Dokumentation & Benutzerhandbuch
Willkommen bei der offiziellen Dokumentation für DataSynth Pro. Dieses umfassende Handbuch bietet detaillierte Anleitungen zur Konfiguration von Parametern für verschiedene statistische Module, um robuste, wissenschaftlich tragfähige und statistisch valide Datensätze vollständig offline zu simulieren.
1. Mehrere Indikatoren gleichzeitig generieren
1.1 Voraussetzungen & Programmstart
Doppelklicken Sie auf die ausführbare Datei, um die Anwendung zu starten. Die Software benötigt das Microsoft .NET 8.0 Runtime-Framework. Wenn dieses nicht auf Ihrem Computer installiert ist, folgen Sie bitte den Anweisungen zum Herunterladen und Installieren und öffnen Sie das Programm anschließend erneut.
Sicherheitshinweis: Falls Ihre Antivirensoftware die ausführbare Datei fälschlicherweise als Bedrohung einstuft, fügen Sie sie bitte zu Ihren lokalen Ausnahmen oder der Whitelist hinzu, um einen reibungslosen Betrieb zu gewährleisten.
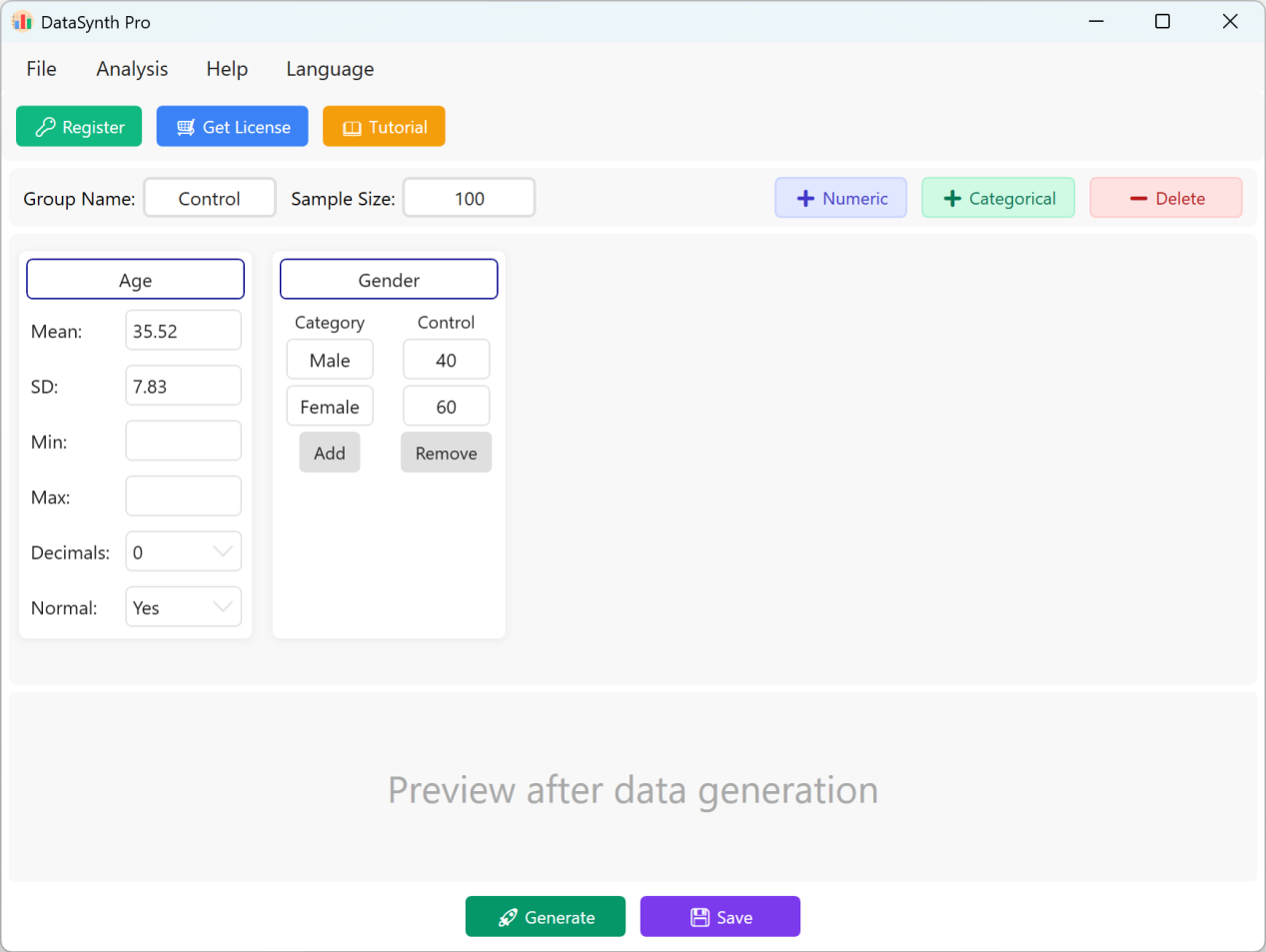
Abbildung 1.1: Benutzeroberfläche / Bedienung (Hauptfenster)
1.2 Parameterkonfiguration
Standardmäßig füllt die Anwendung zwei kontinuierliche Variablen, „Age“ (Alter) und „Gender“ (Geschlecht), als Schnellreferenz vor. Die Gruppenbezeichnung lautet standardmäßig „Control Group“ (Kontrollgruppe) und der Stichprobenumfang ist auf „100“ Fälle eingestellt. Wenn Ihre Studie mehrere Gruppen erfordert, können Sie den Datensatz jeder Gruppe nacheinander generieren und exportieren, indem Sie die Parameter für jeden Durchlauf aktualisieren.
- Hinzufügen kontinuierlicher numerischer Variablen: Um eine neue quantitative Variable hinzuzufügen, klicken Sie auf die Schaltfläche + Numeric. Sie können dann den Namen des Indikators (z. B. „Body-Mass-Index“ oder „BMI“), den Mittelwert, die Standardabweichung und die Dezimalstellen festlegen. Die Felder für die minimale (Minimum) und maximale (Maximum) Grenze sind optional und können leer gelassen werden, wenn Sie keine spezifischen Grenzwerte haben.
- Einstellungen zur Datenverteilung: Standardmäßig folgen die generierten numerischen Messwerte einer Normalverteilung. Wenn Sie nicht normalverteilte Daten benötigen, stellen Sie die Option Normal Distribution einfach auf No.
Verteilungsanpassung: Eine Normalverteilung basiert auf einer natürlichen Streubreite. Wenn Sie die minimale und maximale Grenze zu eng einschränken, wird die Normalkurve abgeschnitten, was zu nicht normalverteilten Werten führen kann. Versuchen Sie in diesem Fall, die Grenzen zu erweitern oder die Min/Max-Grenzwerte ganz zu entfernen.
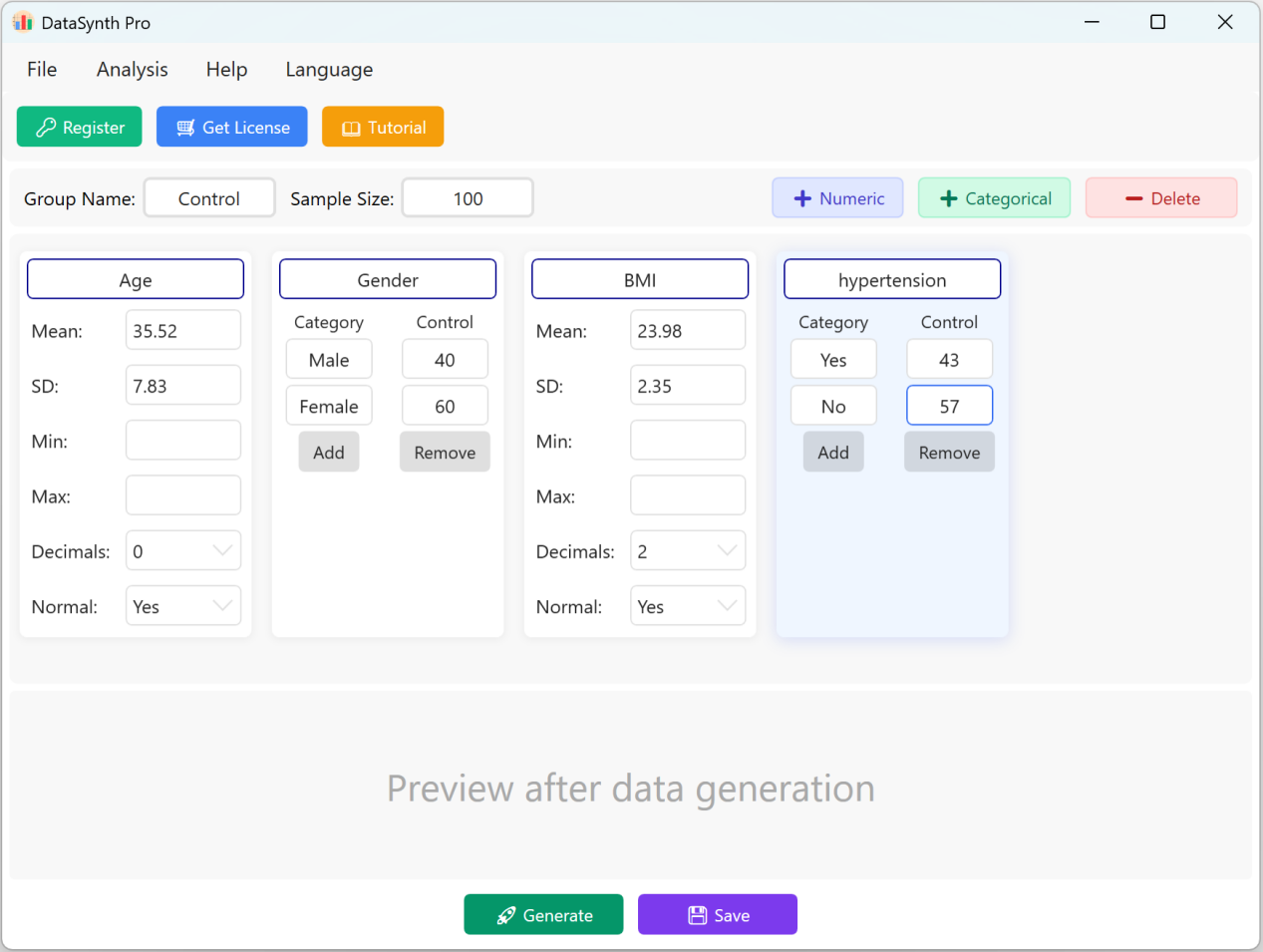
Abbildung 1.2: Benutzeroberfläche / Hinzufügen von Variablen
1.3 Hinzufügen kategorialer Variablen
Klicken Sie auf die Schaltfläche + Categorical, um qualitative Variablen (z. B. „Hypertension“ / Bluthochdruck) hinzuzufügen. Sie können Kategorienamen und die entsprechenden Zielverteilungen oder -anteile eingeben. Die Summe der Kategorieanteile wird dynamisch an Ihren konfigurierten Stichprobenumfang angepasst.
1.4 Generierung ausführen
Klicken Sie auf die Schaltfläche Generate, um die gewünschte Anzahl an Datensätzen zu simulieren. Nach der Berechnung öffnet sich ein Fenster mit einer deskriptiven Statistikübersicht, in dem Sie überprüfen können, ob die tatsächlich generierten Werte mit Ihren konfigurierten Parametern übereinstimmen.
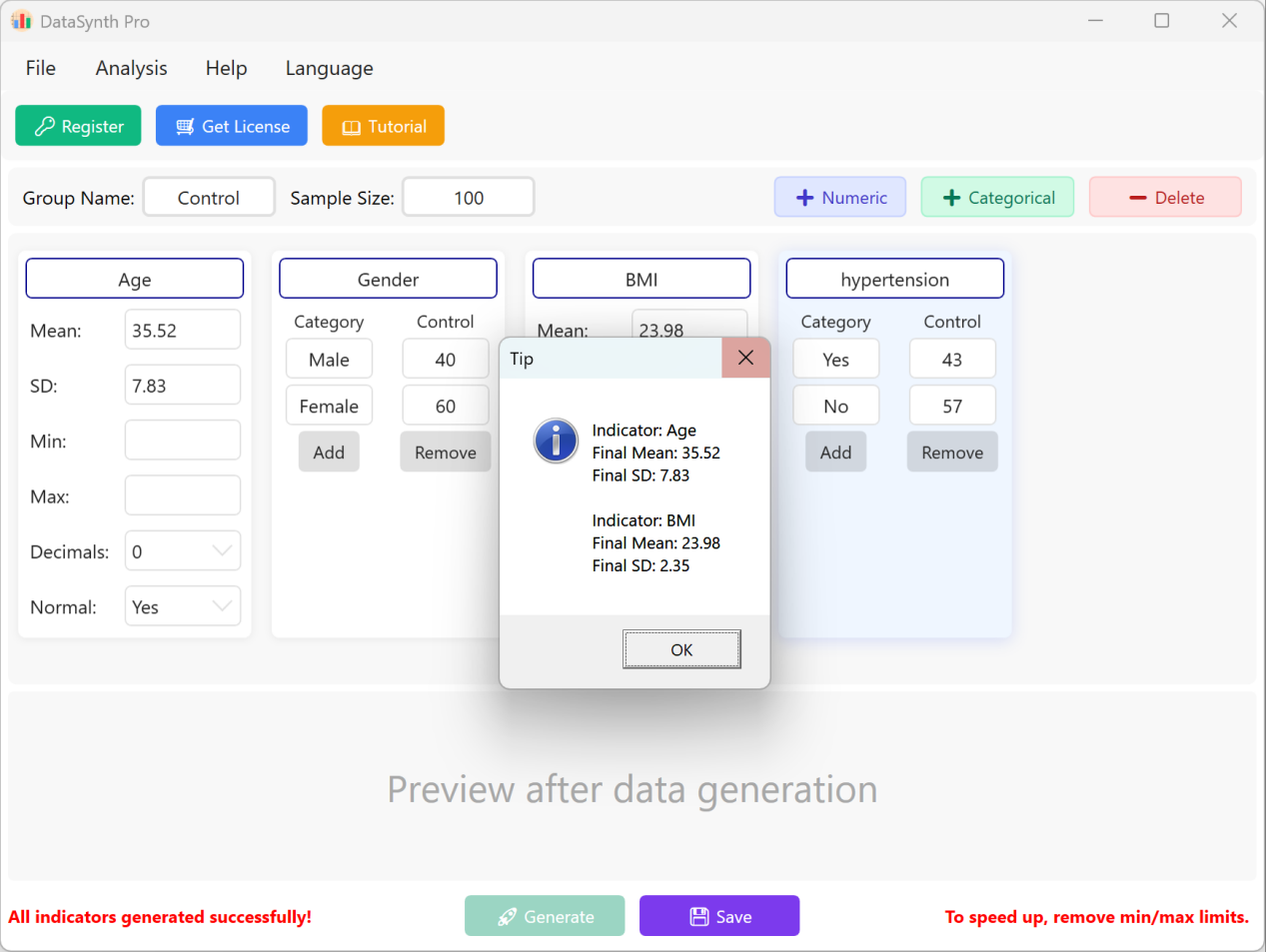
Abbildung 1.3: Benutzeroberfläche / Ausführen der Generierung
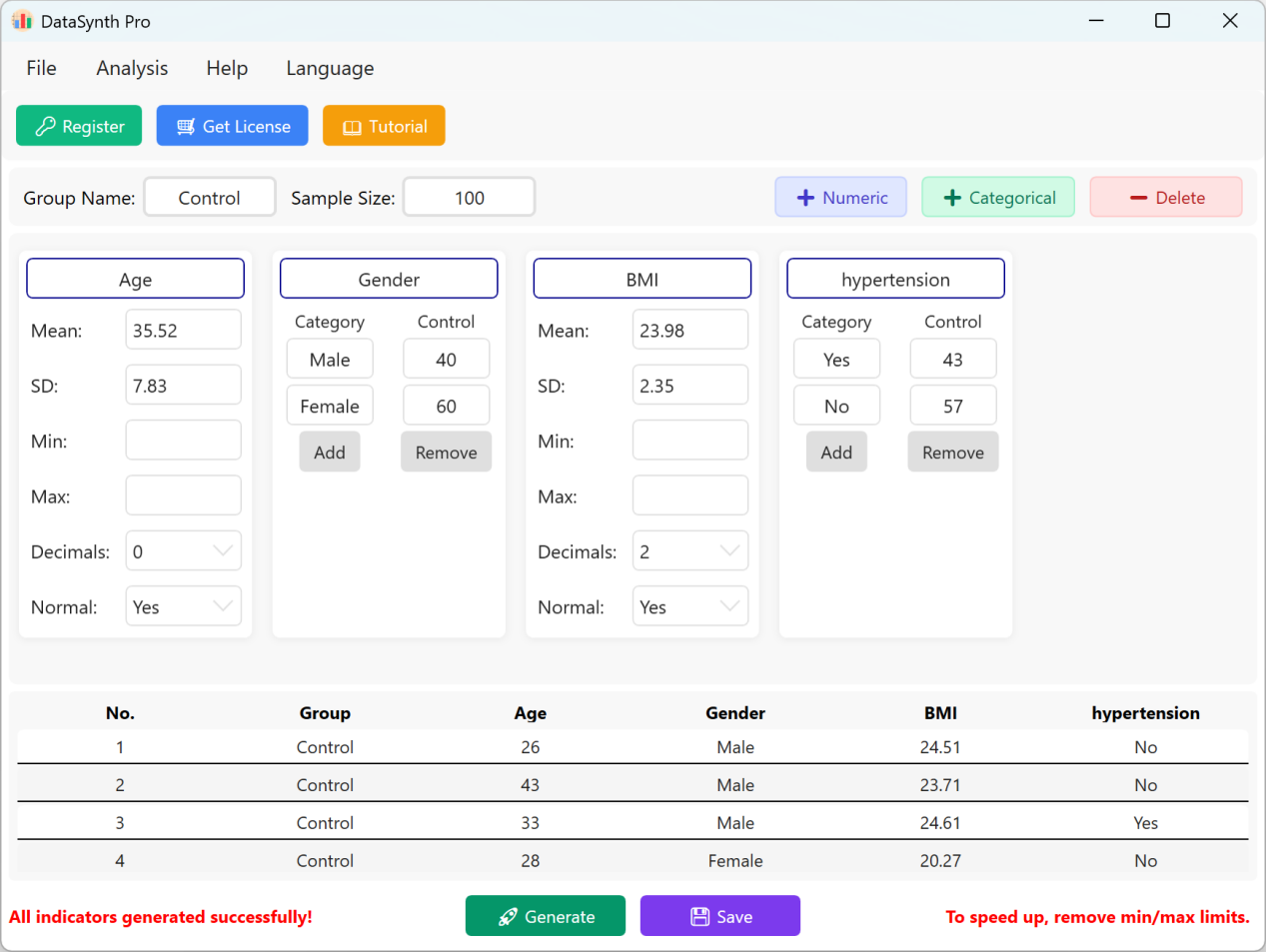
Abbildung 1.4: Benutzeroberfläche / Datenanzeige
1.5 Exportieren und Verifizieren
Klicken Sie auf die Schaltfläche Save, um den generierten Datensatz als Standard-Excel-Datei zu exportieren. Wenn Sie die exportierte Tabelle öffnen und die deskriptiven Statistiken für „Age“ (auf zwei Dezimalstellen gerundet) mit Standard-Excel-Formeln berechnen, stimmen der tatsächliche Mittelwert und die Standardabweichung perfekt mit Ihren ursprünglichen Einstellungen überein.
