ドキュメントとユーザーガイド
DataSynth Proの公式ドキュメントへようこそ。この包括的なマニュアルでは、さまざまな統計モジュールのパラメータ設定方法について詳細なガイダンスを提供し、堅牢で学術的に有効な統計データセットを完全オフラインで合成する方法を説明します。
1. 複数の指標を同時に生成
1.1 前提条件と起動
実行可能ファイルをダブルクリックしてアプリケーションを起動します。このソフトウェアにはMicrosoft .NET 8.0 Runtime Frameworkが必要です。お使いのコンピュータにインストールされていない場合は、プロンプトに従ってダウンロードしてインストールし、プログラムを再起動してください。
セキュリティ通知: ウイルス対策ソフトウェアが実行ファイルを誤検出した場合は、ローカルの除外リストまたはホワイトリストに追加して、中断のない動作を確保してください。
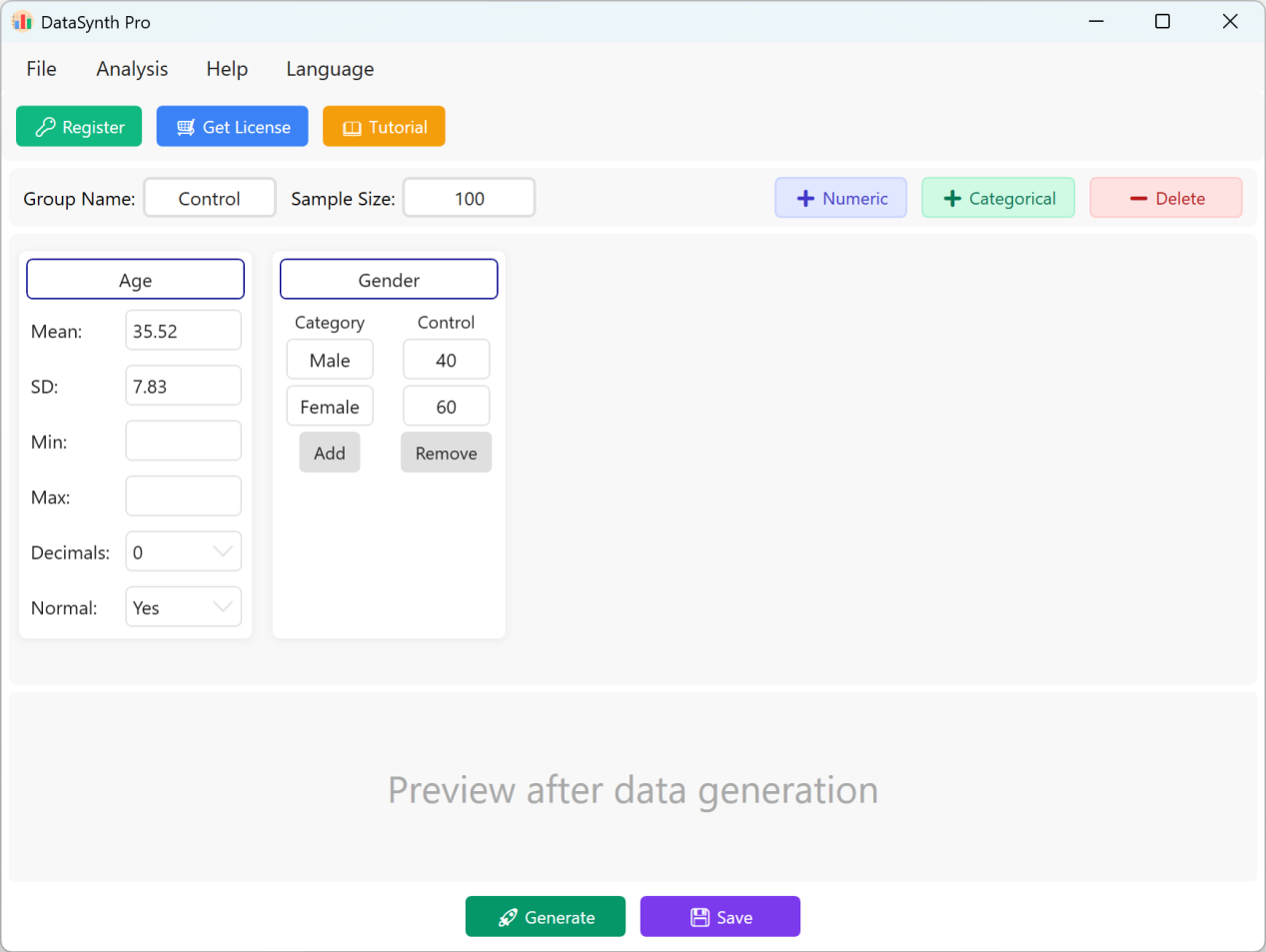
図1.1: メインインターフェース
1.2 パラメータ設定
デフォルトでは、アプリケーションは「年齢」と「性別」の2つの連続変数を事前入力し、クイックリファレンスとして機能します。グループ名はデフォルトで「Control Group」に設定され、サンプルサイズは100ケースに設定されています。研究で複数のグループが必要な場合は、各実行のパラメータを更新して各グループのデータセットを順次生成・エクスポートできます。
- 連続数値変数の追加: 新しい量的変数を追加するには、+ Numeric ボタンをクリックします。指標名(例:「Body Mass Index」や「BMI」)、平均、標準偏差、小数点以下の桁数を指定できます。最小値と最大値のフィールドはオプションで、特定の値の制限がない場合は空白のままにできます。
- データ分布の設定: デフォルトでは、生成される数値指標は正規分布に従います。非正規分布のデータが必要な場合は、Normal Distribution オプションを No に設定するだけです。
分布調整: 正規分布は自然な分散範囲に依存します。最小値と最大値の制限を厳しくしすぎると正規曲線が切断され、非正規分布の値になる可能性があります。この問題が発生した場合は、境界を広げるか、最小値/最大値の制限を完全に削除してみてください。
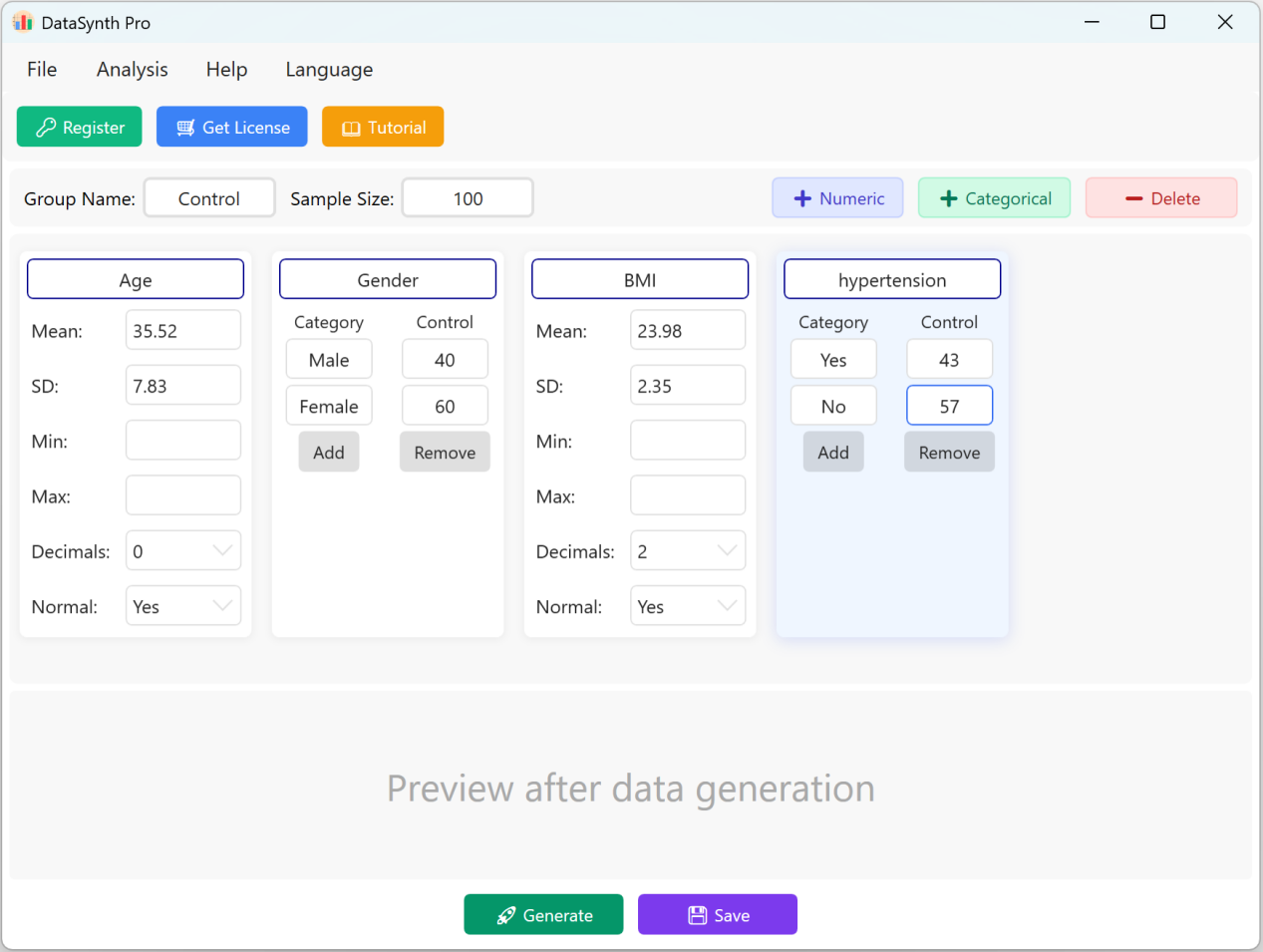
図1.2: 変数の追加
1.3 カテゴリカル変数の追加
+ Categorical ボタンをクリックして、質的変数(例:「高血圧」)を追加します。カテゴリ名と対応する目標分布または比率を入力できます。カテゴリ比率の合計は、設定されたサンプルサイズに合わせて動的にスケーリングされます。
1.4 生成の実行
