموع نسب الفئات ديناميكياً ليتوافق مع حجم العينة الذي ضبطته.
1.4 تنفيذ التوليد
انقر زر توليد لتركيب عدد السجلات المطلوب. بعد الحساب، ستظهر نافذة ملخص للإحصاءات الوصفية لتتمكن من التحقق مما إذا كانت القيم المولدة فعلياً تتوافق مع المعلمات التي ضبطتها.
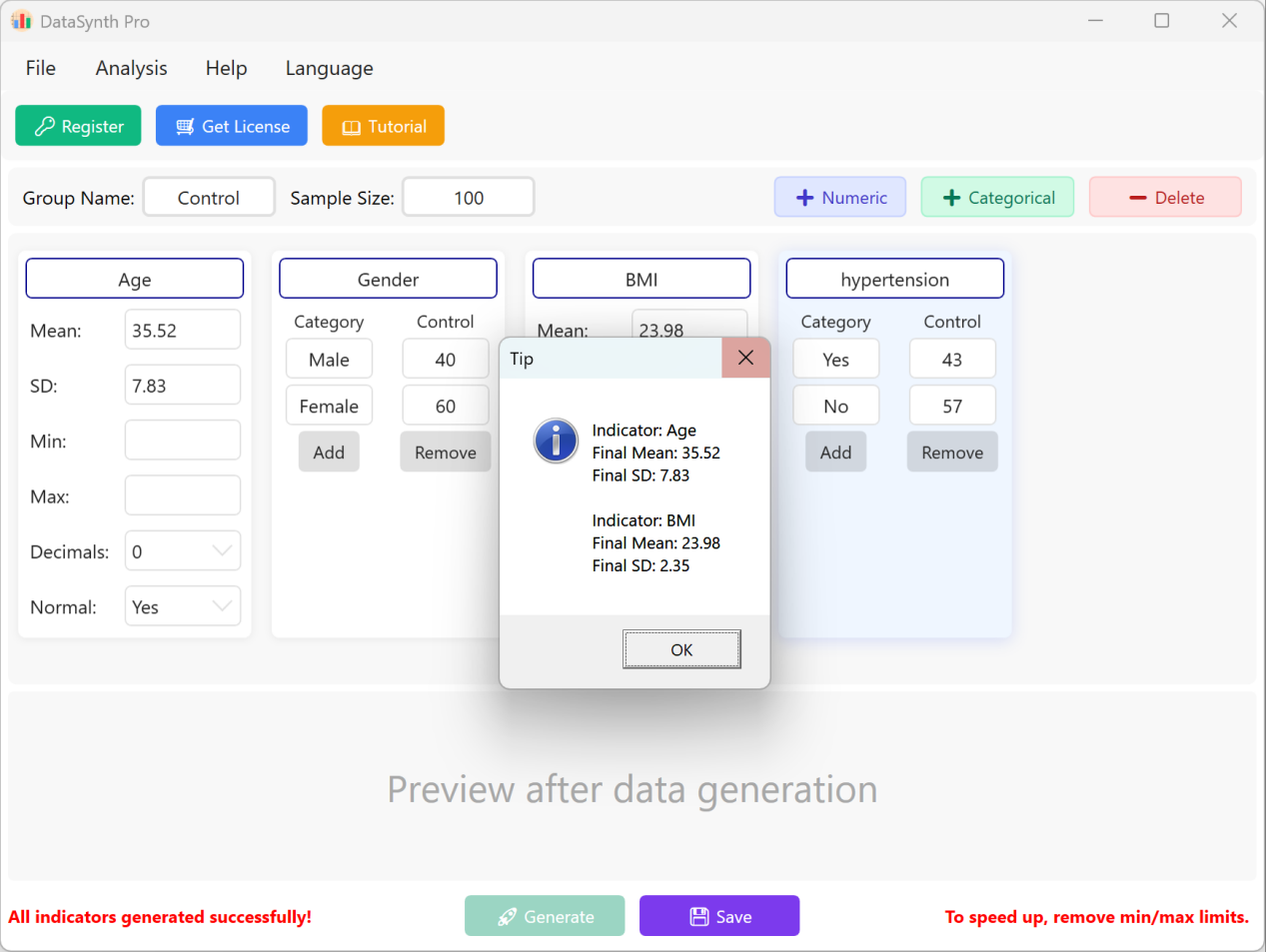
الشكل 1.3: واجهة المستخدم / العمليات لتنفيذ التوليد
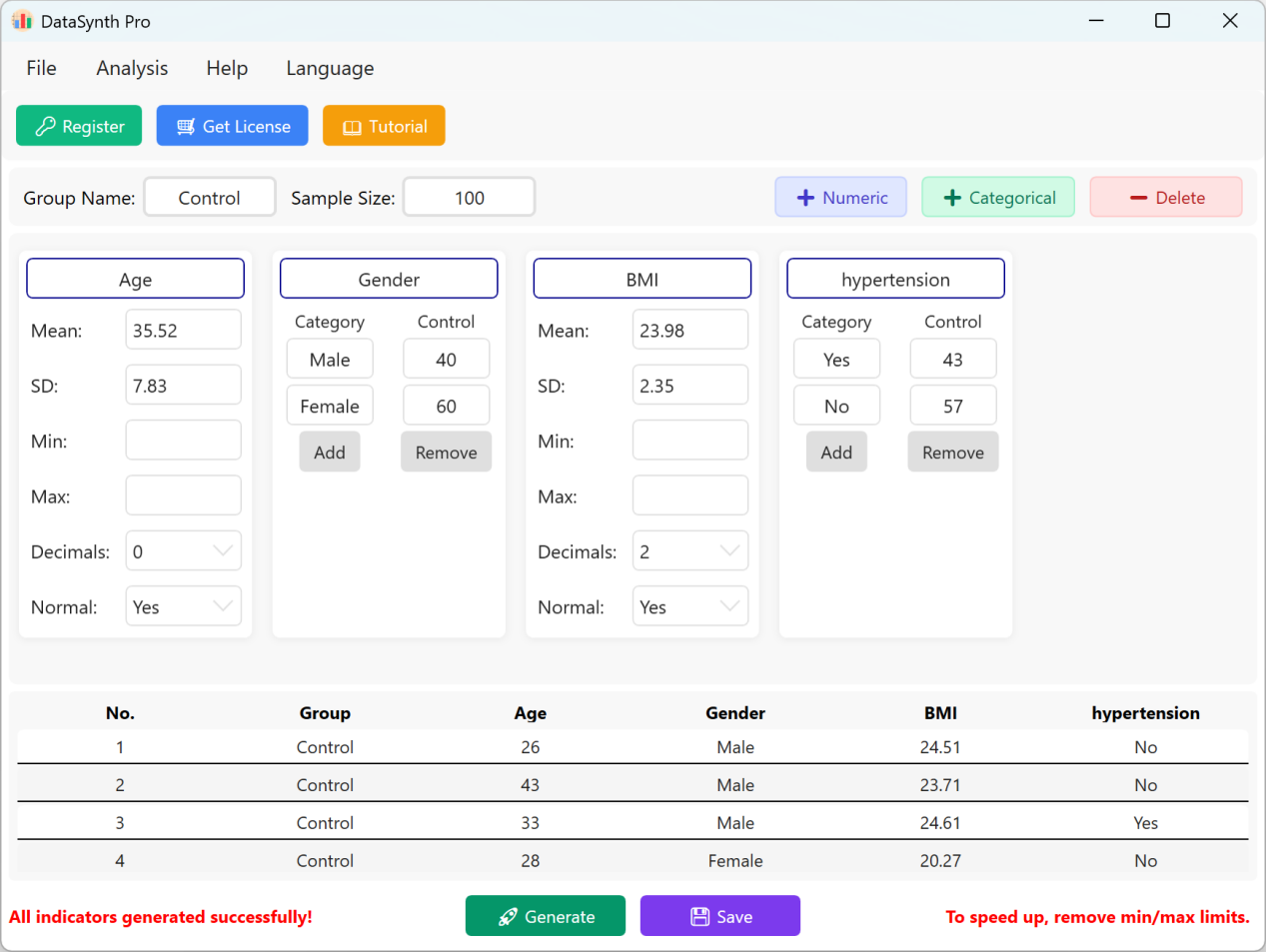
الشكل 1.4: واجهة المستخدم / العمليات لعرض البيانات
1.5 التصدير والتحقق
انقر زر حفظ لتصدير مجموعة البيانات المولدة كملف Excel قياسي. إذا فتحت جدول البيانات المصدر وحسبت الإحصاءات الوصفية لـ 'Age' (مقربة إلى منزلتين عشريتين) باستخدام صيغ Excel القياسية، فسيتطابق المتوسط والانحراف المعياري الفعليان تماماً مع إعداداتك الأولية.
الشكل 1.5: تصدير الجداول المولدة إلى Excel
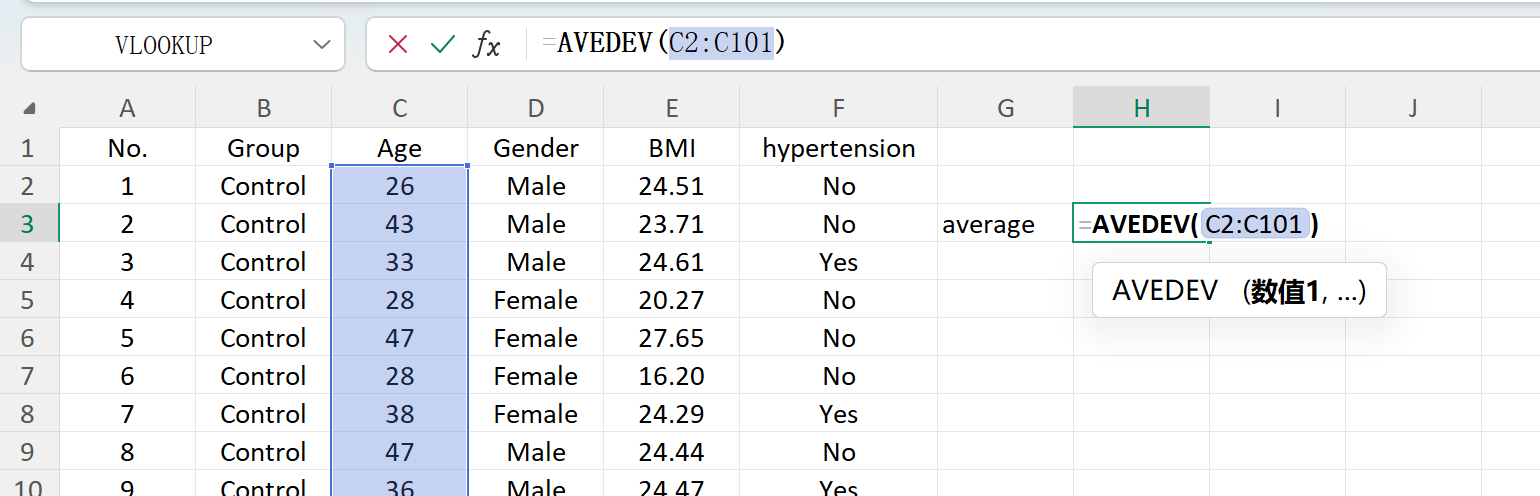
الشكل 1.6: عمليات Excel لحساب المتوسط
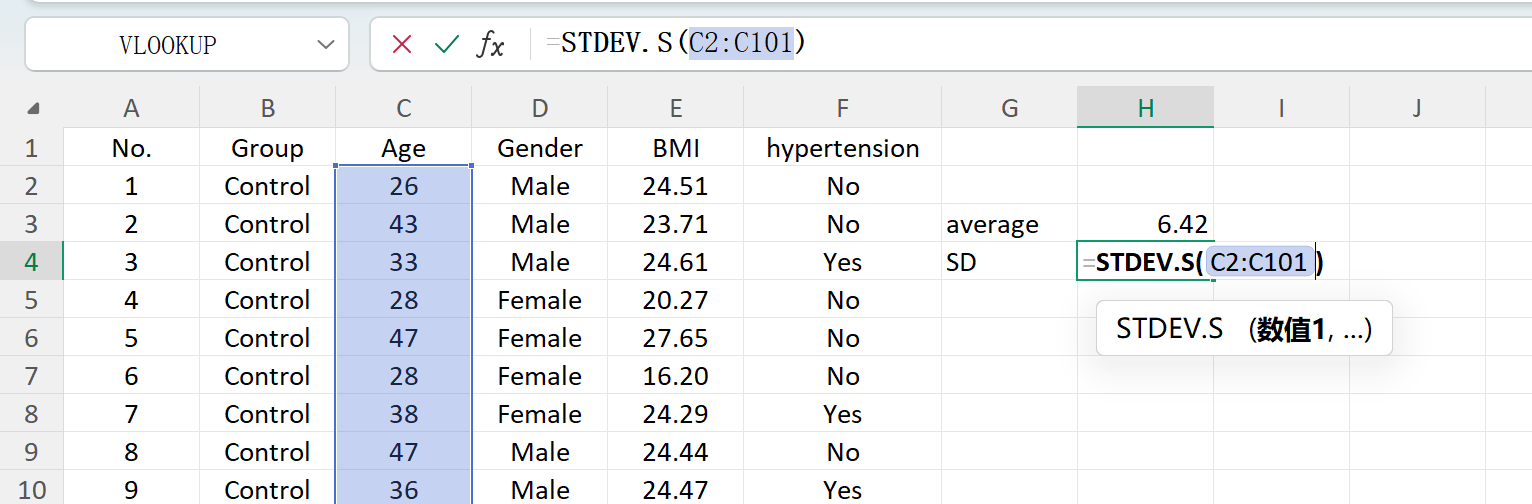
الشكل 1.7: عمليات Excel لحساب الانحراف المعياري
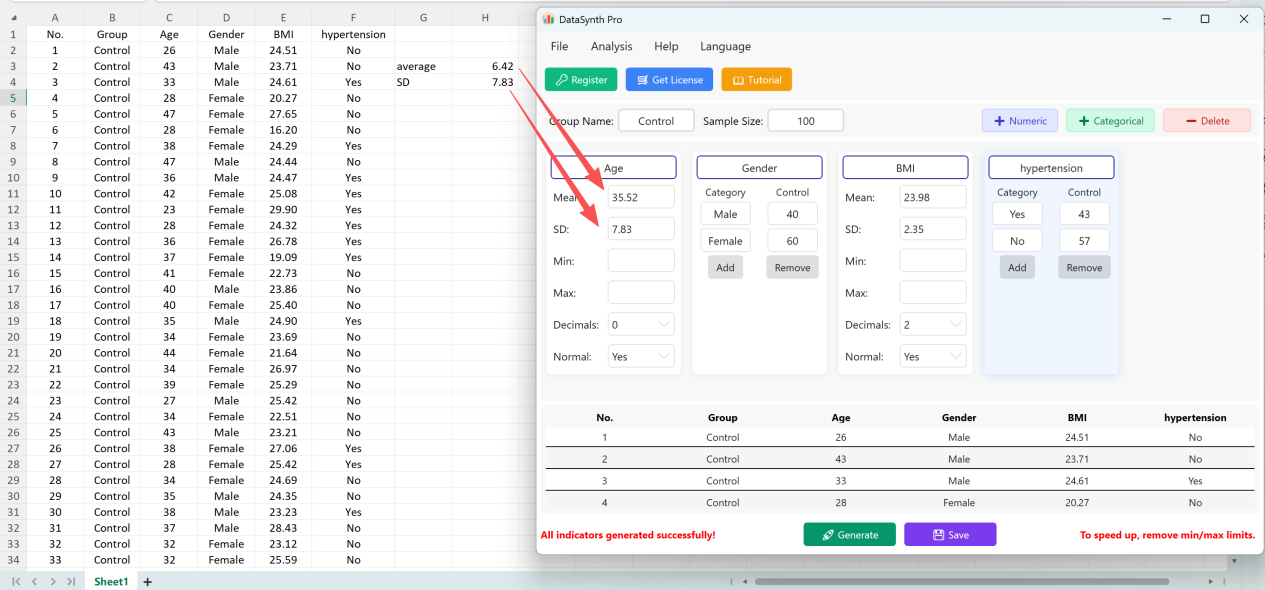
الشكل 1.8: نتائج التحقق مطابقة للإعدادات الأولية
1.6 الكفاءة الحسابية
بفضل محرك تحسين عالي الأداء، يستطيع البرنامج توليد مجموعات بيانات تحتوي على آلاف أو عشرات الآلاف من السجلات خلال ثوانٍ. إذا فشل النظام في التقارب بعد الحد الأقصى من التكرارات، فتحقق من المعقولية الإحصائية لإعداداتك أو جرّب التشغيل دون حدود الحد الأدنى/الأقصى. يدعم البرنامج دقة عشرية تصل إلى 8 منازل لتلبية احتياجات البحث العلمي المتخصص.