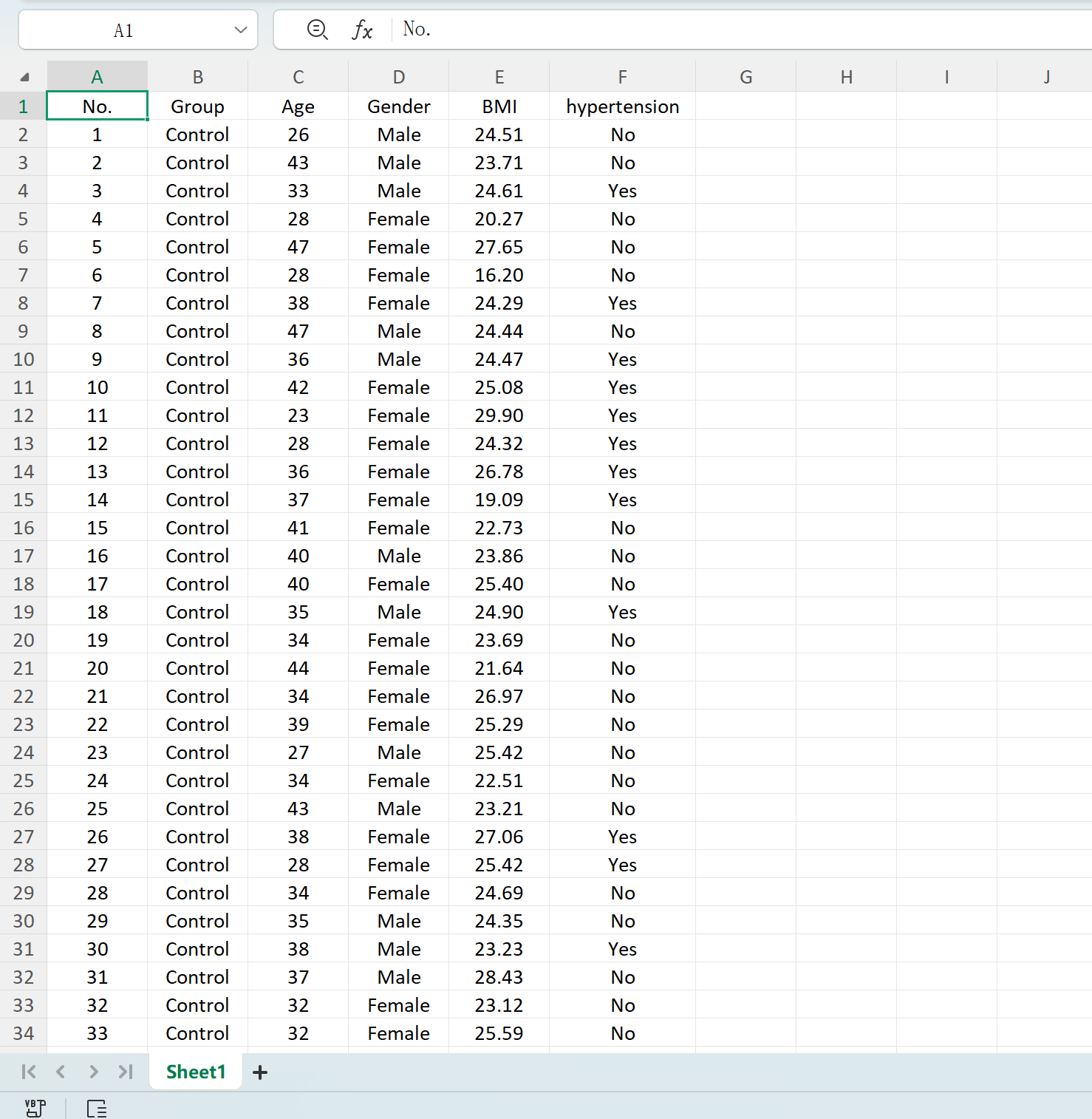
Abbildung 1.5: Exportieren generierter Tabellen nach Excel
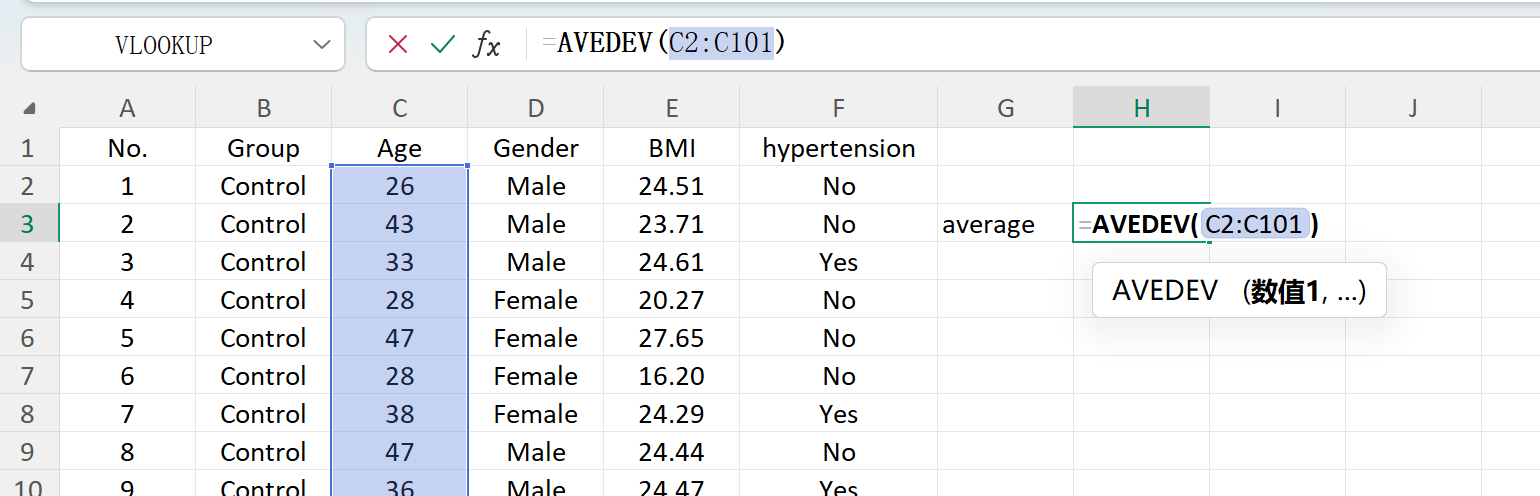
Abbildung 1.6: Excel-Berechnung des Mittelwerts
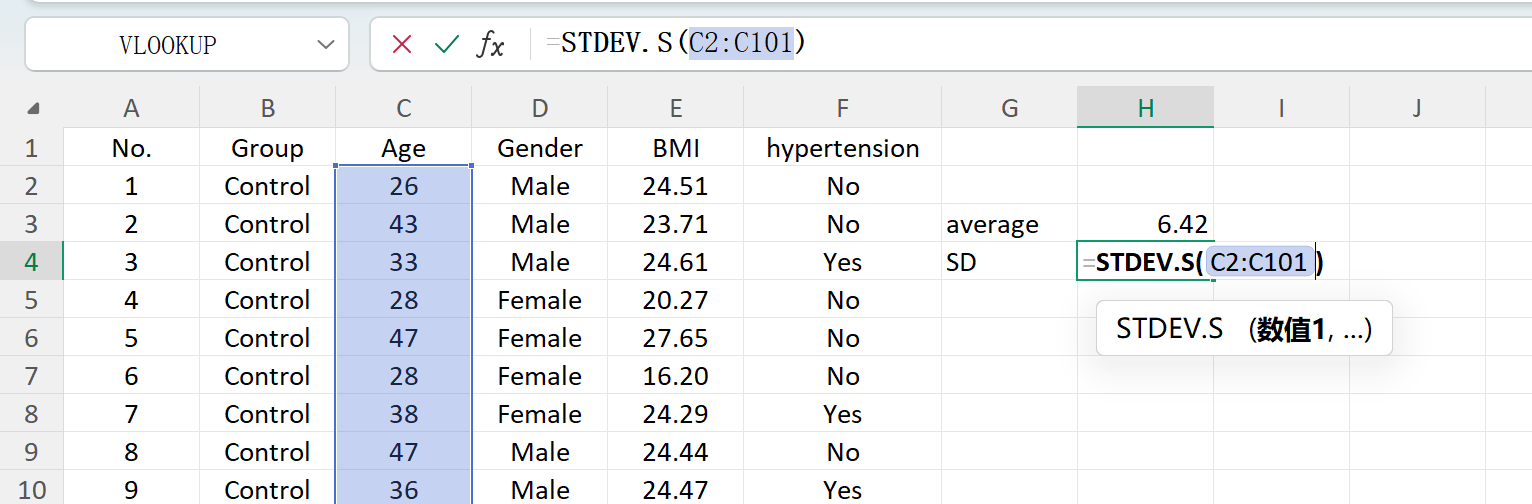
Abbildung 1.7: Excel-Berechnung der Standardabweichung
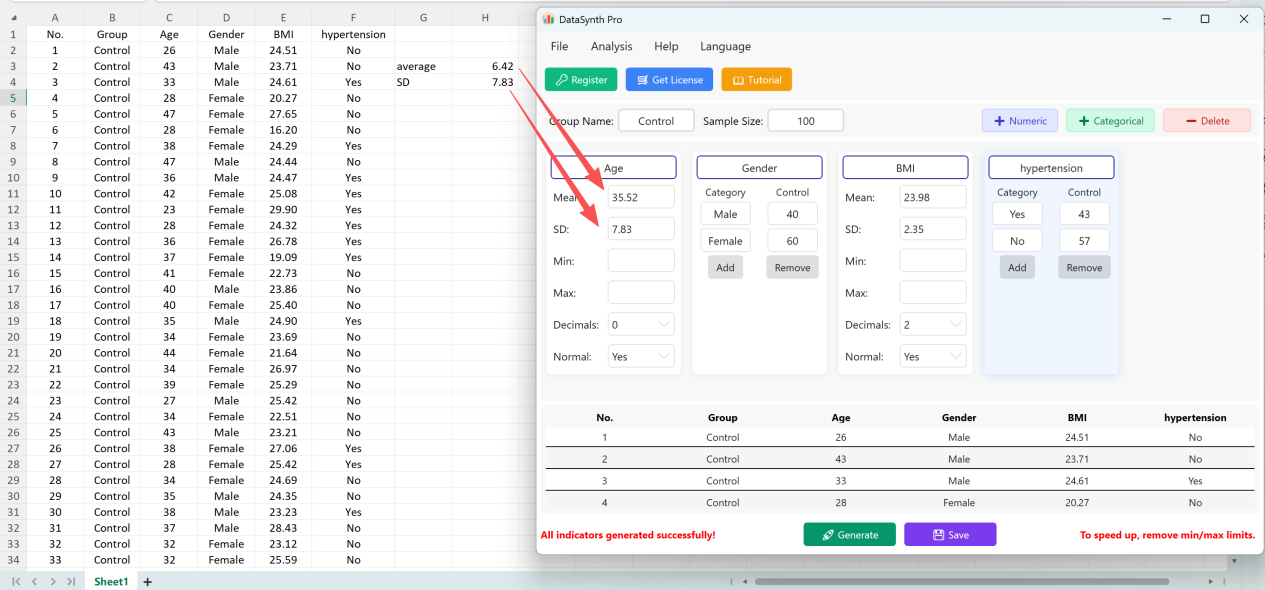
Abbildung 1.8: Verifikationsergebnisse identisch mit den Starteinstellungen
1.6 Rechenleistung
Ausgestattet mit einer leistungsstarken Optimierungs-Engine kann die Software Datensätze mit Tausenden oder Zehntausenden von Einträgen in Sekundenschnelle generieren. Wenn das System nach maximalen Iterationen keine Konvergenz erreicht, überprüfen Sie bitte die statistische Plausibilität Ihrer Konfiguration oder versuchen Sie, die Abfrage ohne Min/Max-Grenzen auszuführen. Das Programm unterstützt eine Dezimalpräzision von bis zu 8 Stellen, um speziellen wissenschaftlichen Anforderungen gerecht zu werden.
Tipps & Empfehlungen:
• Präferenz für Normalverteilung: Daten werden standardmäßig normalverteilt generiert, um nachfolgende Analysen (z. B. t-Tests für unabhängige Stichproben) nahtlos zu ermöglichen. Wenn Sie nichtparametrische oder benutzerdefinierte Datenverteilungen bevorzugen, stellen Sie Normal Distribution einfach auf No.
2. T-Test für unabhängige Stichproben
Entwickelt für Querschnittsstudien zum Vergleich der Mittelwerte zweier unabhängiger Gruppen. Häufig verwendet in klinischen Studien (z. B. Vergleich der Arzneimittelwirkung zwischen Behandlungs- und Placebogruppe) und soziologischen Erhebungen.
2.1 Arbeitsablauf
Navigieren Sie zu Analyze → Independent T-Test. Das Konfigurationsfenster wird wie folgt angezeigt:
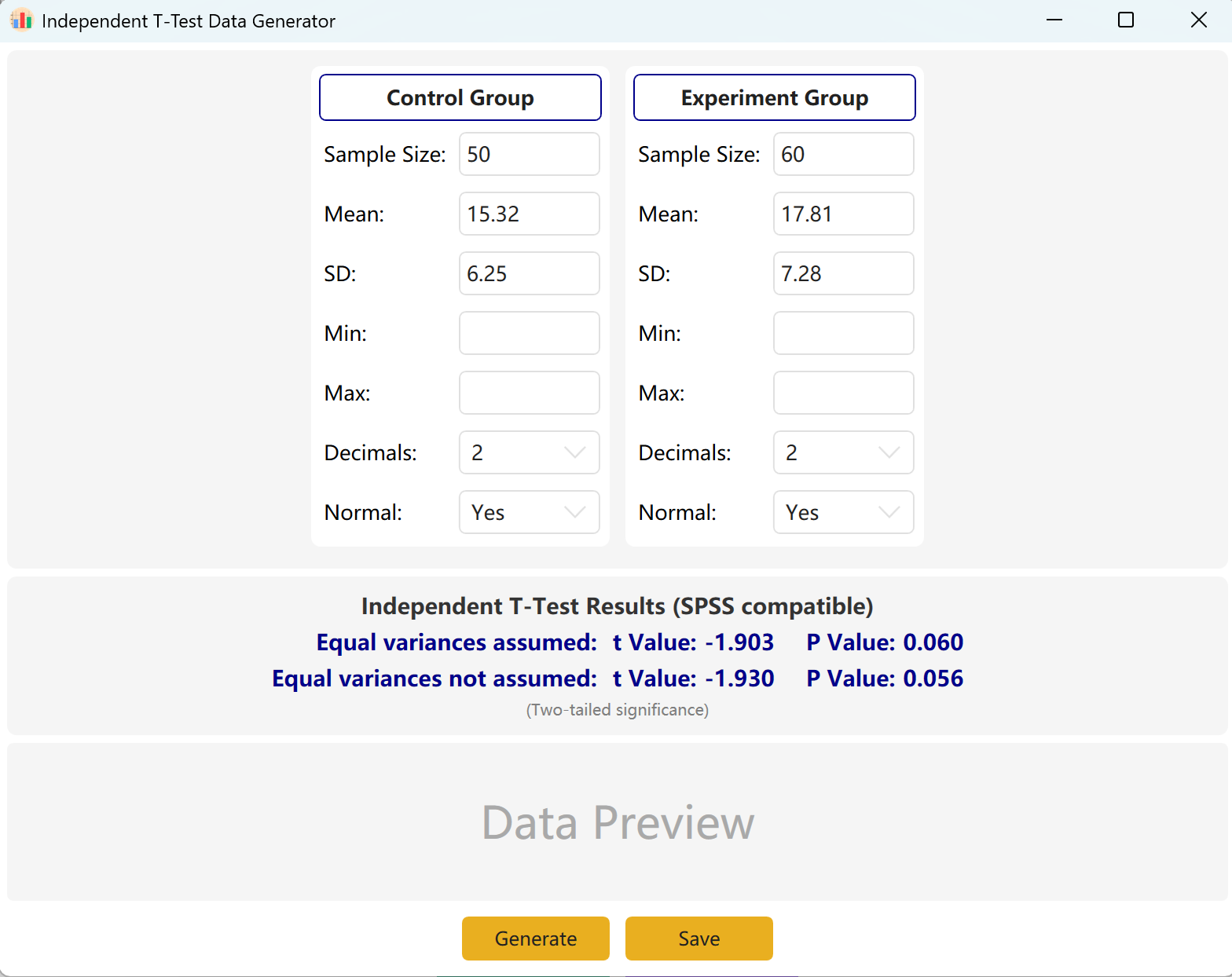
Abbildung 2.1: Benutzeroberfläche / Bedienung für unabhängigen T-Test
2.2 Parameter
Das Programm lädt standardmäßig beispielhafte Setups für eine Kontrollgruppe („Control Group“) und eine Experimentalgruppe („Experimental Group“) vor. Geben Sie Stichprobenumfang, Mittelwert und Standardabweichung für jede Gruppe ein, um den berechneten t-Wert und p-Wert in Echtzeit anzuzeigen. Min- und Max-Parameter sind optional.