Generate ボタンをクリックして、要求された数のレコードを合成します。計算後、記述統計のサマリーウィンドウが表示され、実際の生成値が設定パラメータと一致するかどうかを確認できます。
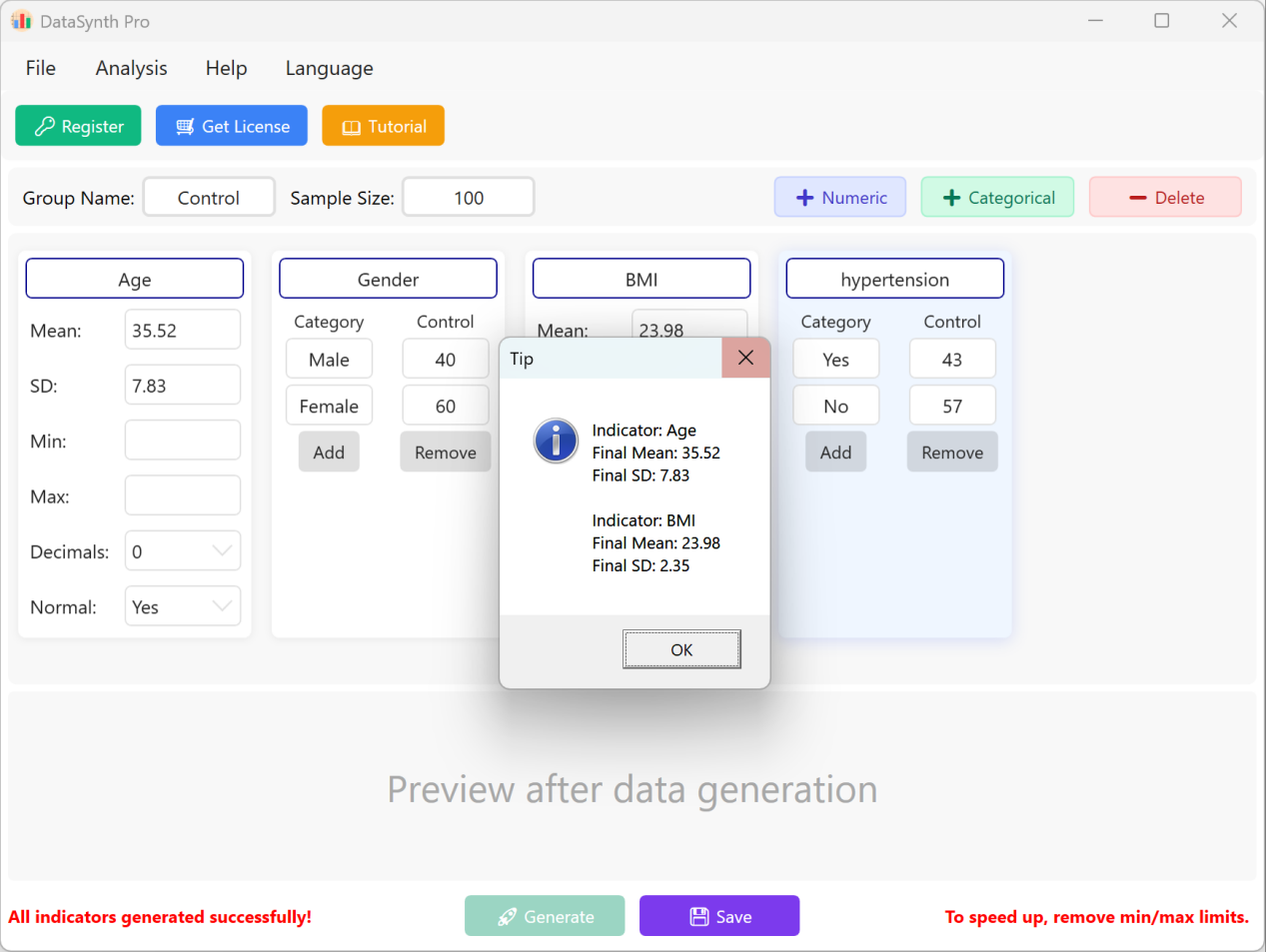
図1.3: 生成の実行
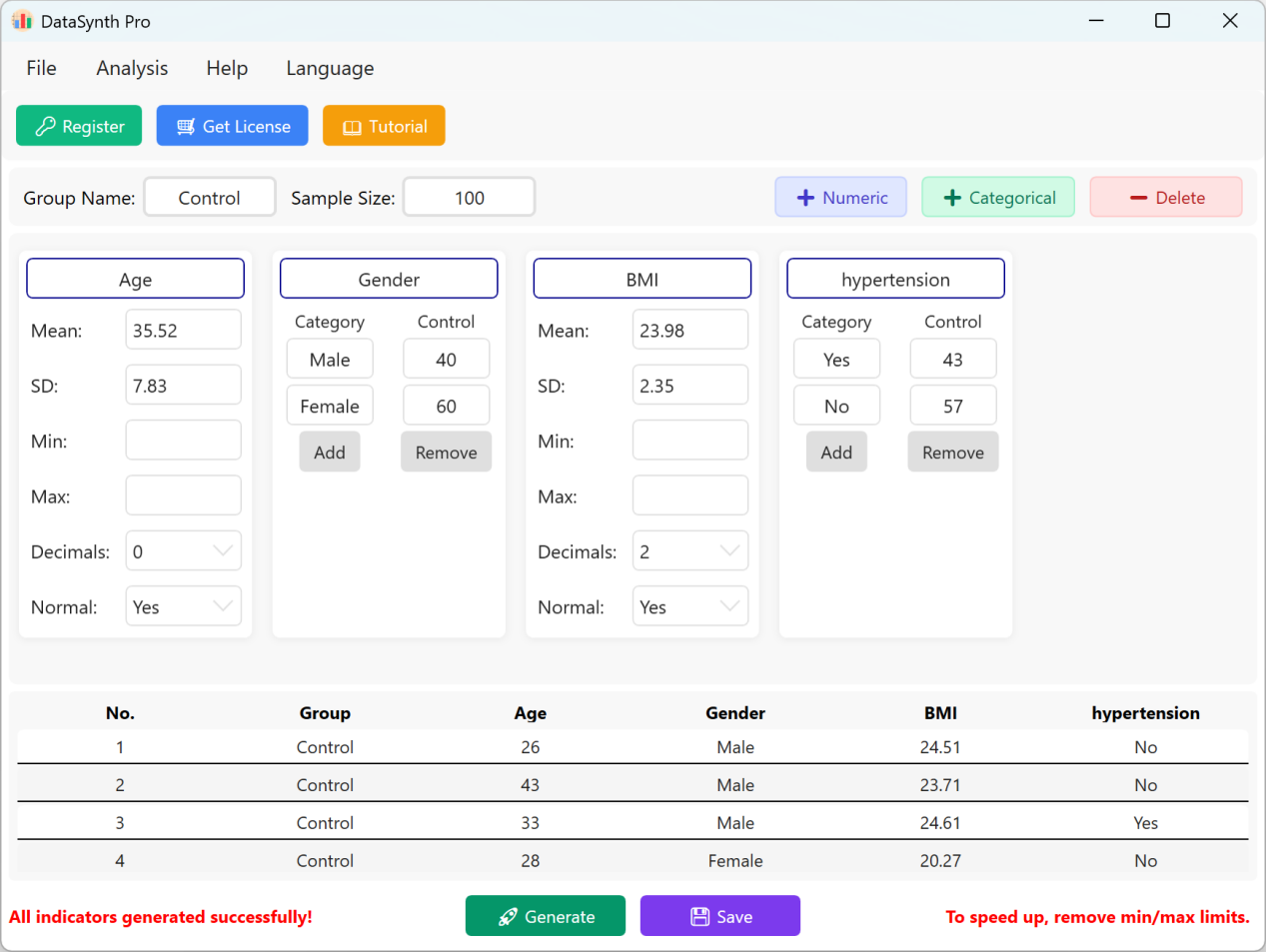
図1.4: データの表示
1.5 エクスポートと検証
Save ボタンをクリックして、生成されたデータセットを標準のExcelファイルとしてエクスポートします。エクスポートされたスプレッドシートを開き、標準のExcel数式を使用して「年齢」の記述統計(小数点以下2桁に四捨五入)を計算すると、実際の平均と標準偏差が初期設定と完全に一致します。
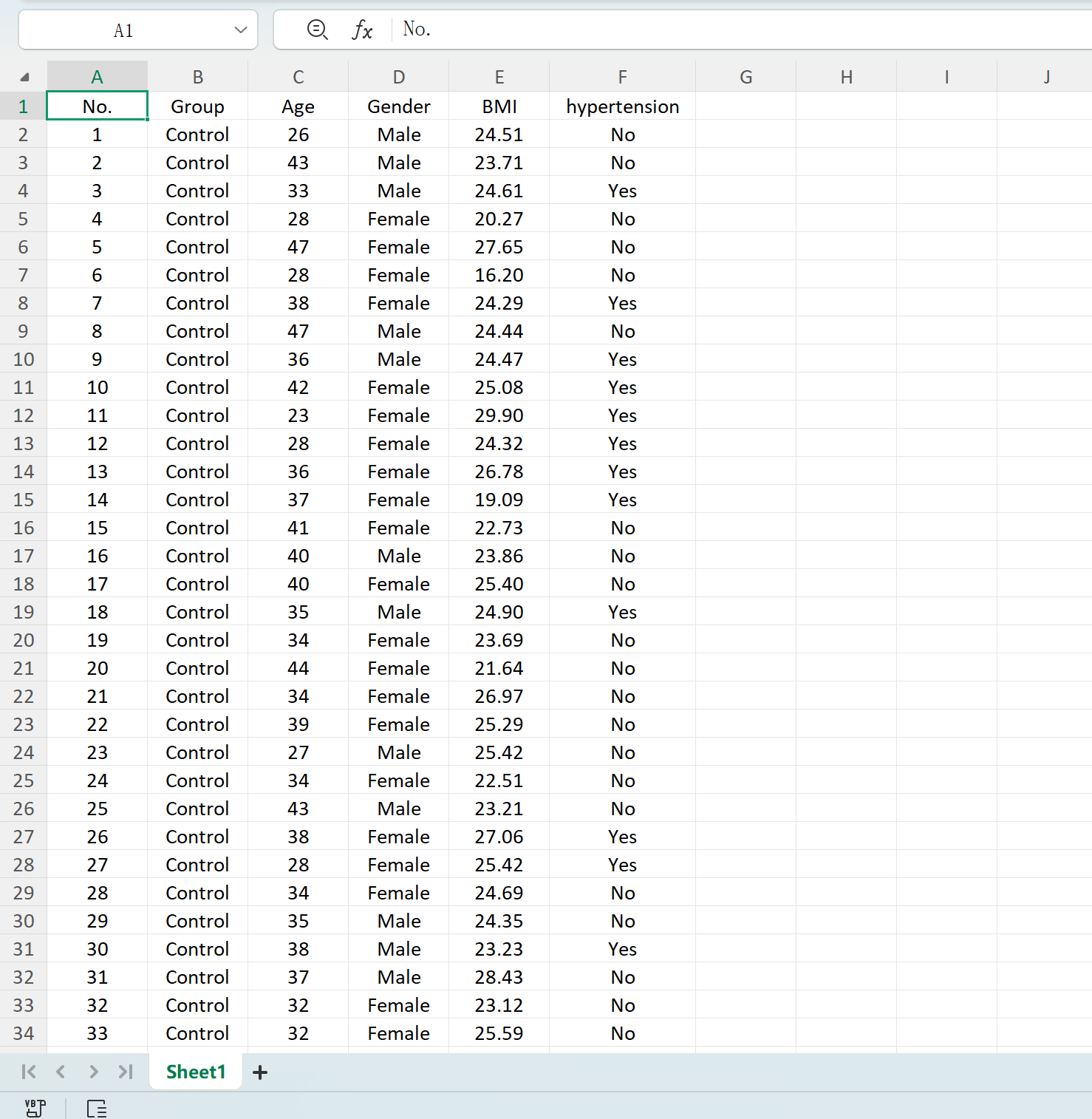
図1.5: 生成されたテーブルのExcelへのエクスポート
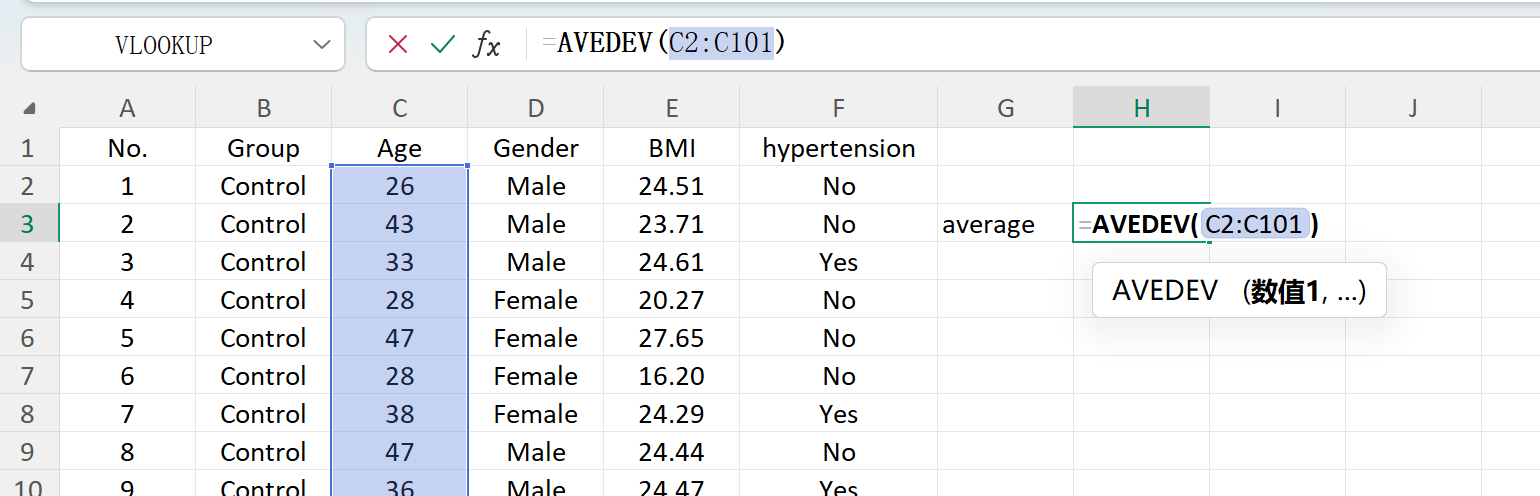
図1.6: Excelでの平均計算
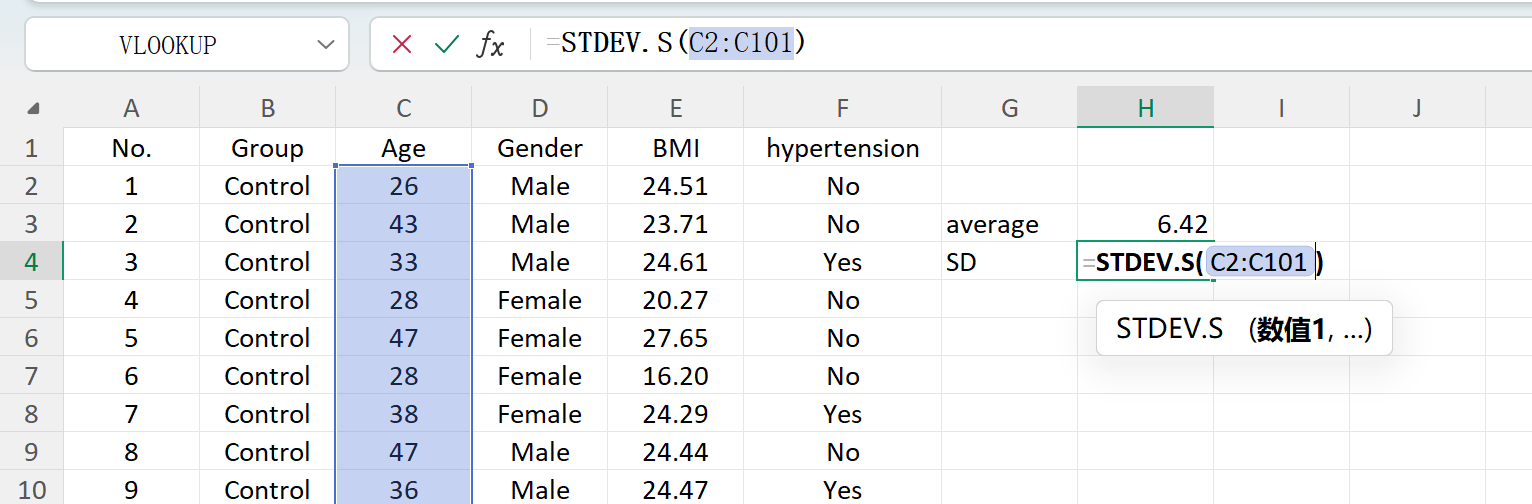
図1.7: Excelでの標準偏差計算
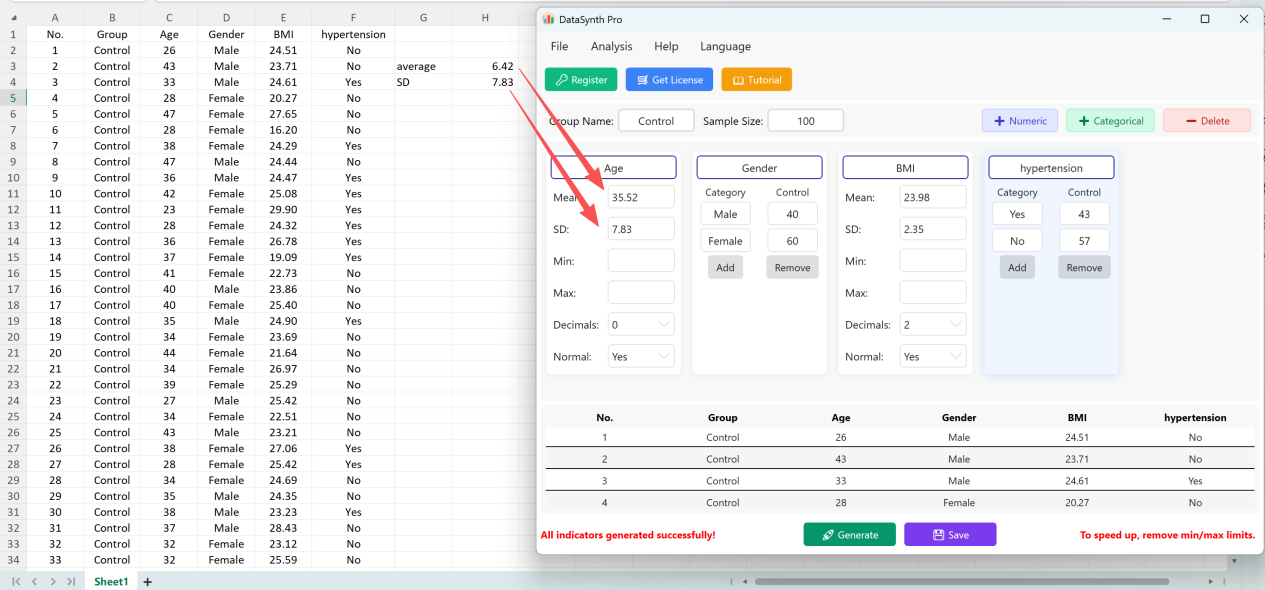
図1.8: 初期設定と一致する検証結果
1.6 計算効率
高性能最適化エンジンを搭載しており、数千から数万のレコードを含むデータセットを数秒で生成できます。最大反復回数後にシステムが収束しない場合は、設定の統計的妥当性を再確認するか、最小値/最大値なしでクエリを実行してみてください。プログラムは特殊な科学研究のニーズを満たすために、最大8桁の小数点精度をサポートしています。
ヒントと推奨事項:
• 正規分布の推奨: データはデフォルトで正規分布になり、シームレスなダウンストリーム分析(例:独立したサンプルのt検定)を可能にします。ノンパラメトリックまたはカスタム分布のデータセットが必要な場合は、Normal Distribution設定をNoに切り替えるだけです。
2. 独立したサンプルのt検定
2つの異なるグループの平均を比較する横断研究向けに設計。臨床試験(例:治療群とプラセボ群間の薬効)や社会学的調査で広く使用されています。
2.1 ワークフロー
Analyze → Independent T-Test に移動します。以下のように設定ウィンドウが表示されます。
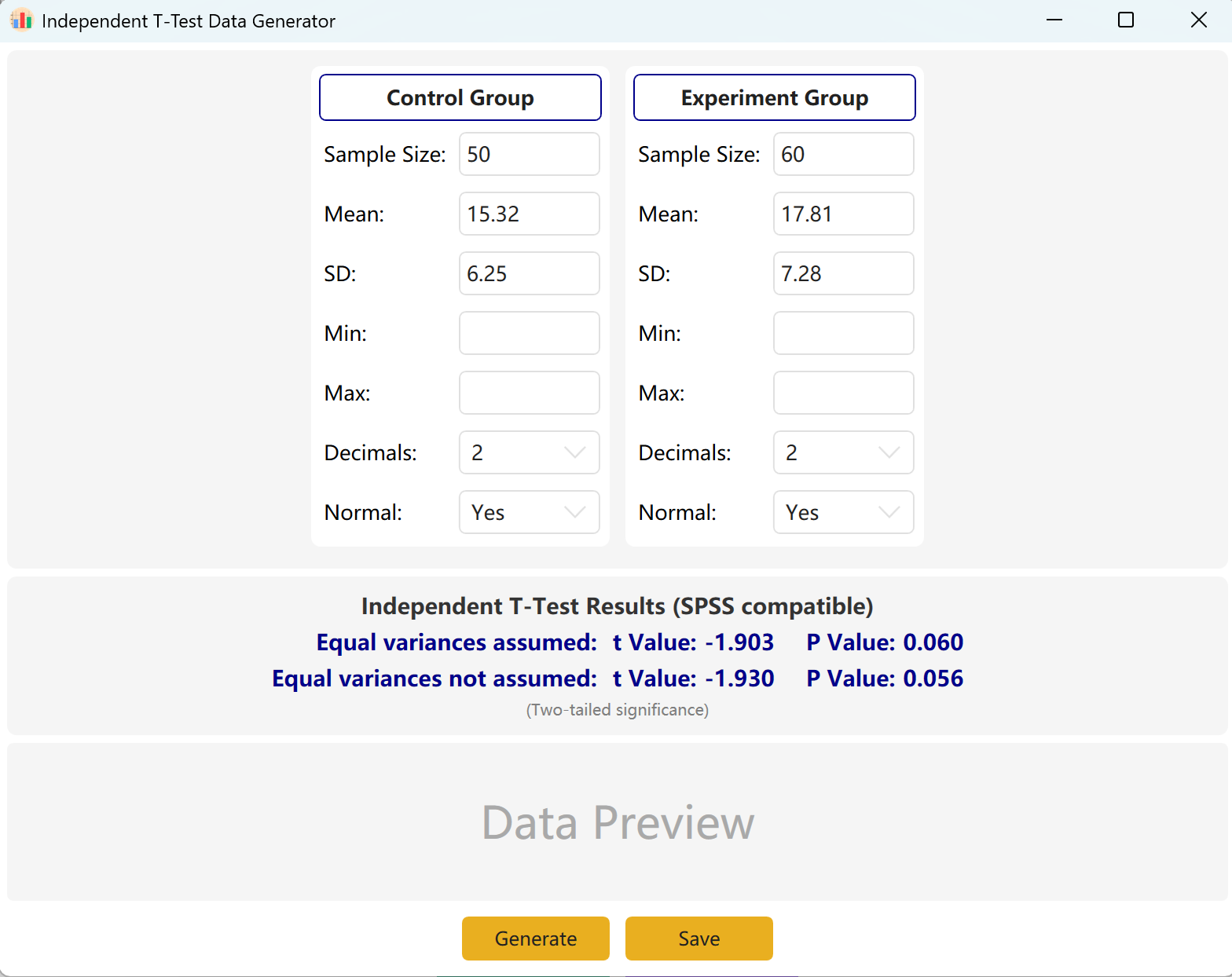
図2.1: 独立したT検定の設定
2.2 パラメータ
プログラムは「Control Group」と「Experimental Group」のサンプル設定を事前入力します。各グループのサンプルサイズ、平均、標準偏差を入力すると、計算されたt値とp値がリアルタイムでプレビューされます。最小値と最大値のパラメータはオプションです。