نصائح وتوصيات:
• تفضيل التوزيع الطبيعي: تكون البيانات افتراضياً موزعة طبيعياً لتسهيل التحليل اللاحق (مثل اختبارات T للعينات المستقلة). إذا كنت تفضل بيانات لامعلمية أو مخصصة التوزيع، فغيّر إعداد التوزيع الطبيعي إلى لا.
2. اختبار t للعينات المستقلة
مصمم للدراسات المقطعية التي تقارن متوسطات مجموعتين مختلفتين. يُستخدم على نطاق واسع في التجارب السريرية (مثل فعالية الدواء بين مجموعة العلاج ومجموعة الدواء الوهمي) والاستبيانات الاجتماعية.
2.1 سير العمل
انتقل إلى Analyze → Independent T-Test. ستظهر نافذة الإعداد كما هو موضح أدناه:
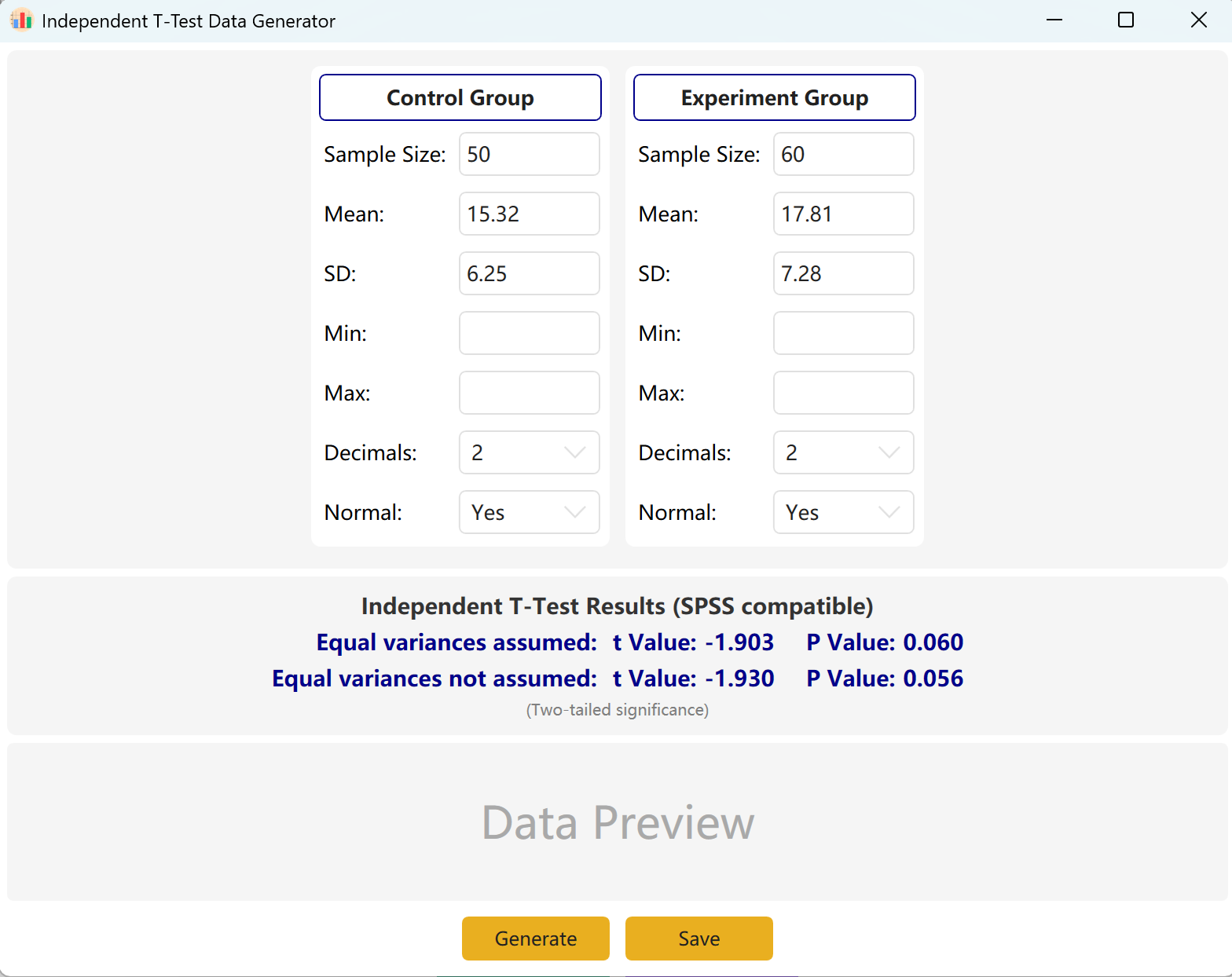
الشكل 2.1: واجهة المستخدم / العمليات لاختبار T المستقل
2.2 المعلمات
يملأ البرنامج مسبقاً إعدادات عينات لمجموعتي 'Control Group' و'Experimental Group' كمرجع. أدخل حجم العينة والمتوسط والانحراف المعياري لكل مجموعة لمعاينة قيمة t وقيمة p المحسوبتين فورياً. معلمات الحد الأدنى والحد الأقصى اختيارية.
سيؤدي النقر على زر التوليد إلى إنشاء مجموعات بيانات خام لكلتا المجموعتين في جدول المعاينة أدناه، وستُعدّل قيمة t وقيمة p النهائيتان لتعكسا البيانات المولدة فعلياً باستخدام اختبار Levene لتساوي التباينات.
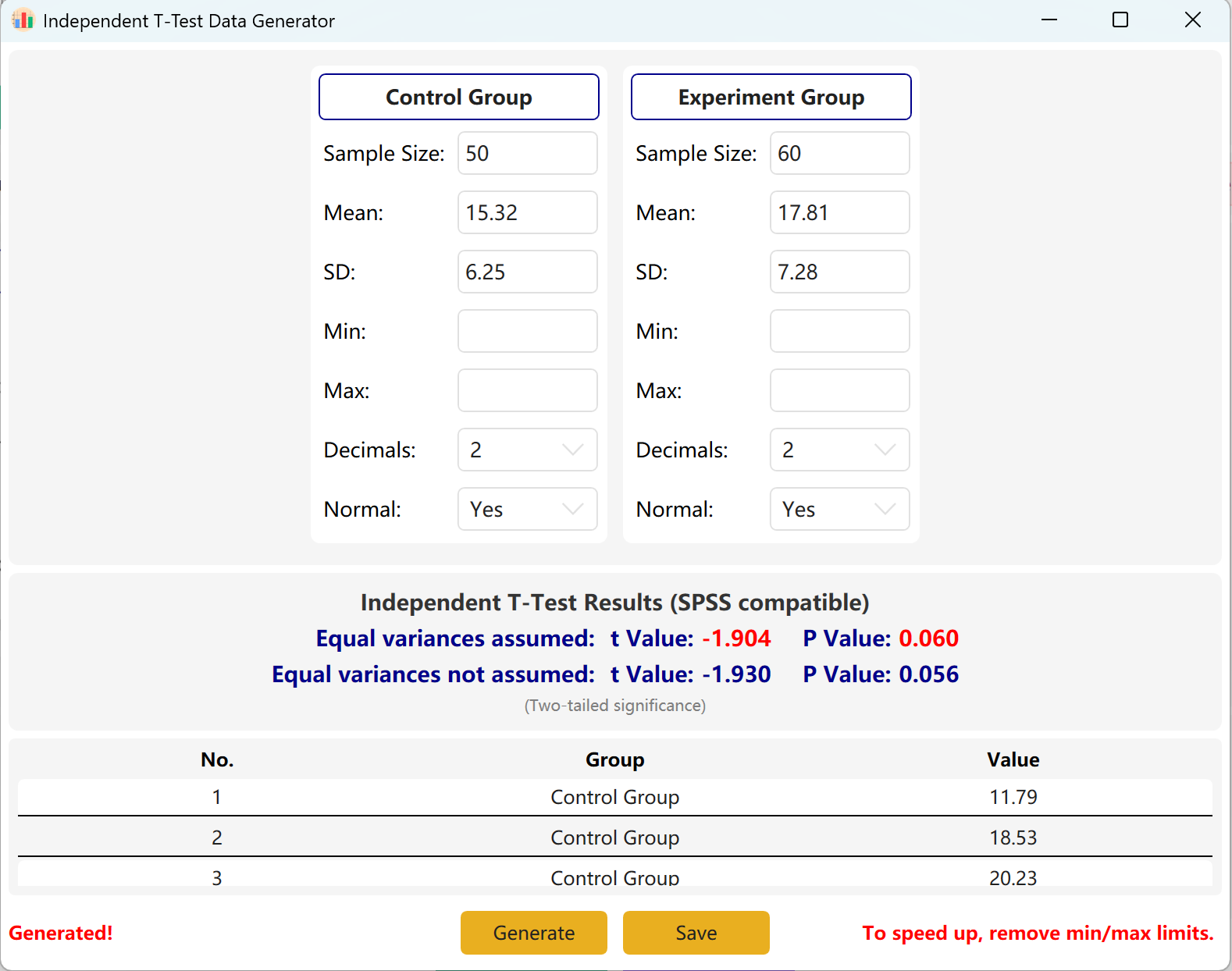
الشكل 2.2: واجهة المستخدم / العمليات لعرض بيانات اختبار T للعينات المستقلة
3. اختبار t للعينات المزدوجة
يُستخدم في الدراسات الطولية أو المتقاطعة التي تُقاس فيها نفس الحالات مرتين (مثل الاختبار القبلي مقابل الاختبار البعدي). يركز على تركيب فرق المتوسط بين الملاحظات المزدوجة.
3.1 سير العمل
انتقل إلى Analyze → Paired T-Test. يظهر تخطيط مساحة العمل أدناه:
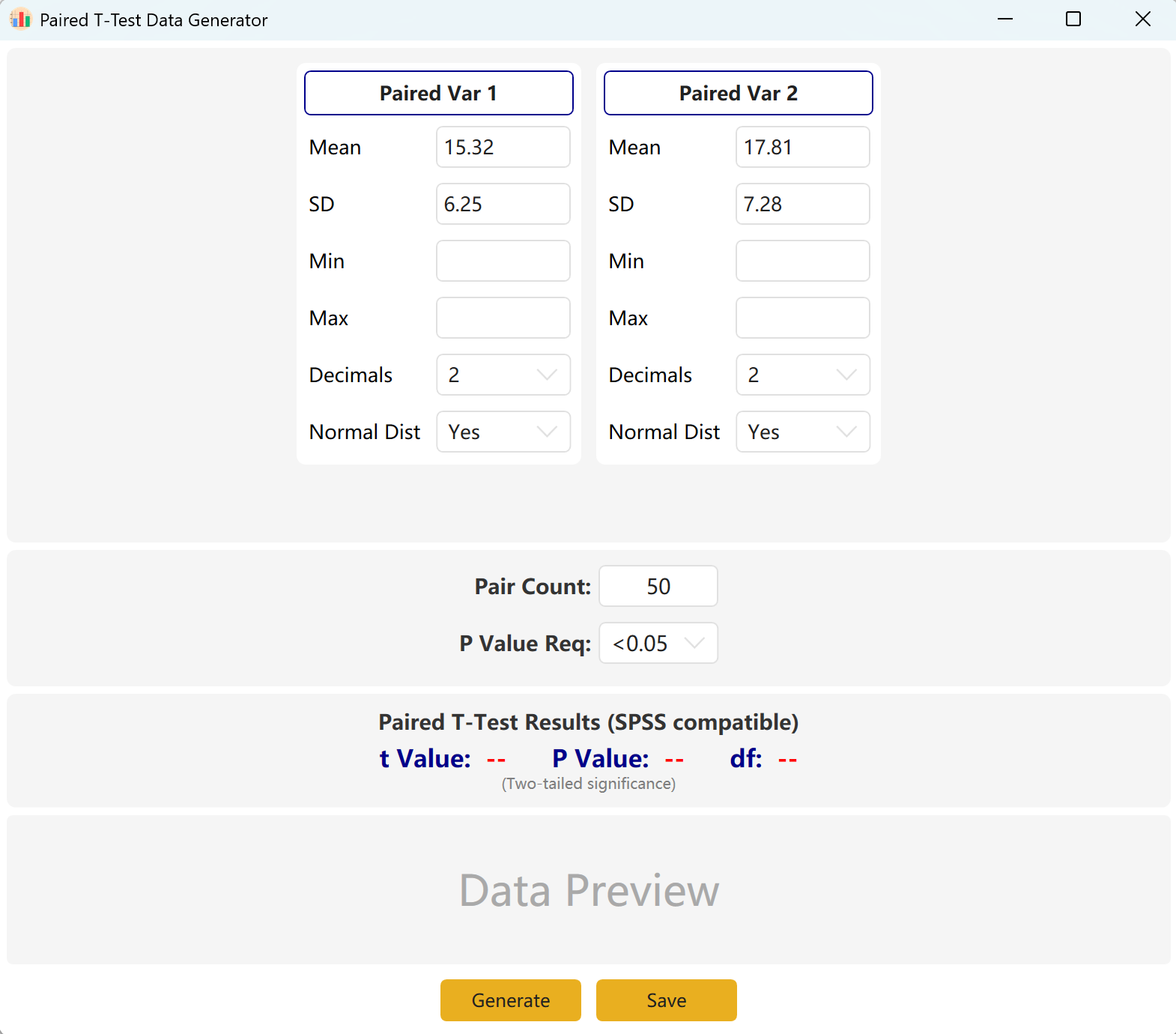
الشكل 3.1: واجهة المستخدم / العمليات لاختبار T المزدوج
3.2 منطق المحاكاة
يعتمد البرنامج افتراضياً متغيرين مزدوجين هما Paired Var1 وPaired Var2. يمكنك تحديد المتوسط والانحراف المعياري لكل متغير، وضبط حجم العينة الكلي، وتحديد نطاق قيمة p المستهدفة لاختبار t المزدوج. سيحسب المحرك مجموعة بيانات متوافقة بشكل تكراري.
التكيف مع التقارب: إذا كانت المتوسطات المضبوطة غير متسقة رياضياً مع قيمة p المستهدفة (مثلاً إذا كان المتوسطان مختلفين جداً وطلبت p غير دالة > 0.05)، فسيثبت البرنامج معلمات المجموعة الأولى ويعدل متوسط المجموعة الثانية ديناميكياً لتحقيق قيمة p المستهدفة.