Durch Klicken auf die Schaltfläche Generate werden Rohdaten für beide Gruppen in der Vorschautabelle generiert, und die endgültigen t- und p-Werte passen sich an die tatsächlich generierten Daten an (unter Verwendung des Levene-Tests auf Varianzhomogenität).
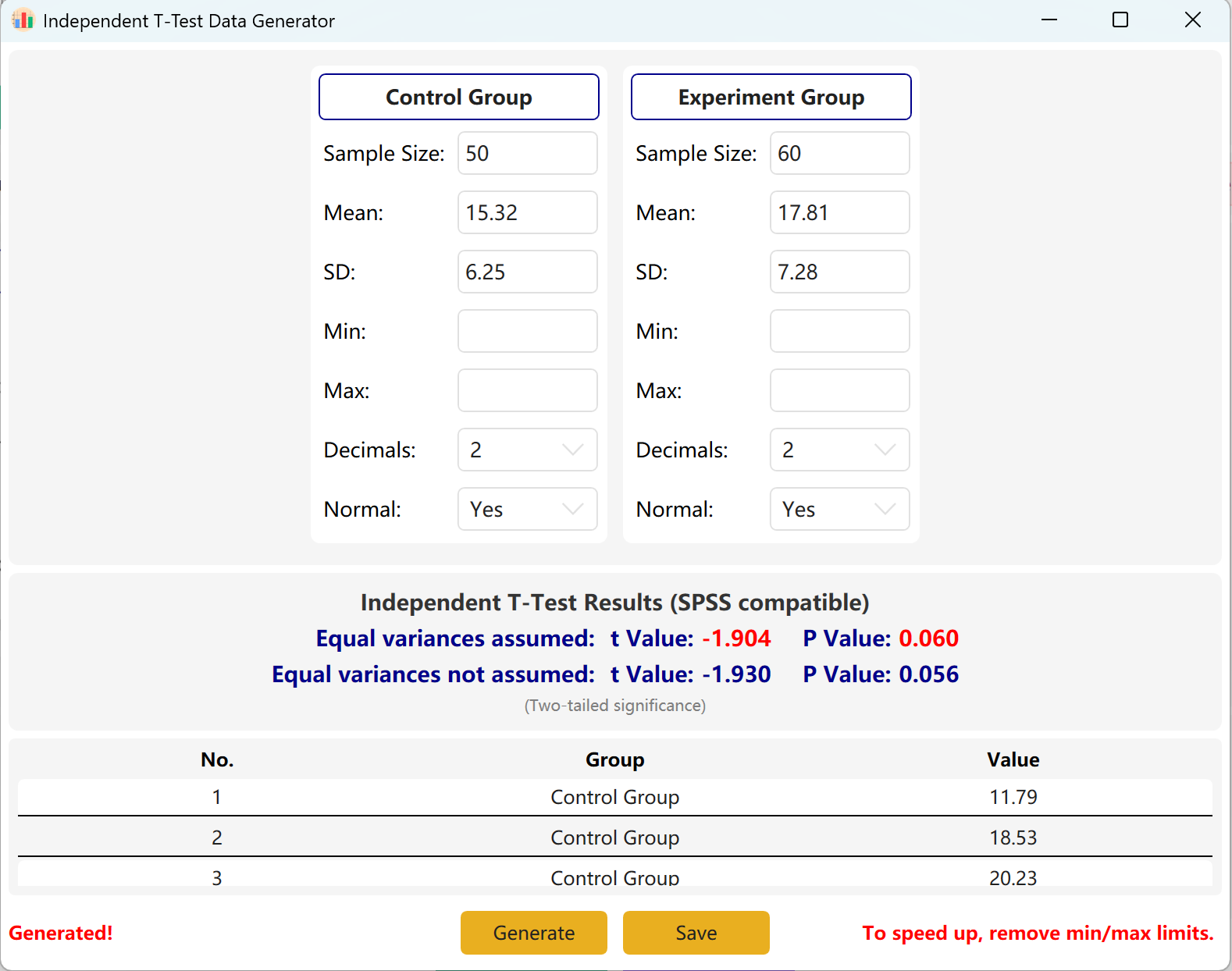
Abbildung 2.2: Benutzeroberfläche / Datenanzeige für den T-Test unabhängiger Stichproben
3. T-Test für gepaarte Stichproben
Wird für Längsschnitt- oder Crossover-Studien verwendet, bei denen dieselben Probanden zweimal gemessen werden (z. B. Pre-Test vs. Post-Test). Der Fokus liegt auf der Synthese der mittleren Differenz zwischen gepaarten Beobachtungen.
3.1 Arbeitsablauf
Navigieren Sie zu Analyze → Paired T-Test. Das Layout des Arbeitsbereichs sieht wie folgt aus:
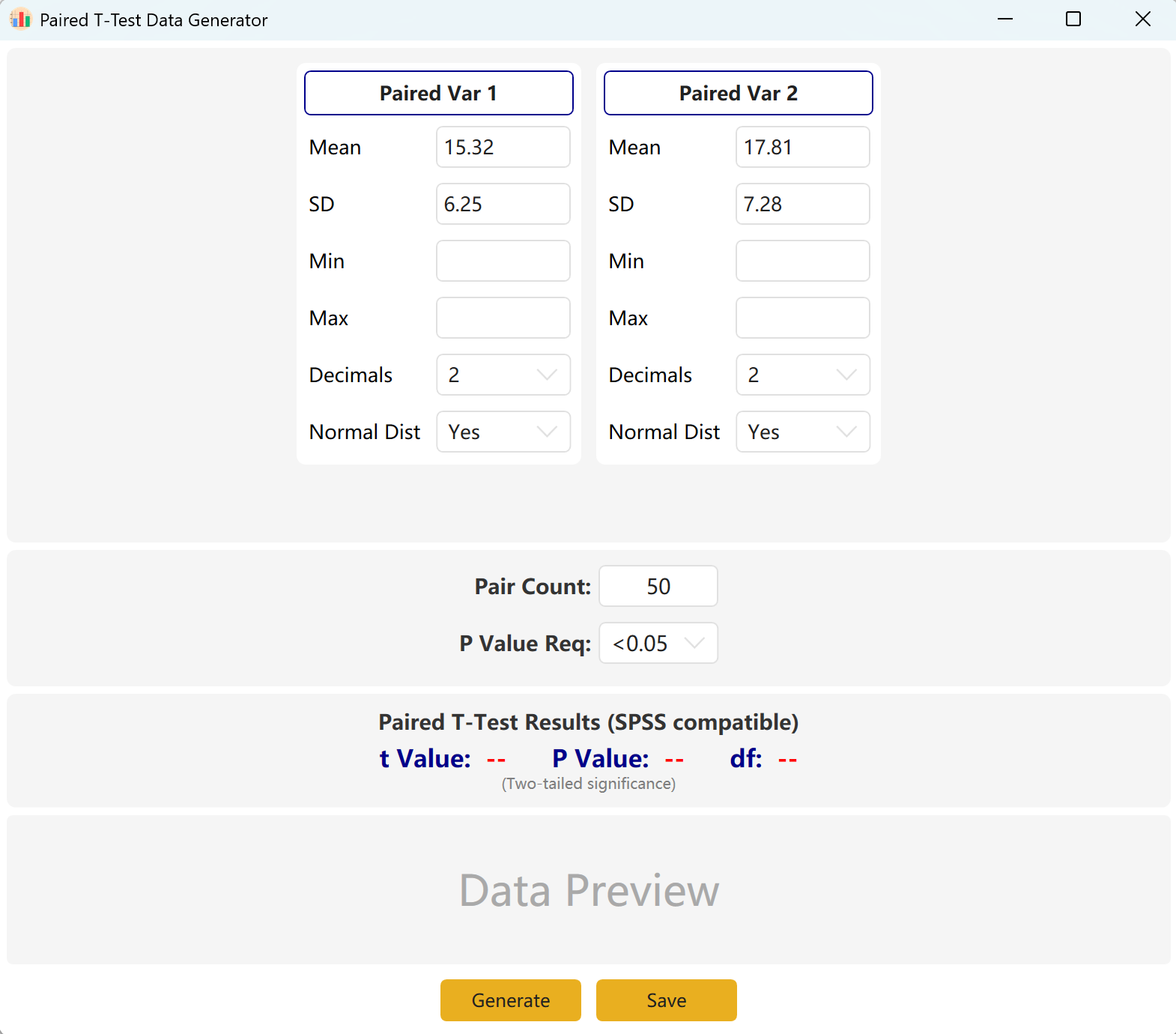
Abbildung 3.1: Benutzeroberfläche / Bedienung für gepaarten T-Test
3.2 Simulationslogik
Die Software schlägt standardmäßig zwei gepaarte Variablen vor: Paired Var1 und Paired Var2. Sie können den Mittelwert und die Standardabweichung für jede Variable definieren, den Gesamtstichprobenumfang festlegen und einen Ziel-p-Wertbereich für den gepaarten t-Test bestimmen. Die Engine berechnet iterativ einen passenden Datensatz.
Konvergenzanpassung: Wenn die konfigurierten Mittelwerte mathematisch nicht mit dem angestrebten p-Wert vereinbar sind (z. B. wenn sich die beiden Mittelwerte stark unterscheiden, Sie aber ein nicht signifikantes p > 0,05 anfordern), hält das Programm die Parameter der ersten Gruppe konstant und passt den Mittelwert der zweiten Gruppe dynamisch an, um den Ziel-p-Wert zu erreichen.
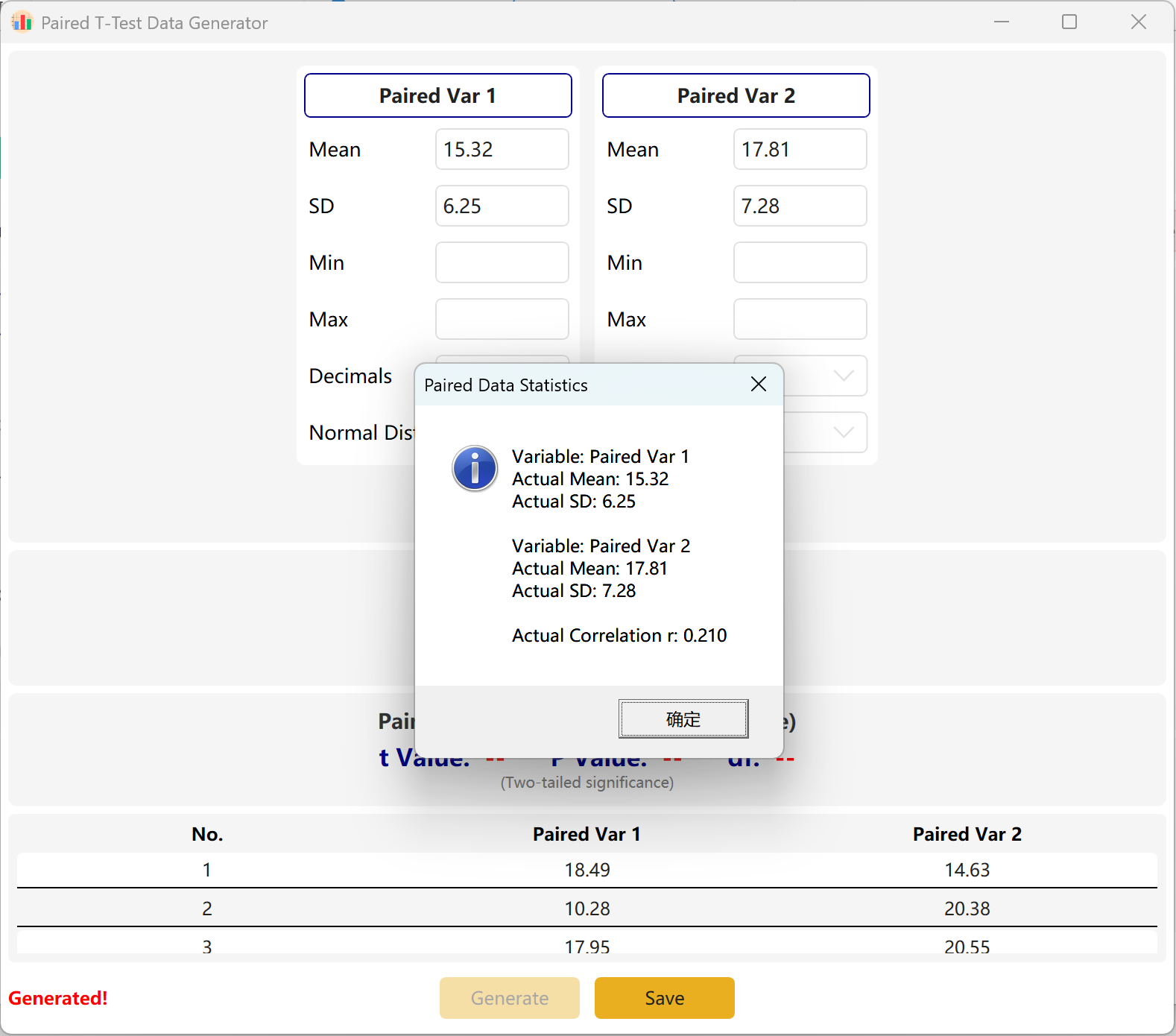
Abbildung 3.2: Benutzeroberfläche / Datenanzeige für den gepaarten T-Test
4. Chi-Quadrat-Test
Bestimmt, ob ein signifikanter Zusammenhang zwischen zwei kategorialen Variablen besteht. Häufig verwendet für demografische Kreuztabellen.
4.1 Arbeitsablauf
Navigieren Sie zu Analyze → Chi-Square Test. Das Konfigurationsfenster öffnet sich wie folgt:
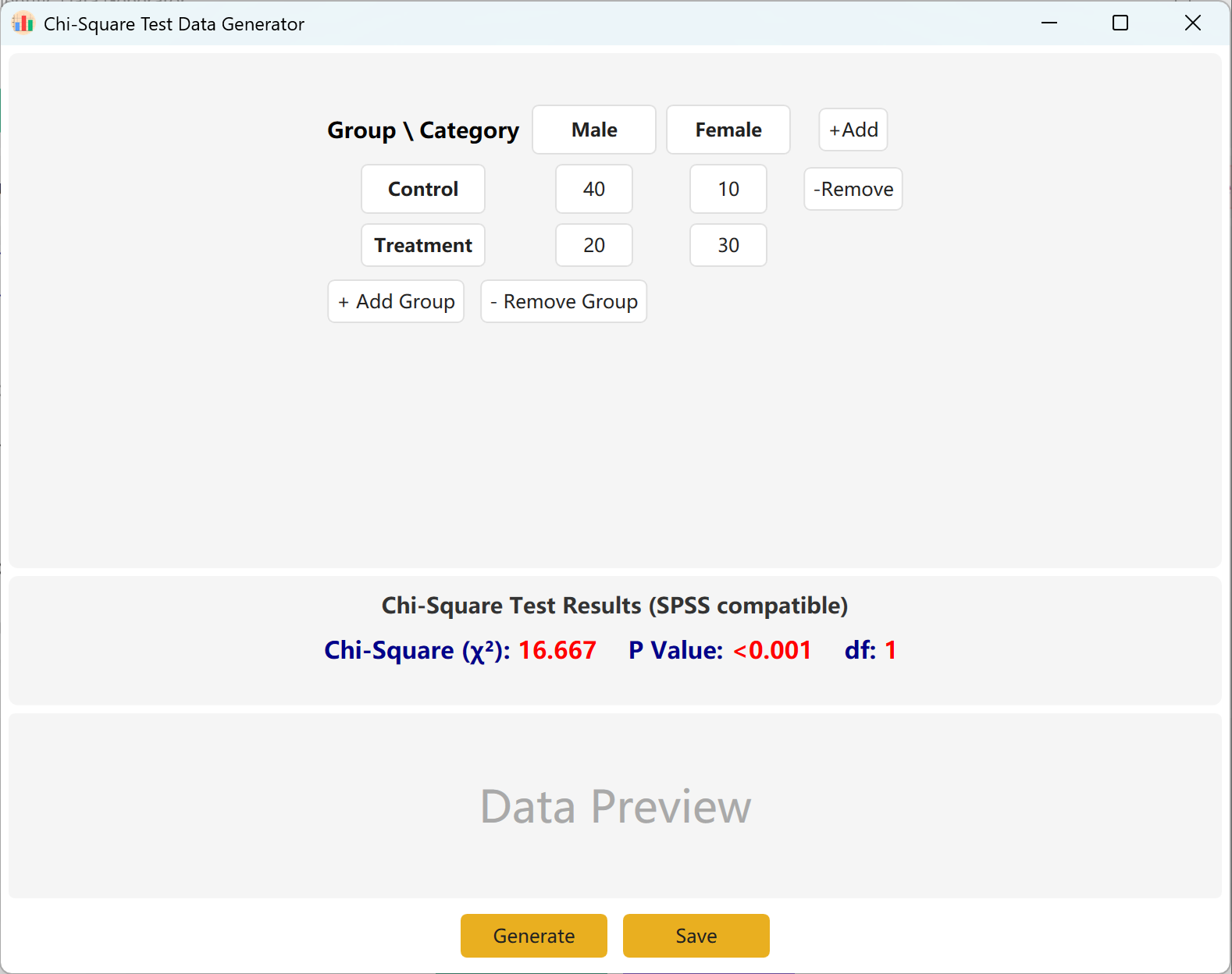
Abbildung 4.1: Benutzeroberfläche / Bedienung für den Chi-Quadrat-Test
4.2 Kontingenzmatrix
Die Oberfläche zeigt standardmäßig eine 2x2-Kontingenztabelle für die Chi-Quadrat-Berechnungen. Die Gruppen- und Kategorienamen sind frei editierbar. Tragen Sie die beobachteten Häufigkeiten (Häufigkeiten) für jede Zelle ein, und der berechnete Chi-Quadrat-Wert sowie der p-Wert werden in Echtzeit aktualisiert.