Generateボタンをクリックすると、両グループの生データセットが下のプレビューテーブルに作成され、最終的なt値とp値は実際の生成データを反映するように調整され、Leveneの等分散性検定が使用されます。
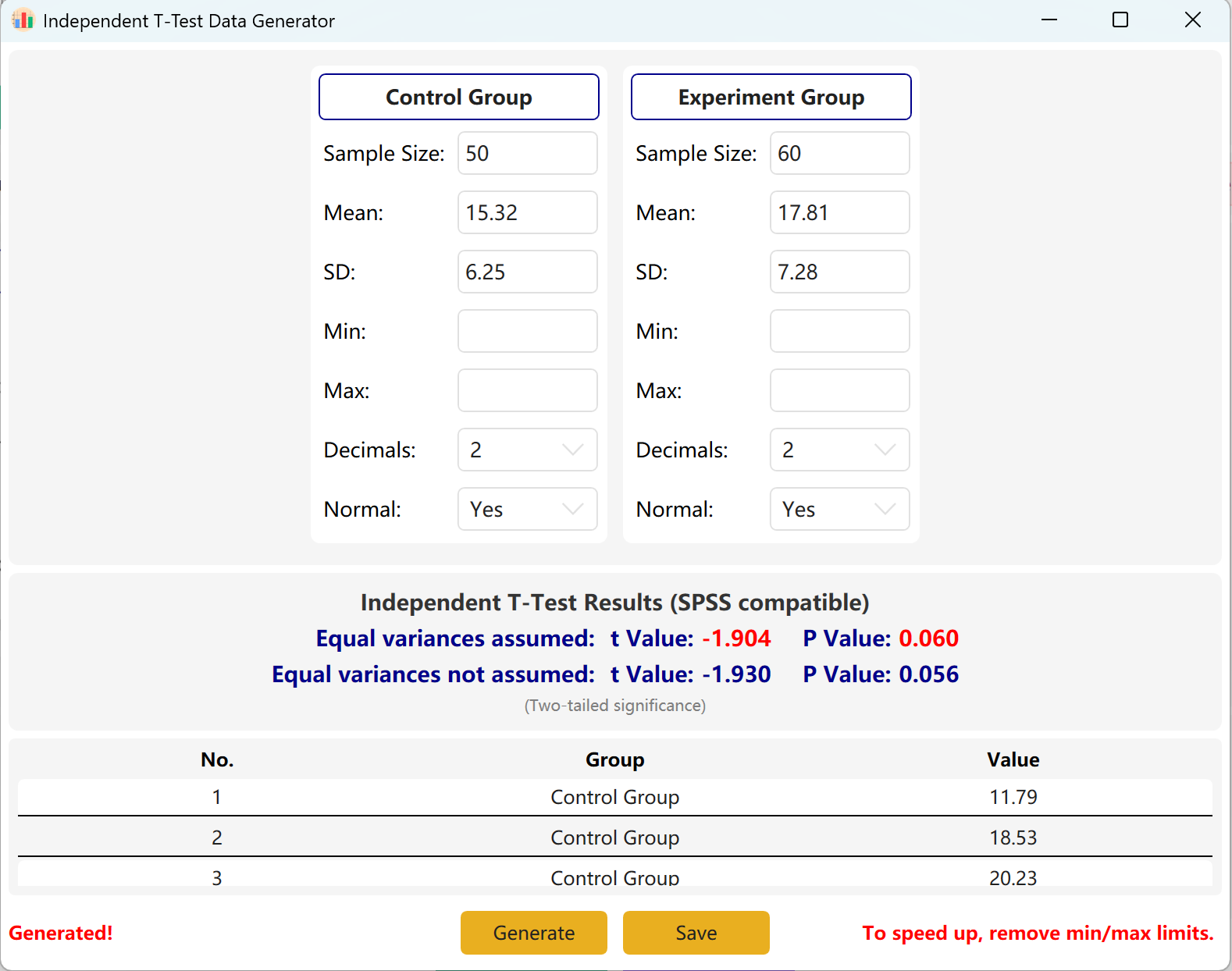
図2.2: 独立したサンプルのT検定データの表示
3. 対応のあるサンプルのt検定
同じ被験者が2回測定される縦断研究やクロスオーバー研究で使用されます(例:事前テスト vs. 事後テスト)。ペアになった観測間の平均差の合成に焦点を当てています。
3.1 ワークフロー
Analyze → Paired T-Test に移動します。ワークスペースのレイアウトは以下のとおりです。
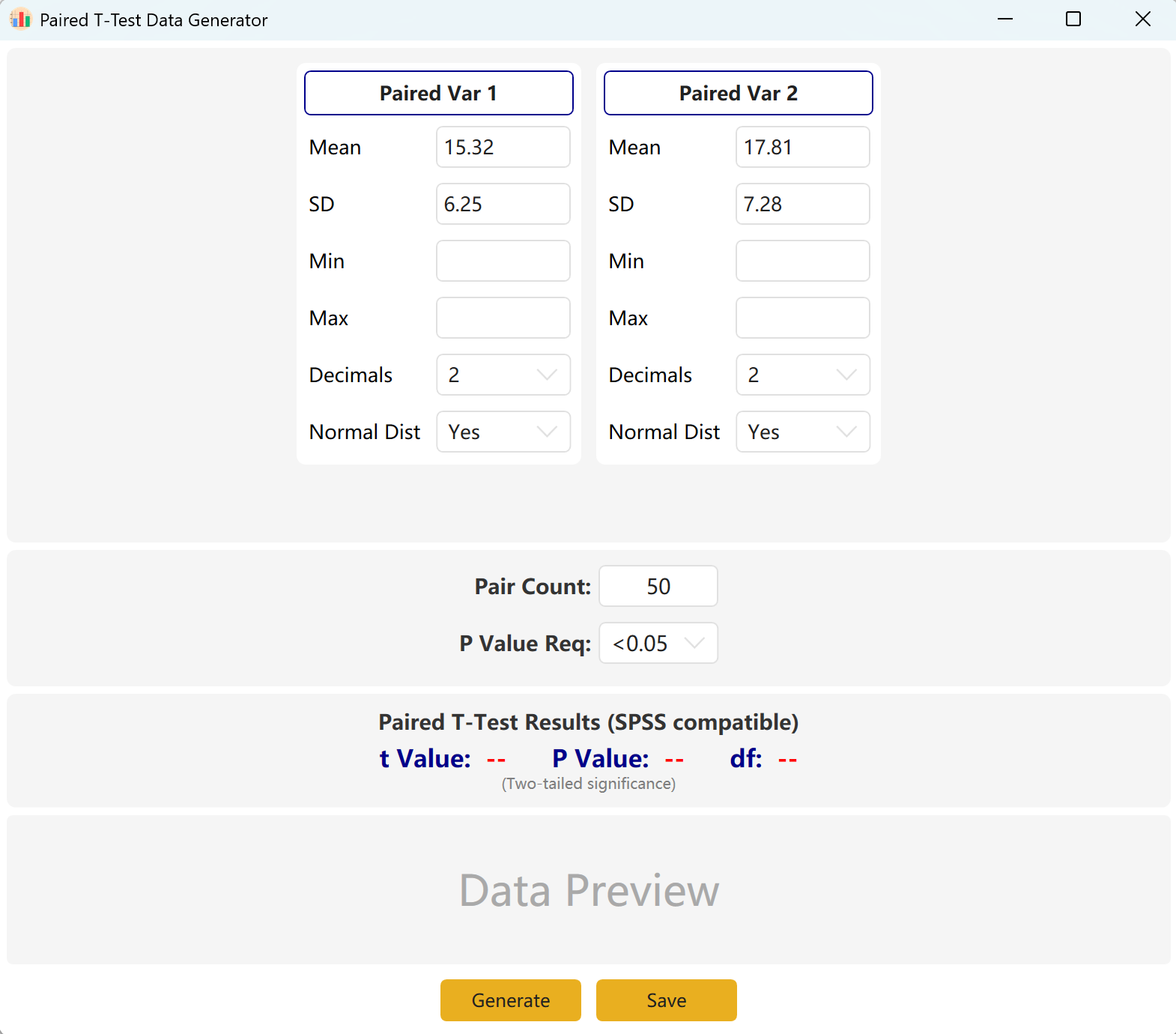
図3.1: 対応のあるT検定の設定
3.2 シミュレーションロジック
ソフトウェアはデフォルトで2つのペア変数(Paired Var1とPaired Var2)を設定します。各変数の平均と標準偏差を定義し、全体のサンプルサイズを設定し、対応のあるt検定の目標p値範囲を確立できます。エンジンは反復的に準拠したデータセットを計算します。
収束適応: 設定された平均が目標のp値と数学的に矛盾している場合(例:2つの平均が大きく異なるが、p > 0.05の非有意を要求する場合)、プログラムは最初のグループのパラメータを一定に保ち、2番目のグループの平均を動的に調整して目標のp値を達成します。
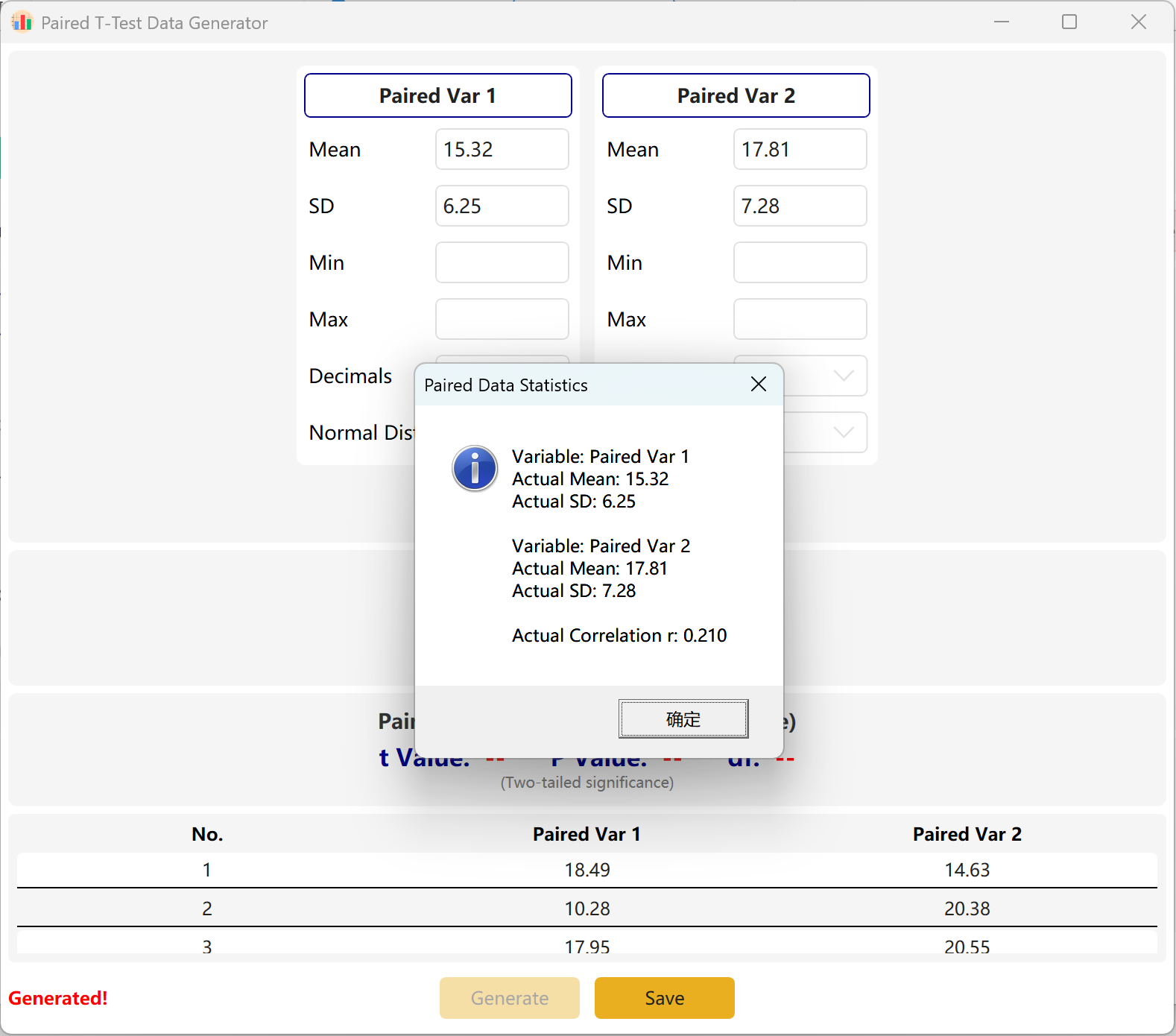
図3.2: 対応のあるサンプルのT検定データの表示
4. カイ二乗検定
2つのカテゴリカル変数間に有意な関連があるかどうかを判断します。人口統計学的クロス集計で広く使用されています。
4.1 ワークフロー
Analyze → Chi-Square Test に移動します。設定ペインが以下のように開きます。
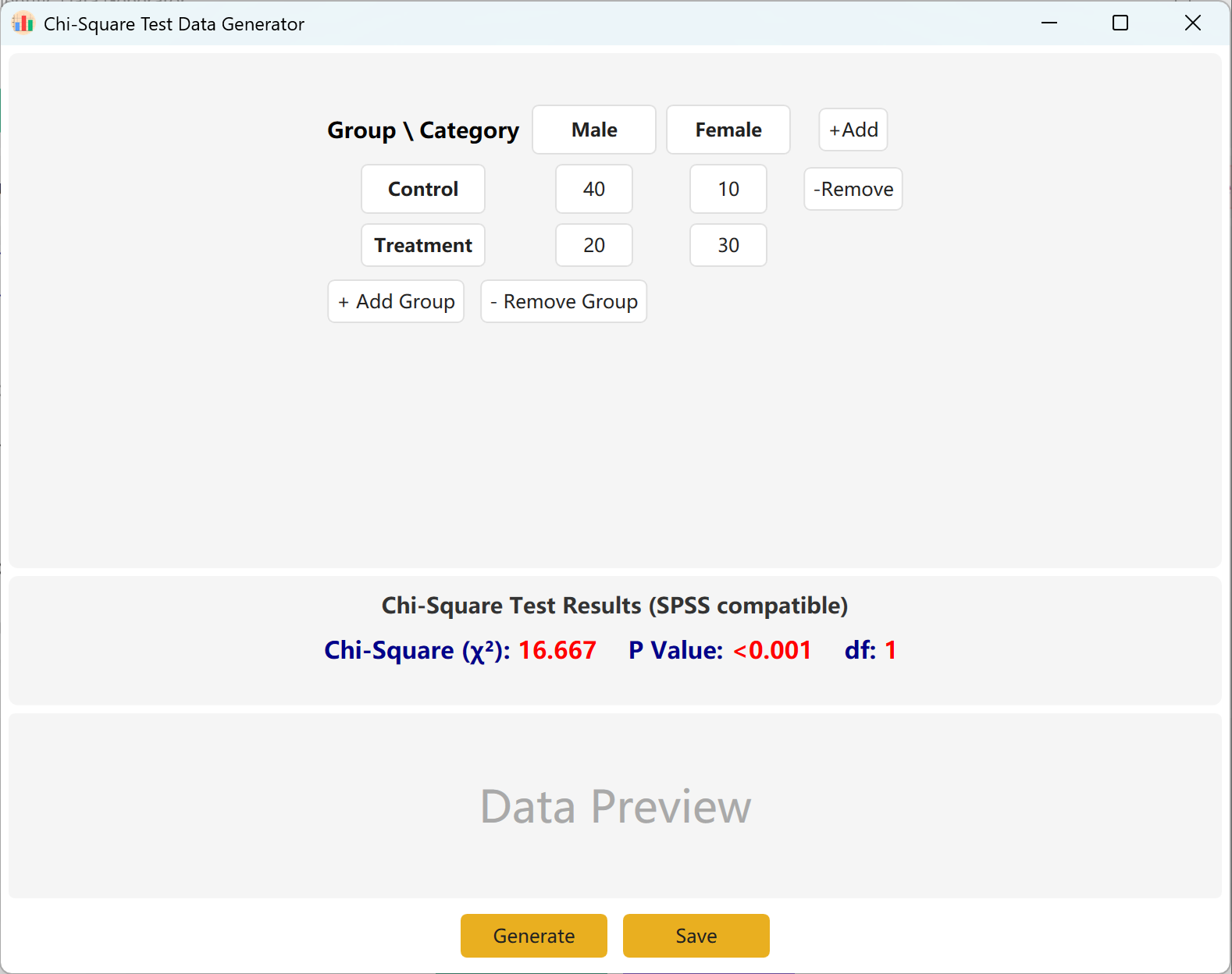
図4.1: カイ二乗検定の設定
4.2 分割表
インターフェースはデフォルトでカイ二乗計算用の標準的な2x2分割表を使用します。グループ名とカテゴリ名は完全に編集可能です。各セルに観測頻度(カウント)を入力すると、計算されたカイ二乗値とp値がリアルタイムで更新されます。
グループ(行)やカテゴリ(列)を動的に追加して、より大きなモデルに対応できます。Generate ボタンをクリックしてこれらの頻度に一致する個々の生レコードを生成し、Save をクリックしてデータセットをExcelにエクスポートします。
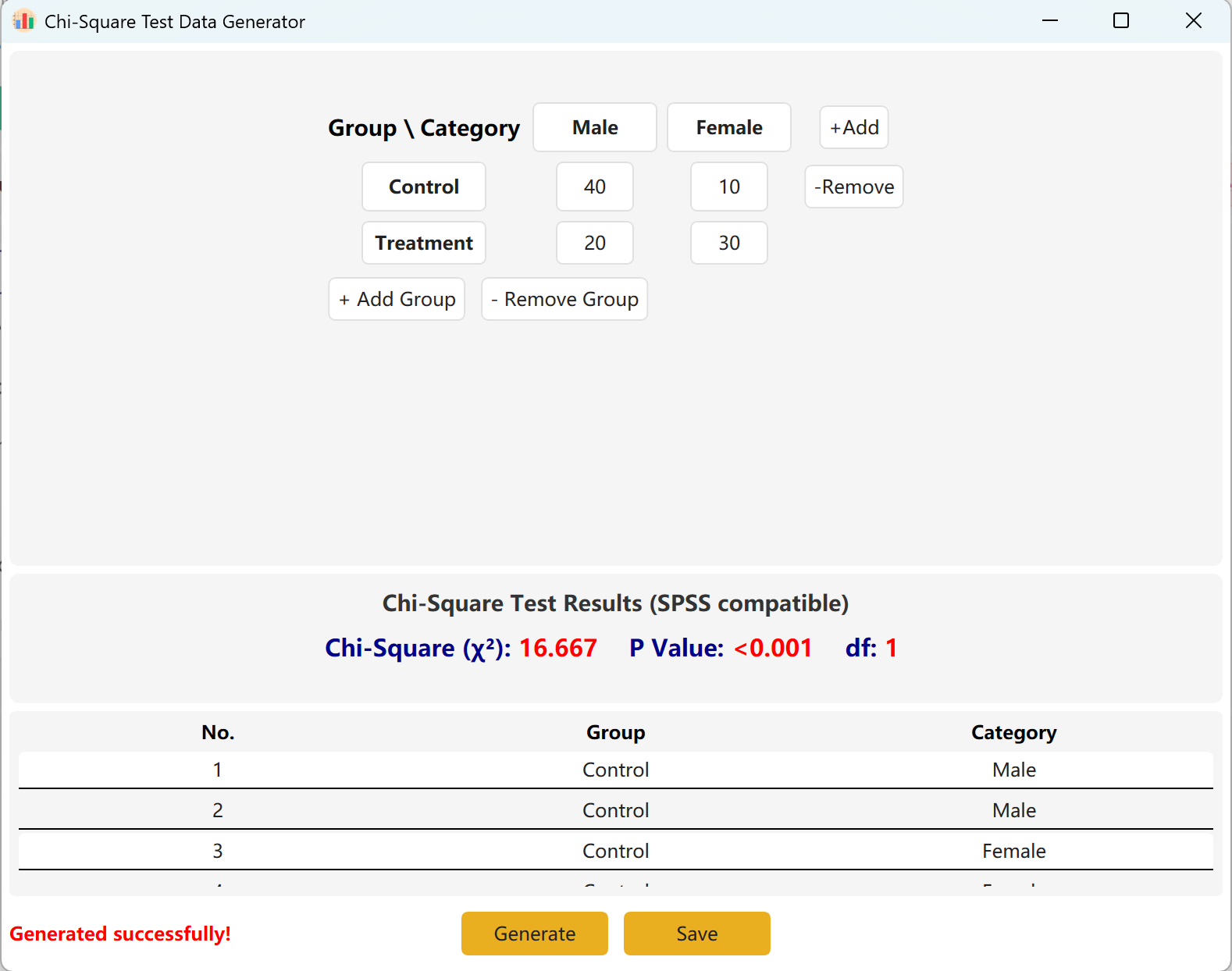
図4.2: カイ二乗検定データの表示