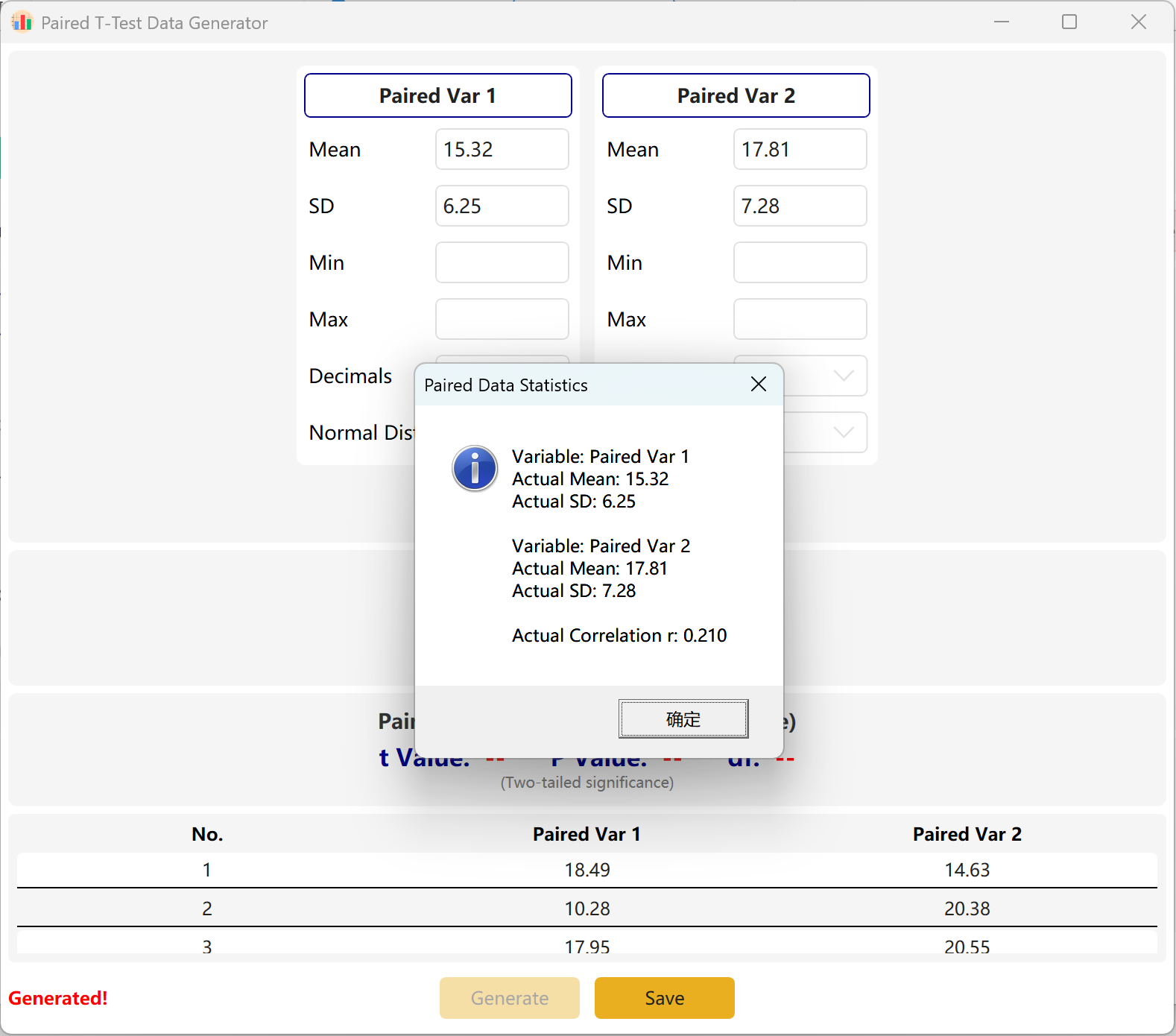
الشكل 3.2: واجهة المستخدم / العمليات لعرض بيانات اختبار T للعينات المزدوجة
4. اختبار كاي تربيع
يحدد ما إذا كانت هناك علاقة معنوية بين متغيرين فئويين. يُستخدم كثيراً في الجداول المتقاطعة الديموغرافية.
4.1 سير العمل
انتقل إلى Analyze → Chi-Square Test. تفتح لوحة الإعداد كما يلي:
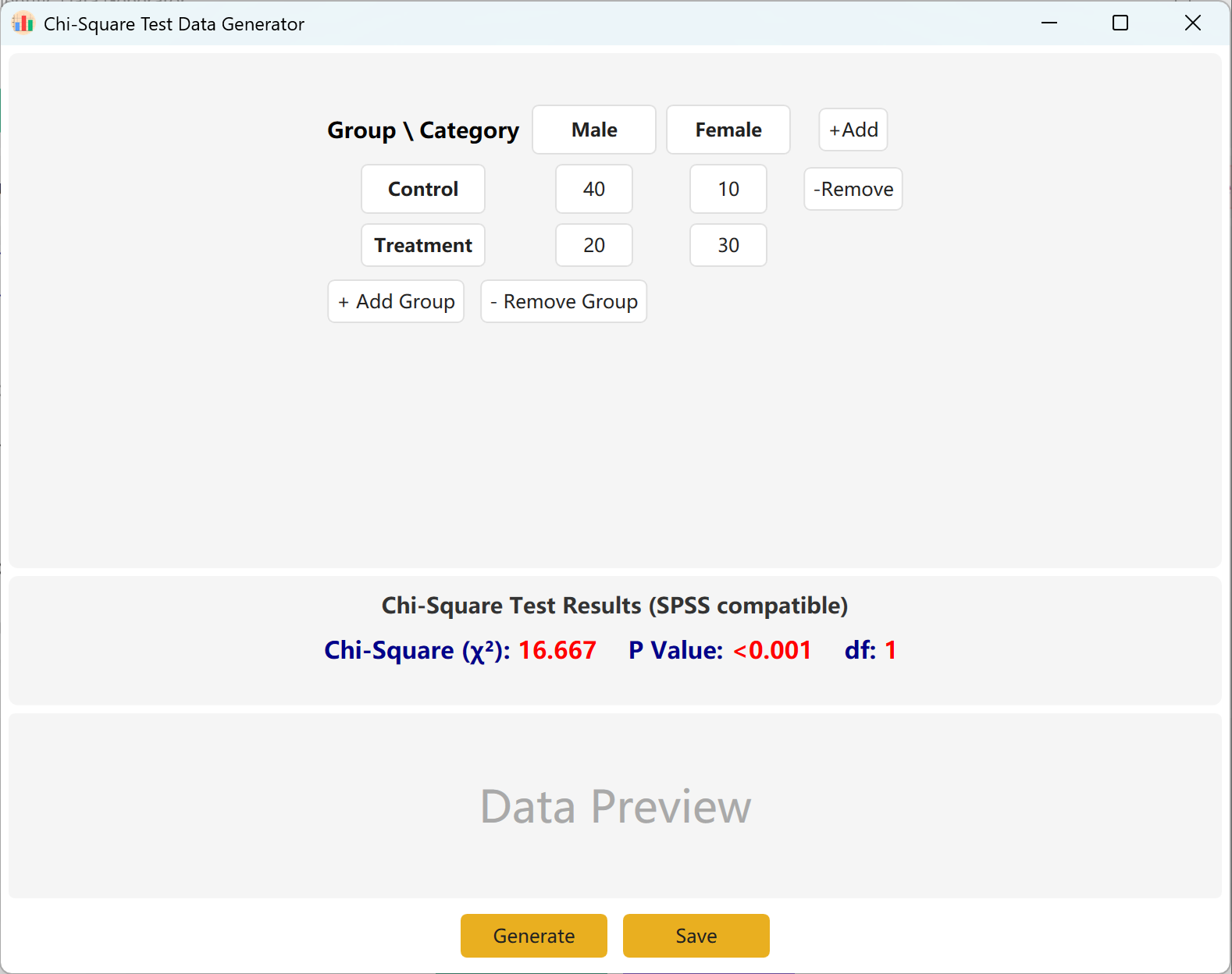
الشكل 4.1: واجهة المستخدم / العمليات لاختبار كاي تربيع
4.2 مصفوفة التوافق
تعتمد الواجهة افتراضياً جدول توافق قياسي 2×2 لحسابات كاي تربيع، ويمكن تحرير أسماء المجموعات والفئات بالكامل. أدخل التكرارات المرصودة (الأعداد) لكل خلية، وستتحدث قيمة كاي تربيع وقيمة p المحسوبتان فورياً.
يمكنك إضافة مجموعات (صفوف) أو فئات (أعمدة) ديناميكياً لاستيعاب نماذج أكبر. انقر توليد لإنتاج سجلات خام فردية تطابق هذه التكرارات، ثم انقر حفظ لتصدير مجموعة البيانات إلى Excel.
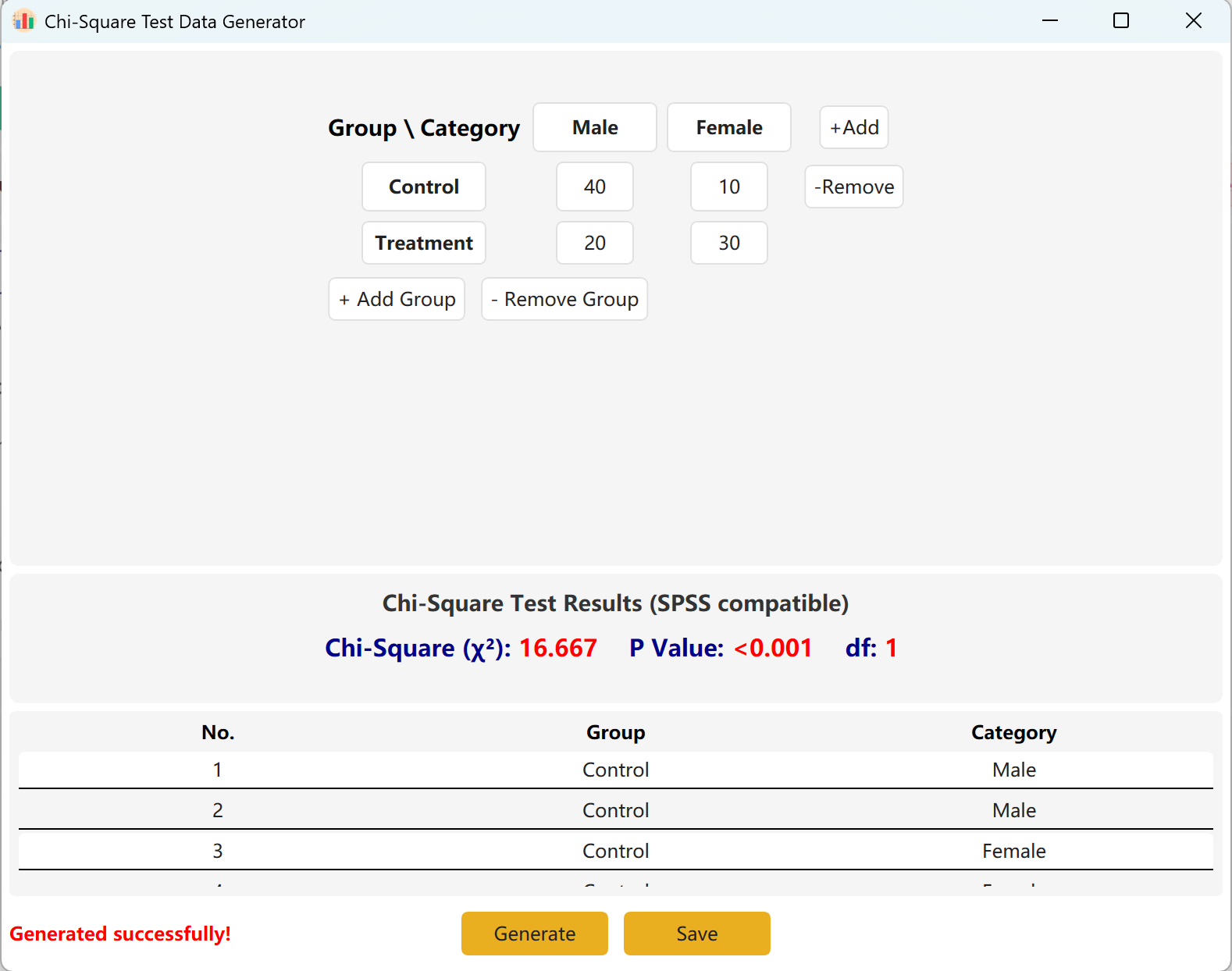
الشكل 4.2: واجهة المستخدم / العمليات لعرض بيانات اختبار كاي تربيع
5. تحليل التباين الأحادي
يُستخدم عند مقارنة متوسطات ثلاث مجموعات مستقلة أو أكثر. يركب الخوارزم تباين داخل المجموعات وفروقاً بين المجموعات لتلبية قيم F المستهدفة.
5.1 سير العمل
انتقل إلى Analyze → ANOVA → One-Way ANOVA. تخطيط مساحة العمل كما يلي:
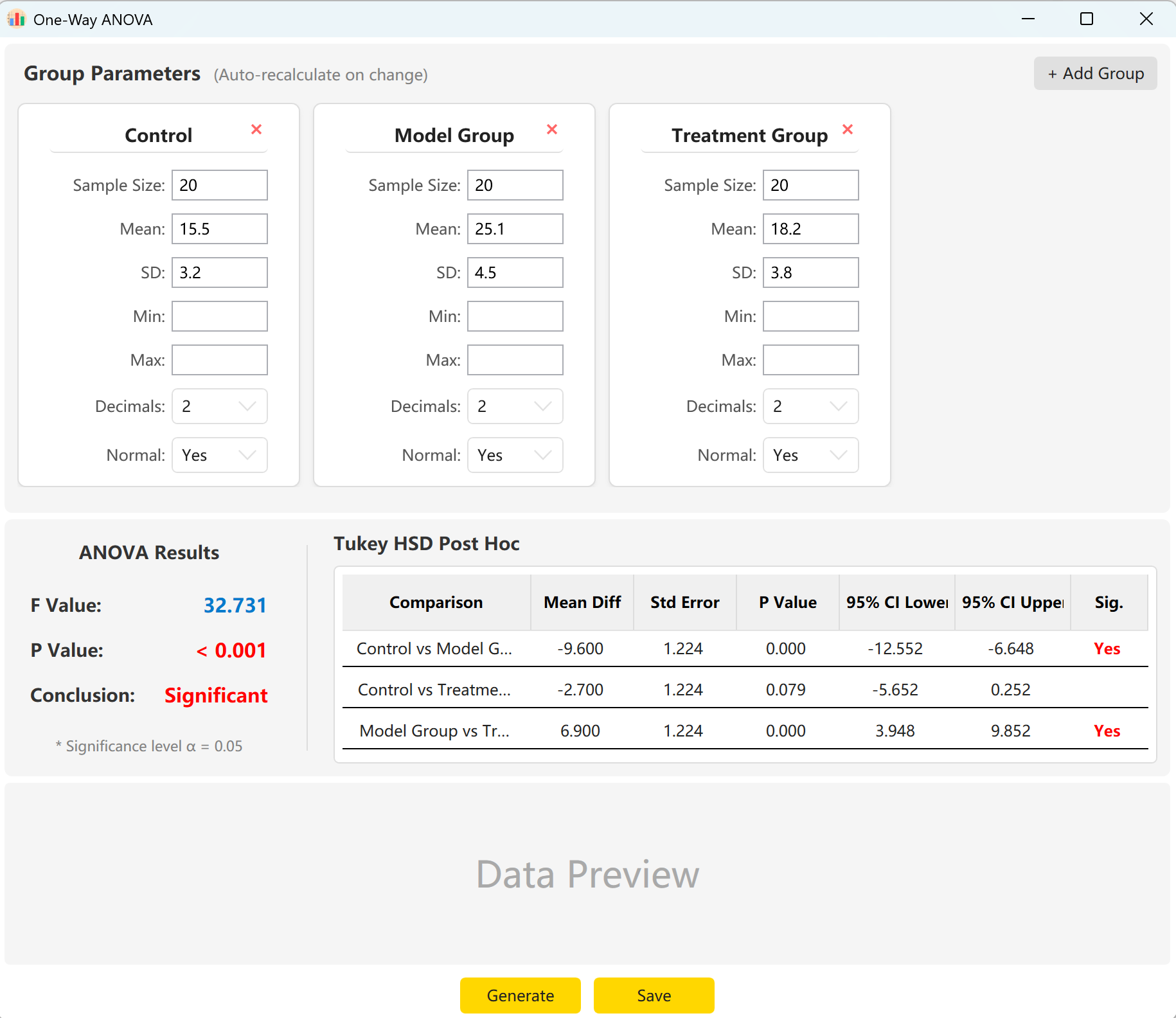
الشكل 5.1: واجهة المستخدم / العمليات لتحليل التباين الأحادي
5.2 الإعداد
يحمّل النظام مسبقاً معلمات ثلاث مجموعات: 'Control Group' و'Experimental Group' و'Treatment Group'. أدخل حجم العينة والمتوسط والانحراف المعياري لكل مجموعة لمعاينة إحصاء F العام وقيمة p ونتائج المقارنات البعدية المتعددة Tukey HSD فورياً.
انقر توليد لحساب ومعاينة السجلات الخام الفردية أدناه. ستتحدث قيمة F العامة وقيمة p تلقائياً لتمثيل القيم المولدة فعلياً.