Sie können dynamisch Gruppen (Zeilen) oder Kategorien (Spalten) hinzufügen, um größere Modelle abzubilden. Klicken Sie auf Generate, um Rohdatensätze zu erstellen, die diesen Häufigkeiten entsprechen, und auf Save, um das Ergebnis nach Excel zu exportieren.
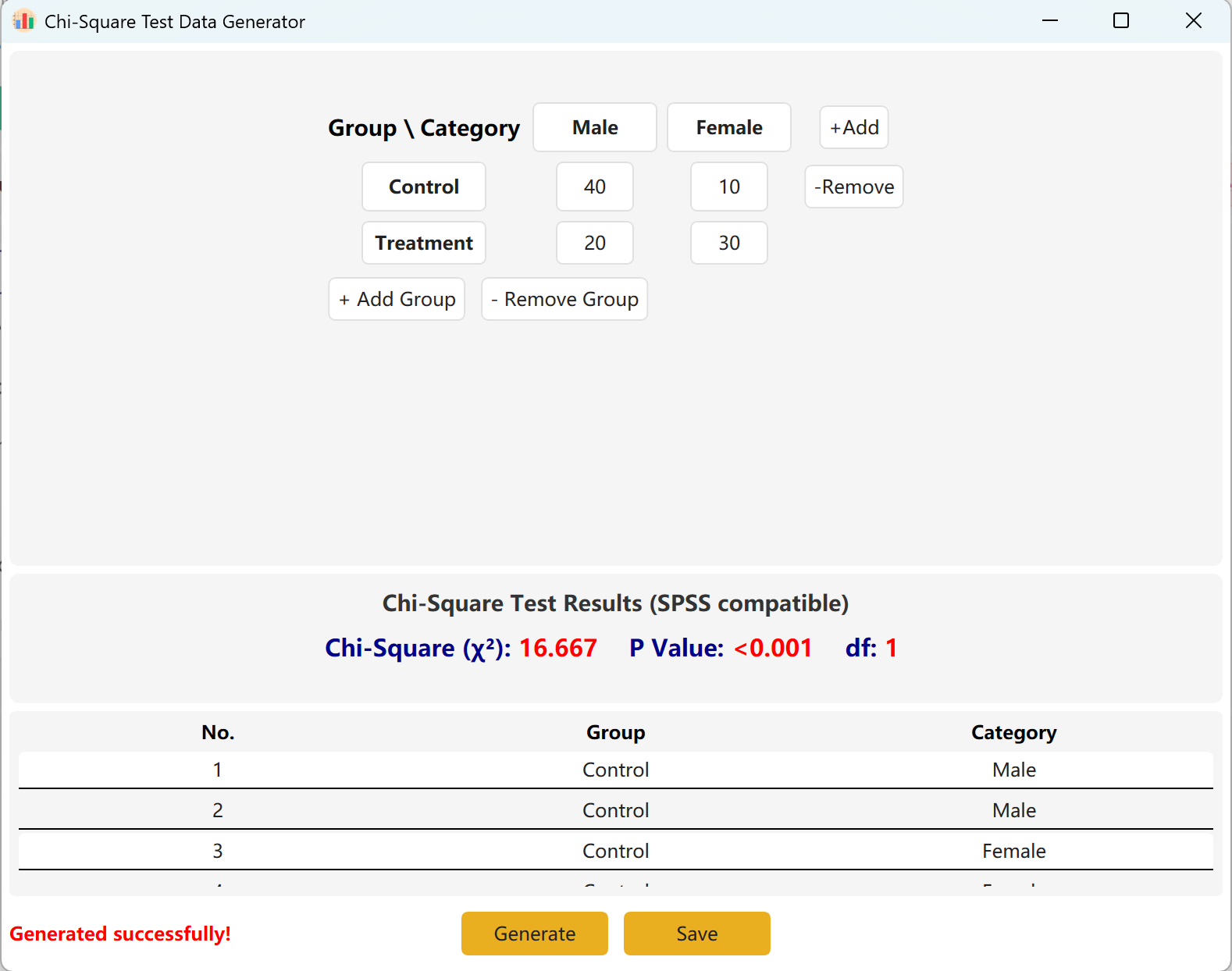
Abbildung 4.2: Benutzeroberfläche / Datenanzeige für den Chi-Quadrat-Test
5. Einfaktorielle ANOVA (Varianzanalyse)
Wird verwendet, um die Mittelwerte von drei oder mehr unabhängigen Gruppen zu vergleichen. Der Algorithmus synthetisiert die Varianz innerhalb der Gruppen und die Unterschiede zwischen den Gruppen, um die Ziel-F-Werte zu erreichen.
5.1 Arbeitsablauf
Navigieren Sie zu Analyze → ANOVA → One-Way ANOVA. Das Layout des Arbeitsbereichs sieht wie folgt aus:
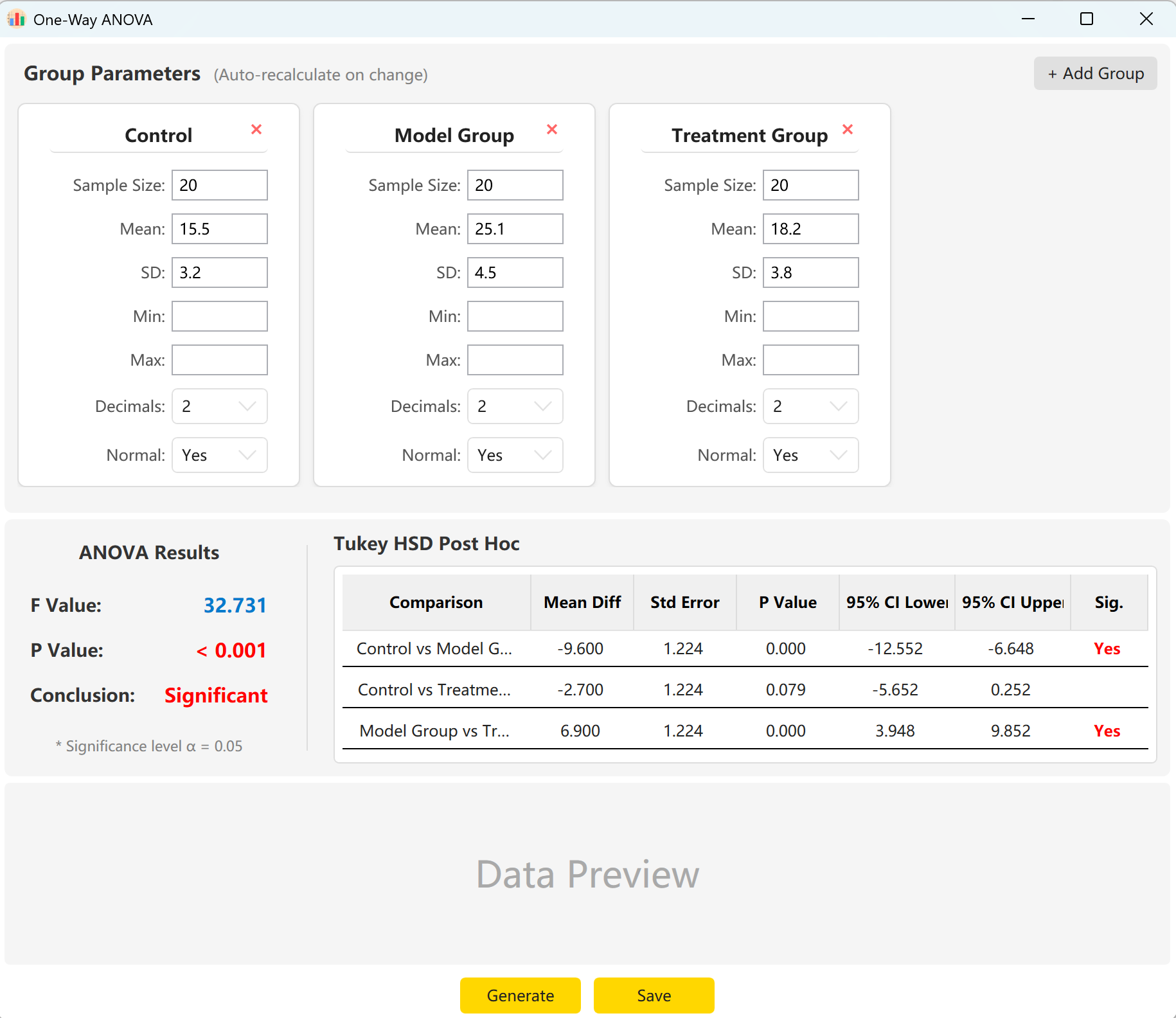
Abbildung 5.1: Benutzeroberfläche / Bedienung für einfaktorielle ANOVA
5.2 Konfiguration
Das System lädt Parameter für drei Gruppen vor: „Control Group“ (Kontrollgruppe), „Experimental Group“ (Experimentalgruppe) und „Treatment Group“ (Behandlungsgruppe). Geben Sie einfach den Stichprobenumfang, den Mittelwert und die Standardabweichung für jede Gruppe ein, um sofort die F-Statistik, den p-Wert und die Tukey-HSD-Post-hoc-Mehrfachvergleiche anzuzeigen.
Klicken Sie auf die Schaltfläche Generate, um die entsprechenden Rohdaten zu erstellen. Der F-Wert und der p-Wert in der Statistikübersicht passen sich automatisch an die tatsächlich generierten Werte an.
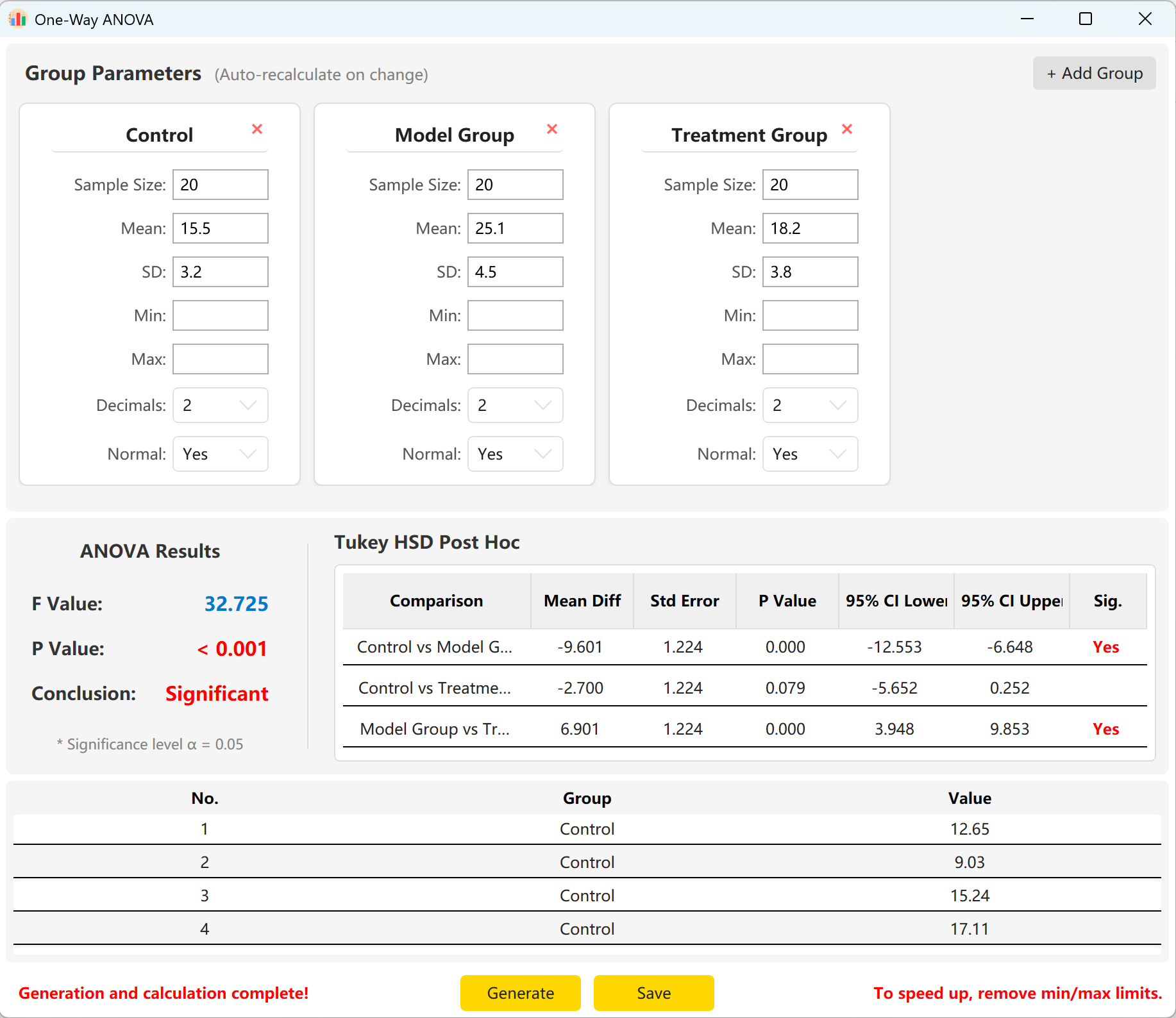
Abbildung 5.2: Benutzeroberfläche / Datenanzeige für einfaktorielle ANOVA
6. Zweifaktorielle ANOVA
Untersucht den Einfluss zweier unabhängiger kategorialer Variablen auf eine kontinuierliche abhängige Variable. Unerlässlich für faktorielle Versuchspläne zur Bewertung von Haupteffekten und Interaktionseffekten.
6.1 Arbeitsablauf
Navigieren Sie zu Analyze → ANOVA → Two-Way ANOVA. Das Konfigurationsfenster wird unten dargestellt:
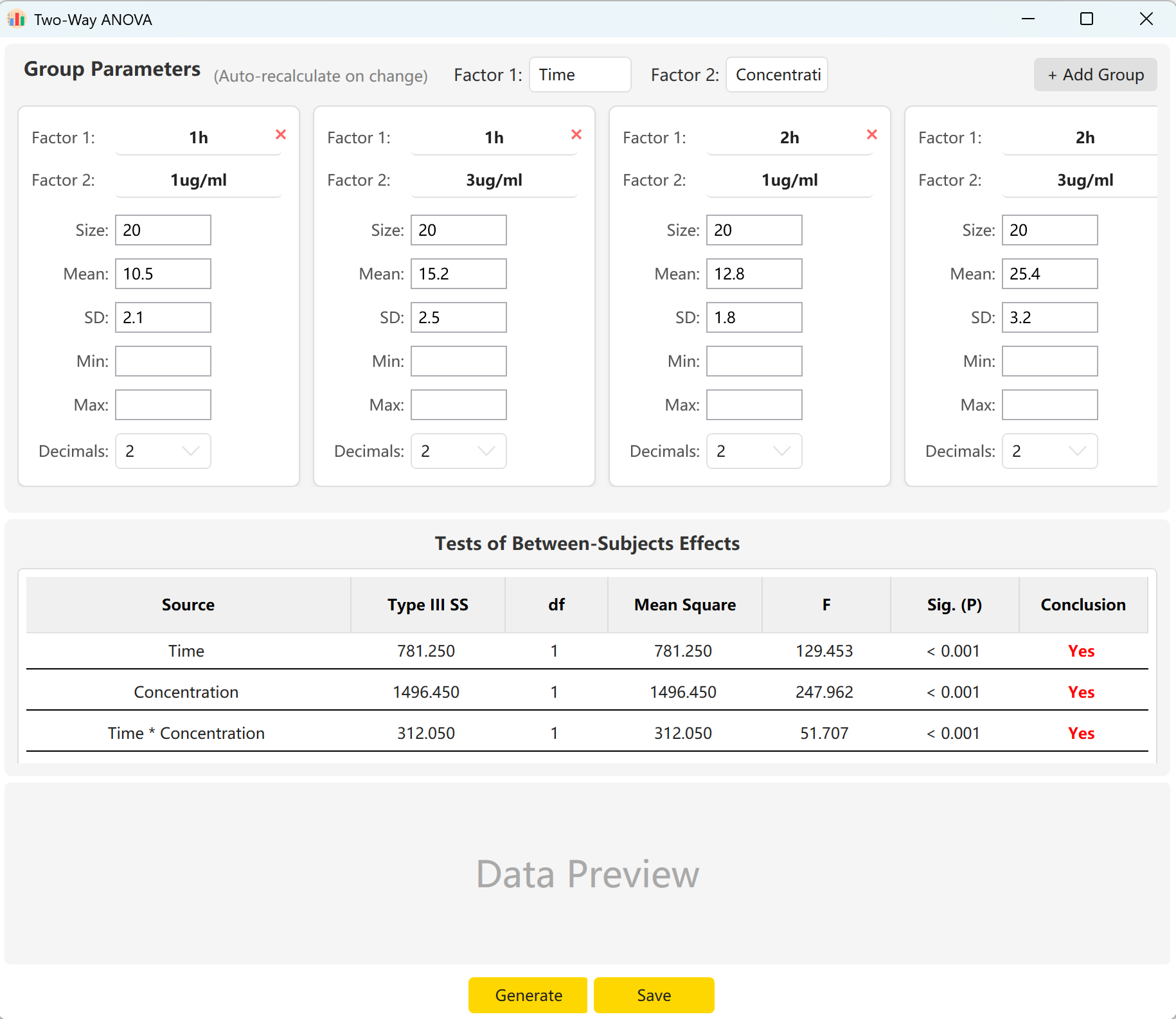
Abbildung 6.1: Benutzeroberfläche / Bedienung für zweifaktorielle ANOVA
6.2 Faktoren & Interaktionen
Die Anwendung schlägt standardmäßig zwei Faktoren vor: „Time“ (Zeit - 2 Stufen) und „Concentration“ (Konzentration - 2 Stufen). Klicken Sie auf Add Group, um weitere Stufen hinzuzufügen, falls ein Faktor mehrere Ausprägungen besitzt.
Indem Sie Stichprobenumfang, Mittelwert und Standardabweichung für jede Zelle eintragen, erhalten Sie eine Vorschau auf die F-Statistiken und p-Werte des Haupteffekts von Time, des Haupteffekts von Concentration sowie des Interaktionseffekts (Time × Concentration). Klicken Sie auf Generate, um die entsprechenden Rohdaten zu erstellen.