5. 一元配置分散分析
3つ以上の独立したグループの平均を比較する際に使用されます。アルゴリズムはグループ内分散とグループ間差異を合成して、目標のF値を達成します。
5.1 ワークフロー
Analyze → ANOVA → One-Way ANOVA に移動します。ワークスペースのレイアウトは以下のとおりです。
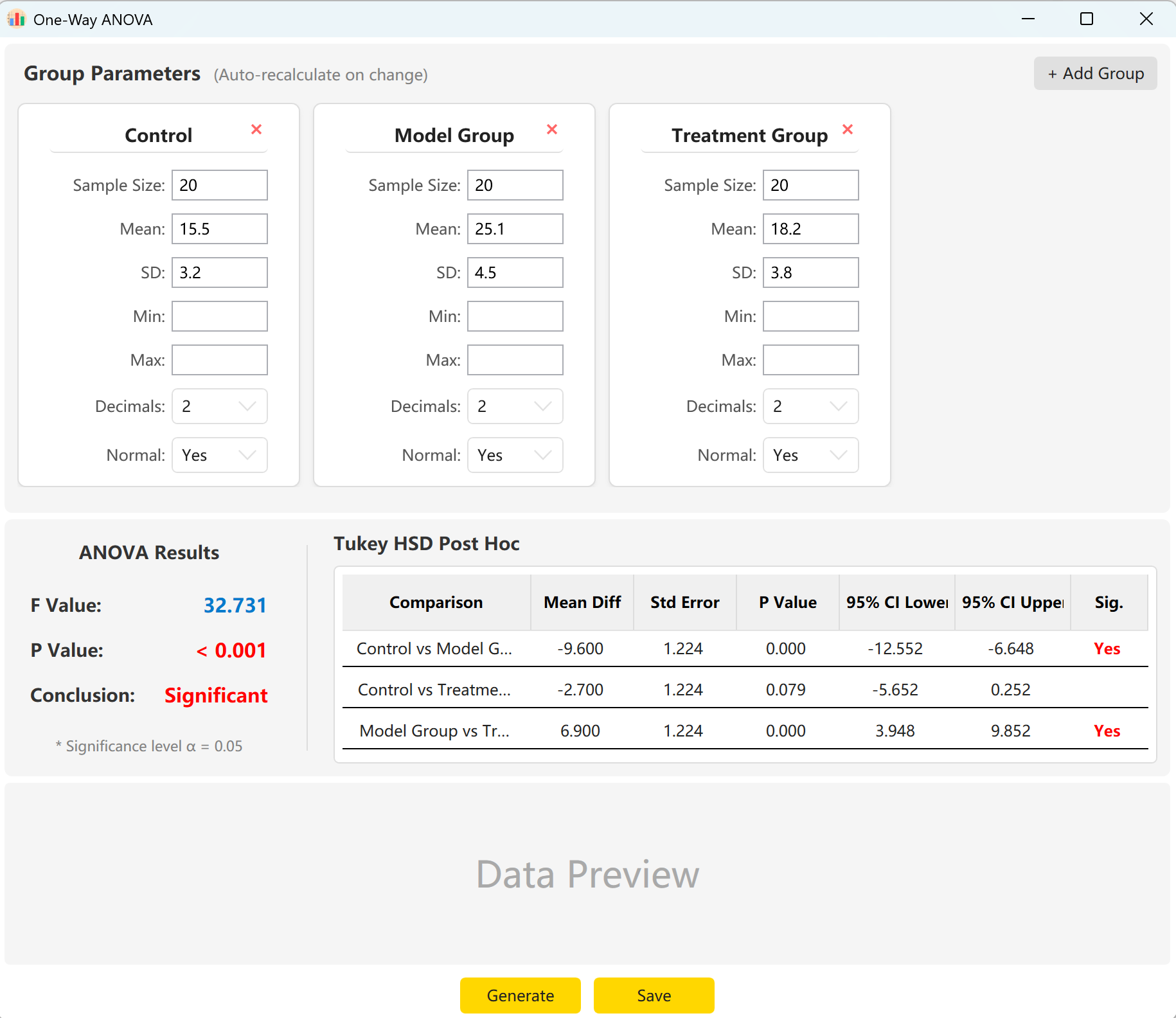
図5.1: 一元配置分散分析の設定
5.2 設定
システムは「Control Group」、「Experimental Group」、「Treatment Group」の3つのグループのパラメータを事前読み込みします。各グループのサンプルサイズ、平均、標準偏差を入力するだけで、全体的なF統計量、p値、TukeyのHSDの事後多重比較結果を即座にプレビューできます。
Generate ボタンをクリックして、個々の生レコードを計算・プレビューします。全体的なF値とp値は自動的に更新され、実際の生成値を表します。
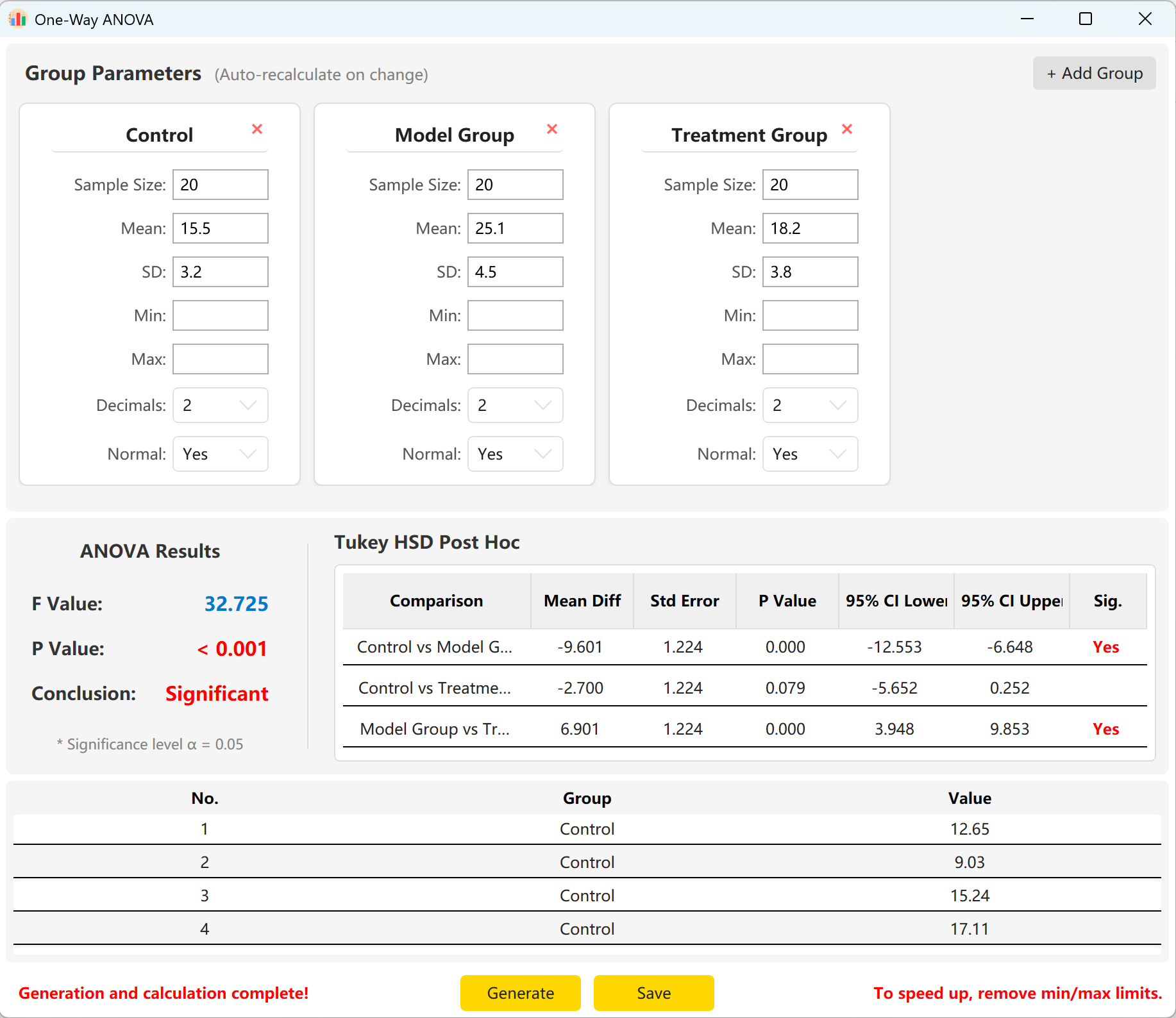
図5.2: 一元配置分散分析データの表示
6. 二元配置分散分析
2つの独立したカテゴリカル変数が1つの連続従属変数に及ぼす影響を調べます。因子計画で主効果と交互作用効果を評価するために不可欠です。
6.1 ワークフロー
Analyze → ANOVA → Two-Way ANOVA に移動します。設定ペインが以下のように表示されます。
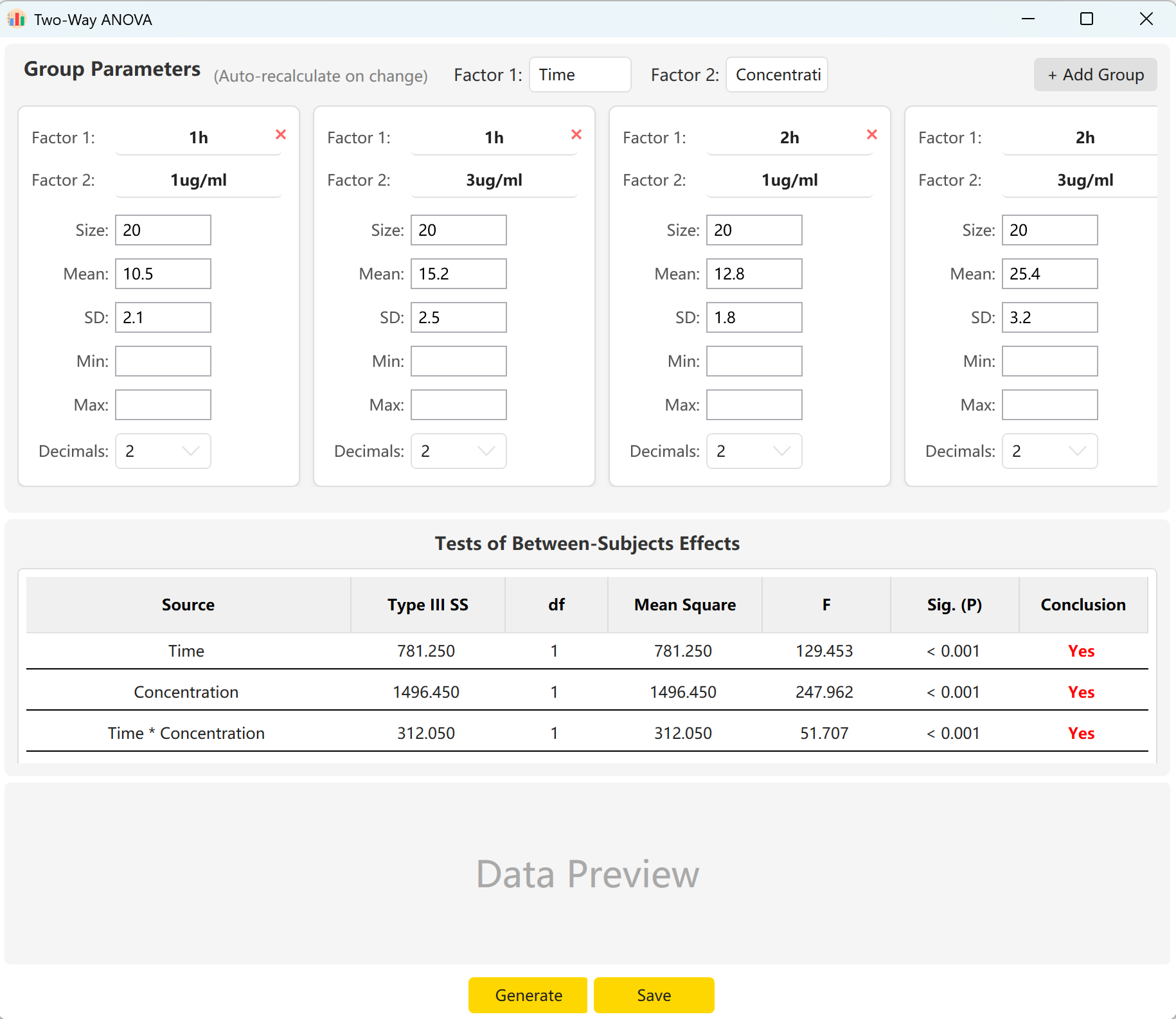
図6.1: 二元配置分散分析の設定
6.2 因子と交互作用
ツールはデフォルトで「時間」(2水準)と「濃度」(2水準)の2因子を使用します。因子に複数の分類が含まれる場合は、Add Group をクリックしてより多くの水準を設定します。
各セルのサンプルサイズ、平均、標準偏差を入力することで、時間の主効果、濃度の主効果、およびそれらの交互作用効果(時間×濃度)のF統計量とp値をプレビューできます。Generate ボタンをクリックして、プレビューペインに一致する個々の生レコードを構築します。
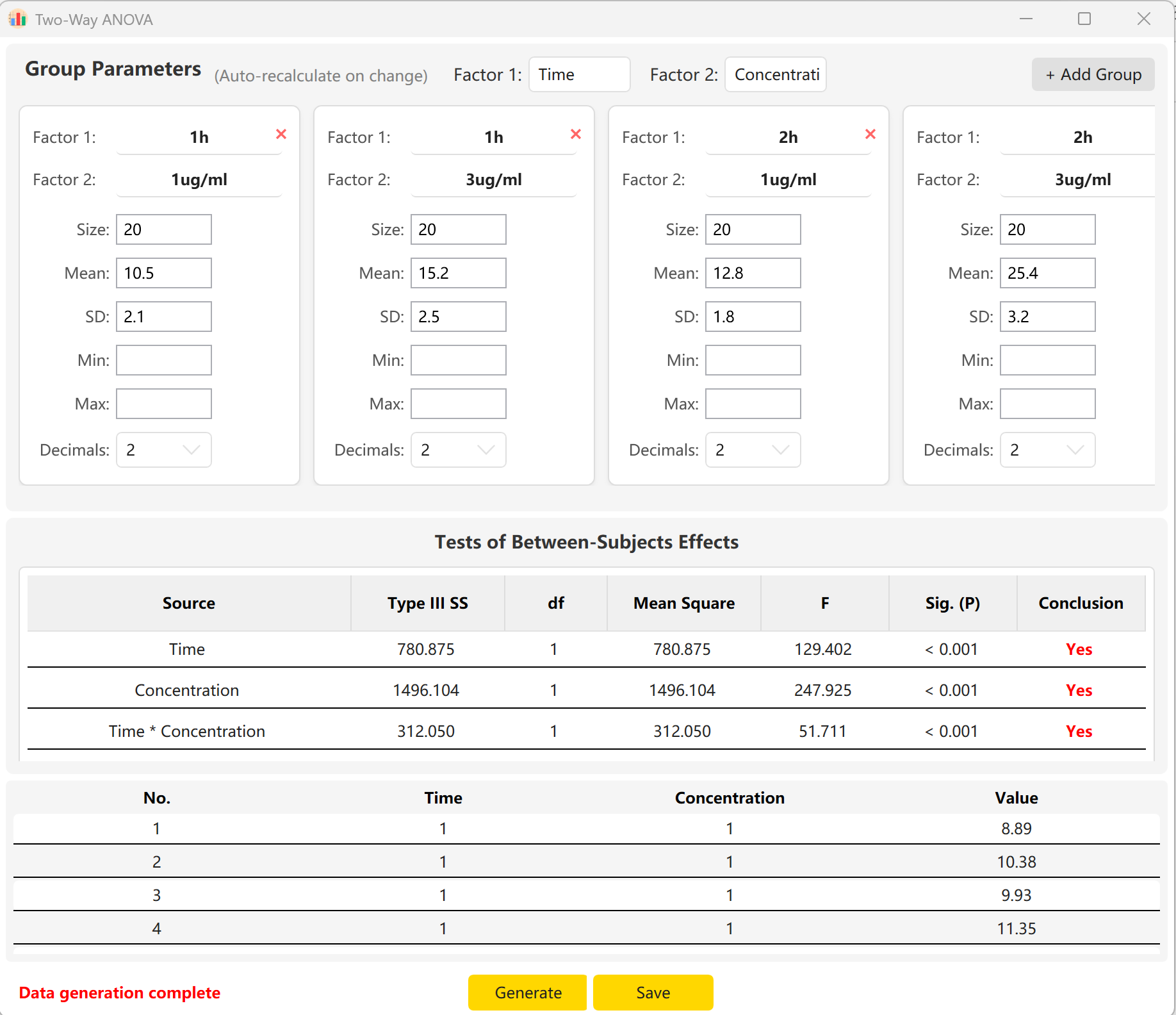
図6.2: 二元配置分散分析データの表示
7. 一元配置反復測定分散分析
対応のあるT検定を3つ以上の時点に拡張したものです。長期間にわたる縦断的追跡に最適です(例:ベースライン、1ヶ月後、3ヶ月後)。
7.1 ワークフロー
Analyze → ANOVA → Repeated Measures ANOVA に移動します。ワークスペースのレイアウトは以下のとおりです。
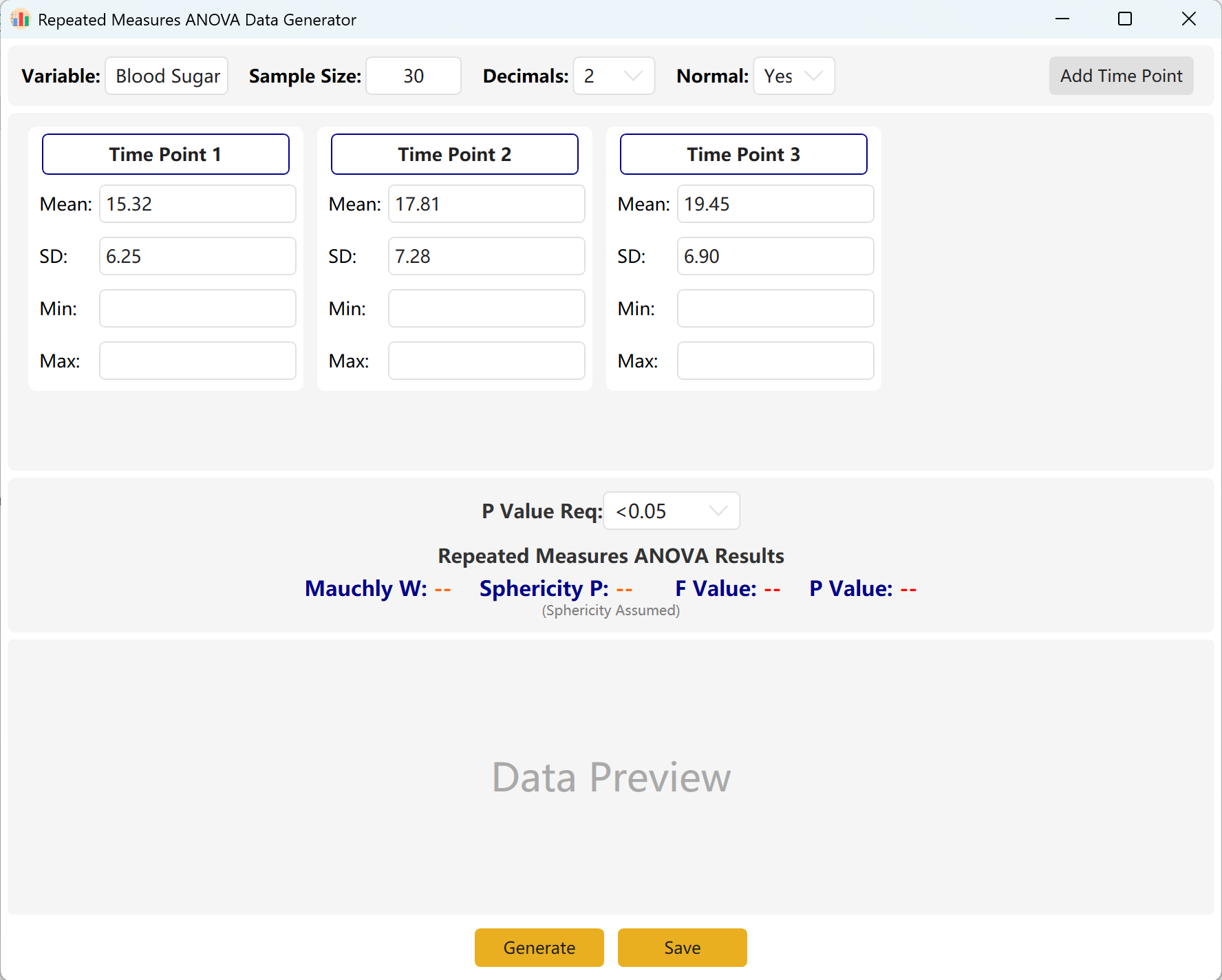
図7.1: 一元配置反復測定分散分析の設定