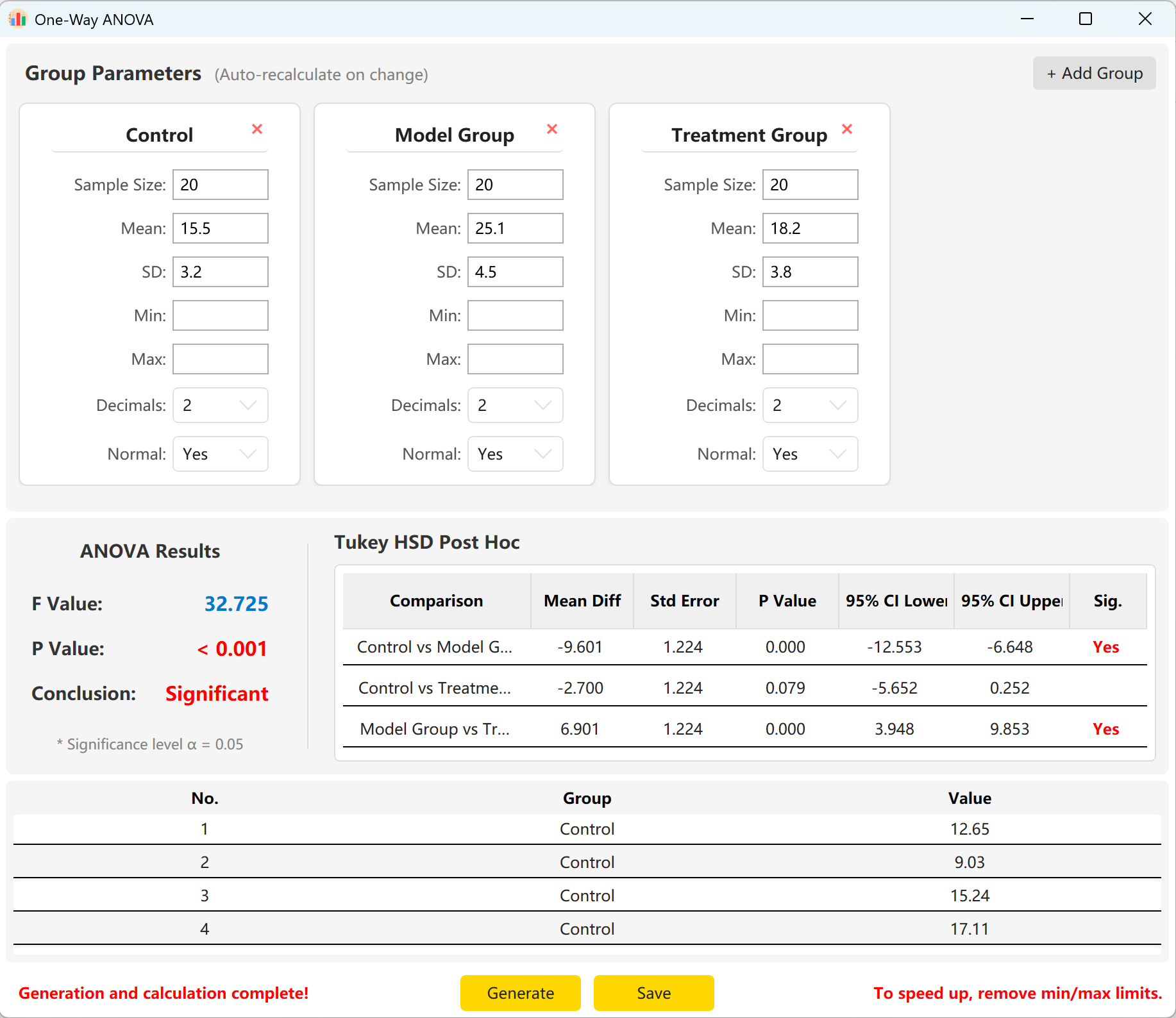
الشكل 5.2: واجهة المستخدم / العمليات لعرض بيانات تحليل التباين الأحادي
6. تحليل التباين الثنائي
يفحص تأثير متغيرين فئويين مستقلين على متغير تابع مستمر واحد. وهو أساسي للتصاميم العاملية لتقييم التأثيرات الرئيسية وتأثيرات التفاعل.
6.1 سير العمل
انتقل إلى Analyze → ANOVA → Two-Way ANOVA. تُعرض لوحة الإعداد أدناه:
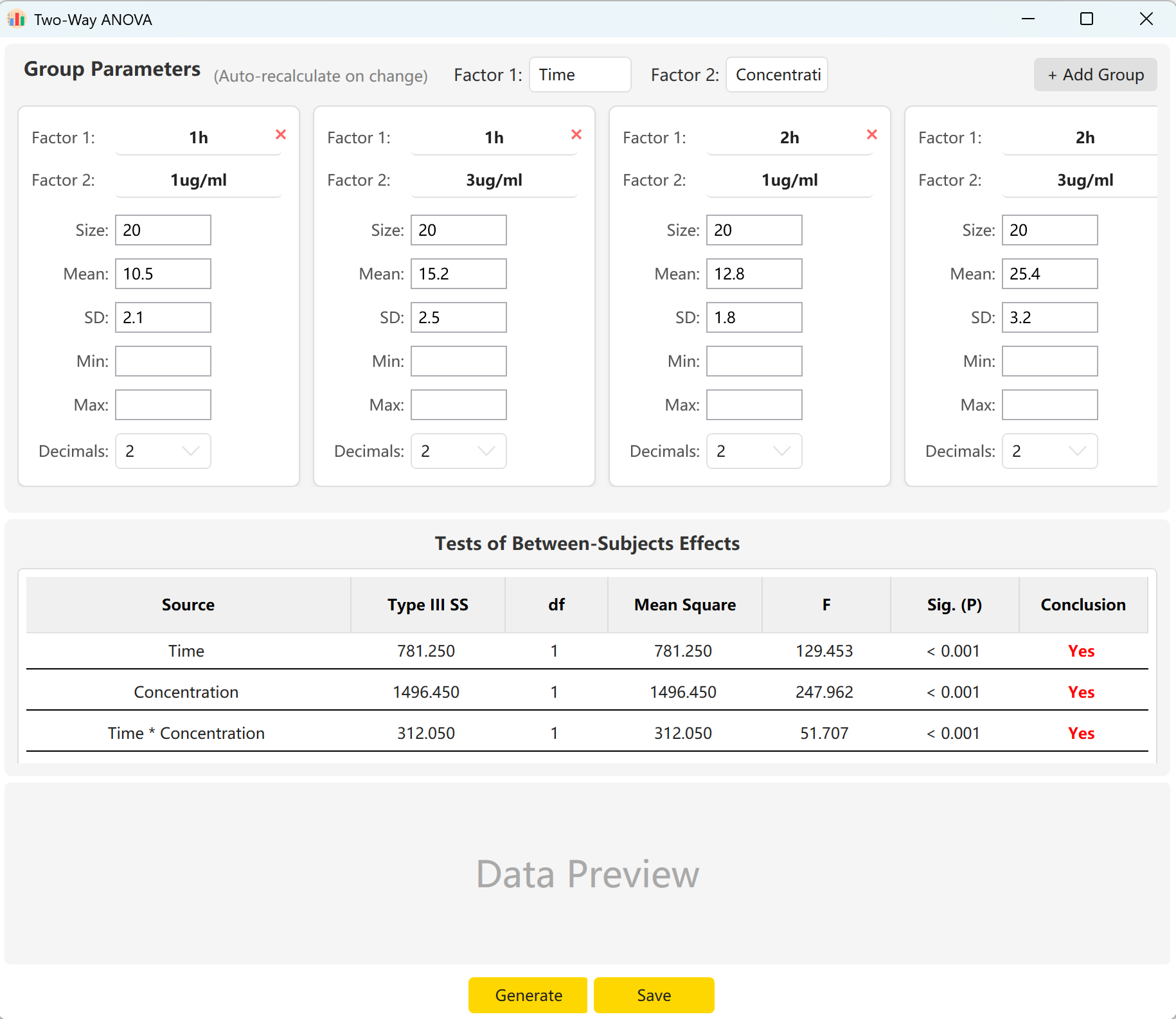
الشكل 6.1: واجهة المستخدم / العمليات لتحليل التباين الثنائي
6.2 العوامل والتفاعلات
تعتمد الأداة افتراضياً عاملين: 'Time' (مستويان) و'Concentration' (مستويان). انقر إضافة مجموعة لإعداد مستويات إضافية إذا كان العامل يحتوي على تصنيفات متعددة.
بإدخال حجم العينة والمتوسط والانحراف المعياري لكل خلية، يمكنك معاينة إحصاءات F وقيم p للتأثير الرئيسي للوقت، والتأثير الرئيسي للتركيز، وتأثير التفاعل بينهما (Time × Concentration). انقر توليد لبناء السجلات الخام الفردية المطابقة في لوحة المعاينة.
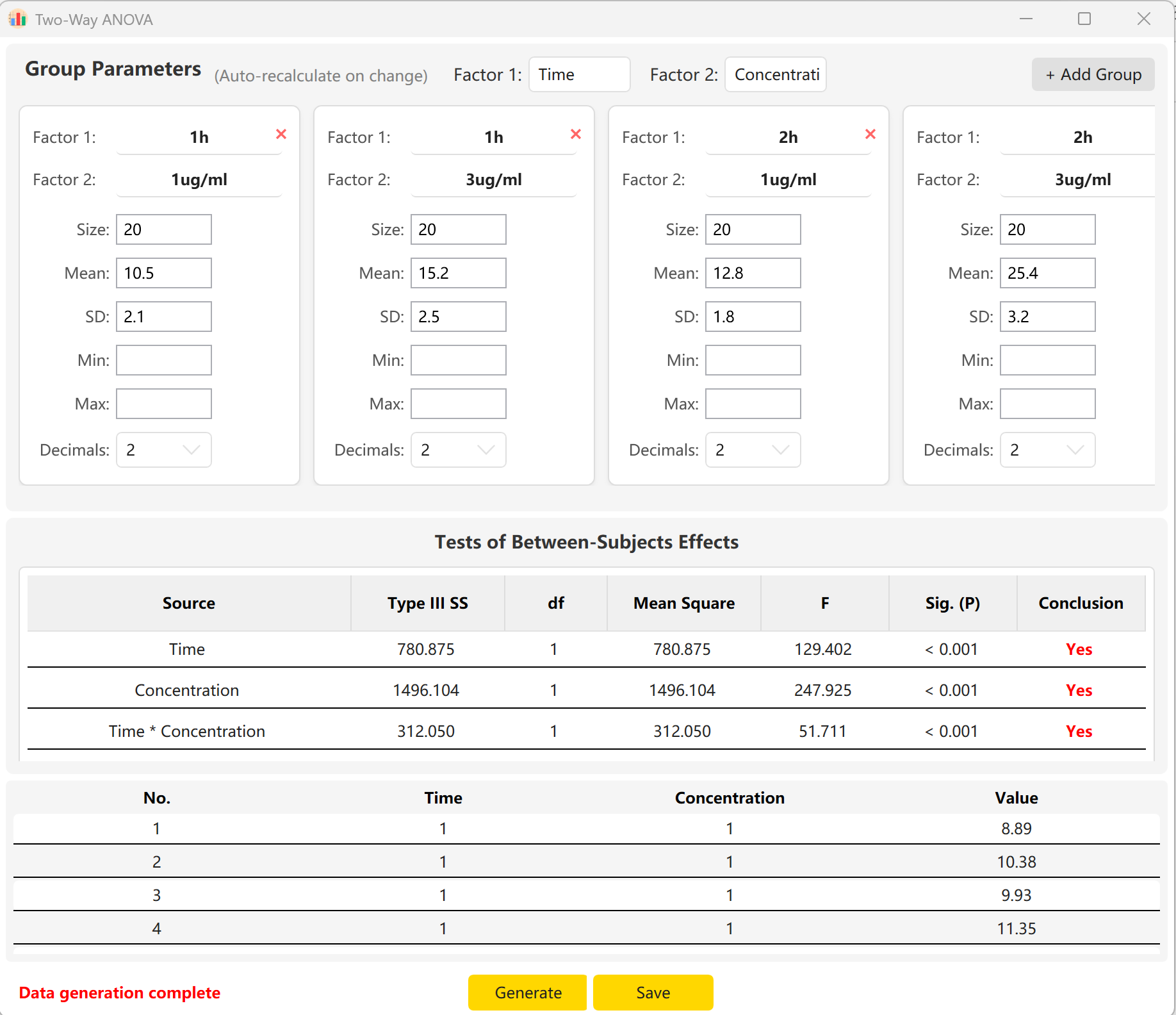
الشكل 6.2: واجهة المستخدم / العمليات لعرض بيانات تحليل التباين الثنائي
7. تحليل التباين الأحادي للقياسات المتكررة
امتداد لاختبار T المزدوج إلى ثلاث نقاط زمنية أو أكثر. مثالي للتتبع الطولي عبر فترات ممتدة (مثل خط الأساس، الشهر 1، الشهر 3).
7.1 سير العمل
انتقل إلى Analyze → ANOVA → Repeated Measures ANOVA. يظهر تخطيط مساحة العمل أدناه:
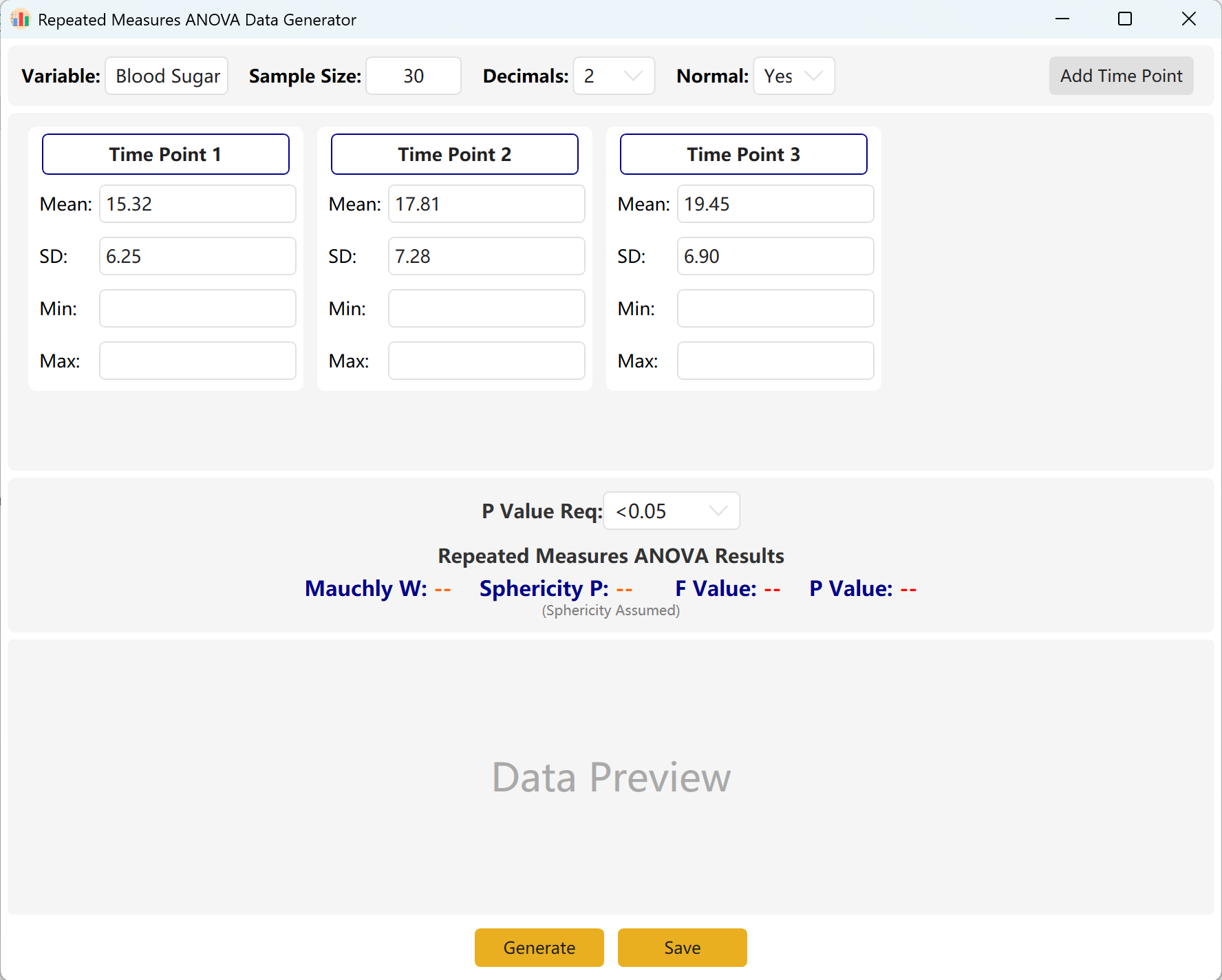
الشكل 7.1: واجهة المستخدم / العمليات لتحليل التباين الأحادي للقياسات المتكررة
7.2 الملاحظات المتكررة
يعتمد النظام افتراضياً ثلاث نقاط زمنية للملاحظة. يمكنك زيادتها بسهولة بالنقر على إضافة نقطة زمنية أدخل المتوسط والانحراف المعياري لكل نقطة زمنية وحدد نطاق قيمة p المستهدفة.