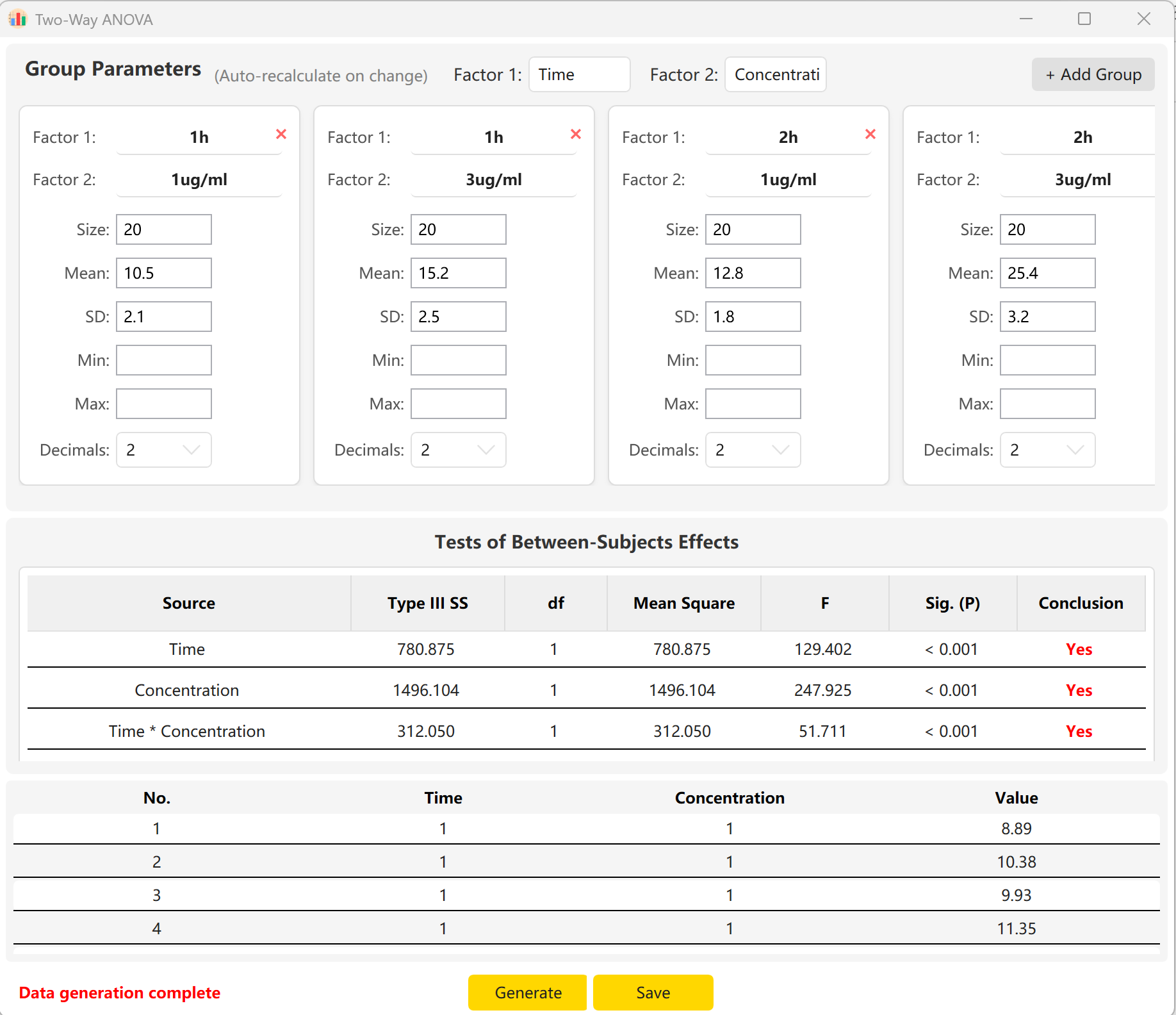
Abbildung 6.2: Benutzeroberfläche / Datenanzeige für zweifaktorielle ANOVA
7. Einfaktorielle ANOVA mit Messwiederholung
Die Erweiterung des gepaarten T-Tests auf drei oder mehr Messzeitpunkte. Ideal zur Nachverfolgung von Längsschnittdaten über längere Zeiträume (z. B. Baseline, Monat 1, Monat 3).
7.1 Arbeitsablauf
Navigieren Sie zu Analyze → ANOVA → Repeated Measures ANOVA. Das Layout des Arbeitsbereichs sieht wie folgt aus:
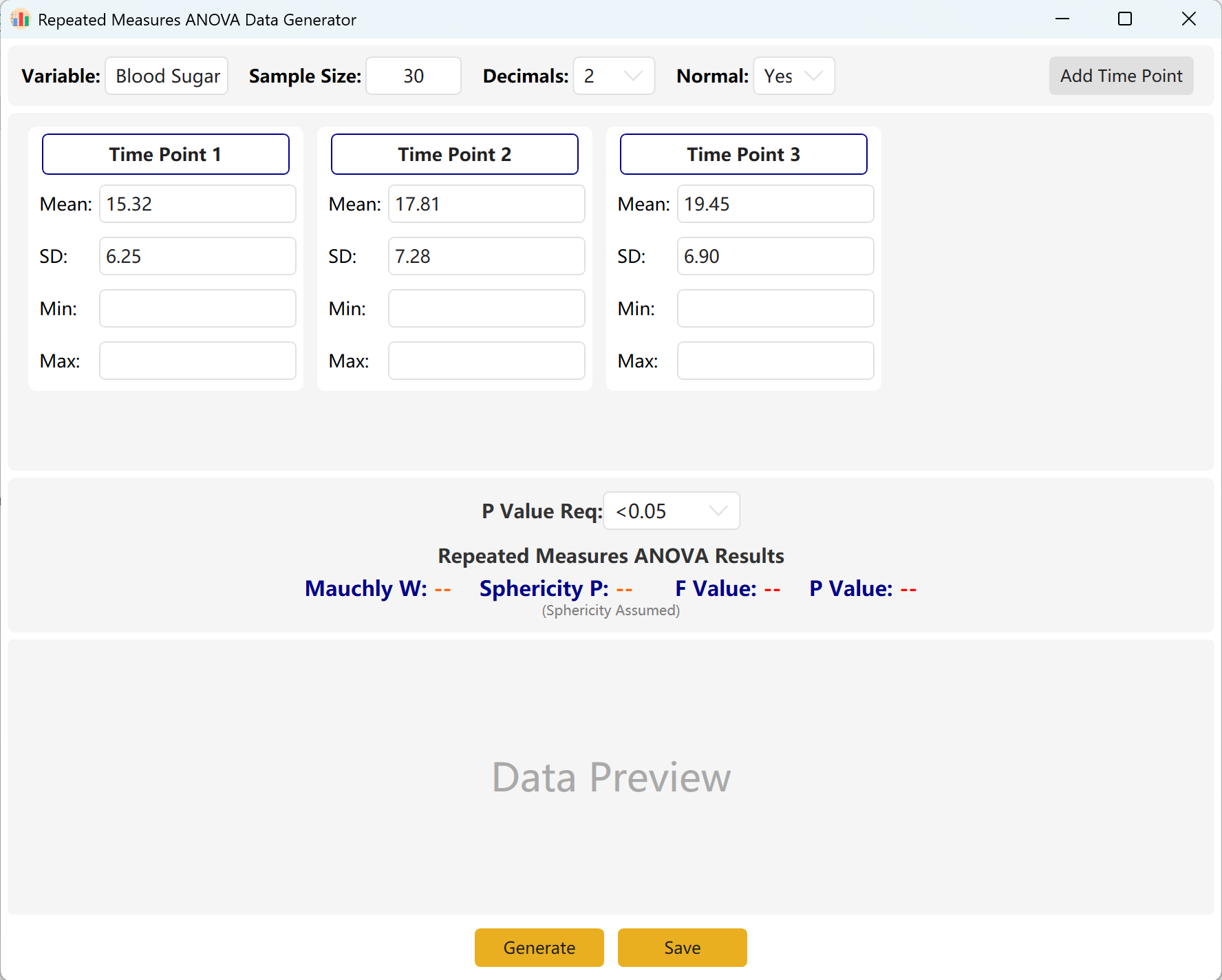
Abbildung 7.1: Benutzeroberfläche / Bedienung für ANOVA mit Messwiederholung
7.2 Wiederholte Messungen
Das System schlägt standardmäßig drei Messzeitpunkte vor. Sie können weitere hinzufügen, indem Sie auf die Schaltfläche Add Time Point klicken. Geben Sie Mittelwert und Standardabweichung für jeden Zeitpunkt ein und definieren Sie Ihren Ziel-p-Wertbereich.
Klicken Sie auf Generate, um konforme Werte zu simulieren.
Stauchung durch die Engine: Wenn der Unterschied zwischen den Zeitpunkten mathematisch sehr groß ist (was natürlicherweise zu einem hochsignifikanten p-Wert führt), Ihr Zielbereich jedoch auf p > 0,05 eingestellt ist, komprimiert die Engine automatisch die Varianzen und Mittelwertdifferenzen zwischen den Zeitpunkten, um Ihren Ziel-p-Wert exakt zu treffen. Ein Pop-up-Dialog zeigt die tatsächlichen Statistiken des generierten Datensatzes an.
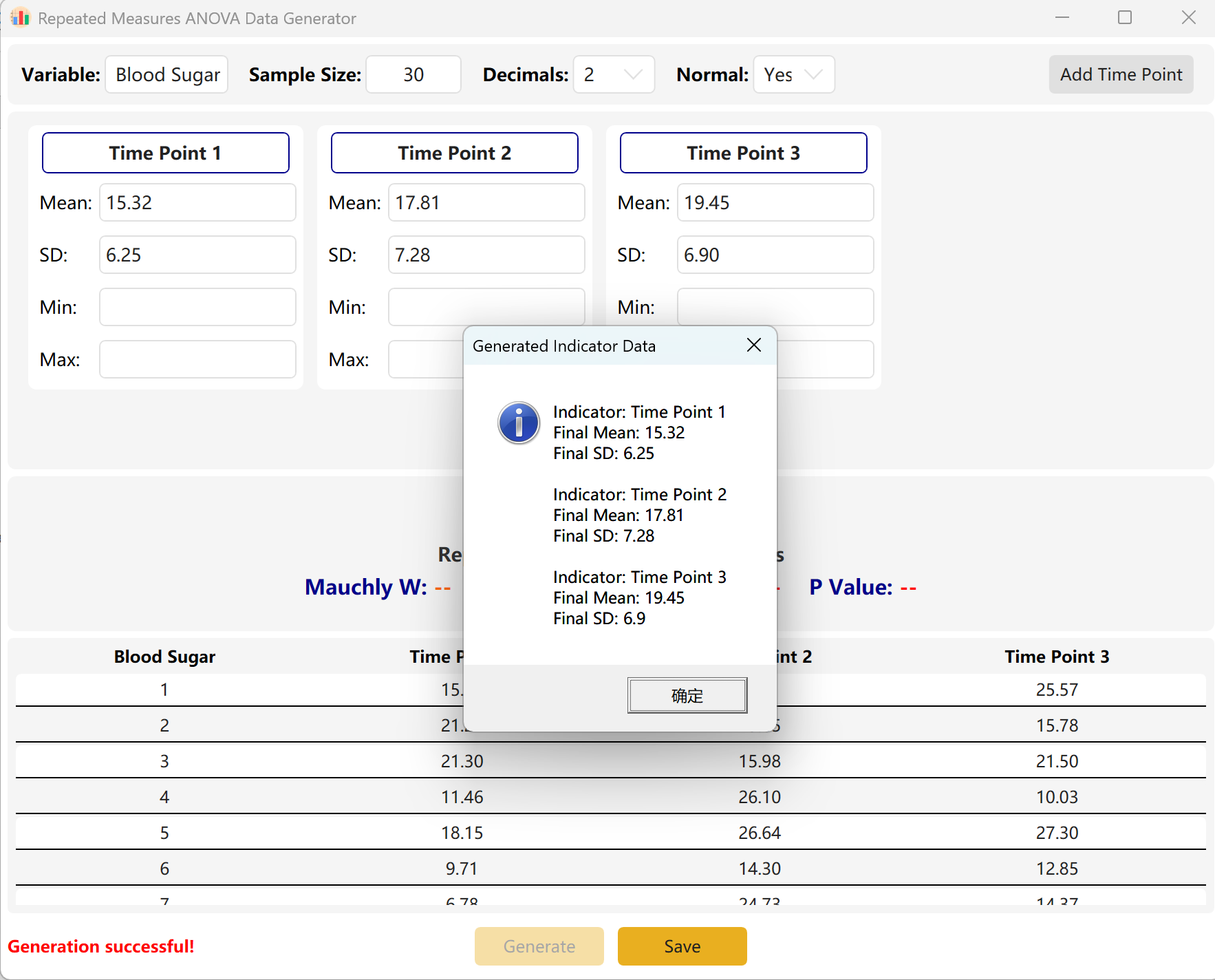
Abbildung 7.2: Benutzeroberfläche / Datenanzeige für ANOVA mit Messwiederholung
8. Rangsummentest für zwei unabhängige Stichproben (Nichtparametrisch)
Mann-Whitney-U-Test-Alternative für Daten, die die Normalverteilungsannahme verletzen. Bewertet Median-Unterschiede basierend auf Rangordnungslogik bei kontinuierlichen oder ordinalen Variablen.
8.1 Arbeitsablauf
Navigieren Sie zu Analyze → Non-parametric → 2 Independent Samples. Die Konfigurationsoberfläche wird unten gezeigt:
1.png)
Abbildung 8.1: Benutzeroberfläche / Bedienung für den Rangsummentest zweier unabhängiger Stichproben
8.2 Einrichtung
Das Programm schlägt standardmäßig zwei Referenzgruppen vor. Da nichtparametrische Methoden für nicht normalverteilte Daten gedacht sind, ist die Option Normal Distribution standardmäßig auf No eingestellt. Sie können einen Ziel-p-Wertbereich für den Mann-Whitney-U-Test definieren. Klicken Sie auf Generate, um Rohdaten zu simulieren, die diese Grenze statistisch einhalten.
Logik der Rangsummen-Generierung: Nichtparametrische Tests analysieren Gruppenunterschiede durch Zusammenlegen und Rangzuweisung aller Beobachtungen. Wenn die konfigurierten Parameter der beiden Gruppen stark voneinander abweichen (was einen sehr kleinen p-Wert erzeugt), Sie aber p > 0,05 anfordern, reduziert die Engine die Abweichungen zwischen den Gruppen automatisch, um das Ziel zu erfüllen. Die tatsächlichen Werte werden in einem Dialog ausgegeben.
2.png)
Abbildung 8.2: Benutzeroberfläche / Datenanzeige für den Rangsummentest zweier unabhängiger Stichproben
9. Kruskal-Wallis-Test (K unabhängige Stichproben, Nichtparametrisch)
Entspricht dem Kruskal-Wallis-H-Test. Generiert ordinale oder nicht normalverteilte kontinuierliche Daten für drei oder mehr unabhängige Gruppen.
9.1 Arbeitsablauf
Navigieren Sie zu Analyze → Non-parametric → K Independent Samples. Die Konfigurationsoberfläche wird unten gezeigt:
1.png)
Abbildung 9.1: Benutzeroberfläche / Bedienung für den Kruskal-Wallis-Test
9.2 Mehrgruppen-Rangverfahren
Das Programm sieht standardmäßig drei Referenzgruppen vor und führt einen Kruskal-Wallis-Test durch. Genau wie beim Zwei-Gruppen-Test: Da die Berechnungen auf Rängen über den gesamten gepoolten Datensatz basieren, passt die Engine bei zu großen Unterschieden (sehr kleinen p-Werten) und einer Zielvorgabe von z. B. p > 0,05 die Gruppenwerte an. Die resultierenden Statistiken werden im Dialog zusammengefasst.
2.png)
Abbildung 9.2: Benutzeroberfläche / Datenanzeige für den Kruskal-Wallis-Test
10. Quartilsdaten generieren
Teilt einen sortierten Datensatz in vier gleiche Teile auf. Nützlich zur Bestimmung der Datenstreuung und der zentralen Tendenz, zur Ermittlung des Medians und zum Erkennen von Ausreißern.