7.2 反復観測
システムはデフォルトで3つの観測時点を使用します。Add Time Point ボタンをクリックして簡単に拡張できます。各時点の平均と標準偏差を入力し、目標のp値範囲を定義します。
Generate ボタンをクリックして、準拠した値を合成します。
エンジン圧縮: 時点間の差が数学的に大きく(非常に有意なp値を示す)、目標範囲がp > 0.05に設定されている場合、エンジンは自動的に時点間の分散と平均差を圧縮して、正確な目標p値を満たします。ポップアップダイアログに合成データセットの実際の統計情報が表示されます。
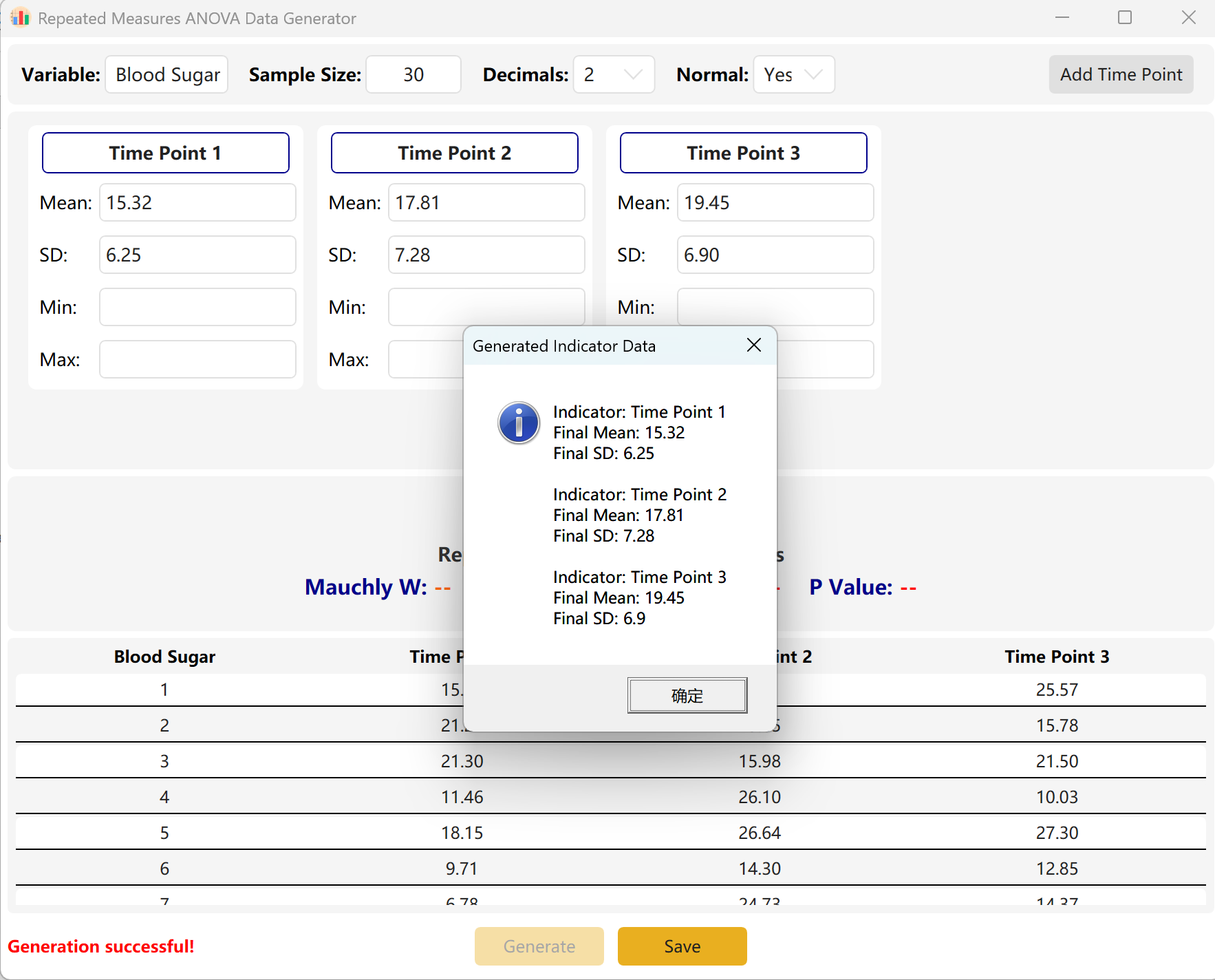
図7.2: 反復測定分散分析データの表示
8. 2つの独立標本の順位和検定(ノンパラメトリック)
正規性の仮定を満たさないデータに対するマン・ホイットニーのU検定の代替手段です。連続変数または順序変数における順位ベースのロジックに基づいて中央値の差を評価します。
8.1 ワークフロー
Analyze → Non-parametric → 2 Independent Samples に移動します。設定ワークスペースは以下のとおりです。
1.png)
図8.1: 2つの独立標本の順位和検定の設定
8.2 設定
プログラムはデフォルトで2つの参照グループを設定します。ノンパラメトリック手法は非正規分布データ向けに設計されているため、Normal Distributionオプションはデフォルトで No に設定されています。マン・ホイットニーのU検定を使用して、目標のp値範囲を定義できます。Generate ボタンをクリックして、統計的にこの閾値に準拠する生データを合成します。
順位和生成ロジック: ノンパラメトリック検定は、すべての観測値をプールして順位を割り当てることによりグループ間の差を分析します。したがって、2つのグループの設定パラメータが大きく異なり(自然に非常に小さなp値が得られる)、目標がp > 0.05に設定されている場合、エンジンは自動的にグループ間の乖離を減らして目標を満たします。最終的な計算平均と標準偏差はポップアップダイアログに表示されます。
2.png)
図8.2: 2つの独立標本の順位和検定データの表示
9. クラスカル・ウォリス検定(K個の独立標本ノンパラメトリック)
クラスカル・ウォリスのH検定と同等です。3つ以上の独立したグループにわたって、順序データまたは非正規分布の連続データを生成します。
9.1 ワークフロー
Analyze → Non-parametric → K Independent Samples に移動します。設定ワークスペースは以下のとおりです。
1.png)
図9.1: クラスカル・ウォリス検定の設定
9.2 マルチグループ順位付け