انقر توليد لتركيب قيم متوافقة.
ضغط المحرك: إذا كان الفرق بين النقاط الزمنية كبيراً رياضياً (مما يشير إلى قيمة p عالية الدلالة) لكن نطاقك المستهدف مضبوط على p > 0.05، فسيضغط المحرك تلقائياً التباينات وفروق المتوسط بين النقاط الزمنية لتحقيق قيمة p المستهدفة بدقة. ستعرض نافذة منبثقة الإحصاءات الفعلية لمجموعة البيانات المركبة.
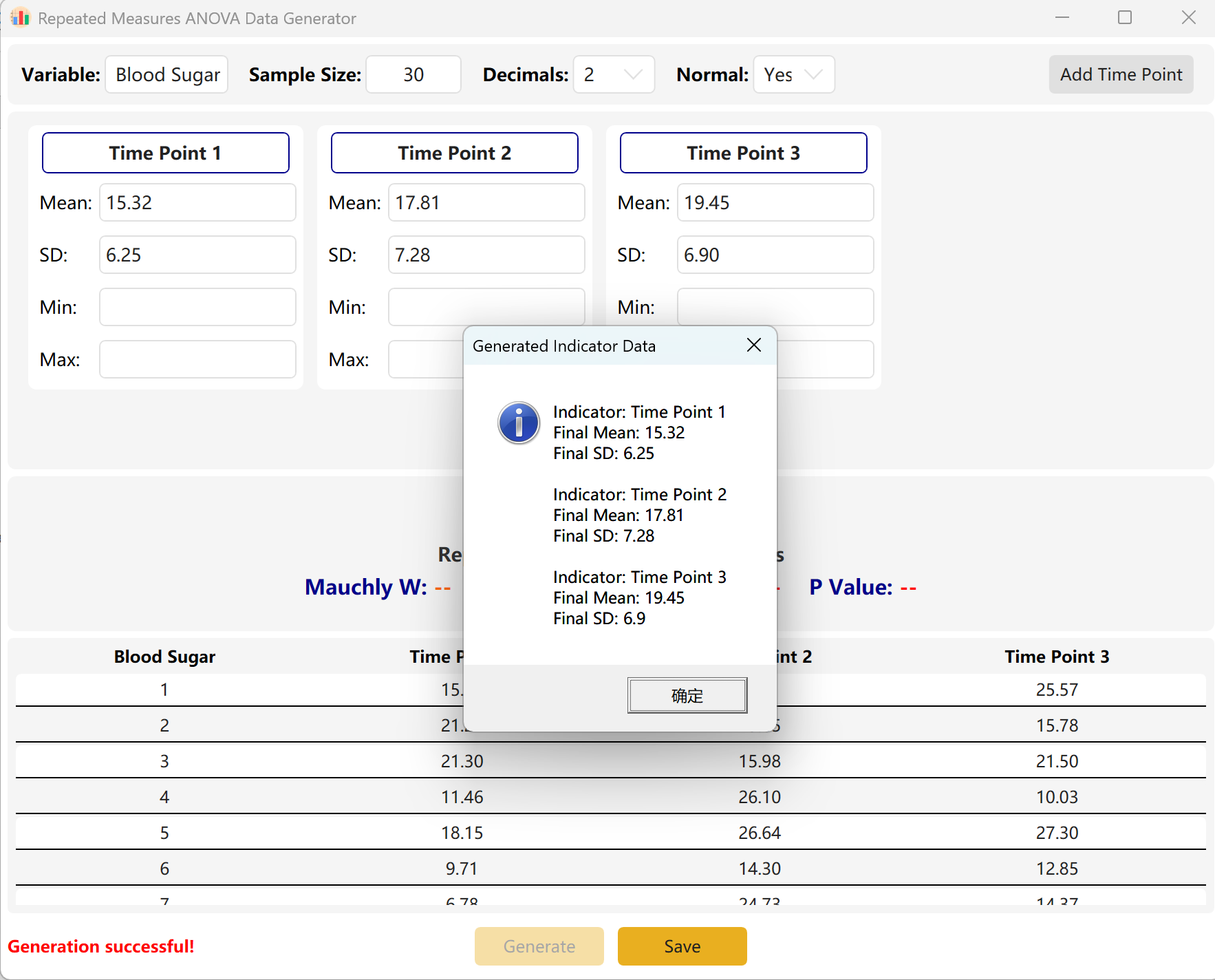
الشكل 7.2: واجهة المستخدم / العمليات لعرض بيانات ANOVA للقياسات المتكررة
8. اختبار مجموع الرتب لعينتين مستقلتين (لامعلمي)
بديل اختبار Mann-Whitney U للبيانات التي لا تحقق افتراضات الطبيعية. يقيّم فروق الوسيط بناءً على منطق ترتيب الرتب للمتغيرات المستمرة أو الترتيبية.
8.1 سير العمل
انتقل إلى Analyze → Non-parametric → 2 Independent Samples. تظهر مساحة عمل الإعداد أدناه:
1.png)
الشكل 8.1: واجهة المستخدم / العمليات لاختبار مجموع الرتب لعينتين مستقلتين
8.2 الإعداد
يعتمد البرنامج افتراضياً مجموعتين مرجعيتين. وبما أن الطرق اللامعلمية مصممة للبيانات غير الموزعة طبيعياً، فإن خيار التوزيع الطبيعي مضبوط على لا افتراضياً. باستخدام اختبار Mann-Whitney U، يمكنك تحديد نطاق قيمة p مستهدفة. انقر توليد لتركيب ملاحظات خام متوافقة إحصائياً مع هذا الحد.
منطق توليد مجموع الرتب: تحلل الاختبارات اللامعلمية فروق المجموعات عبر دمج جميع الملاحظات وتعيين الرتب. لذلك، إذا كانت معلمات المجموعتين مختلفة جداً (مما يعطي طبيعياً قيمة p صغيرة جداً) لكنك ضبطت الحد المستهدف على p > 0.05، فسيقلل المحرك تلقائياً التباعد بين المجموعتين لتحقيق هدفك. ستُعرض المتوسطات والانحرافات المعيارية النهائية في نافذة منبثقة.
2.png)
الشكل 8.2: واجهة المستخدم / العمليات لعرض بيانات اختبار مجموع الرتب لعينتين مستقلتين
9. اختبار Kruskal-Wallis (K عينات مستقلة لامعلمية)
مكافئ لاختبار Kruskal-Wallis H. يولد بيانات ترتيبية أو مستمرة غير موزعة طبيعياً عبر ثلاث مجموعات مستقلة أو أكثر.
9.1 سير العمل
انتقل إلى Analyze → Non-parametric → K Independent Samples. تظهر مساحة عمل الإعداد أدناه:
1.png)
الشكل 9.1: واجهة المستخدم / العمليات لاختبار Kruskal-Wallis
9.2 ترتيب المجموعات المتعددة
يعتمد البرنامج افتراضياً ثلاث مجموعات مرجعية ويجري اختبار Kruskal-Wallis. وكما في اختبار المجموعتين، لأن الحسابات تعتمد على الرتب في مجموعة بيانات مدمجة، فإذا كانت معلمات المجموعات المتعددة تتضمن فروقاً كبيرة (مما ينتج قيم p عالية الدلالة) لكنك تطلب هدف p > 0.05، فسيضغط محرك المحاكاة فروق ما بين المجموعات تلقائياً. ستُلخص الإحصاءات الناتجة في نافذة منبثقة.
2.png)
الشكل 9.2: واجهة المستخدم / العمليات لعرض بيانات اختبار Kruskal-Wallis
10. توليد بيانات الربيعات
يقسم مجموعة بيانات مرتبة إلى أربعة أجزاء متساوية. مفيد لتقييم انتشار البيانات ونزعتها المركزية وإبراز الوسيط واكتشاف القيم الشاذة.
10.1 سير العمل
انتقل إلى Analyze → Quartile Data. يوضح التخطيط أدناه:
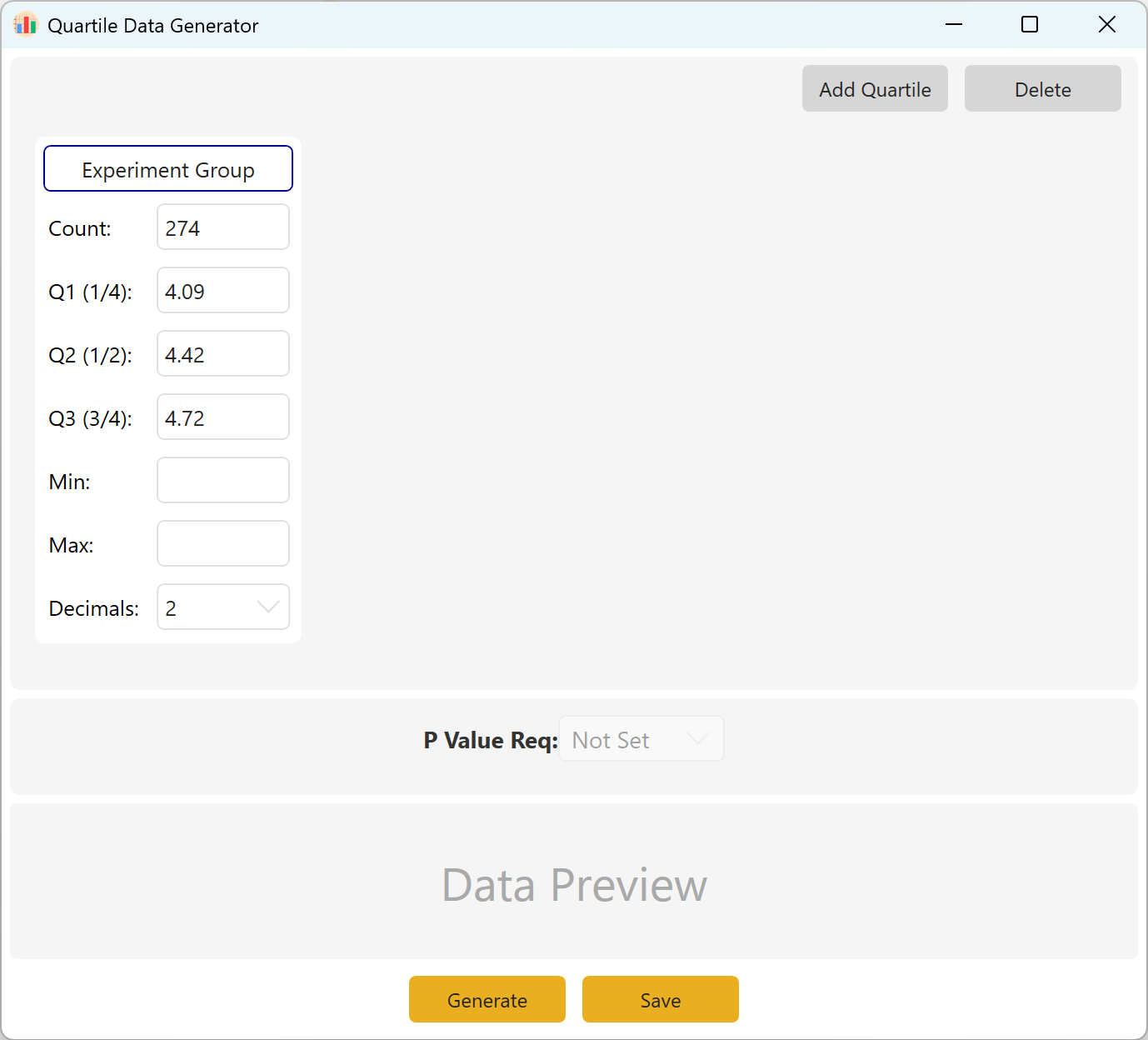
الشكل 10.1: واجهة المستخدم / العمليات لبيانات الربيعات
10.2 تعريف المعلمات
حدد حجم العينة المستهدف وQ1 (المئين 25) وQ2 (الوسيط/المئين 50) وQ3 (المئين 75). يمكن ترك حدود الحد الأدنى/الأقصى فارغة إذا لم توجد قيود محددة. اختر الدقة العشرية وانقر توليد لإنتاج ملاحظات تحقق حدود الربيعات هذه بدقة.
الملخص: اضبط أحجام العينات والقيم المستهدفة لـ Q1 وQ2 وQ3. تشمل المعلمات الاختيارية الحد الأدنى والحد الأقصى والمنازل العشرية. انقر توليد لحساب وعرض الملاحظات الخام المطابقة لبنية الربيعات المستهدفة. في إعدادات المجموعات المتعددة، يمكنك أيضاً تثبيت نطاق قيمة p مستهدفة بين المجموعات.
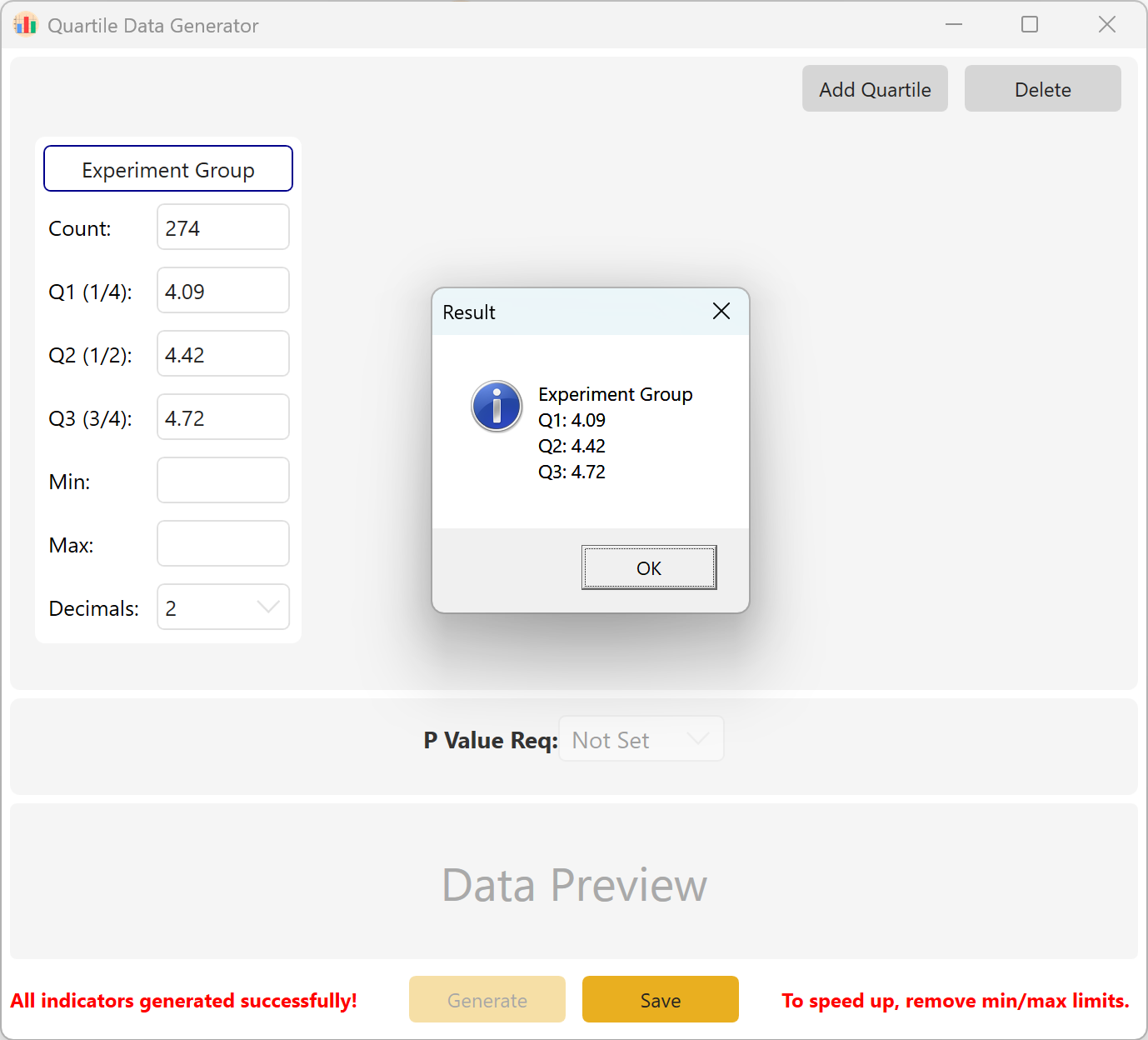
الشكل 10.2: واجهة المستخدم / العمليات لعرض بيانات الربيعات
11. توليد بيانات الانحدار اللوجستي الثنائي
أساسي لمشكلات التصنيف التي تكون فيها النتيجة ثنائية (DV=0 أو DV=1). شائع جداً في علم الوبائيات لتحديد عوامل الخطر (مثل المرض مقابل الصحة).