10.1 Arbeitsablauf
Navigieren Sie zu Analyze → Quartile Data. Das Layout ist unten dargestellt:
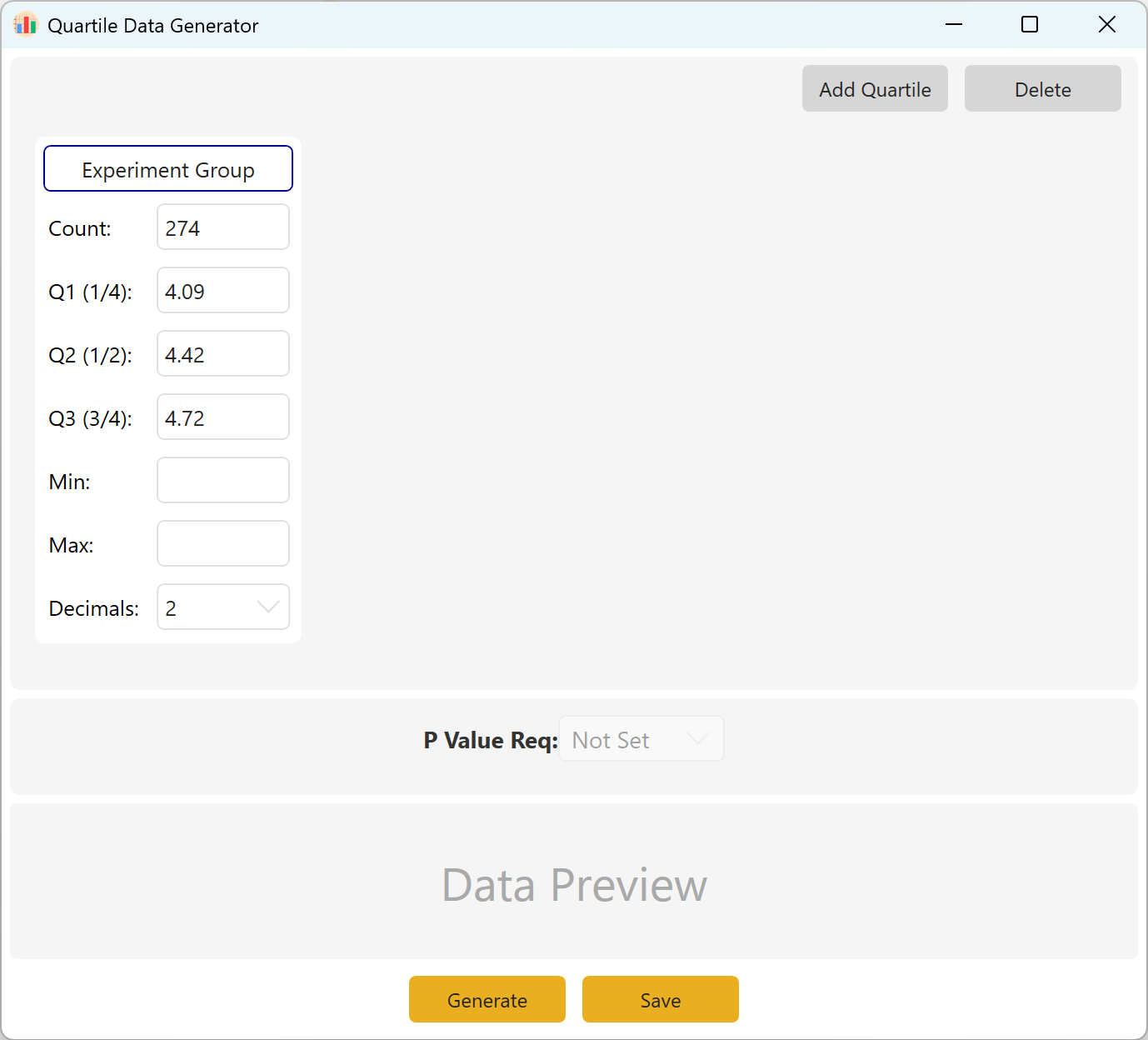
Abbildung 10.1: Benutzeroberfläche / Bedienung für Quartilsdaten
10.2 Parameterdefinition
Definieren Sie Stichprobenumfang sowie die Zielwerte für Q1 (25. Perzentil), Q2 (Median / 50. Perzentil) und Q3 (75. Perzentil). Min/Max-Grenzen können frei bleiben. Wählen Sie die Dezimalpräzision und klicken Sie auf Generate, um Datensätze zu berechnen, die exakt diesen Quartilsgrenzen entsprechen.
Zusammenfassung: Konfigurieren Sie Stichprobenumfang und Zielwerte für Q1, Q2 und Q3. Optionale Parameter sind Minimum, Maximum und Dezimalstellen. Klicken Sie auf Generate, um die entsprechenden Rohdaten zu erstellen. Für Mehrgruppendesigns können Sie zusätzlich einen Ziel-p-Wertbereich festlegen.
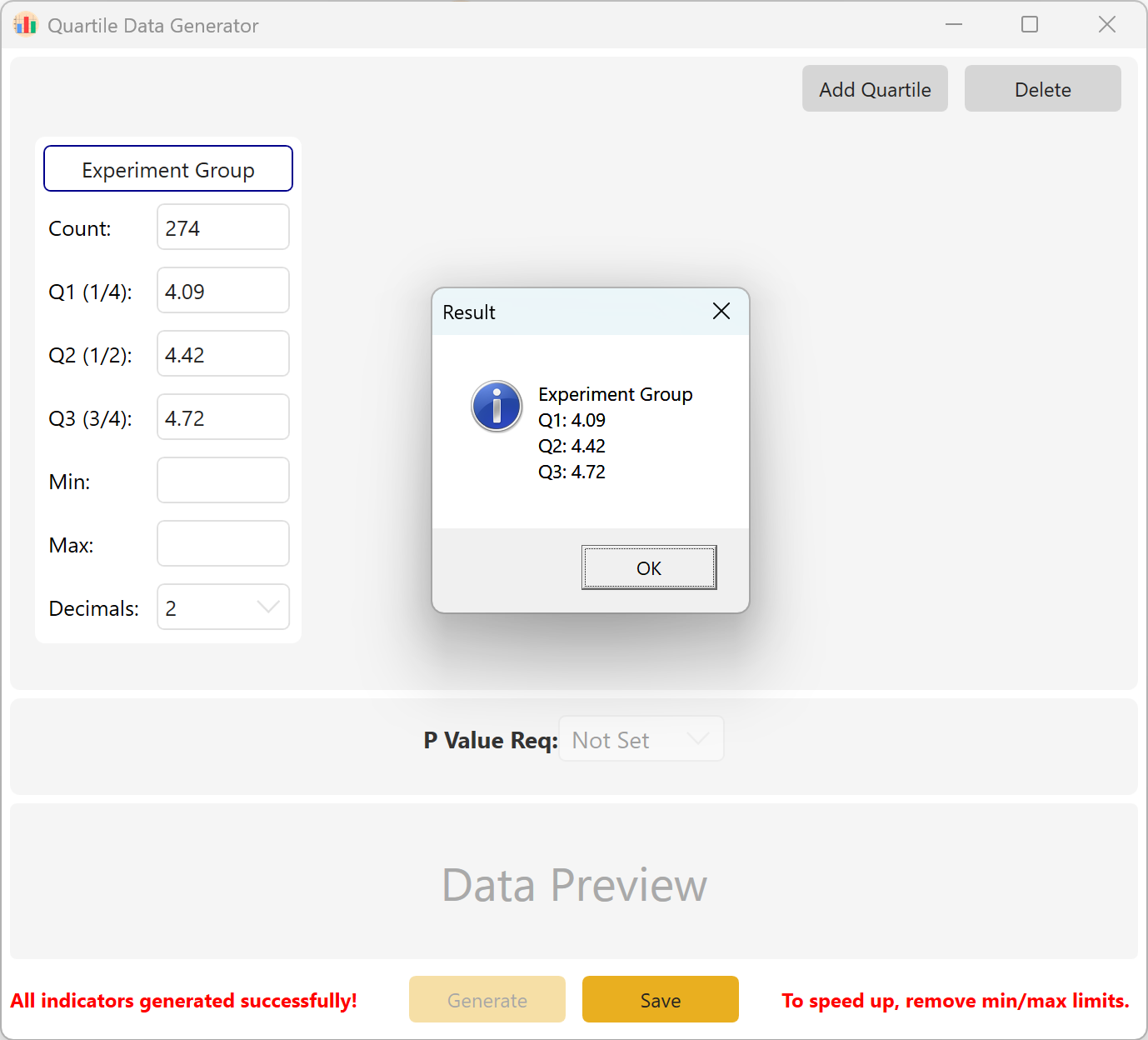
Abbildung 10.2: Benutzeroberfläche / Datenanzeige für Quartilsdaten
11. Binär-logistische Regression
Wichtig für Klassifikationsprobleme mit dichotomer Zielvariable (abhängige Variable = 0 oder 1). Weit verbreitet in der Epidemiologie zur Identifizierung von Risikofaktoren (z. B. Erkrankt vs. Gesund).
11.1 Arbeitsablauf
Navigieren Sie zu Analyze → Regression → Binary Logistic.
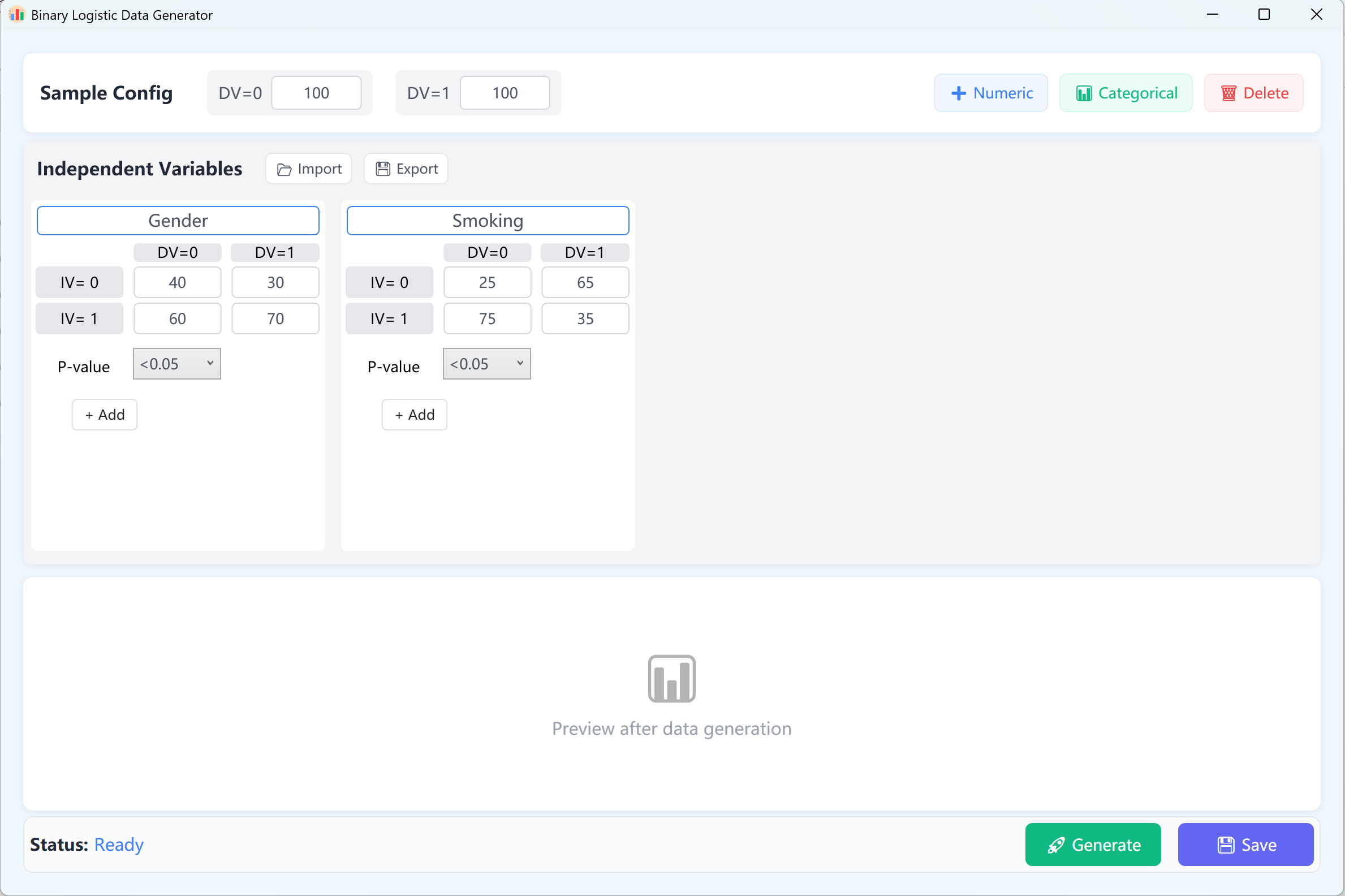
Abbildung 11.1: Benutzeroberfläche / Bedienung für binär-logistische Regression
11.2 Versuchsplanung
Standardmäßig sind zwei kontinuierliche unabhängige Variablen als Referenz hinterlegt. In einem binär-logistischen Modell hat die abhängige Variable exakt zwei Zustände (0 und 1). Dementsprechend ist sie in die Gruppen 0 und 1 unterteilt, mit einem Standard-Stichprobenumfang von 100 Fällen pro Kategorie (anpassbar).
- Variablen einrichten: Klicken Sie auf + Numeric, um kontinuierliche unabhängige Variablen hinzuzufügen (z. B. „Age“, „BMI“). Tragen Sie Name, Mittelwert, Standardabweichung, Dezimalstellen und den Ziel-p-Wertbereich ein (dieser legt fest, welches Signifikanzniveau die Variable im fertigen Regressionsmodell erreichen soll). Min/Max-Grenzen sind optional.
- Generierung & Validierung: Klicken Sie auf die Schaltfläche Generate, um die Simulation zu starten. Das System berechnet iterativ einen Datensatz, in dem die Regressionsanalyse genau die geforderten p-Werte liefert.
Ein detaillierter Regressionsbericht im typischen SPSS-Format wird automatisch geöffnet. Nach dem Schließen des Berichts können Sie die Rohdaten in der Vorschautabelle ansehen und nach Excel exportieren.
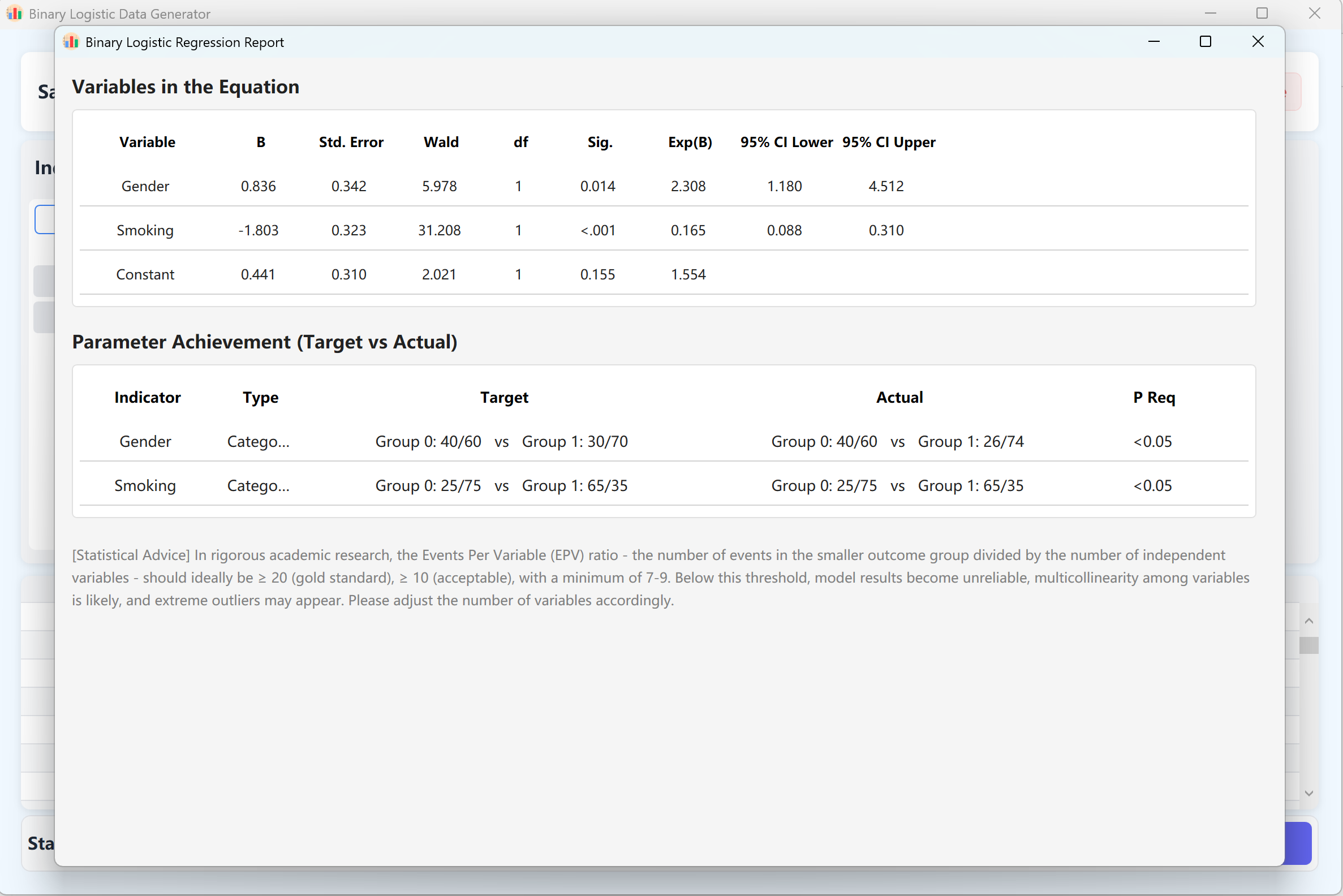
Abbildung 11.2: Benutzeroberfläche / Datenanzeige für binär-logistische Regression
12. Multiple lineare Regression
Ein grundlegendes Werkzeug der prädiktiven Modellierung. Es synthetisiert eine kontinuierliche abhängige Variable (Y), die von mehreren unabhängigen Variablen (X) beeinflusst wird, welche numerisch, quartilbasiert oder kategorial (nominal/ordinal) sein können.
12.1 Arbeitsablauf
Navigieren Sie zu Analyze → Regression → Linear Regression.