プログラムはデフォルトで3つの参照グループを設定し、クラスカル・ウォリス検定を実行します。2グループテストと同様に、計算はプールされたデータセットの順位に基づいているため、設定されたマルチグループパラメータに大きな矛盾があり(非常に有意なp値が得られる)、目標がp > 0.05に設定されている場合、シミュレーションエンジンは自動的にグループ間の差を圧縮します。結果の統計情報はポップアップウィンドウに要約されます。
2.png)
図9.2: クラスカル・ウォリス検定データの表示
10. 四分位データの生成
順位付けされたデータセットを4つの等しい部分に分割します。データの散布度と中心傾向の評価、中央値の強調、外れ値の検出に役立ちます。
10.1 ワークフロー
Analyze → Quartile Data に移動します。レイアウトは以下のとおりです。
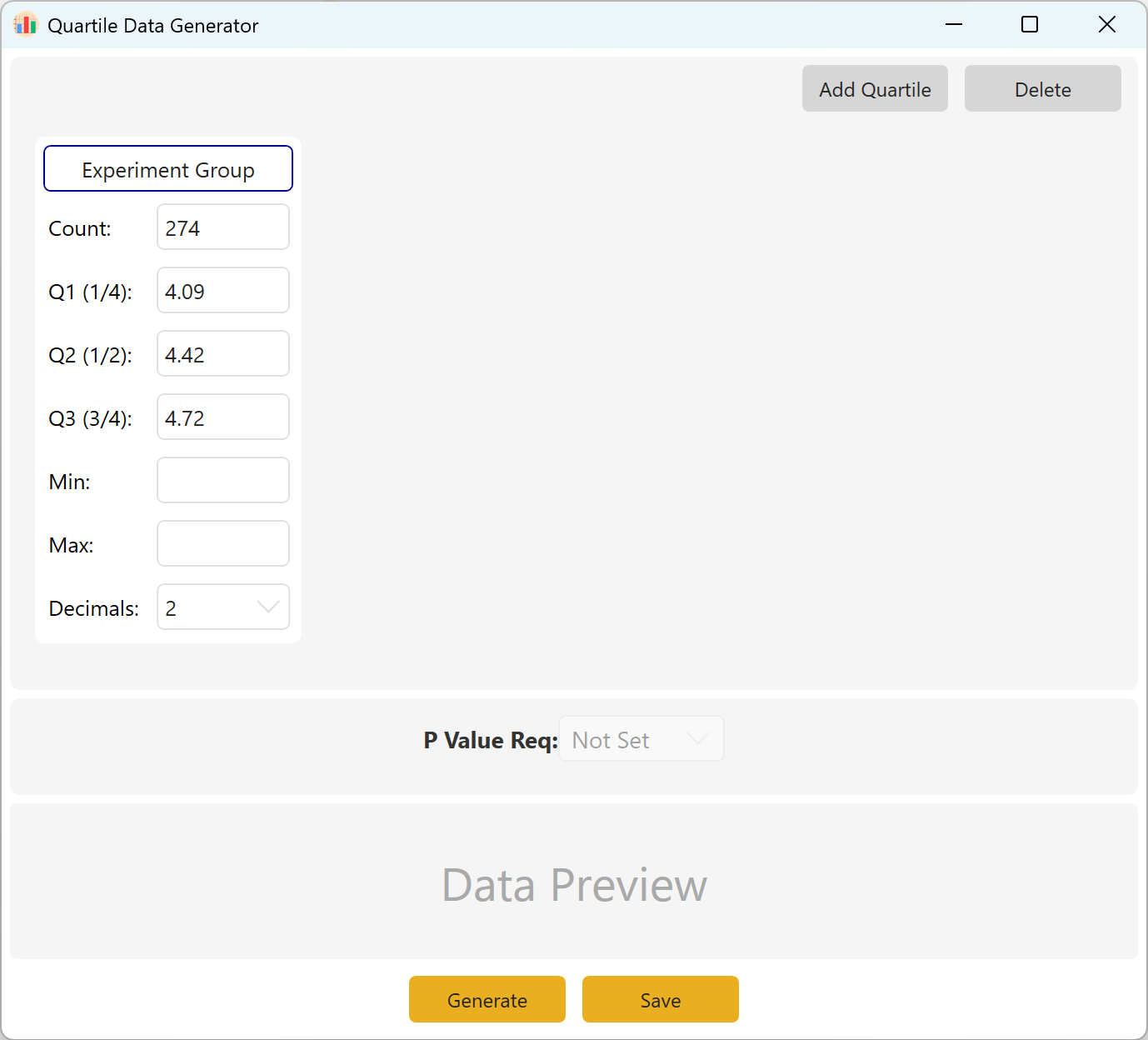
図10.1: 四分位データの設定
10.2 パラメータ定義
目標のサンプルサイズ、Q1(25パーセンタイル)、Q2(中央値/50パーセンタイル)、Q3(75パーセンタイル)を定義します。特定の制約がない場合は、最小値/最大値の境界は空白のままにできます。小数点精度を選択し、Generate ボタンをクリックして、これらの正確な四分位境界を満たす観測値を生成します。
要約: Q1、Q2、Q3のサンプルサイズと目標値を設定します。オプションパラメータには最小値、最大値、小数点以下の桁数が含まれます。Generate ボタンをクリックして、目標の四分位構造に一致する生データを計算して表示します。マルチグループ設定では、グループ間の目標p値範囲も設定できます。
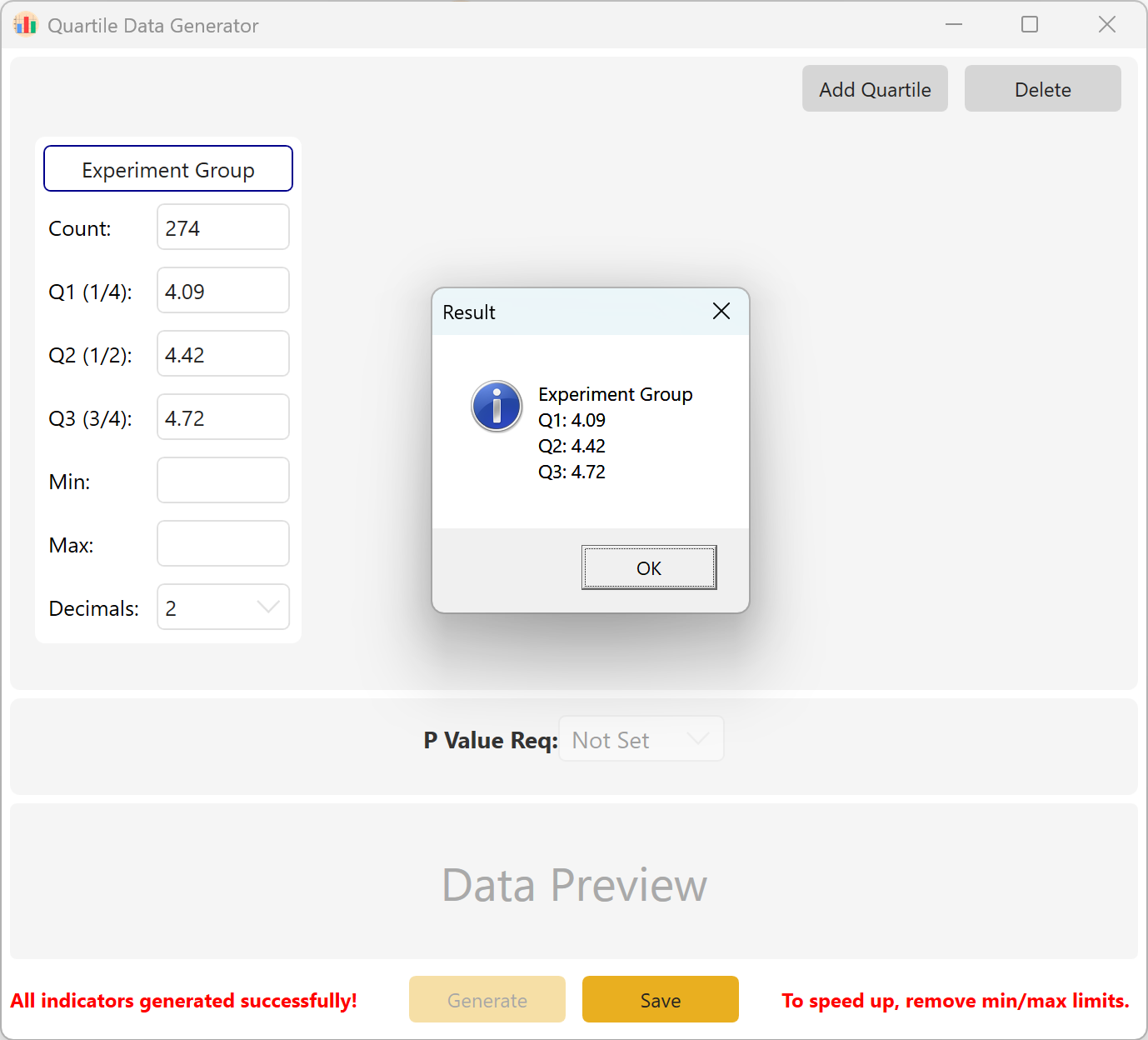
図10.2: 四分位データの表示
11. 二項ロジスティック回帰データの生成
結果が二値(DV=0またはDV=1)である分類問題に不可欠です。疫学におけるリスク因子の特定(例:疾患 vs. 健康)で非常に一般的です。
11.1 ワークフロー
Analyze → Regression → Binary Logistic に移動します。
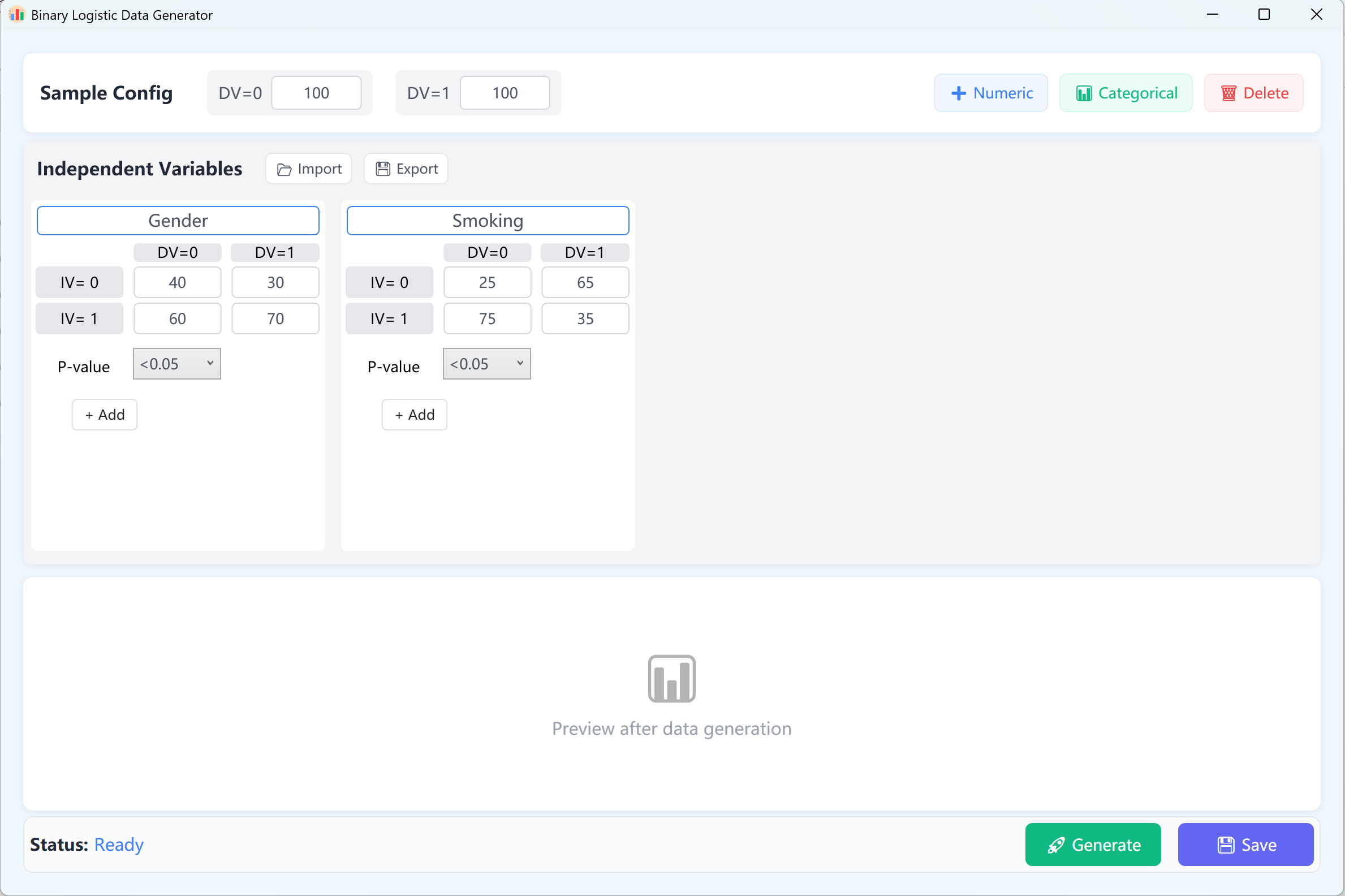
図11.1: 二項ロジスティック回帰の設定
11.2 設計
デフォルトでは、2つの連続独立変数が参照として設定されます。二項ロジスティックモデルでは、従属変数には正確に2つの結果(0と1)があります。したがって、従属変数は0と1のグループとして構成され、デフォルトではカテゴリあたり100ケースのサンプルサイズ(カスタマイズ可能)になります。
- 変数設定: + Numeric をクリックして連続独立変数(例:「年齢」、「BMI」)を追加します。変数名、平均、標準偏差、小数点以下の桁数、目標p値範囲(最終的なロジスティック回帰モデルで変数が達成する目標有意水準を指定)を入力します。最小値/最大値の制約はオプションです。