11.1 سير العمل
انتقل إلى Analyze → Regression → Binary Logistic.
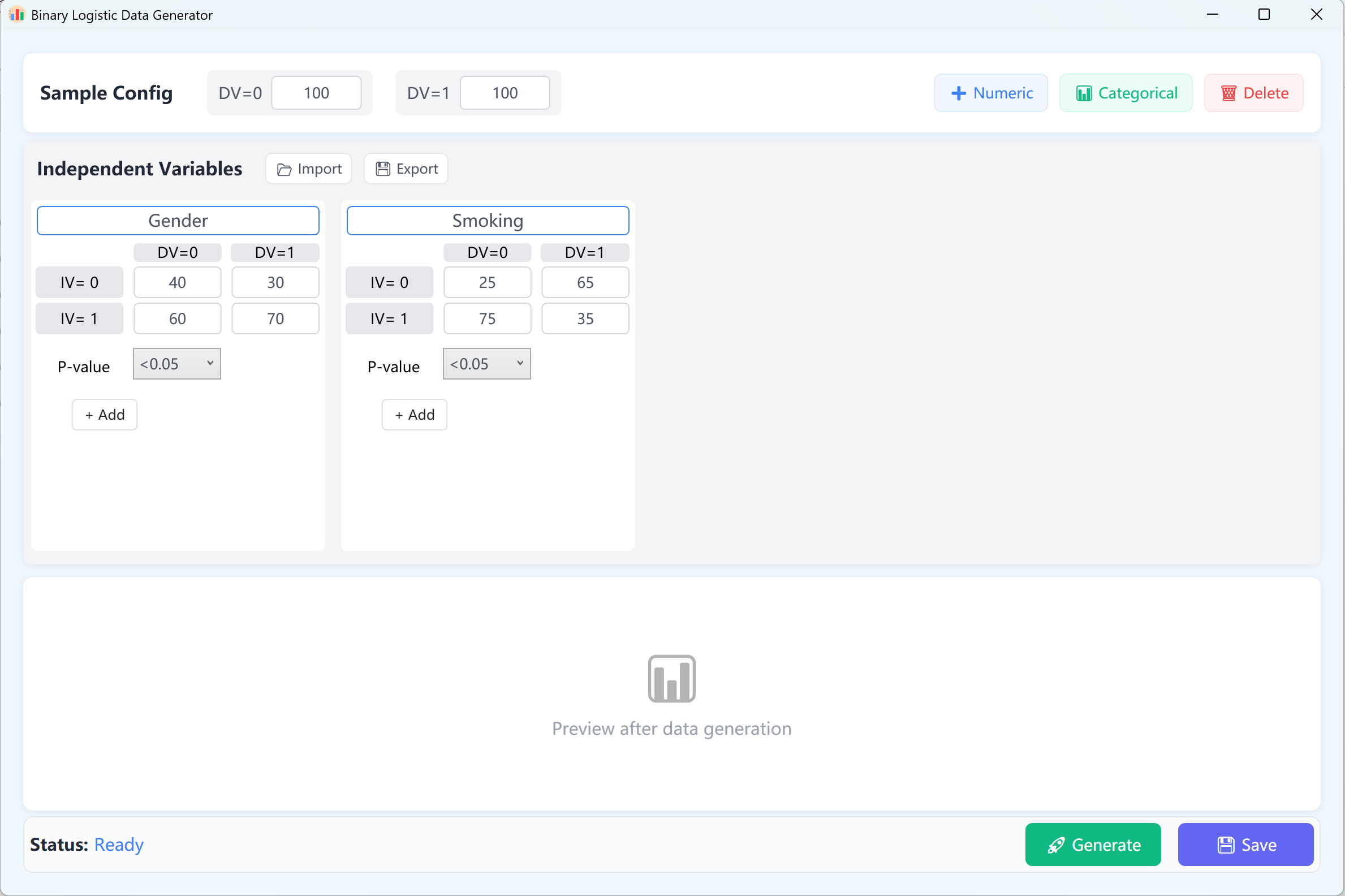
الشكل 11.1: واجهة المستخدم / العمليات للانحدار اللوجستي الثنائي
11.2 التصميم
افتراضياً، يتم إعداد متغيرين مستقلين مستمرين كمرجع. في النموذج اللوجستي الثنائي، يحتوي المتغير التابع على نتيجتين فقط (0 و1). لذلك يُبنى المتغير التابع كمجموعتي 0 و1، مع حجم عينة افتراضي 100 حالة لكل فئة (قابل للتخصيص).
- إعداد المتغير: انقر + رقمي لإضافة متغيرات مستقلة مستمرة (مثل 'Age' و'BMI'). أدخل اسم المتغير والمتوسط والانحراف المعياري والمنازل العشرية ونطاق قيمة p المستهدف (وهو يحدد مستوى الدلالة المستهدف الذي تريد أن يحققه المتغير في نموذج الانحدار اللوجستي النهائي). قيود الحد الأدنى/الأقصى اختيارية.
- التوليد والتحقق: انقر توليد لتشغيل خوارزمية التركيب. سيحسب النظام بشكل تكراري مجموعة بيانات يعطي فيها نموذج الانحدار اللوجستي قيماً لـ p تطابق إعداداتك.
سيظهر تلقائياً تقرير تفصيلي لتحليل الانحدار بتنسيق يطابق IBM SPSS. عند إغلاق التقرير، ستظهر مجموعة البيانات الخام في جدول المعاينة جاهزة للتصدير إلى Excel.
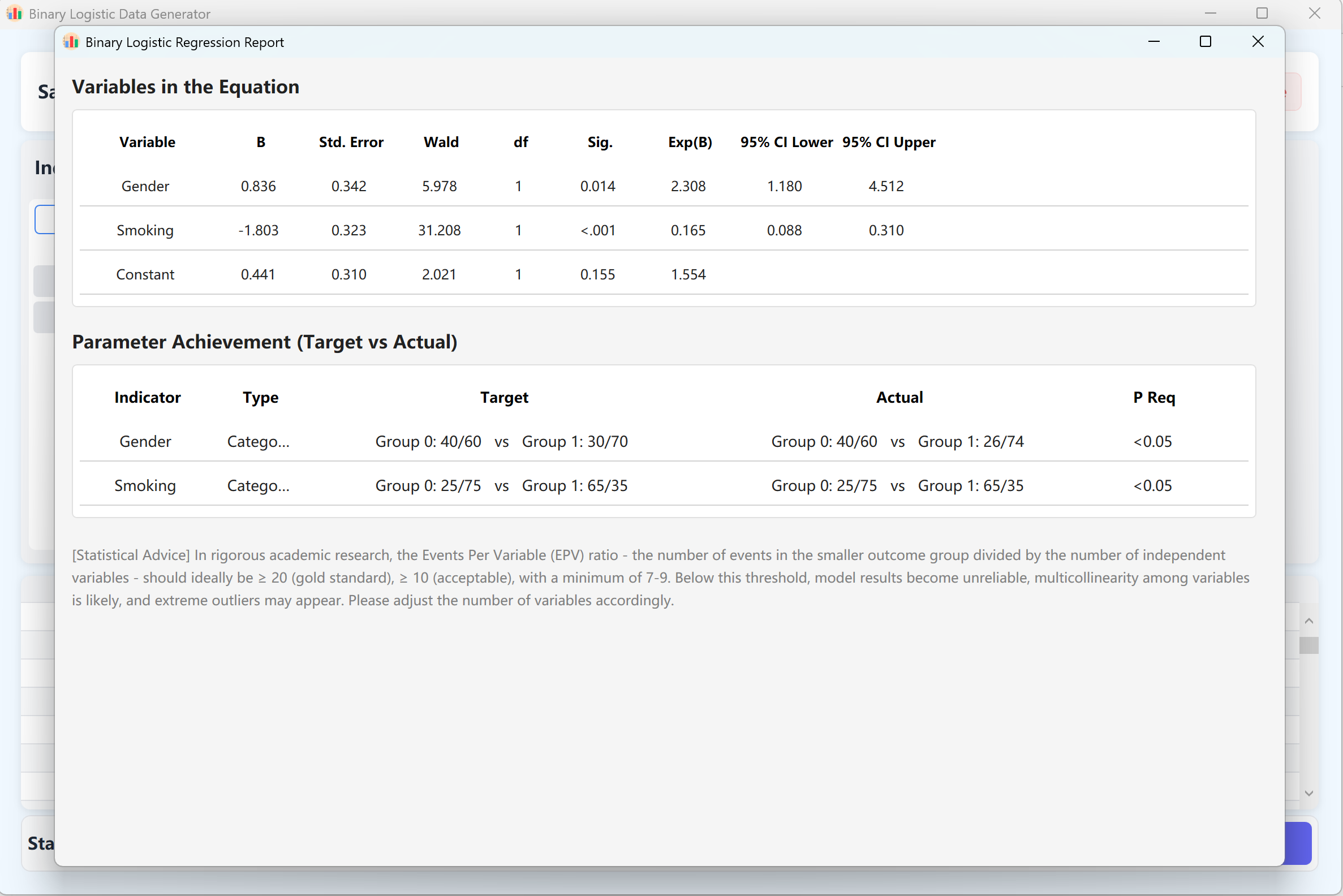
الشكل 11.2: واجهة المستخدم / العمليات لعرض بيانات الانحدار اللوجستي الثنائي
12. توليد بيانات الانحدار الخطي المتعدد
أداة أساسية للنمذجة التنبؤية. تركب متغيراً تابعاً مستمراً (Y) يتأثر بعدة متغيرات مستقلة (X)، ويمكن أن تكون رقمية مستمرة أو ربيعات أو فئوية مرتبة أو فئوية غير مرتبة.
12.1 سير العمل
انتقل إلى Analyze → Regression → Linear Regression.
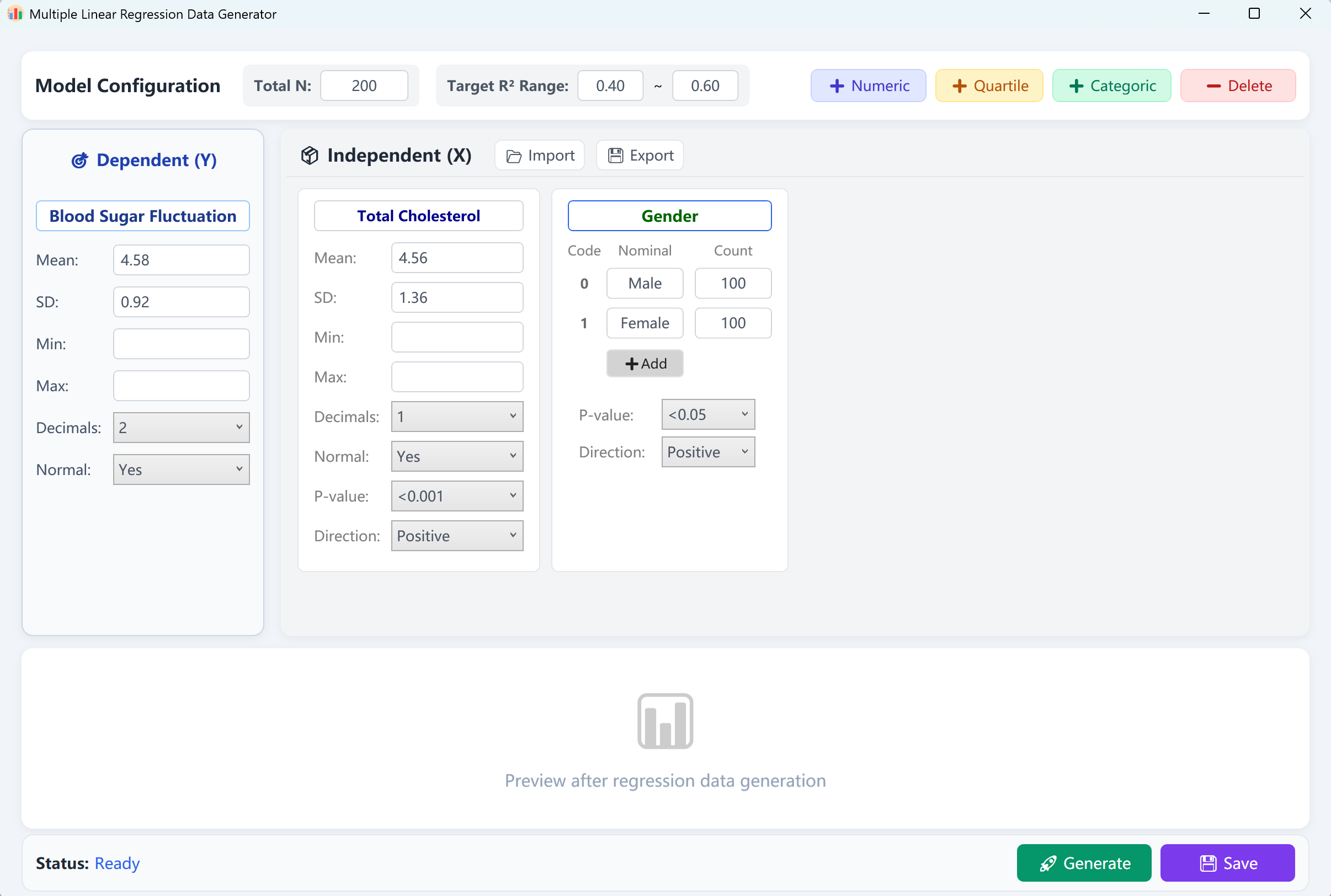
الشكل 12.1: واجهة المستخدم / العمليات للانحدار الخطي المتعدد
12.2 إعدادات النموذج
تحمّل الواجهة مسبقاً متغيراً تابعاً مستمراً ('Blood Glucose Fluctuation') ومتغيرين مستقلين ('Total Cholesterol' كرقمي و'Gender' كفئوي) مع حجم عينة افتراضي 200 حالة. يمكنك ضبط نطاق R-squared (R²) مستهدف (مثل 0.4 إلى 0.6).
انقر توليد لتشغيل نموذج الانحدار. سيظهر تقرير تحقق يطابق مخرجات SPSS. عند إغلاق التقرير، تعود إلى جدول معاينة البيانات الخام، والذي يمكن حفظه كجدول Excel.