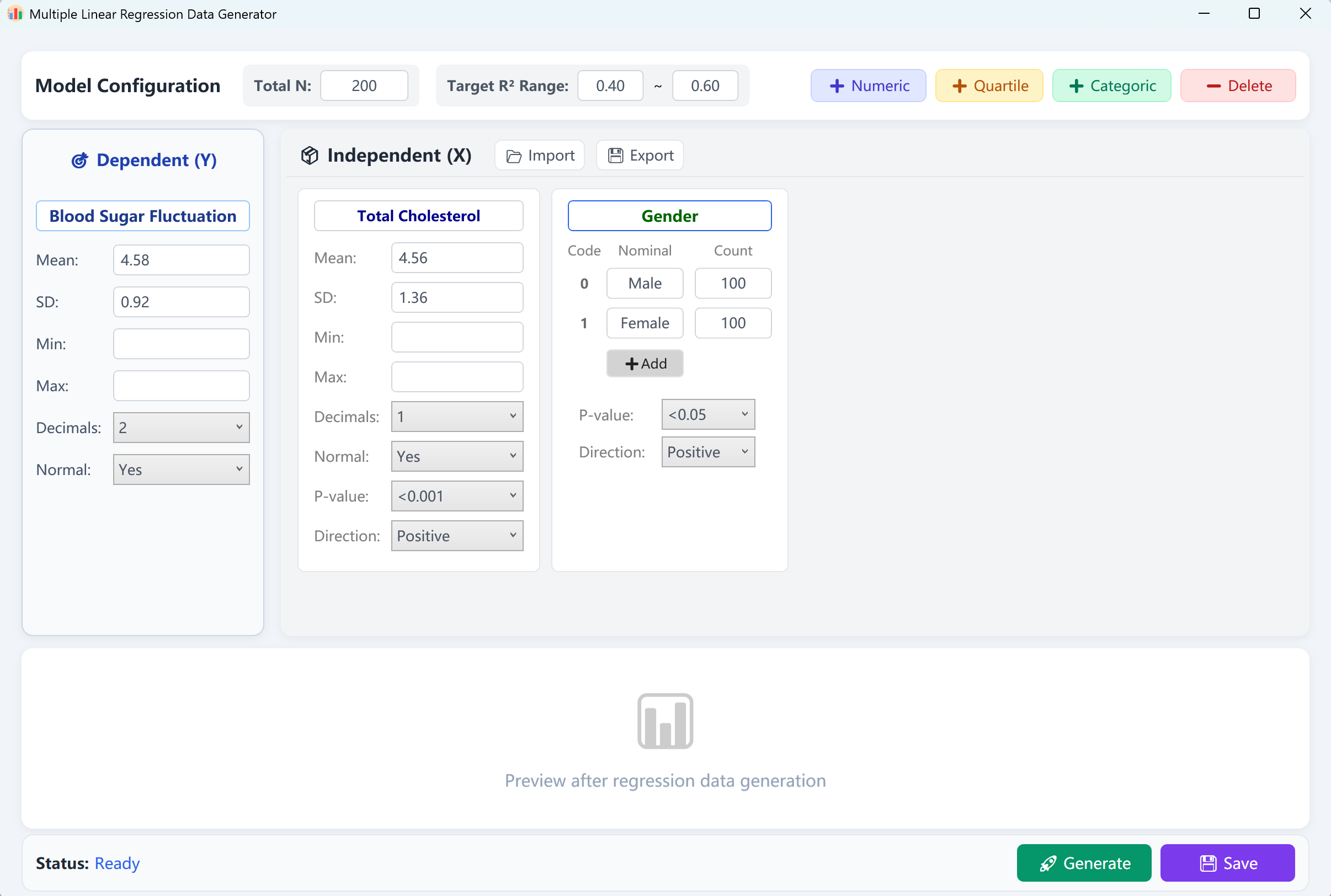
Abbildung 12.1: Benutzeroberfläche / Bedienung für multiple lineare Regression
12.2 Modelleinstellungen
Die Oberfläche lädt eine kontinuierliche abhängige Variable („Blood Glucose Fluctuation“ / Blutzuckerschwankung) und zwei unabhängige Variablen („Total Cholesterol“ als numerisch, „Gender“ als kategorial) mit einer Standardstichprobe von 200 Fällen vor. Sie können ein Ziel-Bestimmtheitsmaß (R-Quadrat / R²) vorgeben (z. B. 0,4 bis 0,6).
Klicken Sie auf Generate, um das Modell zu berechnen. Ein SPSS-konformer Validierungsbericht wird eingeblendet. Nach dem Schließen sehen Sie die Rohdaten in der Vorschautabelle.
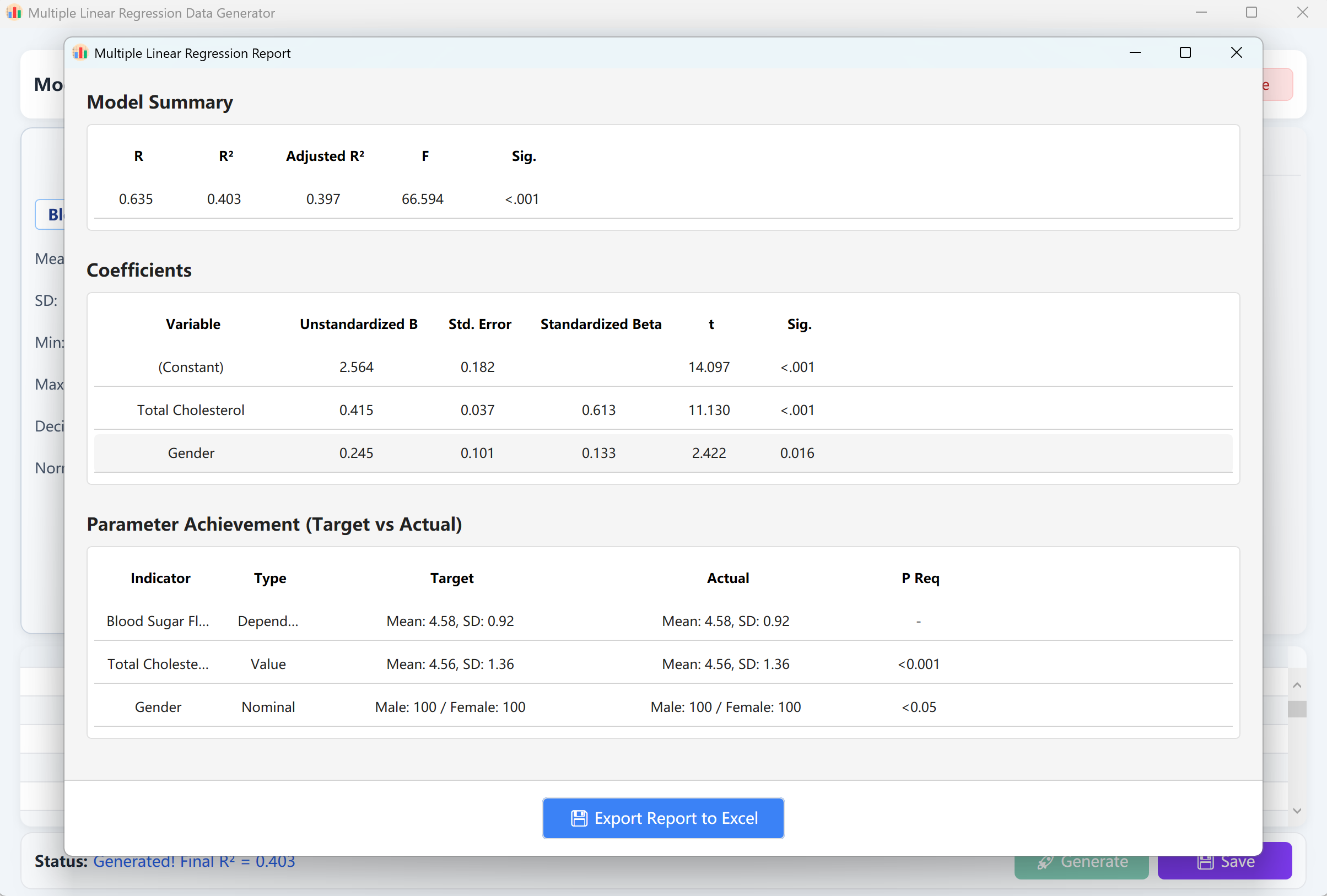
Abbildung 12.2: Benutzeroberfläche / Datenanzeige für multiple lineare Regression
13. Cox-Regressionsanalyse (Proportionale Hazards)
Der Goldstandard der Überlebenszeitanalyse. Simuliert Zeit-bis-Ereignis-Daten unter Berücksichtigung von rechtszensierten Fällen, um den Einfluss von Kovariaten auf Überlebenszeiten zu untersuchen.
13.1 Arbeitsablauf & Technische Leitlinien
Navigieren Sie zu Analyze → Regression → Cox Regression.
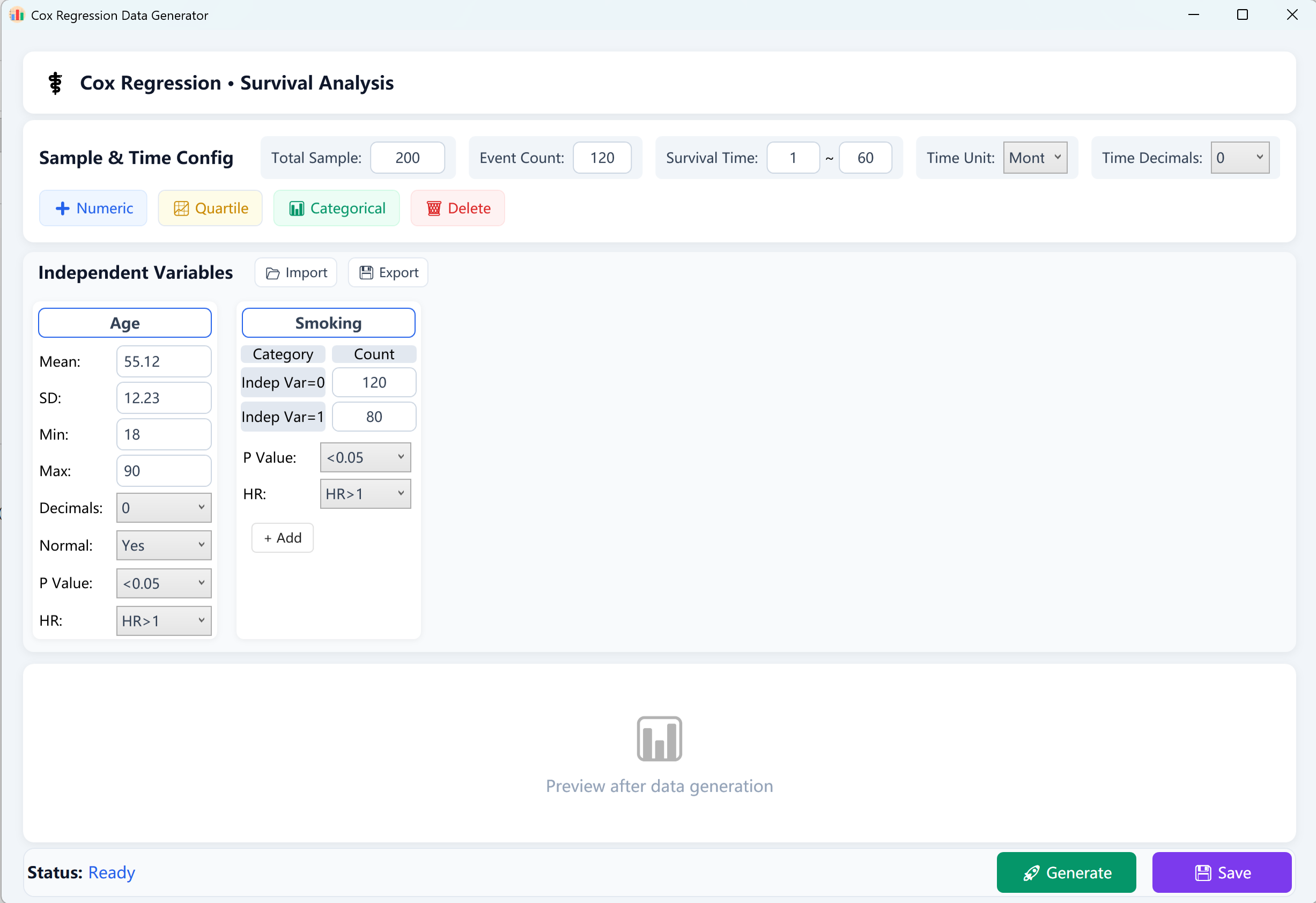
Abbildung 13.1: Benutzeroberfläche / Bedienung für Cox-Regression
- Gesamtstichprobenumfang (N): Die Gesamtzahl der Probanden/Patienten (z. B. 200).
- Beobachtete Ereignisse (Outcome Events): Die Anzahl der positiven Fälle, bei denen das Zielereignis (z. B. Tod, Rezidiv) im Beobachtungszeitraum eingetreten ist. Hinweis: Die Ereignisanzahl muss strikt kleiner als der Gesamtstichprobenumfang sein.
- Überlebenszeitbereich (T): Definieren Sie die Grenzen der Überlebenszeit von [Min Follow-up] bis [Max Follow-up] (z. B. 1~60 Monate) sowie Zeiteinheit und Dezimalstellen.
Statistische EPV-Regel (Events Per Variable): Zur Sicherung der mathematischen Stabilität des Cox-Modells wird empfohlen, dass das Verhältnis von Ereignissen zur Anzahl unabhängiger Variablen (EPV) mindestens 10 bis 20 beträgt. Wenn das Modell nicht konvergiert, erhöhen Sie den Stichprobenumfang oder die Ereignisanzahl.
13.2 Erstellung von Forschungsvariablen
Klicken Sie auf die Schaltflächen unten, um Kovariaten hinzuzufügen:
- Kontinuierliche numerische Variablen: Klicken Sie auf + Numeric. Geben Sie Mittelwert, Standardabweichung (erforderlich), Dezimalstellen und ggf. Min/Max-Grenzen ein.
- Kategoriale Variablen: Klicken Sie auf + Categorical. Geben Sie die exakte Anzahl für jede Kategorie ein. Hinweis: Die Summe der Kategorienhäufigkeiten muss genau dem Gesamtstichprobenumfang entsprechen.
- Quartilsvariablen: Klicken Sie auf + Quartile, um Parameter für Q1, Q2 (Median) und Q3 zu definieren.
Zielvorgaben: Jede Variable besitzt unten zwei wichtige Einstellungsfelder:
- p-Wert der Regression: Wählen Sie die Ziel-Signifikanz (z. B. p > 0,05, p < 0,05, p < 0,01 oder p < 0,001).
- Richtung der Hazard Ratio (HR): Wählen Sie entweder HR > 1 (Risikofaktor) oder HR < 1 (Schutzfaktor).
13.3 Ausführen der Datengenerierung und Speichern
Wenn alle Parameter gesetzt sind, klicken Sie auf die Schaltfläche Generate. Die Engine führt hochparallele iterative Berechnungen durch. Ein professioneller Cox-Regressionsbericht im SPSS-Stil wird automatisch eingeblendet.
Klicken Sie auf Save, um die Rohdaten als Excel-Tabelle zu exportieren, die direkt in SPSS eingelesen werden kann.
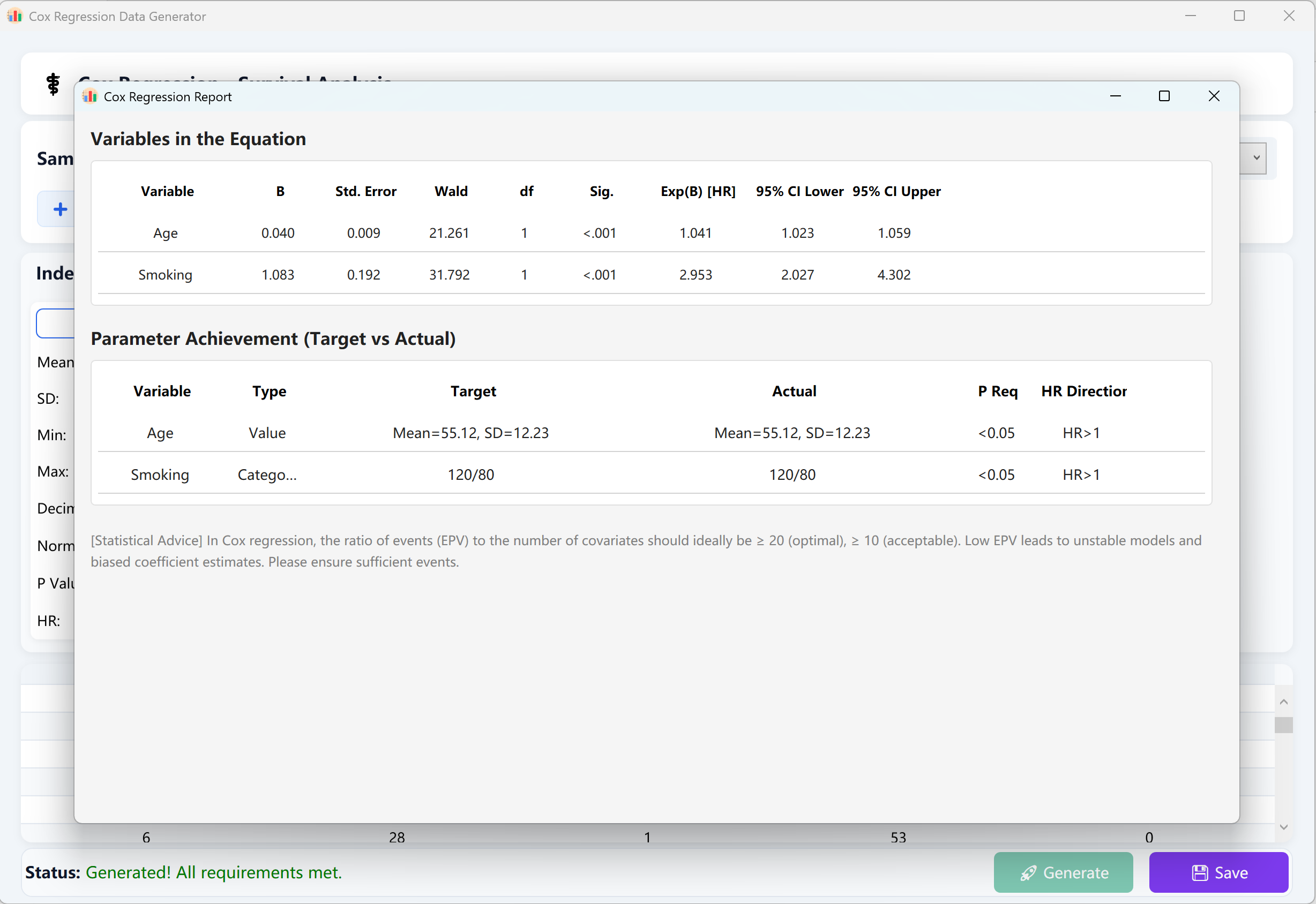
Abbildung 13.2: Benutzeroberfläche / Datenanzeige für Cox-Regression
14. Korrelationsanalyse
Simuliert bivariate Beziehungen (Pearson oder Spearman) sowie partielle Korrelationen durch Vorgabe von Korrelationskoeffizienten (r-Werten) und Signifikanzniveaus.
14.1 Arbeitsablauf
Navigieren Sie zu Analyze → Correlation.