- 生成と検証: Generate ボタンをクリックして合成アルゴリズムを実行します。システムは反復的に、ロジスティック回帰モデルが設定と一致するp値を生成するデータセットを計算します。
IBM SPSSの書式と一致する詳細な回帰分析レポートが自動的に表示されます。このレポートを閉じると、プレビューテーブルに生データセットが表示され、Excelにエクスポートできる状態になります。
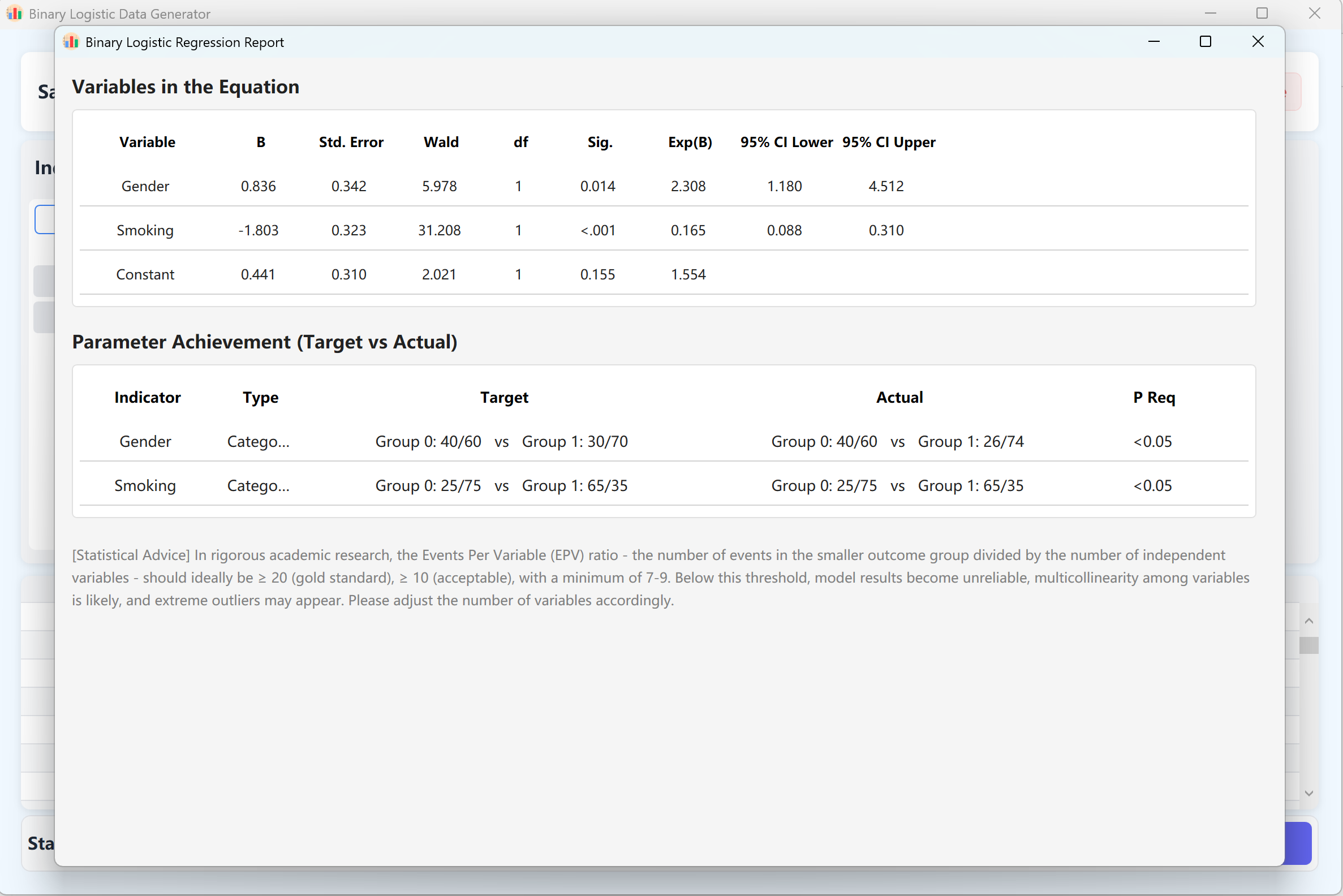
図11.2: 二項ロジスティック回帰データの表示
12. 重回帰データの生成
中核的な予測モデリングツールです。複数の独立変数(X)の影響を受ける連続従属変数(Y)を合成します。独立変数は、連続数値、四分位、順序カテゴリカル(順序)、または非順序カテゴリカル(名義)にすることができます。
12.1 ワークフロー
Analyze → Regression → Linear Regression に移動します。
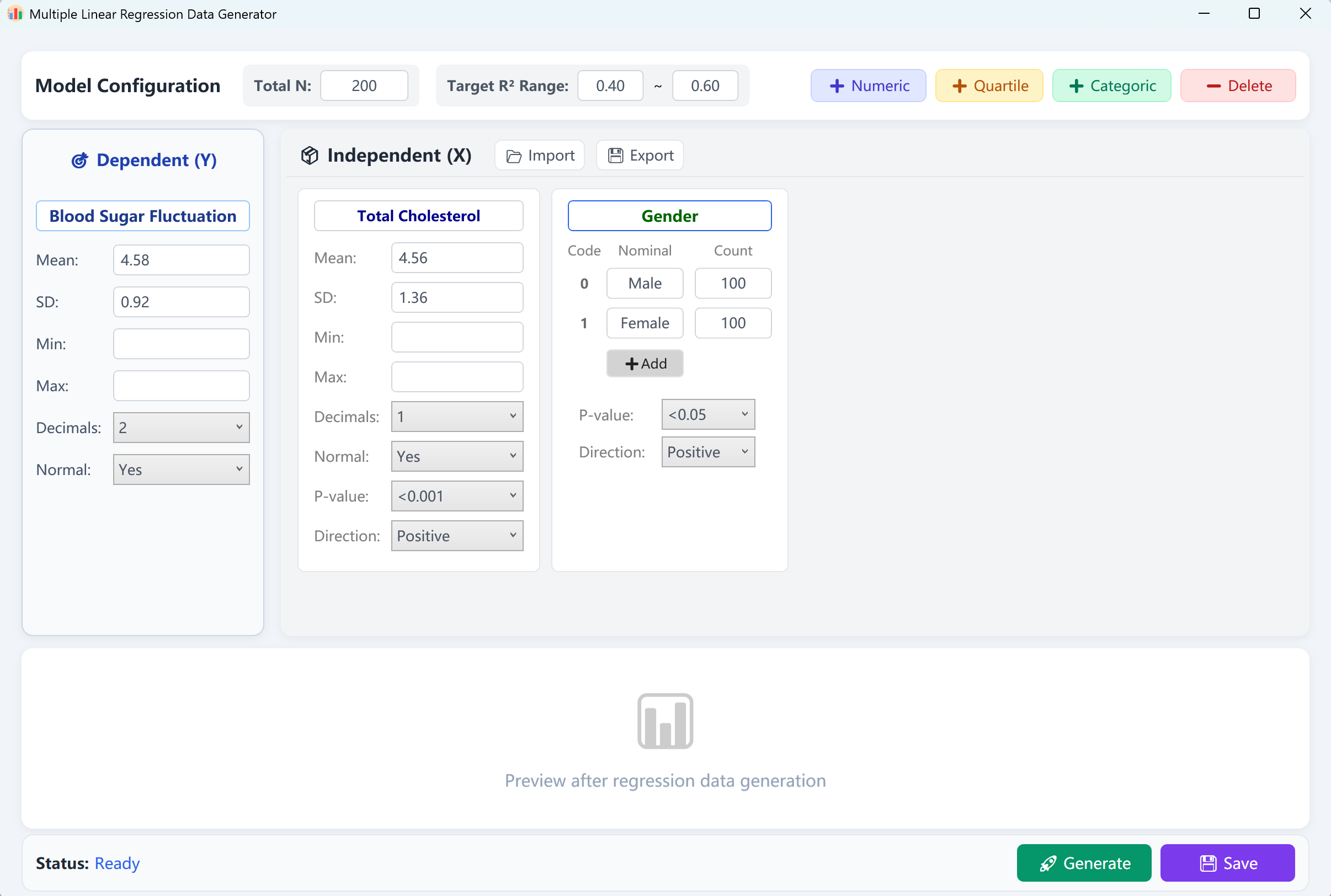
図12.1: 重回帰の設定
12.2 モデル設定
インターフェースは、連続従属変数(「血糖変動」)と2つの独立変数(数値の「総コレステロール」、カテゴリカルの「性別」)をデフォルトのサンプルサイズ200ケースで事前読み込みします。目標のR二乗(R²)範囲(例:0.4〜0.6)を設定できます。
Generate ボタンをクリックして回帰モデルを実行します。SPSS出力と一致する検証レポートが表示されます。このレポートを閉じると、生データプレビューテーブルに戻り、Excelスプレッドシートとして保存できます。
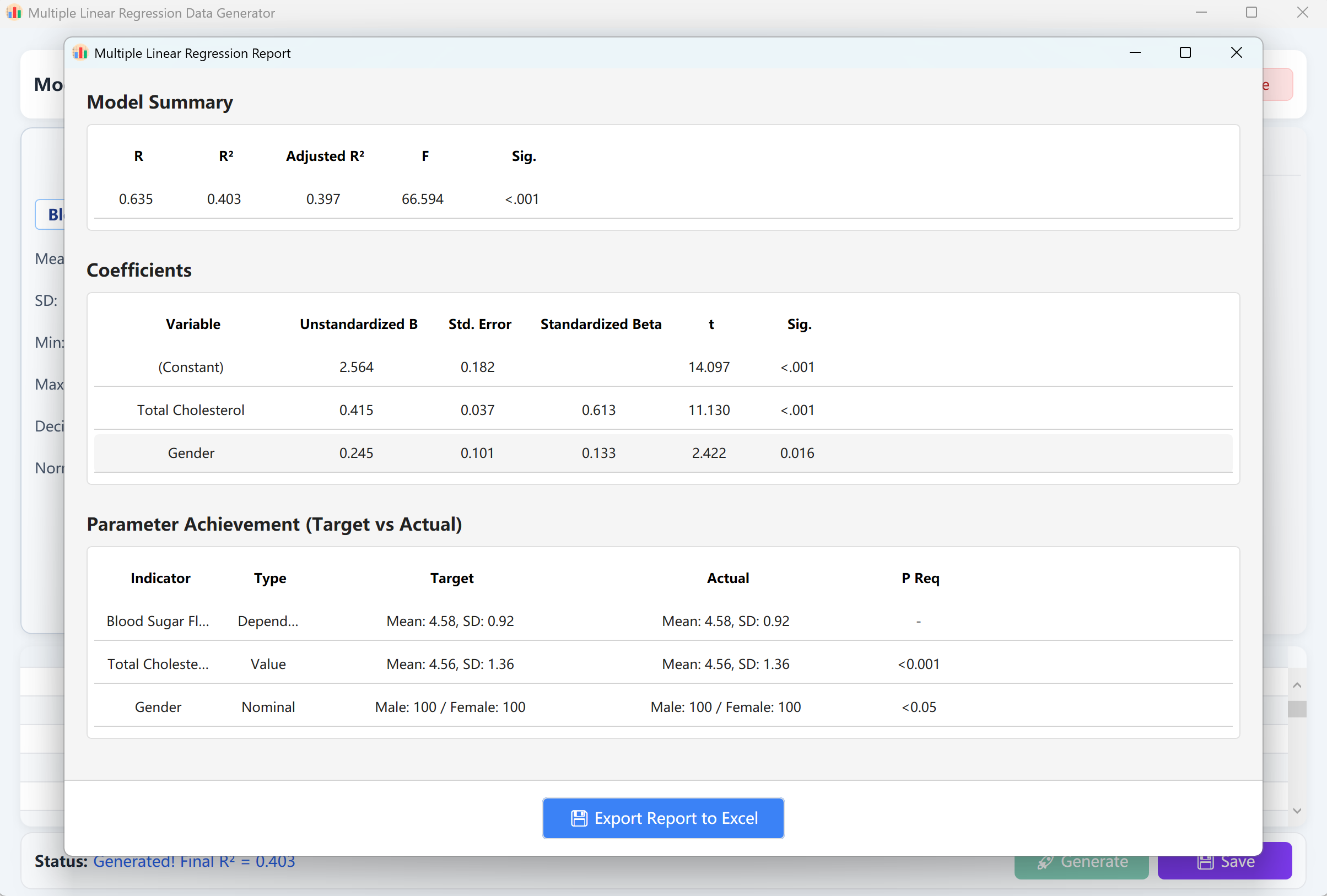
図12.2: 重回帰データの表示
13. コックス比例ハザード回帰データの生成
生存分析のゴールドスタンダードです。右側打ち切りを考慮したイベント発生日時データをシミュレートし、研究者が共変量が生存時間に及ぼす影響を評価できるようにします。
13.1 ワークフローと技術ガイドライン
Analyze → Regression → Cox Regression に移動します。
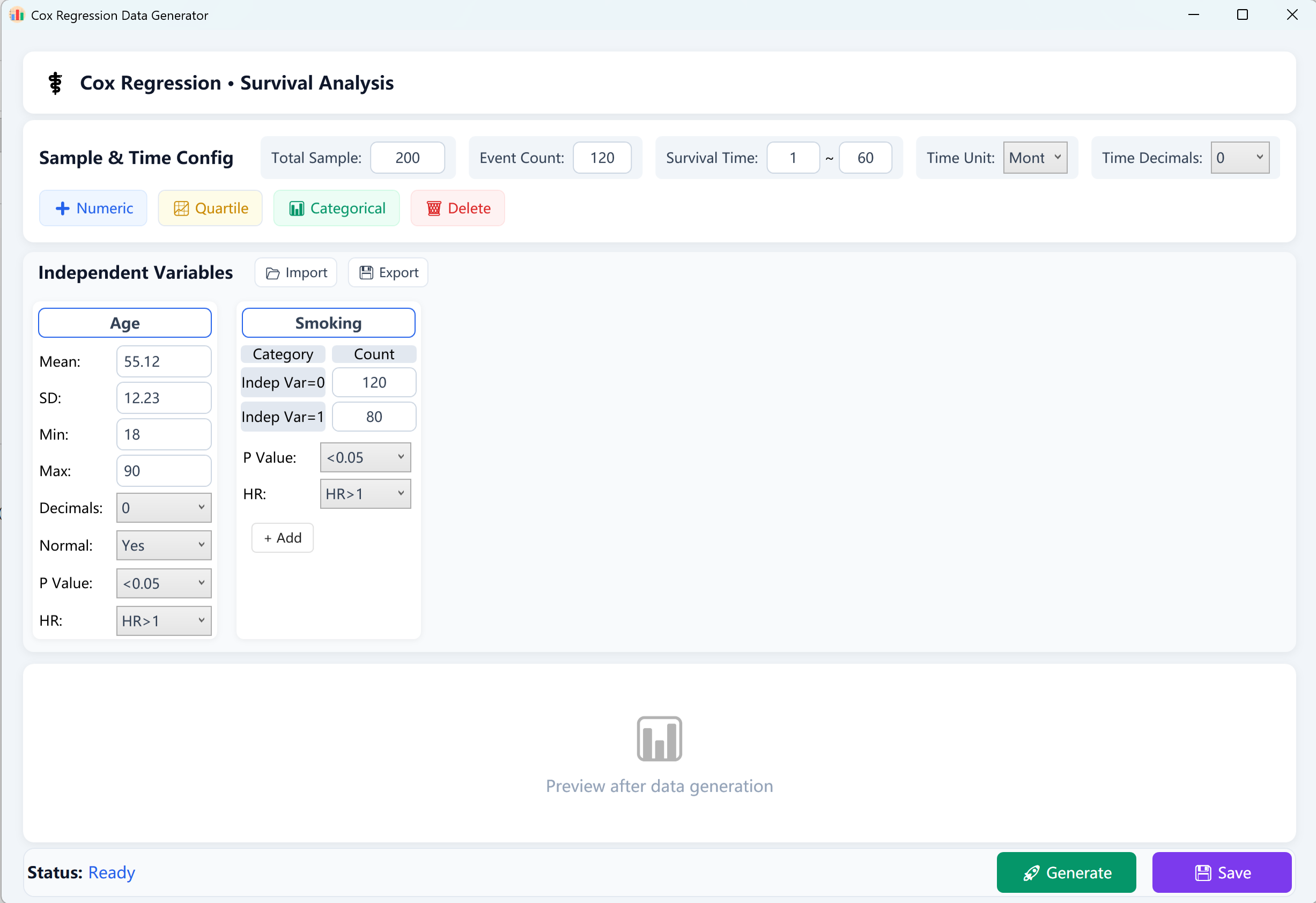
図13.1: コックス比例ハザード回帰の設定
- 総サンプルサイズ(N): 被験者/患者の総数(例:200被験者)。
- 観測イベント(結果イベント): 追跡期間中に最終結果(例:死亡、再発、イベント失敗)を経験した陽性症例の数。注:イベント数は総サンプルサイズより厳密に小さくなければなりません。