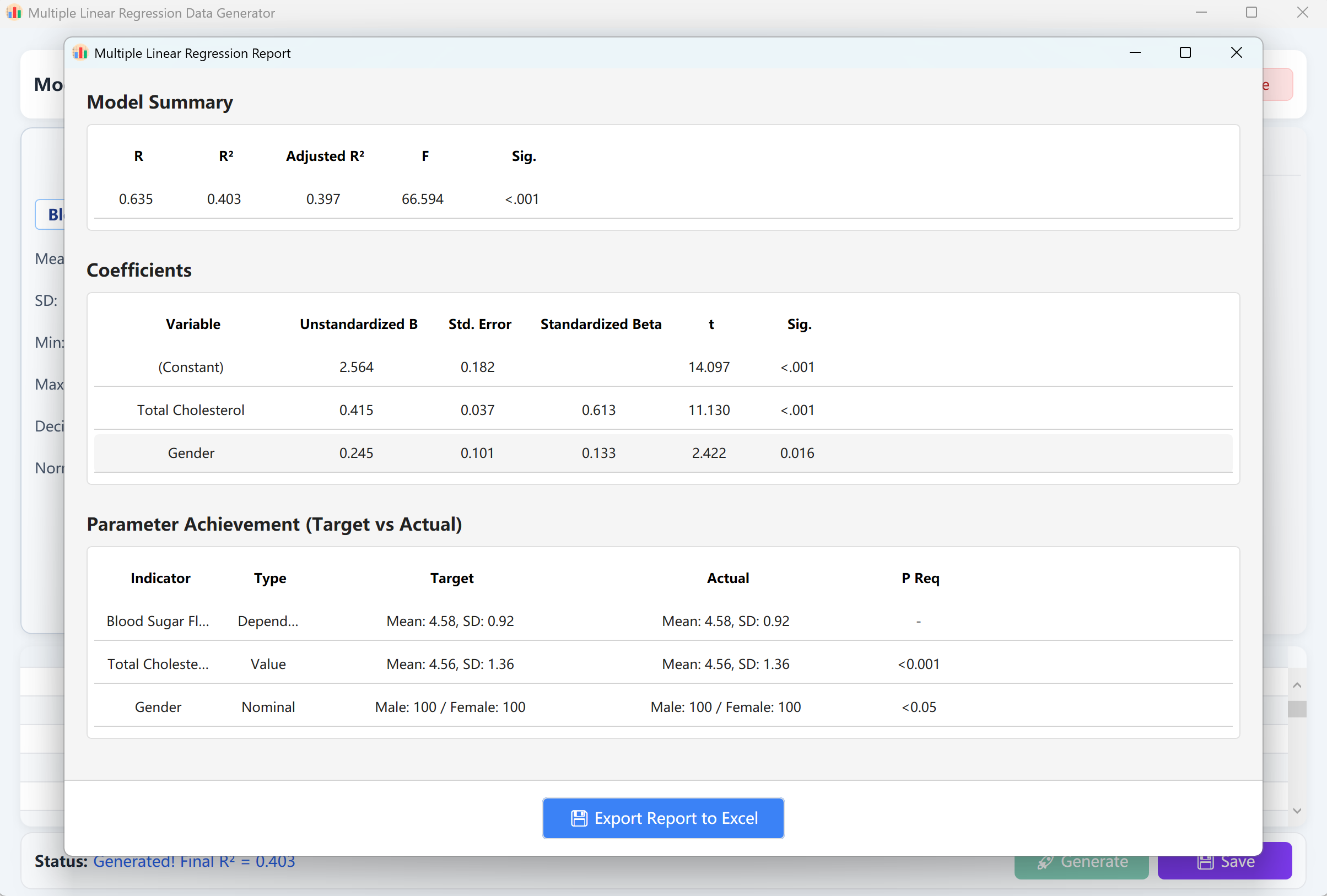
الشكل 12.2: واجهة المستخدم / العمليات لعرض بيانات الانحدار الخطي المتعدد
13. توليد بيانات انحدار Cox للمخاطر النسبية
المعيار الذهبي لتحليل البقاء. يحاكي بيانات الوقت حتى الحدث مع مراعاة الرقابة اليمنى، مما يتيح للباحثين تقييم تأثير المتغيرات المشتركة على أزمنة البقاء.
13.1 سير العمل والإرشادات الفنية
انتقل إلى Analyze → Regression → Cox Regression.
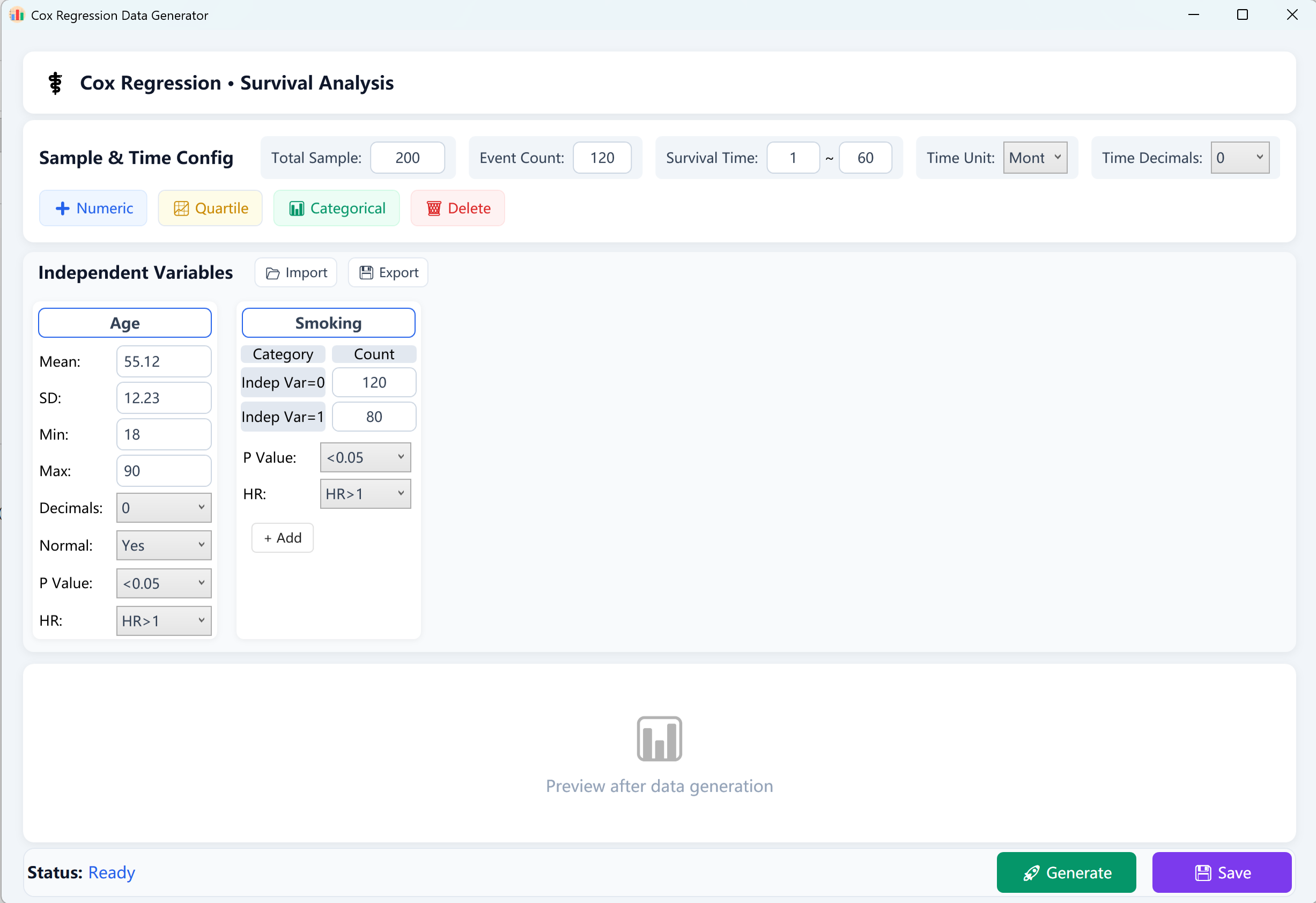
الشكل 13.1: واجهة المستخدم / العمليات لانحدار Cox للمخاطر النسبية
- إجمالي حجم العينة (N): العدد الكلي للمشاركين/المرضى (مثل 200 مشارك).
- الأحداث المرصودة (أحداث النتيجة): عدد الحالات الإيجابية التي شهدت النتيجة النهائية (مثل الوفاة أو النكس أو فشل الحدث) خلال فترة المتابعة. ملاحظة: يجب أن يكون عدد الأحداث أقل تماماً من إجمالي حجم العينة.
- نطاق زمن البقاء (T): حدد حدود مدة البقاء من [الحد الأدنى للمتابعة] إلى [الحد الأقصى للمتابعة] (مثل 1~60 شهراً)، ووسم الزمن بالأيام أو الأشهر أو السنوات، وحدد الدقة العشرية الرقمية.
قاعدة EPV الإحصائية (الأحداث لكل متغير): لضمان الاستقرار الرياضي والموثوقية في نموذج Cox للمخاطر النسبية، يُوصى بشدة بأن تكون نسبة أحداث النتيجة المرصودة إلى عدد المتغيرات المستقلة (EPV) بين 10 و20 على الأقل. إذا فشل النموذج في التقارب، فحاول زيادة إجمالي حجم العينة أو عدد الأحداث المرصودة.
13.2 بناء متغيرات البحث
انقر الأزرار المقابلة أسفل بطاقة المتغير لبناء المتغيرات المشتركة المستقلة:
- متغيرات رقمية مستمرة: انقر + رقمي لإضافة متغيرات مشتركة مستمرة (مثل العمر وBMI والمؤشرات الحيوية السريرية). أدخل المتوسط والانحراف المعياري (مطلوب)، واختيارياً حدود الحد الأدنى/الأقصى لتقييد القيم الشاذة والدقة العشرية.
- متغيرات فئوية: انقر + فئوي لإضافة متغيرات مشتركة اسمية/ترتيبية (مثل Gender أو Satisfaction Score). أدخل التكرار المستهدف الدقيق لكل فئة. ملاحظة: يجب أن يساوي مجموع الأعداد عبر جميع الفئات إجمالي حجم العينة تماماً حتى يعمل.
- متغيرات الربيعات: انقر + ربيع لإضافة متغيرات منظمة بالربيعات عبر ملء معلمات Q1 وQ2 (الوسيط) وQ3 المستهدفة.
المعلمات المستهدفة: تحتوي كل بطاقة متغير في الأسفل على معلمتين مستهدفتين قويتين:
- قيمة p للانحدار: اختر أهداف الدلالة (مثل p > 0.05 أو p < 0.05 أو p < 0.01 أو p < 0.001).
- اتجاه نسبة الخطر (HR): اختر إما HR > 1 (عامل خطر يشير إلى زيادة معدل الخطر) أو HR < 1 (عامل وقائي يشير إلى انخفاض معدل الخطر).
13.3 تنفيذ توليد البيانات وحفظها
بعد ملء جميع المعلمات، انقر توليد أسفل النافذة. سينفذ الخلفية محاكاة تكرارية عالية التوازي. سيظهر تلقائياً تقرير موثوق وشامل لتحليل انحدار Cox للمخاطر النسبية، يعكس الإحصاءات الدقيقة والتنسيق المحسوبين بواسطة IBM SPSS.
انقر حفظ لتصدير مجموعة البيانات الخام المركبة إلى ملف Excel يمكن استيراده بسهولة إلى SPSS أو حزم إحصائية احترافية أخرى للتحقق.
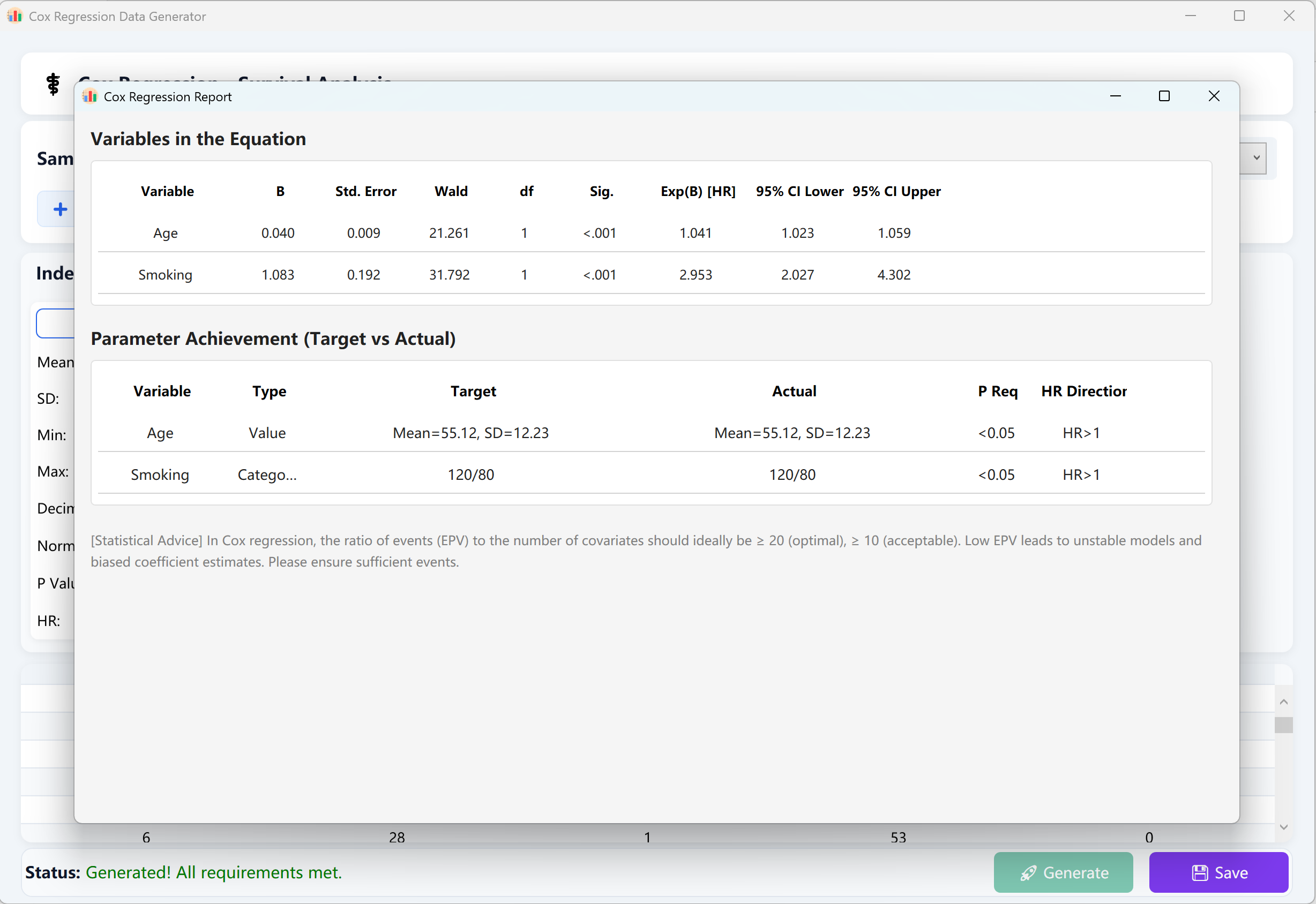
الشكل 13.2: واجهة المستخدم / العمليات لعرض بيانات انحدار Cox للمخاطر النسبية
14. توليد بيانات لتحليل الارتباط
يحاكي العلاقات الثنائية (Pearson أو Spearman) والارتباط الجزئي عبر فرض معاملات الارتباط المستهدفة (قيم r) ومستويات الدلالة.
14.1 سير العمل
انتقل إلى Analyze → Correlation.
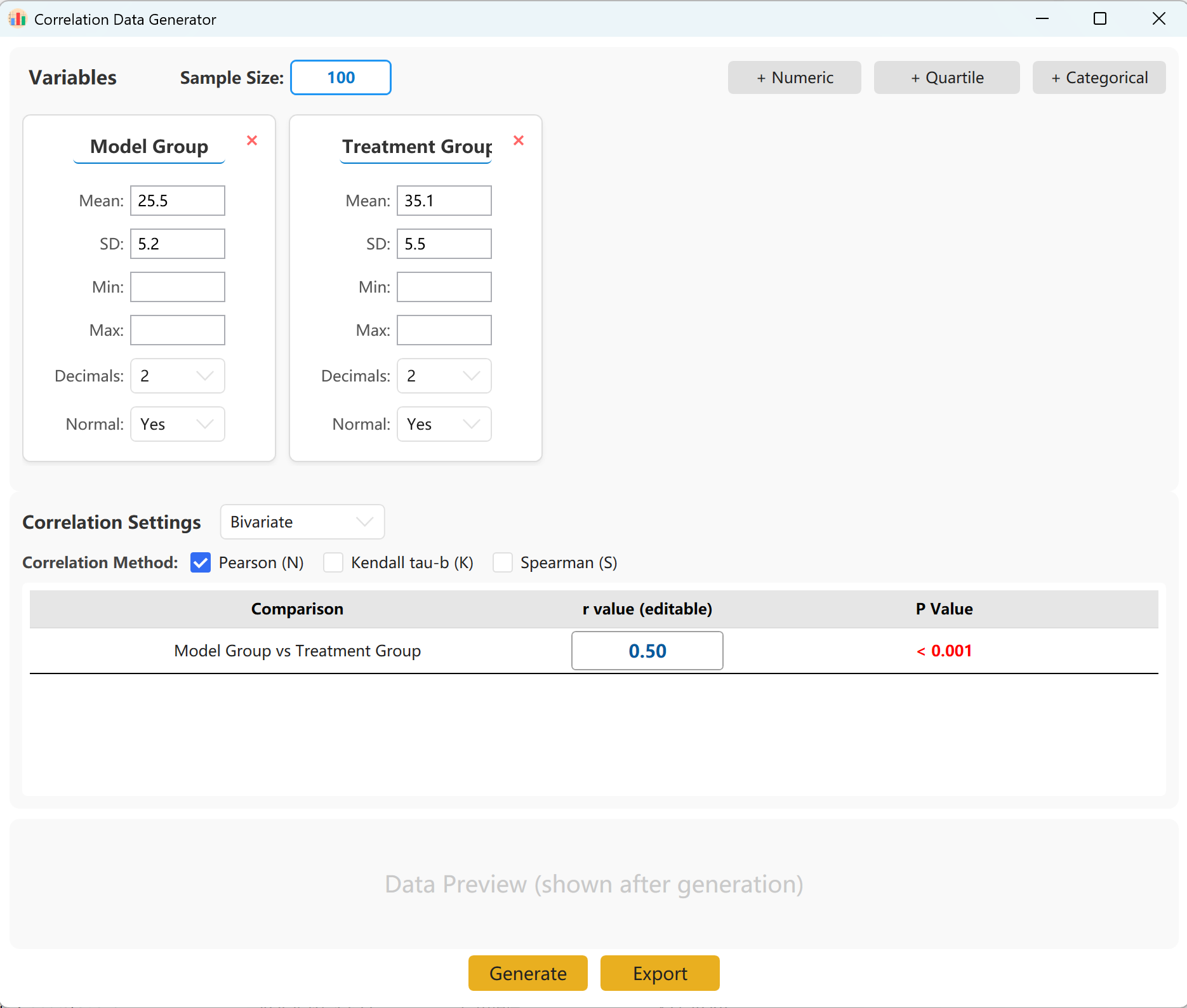
الشكل 14.1: واجهة المستخدم / العمليات لتحليل الارتباط
14.2 المعلمات
يحمّل النظام مسبقاً مجموعتين من المتغيرات كمرجع سريع. يمكنك بسهولة إضافة متغيرات أخرى تدعم الأشكال المستمرة (المتوسط/الانحراف المعياري) والربيعات والفئات. داخل لوحة الإعداد، حدد حجم العينة والمتوسط والانحراف المعياري لكل مقياس (حدود الحد الأدنى/الأقصى اختيارية).