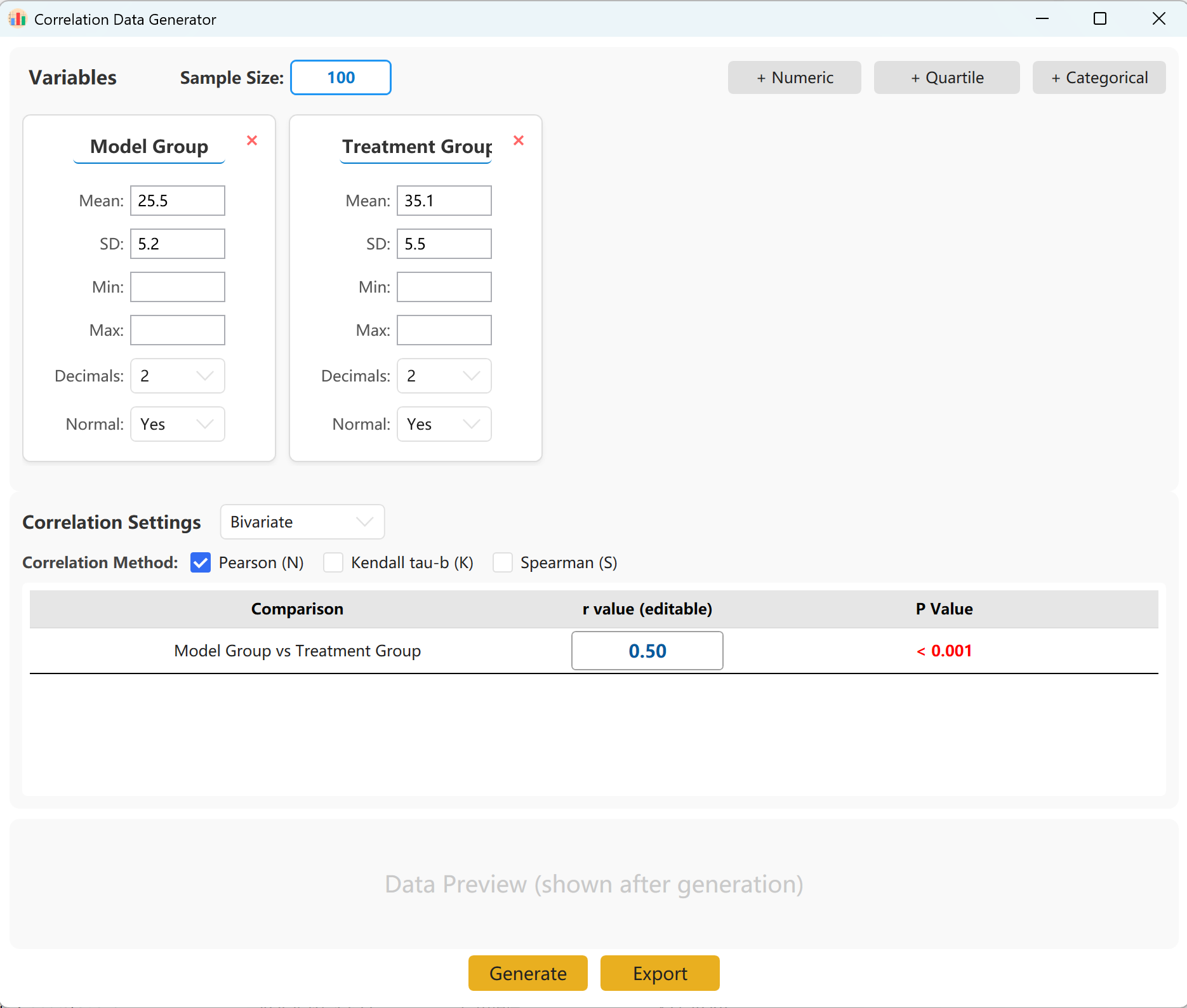
Abbildung 14.1: Benutzeroberfläche / Bedienung für die Korrelationsanalyse
14.2 Parameter
Zwei Variablen-Sets sind standardmäßig vorgeladen. Sie können weitere Variablen in Form von numerischen, quartilsbasierten oder kategorialen Daten hinzufügen. Bestimmen Sie den Stichprobenumfang sowie Mittelwert und Standardabweichung für jeden Indikator (Min/Max-Grenzen sind optional).
Legen Sie den gewünschten Korrelationskoeffizienten (r) fest. Klicken Sie auf Generate, um die Simulation auszuführen und die Korrelationsmatrix in einem Pop-up-Bericht anzuzeigen.
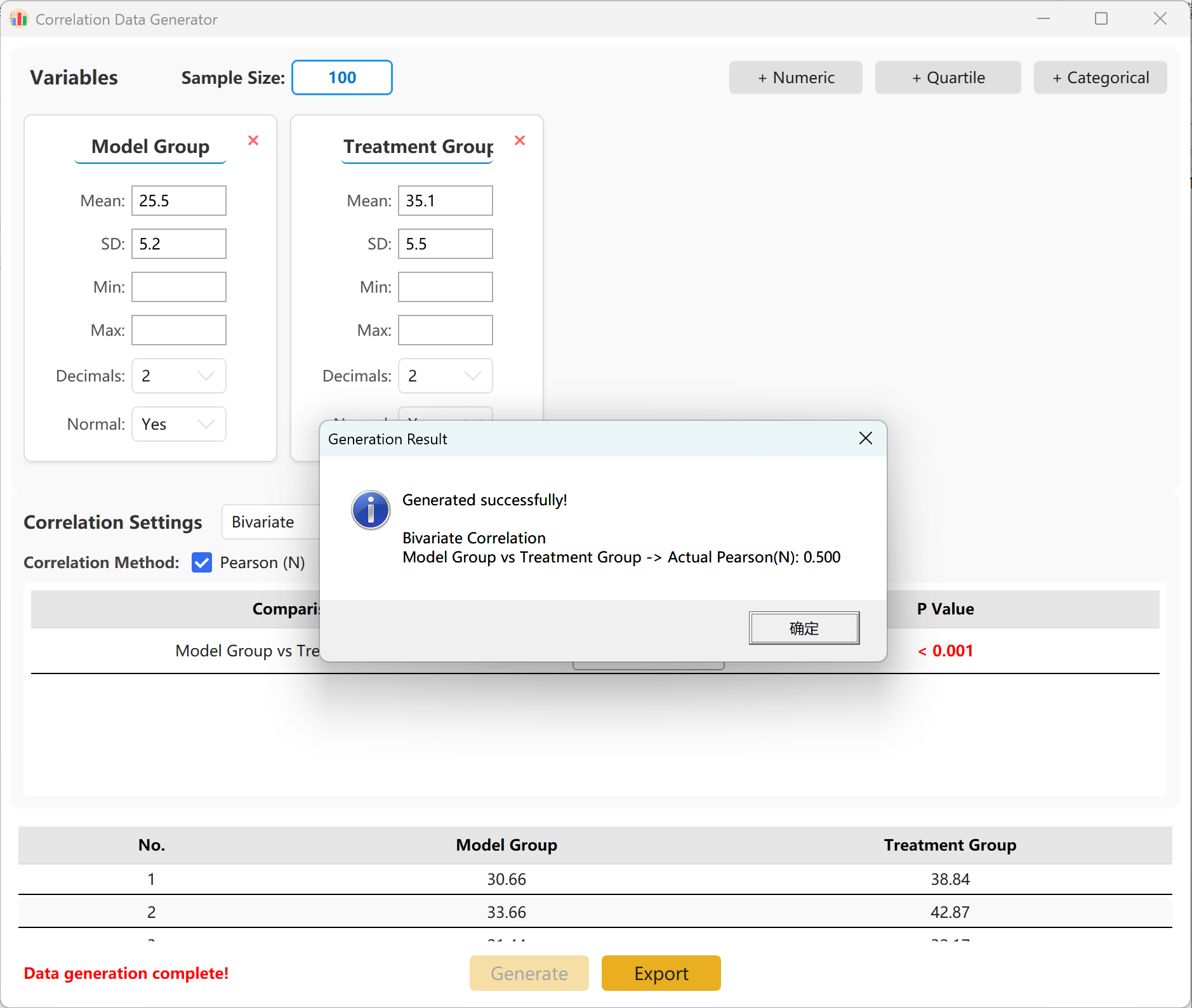
Abbildung 14.2: Benutzeroberfläche / Datenanzeige für die Korrelationsanalyse
15. ROC-Kurvenanalyse
Bewertet die diagnostische Güte einer kontinuierlichen oder kategorialen Testvariablen zur Unterscheidung zwischen zwei Zuständen (z. B. Positiver vs. Negativer Befund).
15.1 Arbeitsablauf
Navigieren Sie zu Analyze → ROC Curve.
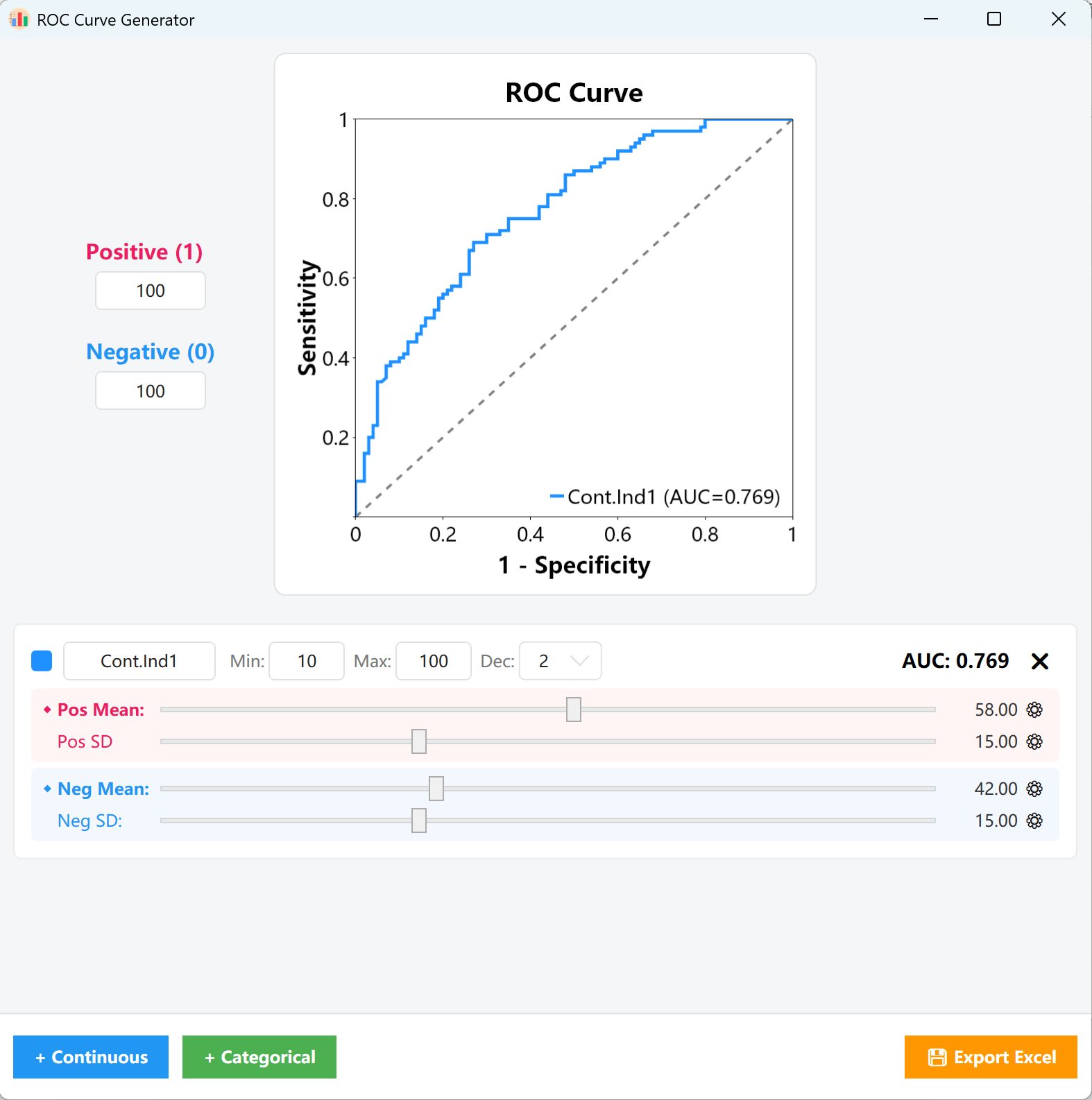
Abbildung 15.1: Benutzeroberfläche / Bedienung für die ROC-Kurvenanalyse
Anteile: Geben Sie im linken Einstellungsbereich die Stichprobenanzahl für positive Proben (1) und negative Proben (0) ein (z. B. 100 positive und 100 negative Fälle). Auf dieser Basis wird die statistische Matrix aufgebaut.
15.2 Variablentypen
Klicken Sie unten links auf + Continuous oder + Categorical:
- Kontinuierliche Variablen: Legen Sie Name, Min/Max und Dezimalstellen fest. Ziehen Sie den pinken Regler (positive Gruppe) und den blauen Regler (negative Gruppe), um Mittelwert und Standardabweichung schnell anzupassen.
- ⚙ Präzise Eingabe: Wenn die visuellen Schieberegler nicht fein genug sind, klicken Sie auf das Zahnrad-Symbol (⚙) neben den Werten, um Fließkommazahlen präzise manuell einzutippen.
- AUC-Wert überwachen: Während dieser Anpassungen aktualisieren sich der AUC-Wert (oben rechts) und die ROC-Kurve in Echtzeit, so dass Sie den Kurvenverlauf optisch genau anpassen können.
- Kategoriale Variablen: Definieren Sie die exakten Verhältnisse in den positiven und negativen Kohorten, um die ROC-Kurve und den AUC-Wert direkt anzupassen.
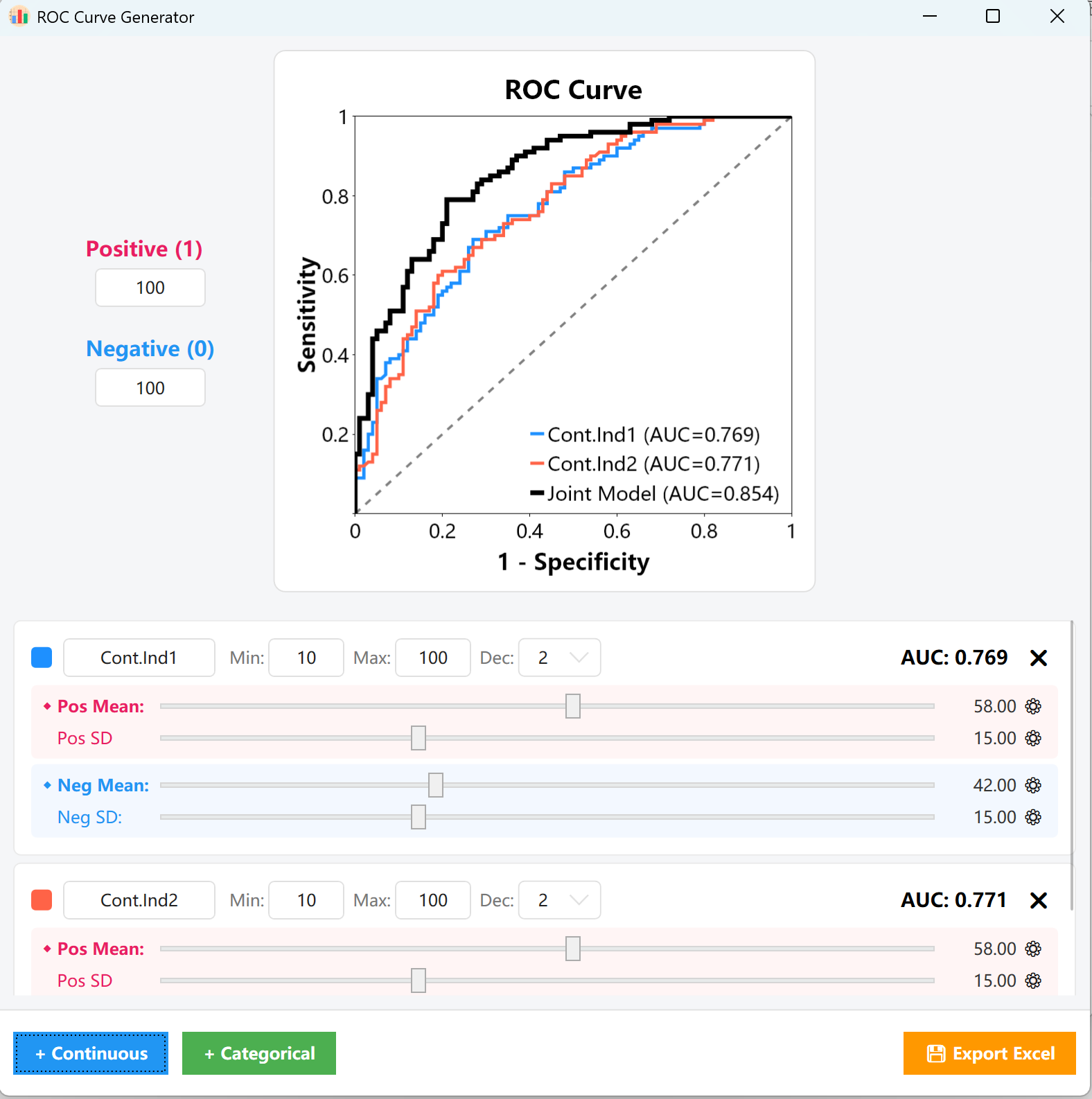
Abbildung 15.2: Benutzeroberfläche / Datenanzeige für die ROC-Kurvenanalyse
16. Speichern und Exportieren konfigurierter Parameter
Um wiederkehrende Modellierungsaufgaben zu vereinfachen und manuelle Eingabefehler zu vermeiden, bietet die Anwendung einen leistungsstarken integrierten Mechanismus zum Sichern des Konfigurationszustands.
16.1 Sichern/Wiederherstellen
- Konfiguration exportieren: Navigieren Sie zu File → Export Configuration, um alle eingestellten Parameter, Variablendefinitionen und Gruppenstrukturen als lokale `.json`-Datei zu sichern.
- Konfiguration importieren: Um die Konfiguration in einer zukünftigen Sitzung wiederherzustellen, wählen Sie einfach File → Import Configuration und wählen Sie die gespeicherte Datei aus. Der gesamte Arbeitsbereich lädt sofort alle Variablenkarten, Regler und Parameterwerte neu.