يمكنك تحديد معامل الارتباط المستهدف الدقيق (r) بين المجموعات. عند النقر توليد سيتم تشغيل المحاكاة وعرض مصفوفة الارتباط الناتجة في نافذة منبثقة، ويمكن بعد ذلك تصديرها كملف Excel.
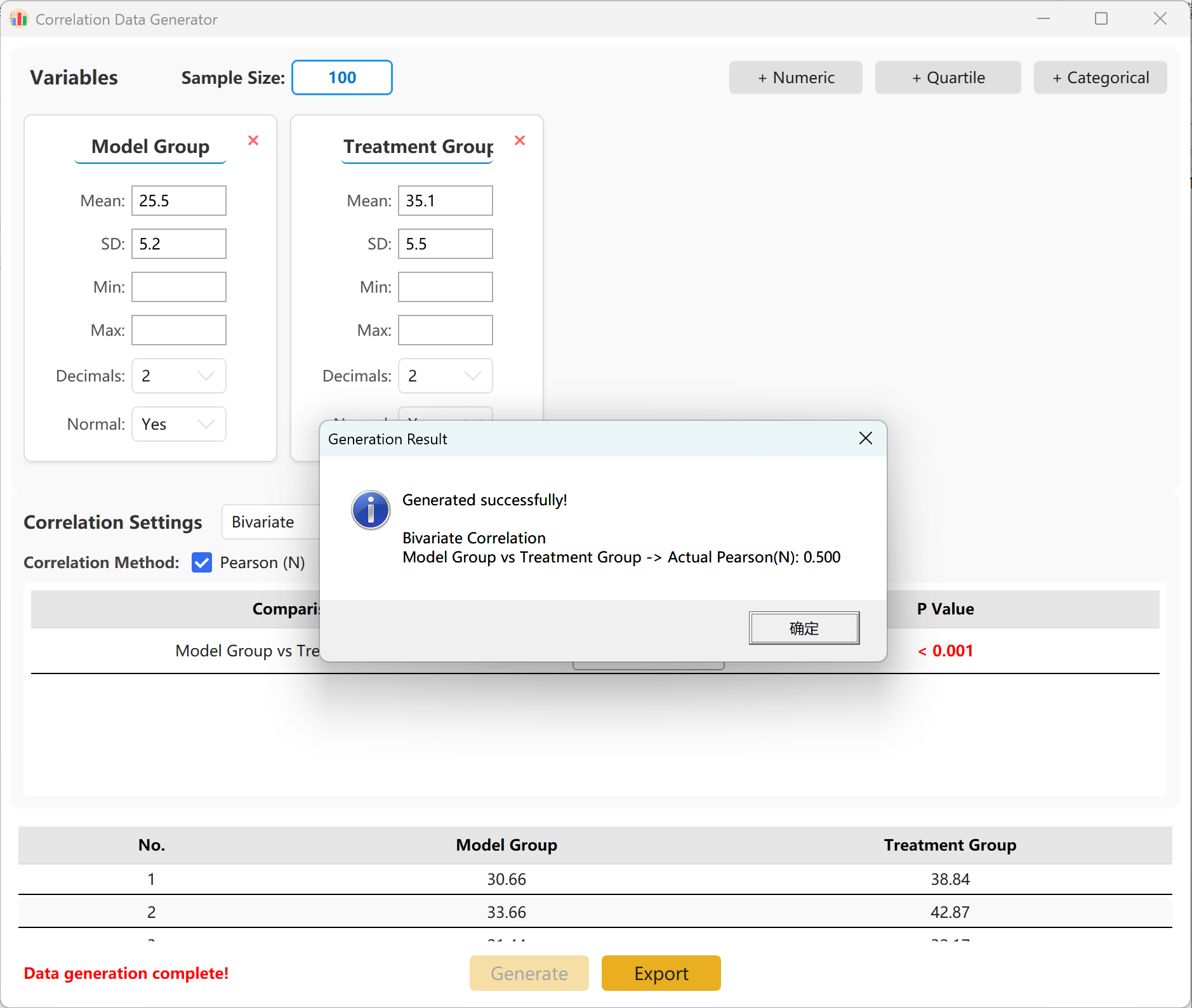
الشكل 14.2: واجهة المستخدم / العمليات لعرض بيانات تحليل الارتباط
15. توليد بيانات لتحليل منحنى ROC
يقيّم القدرة التشخيصية لمتغير اختبار مستمر أو فئوي على التمييز بين حالتين (مثل التشخيص الإيجابي مقابل السلبي).
15.1 سير العمل
انتقل إلى Analyze → ROC Curve.
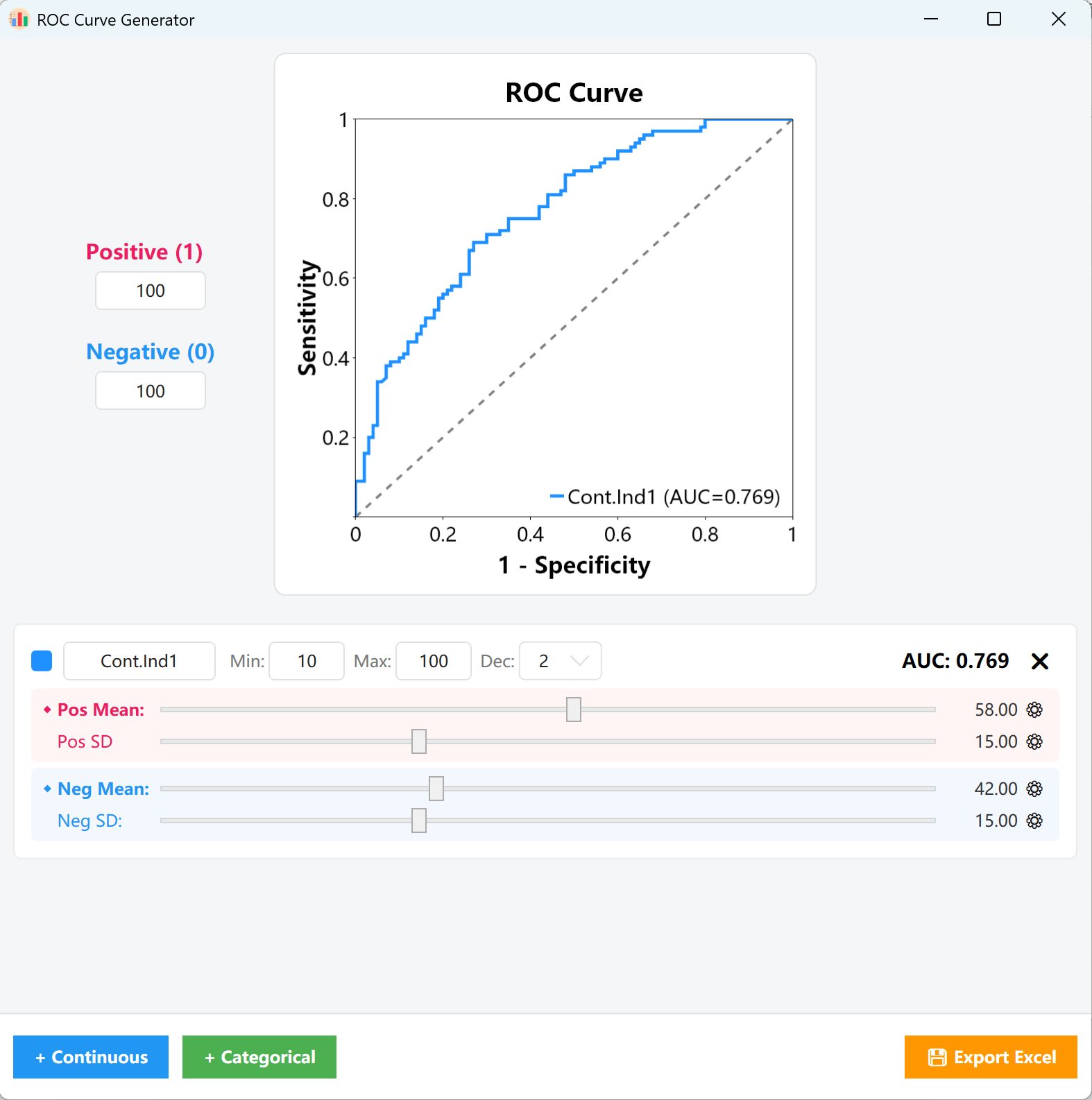
الشكل 15.1: واجهة المستخدم / العمليات لإعدادات منحنى ROC
النسب: في لوحة المعلمات على اليسار، أدخل أعداد الحالات المستهدفة للعينات الإيجابية (1) والعينات السلبية (0) (مثل 100 حالة إيجابية و100 حالة سلبية). سيبني محرك التوليد مصفوفة العينة الإحصائية الأساسية بناءً على هذه النسب.
15.2 أنواع المتغيرات
انقر + مستمر أو + فئوي في أسفل اليسار لإنشاء المتغيرات المقابلة:
- متغيرات مستمرة: خصص اسم المتغير وحدود الحد الأدنى/الأقصى والمنازل العشرية المستهدفة على البطاقة. اسحب شريط التمرير الوردي (المجموعة الإيجابية) والأزرق (المجموعة السلبية) لضبط توزيعات المتوسط والانحراف المعياري لكل منهما بسرعة.
- ⚙ ضبط الدقة: إذا لم تتمكن أشرطة التمرير المرئية من الوصول إلى الدقة المطلوبة، فانقر أيقونة الترس (⚙) بجانب المعلمة لإدخال قيم عشرية دقيقة يدوياً.
- مراقبة AUC: طوال عملية الضبط، سيتحدث مؤشر AUC = 0.XXX في أعلى يمين البطاقة ولوحة الرسم المركزية فورياً بالكامل، مما يسمح لك بمحاذاة المنحنى بصرياً مع حد القطع المستهدف بدقة.
- متغيرات فئوية: حدد ببساطة النسب أو الأعداد الدقيقة لكل من المجموعتين الإيجابية والسلبية. يمكنك فوراً مراقبة التغييرات المقابلة في منحنى ROC وقيمة AUC.
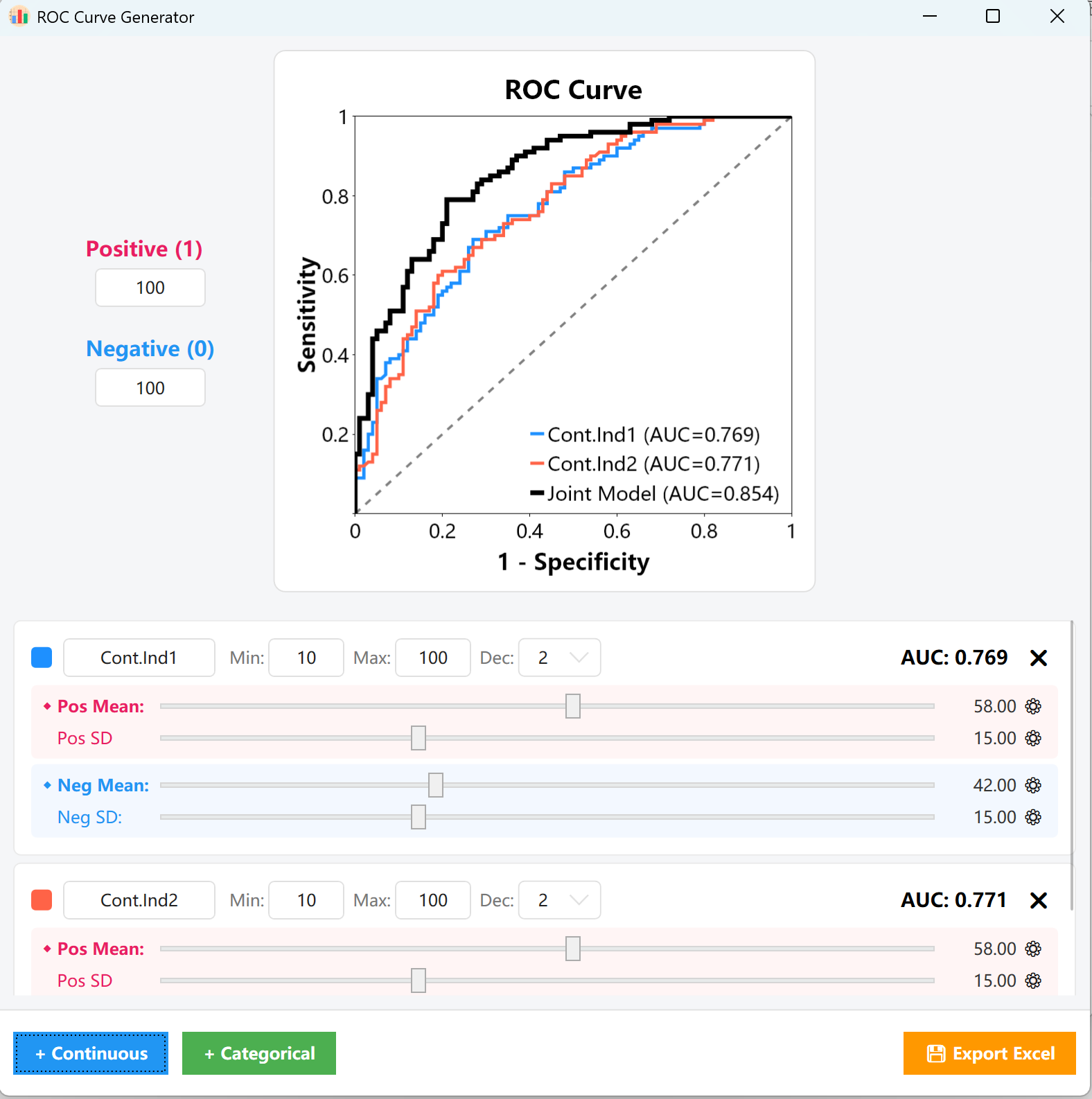
الشكل 15.2: واجهة المستخدم / العمليات لعرض مخطط منحنى ROC
16. حفظ وتصدير المعلمات المضبوطة
لتبسيط مهام النمذجة المتكررة وتجنب أخطاء الإعداد اليدوي، يوفر التطبيق آلية مدمجة قوية لحفظ حالة الإعداد.
16.1 الحفظ/الاستعادة
- تصدير الإعداد: انتقل إلى File → Export Configuration لحفظ جميع المعلمات المضبوطة وتعريفات المتغيرات وبنى المجموعات والأهداف كملف إعداد محلي بصيغة `.json` على جهازك.
- استيراد الإعداد: لاستعادة إعداداتك في جلسة لاحقة، انتقل ببساطة إلى File → Import Configuration واختر ملف الإعداد الذي حفظته سابقاً. ستُعاد مساحة العمل فوراً وتستعيد جميع بطاقات المتغيرات وأشرطة التمرير وقيم المعلمات.