- 生存時間範囲(T): 生存期間の[最小追跡]から[最大追跡]の範囲を定義し(例:1〜60ヶ月)、時間を日、月、年でラベル付けし、数値の小数点精度を定義します。
統計的EPVルール(変数あたりのイベント数): コックス比例ハザードモデルの数学的安定性と信頼性を保証するには、観測された結果イベント数と独立変数の数(EPV)の比率が少なくとも10〜20であることが強く推奨されます。モデルが収束しない場合は、総サンプルサイズまたは観測イベント数のいずれかを増やしてみてください。
13.2 研究変数の構築
変数カードの下部にある対応するボタンをクリックして、独立共変量を構築します:
- 連続数値変数: + Numeric をクリックして連続共変量(例:年齢、BMI、臨床バイオマーカー)を追加します。平均、標準偏差(必須)、およびオプションで外れ値の制限と小数点精度のための最小値/最大値の境界を入力します。
- カテゴリカル変数: + Categorical をクリックして名義/順序共変量(例:性別、満足度スコア)を追加します。各カテゴリの正確な目標頻度を入力します。注:すべてのカテゴリのカウントの合計は、実行するために総サンプルサイズと厳密に等しくなければなりません。
- 四分位変数: + Quartile をクリックして四分位構造の変数を追加し、Q1、Q2(中央値)、Q3の目標パラメータを入力します。
目標パラメータ: すべての変数カードには、下部に2つの強力な目標パラメータが含まれています:
- 回帰p値: 有意目標を選択します(例:p > 0.05、p < 0.05、p < 0.01、またはp < 0.001)。
- ハザード比(HR)の方向: HR > 1(リスク因子、ハザード率の増加を示す)またはHR < 1(保護因子、ハザード率の減少を示す)のいずれかを選択します。
13.3 データ生成の実行と保存
すべてのパラメータが入力されたら、ウィンドウの下部にある Generate ボタンをクリックします。バックエンドは高度に並行した反復シミュレーションを実行します。IBM SPSSで計算された正確な統計とスタイルを反映した、信頼性の高い包括的なコックス比例ハザード回帰分析レポートが自動的に表示されます。
Save ボタンをクリックして、合成された生データセットをExcelファイルにエクスポートします。このファイルは検証のためにSPSSや他のプロフェッショナルな統計スイートに簡単にインポートできます。
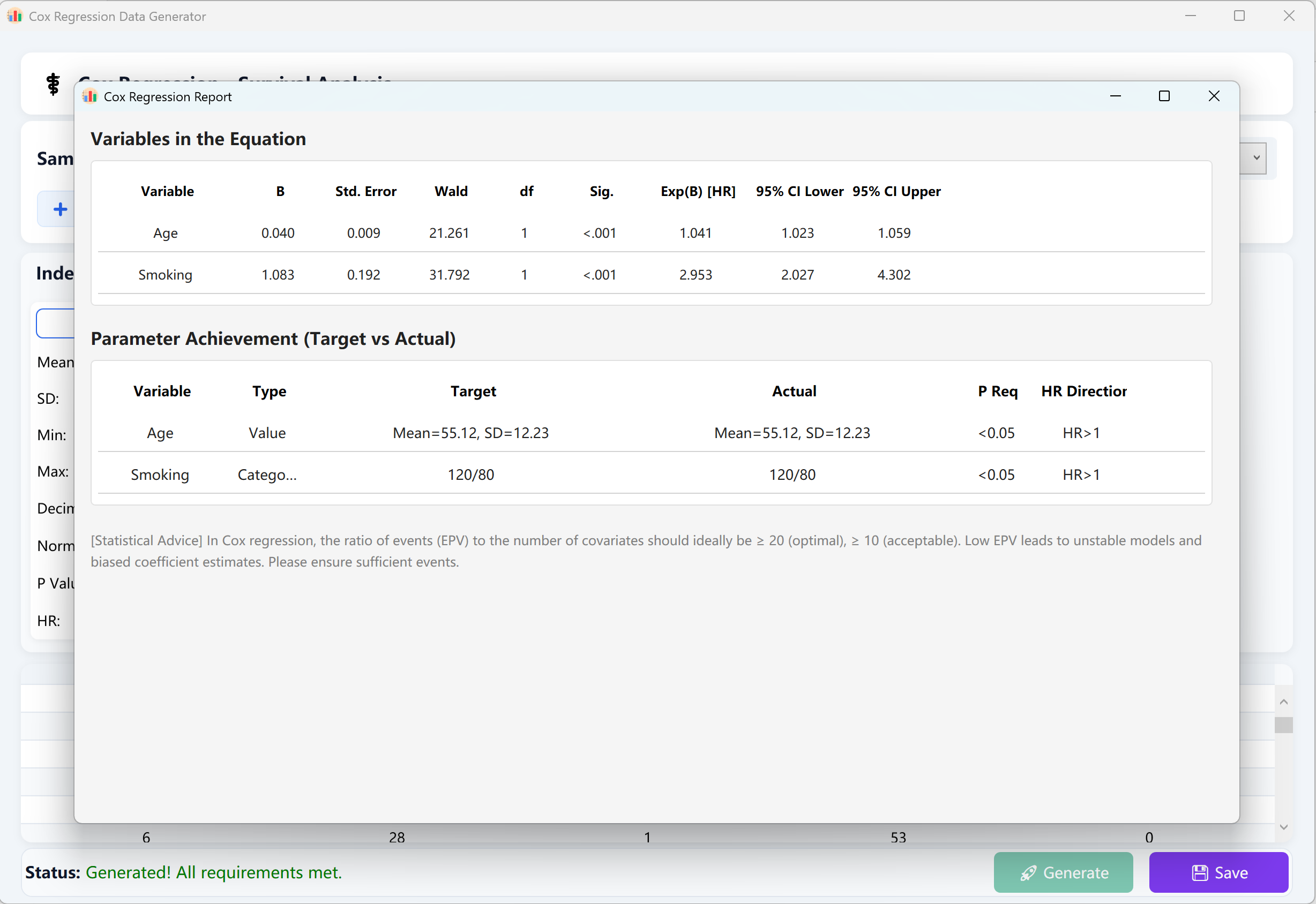
図13.2: コックス比例ハザード回帰データの表示
14. 相関分析のためのデータ生成
目標の相関係数(r値)と有意水準を強制することにより、二変量関係(PearsonまたはSpearman)および偏相関をシミュレートします。
14.1 ワークフロー
Analyze → Correlation に移動します。
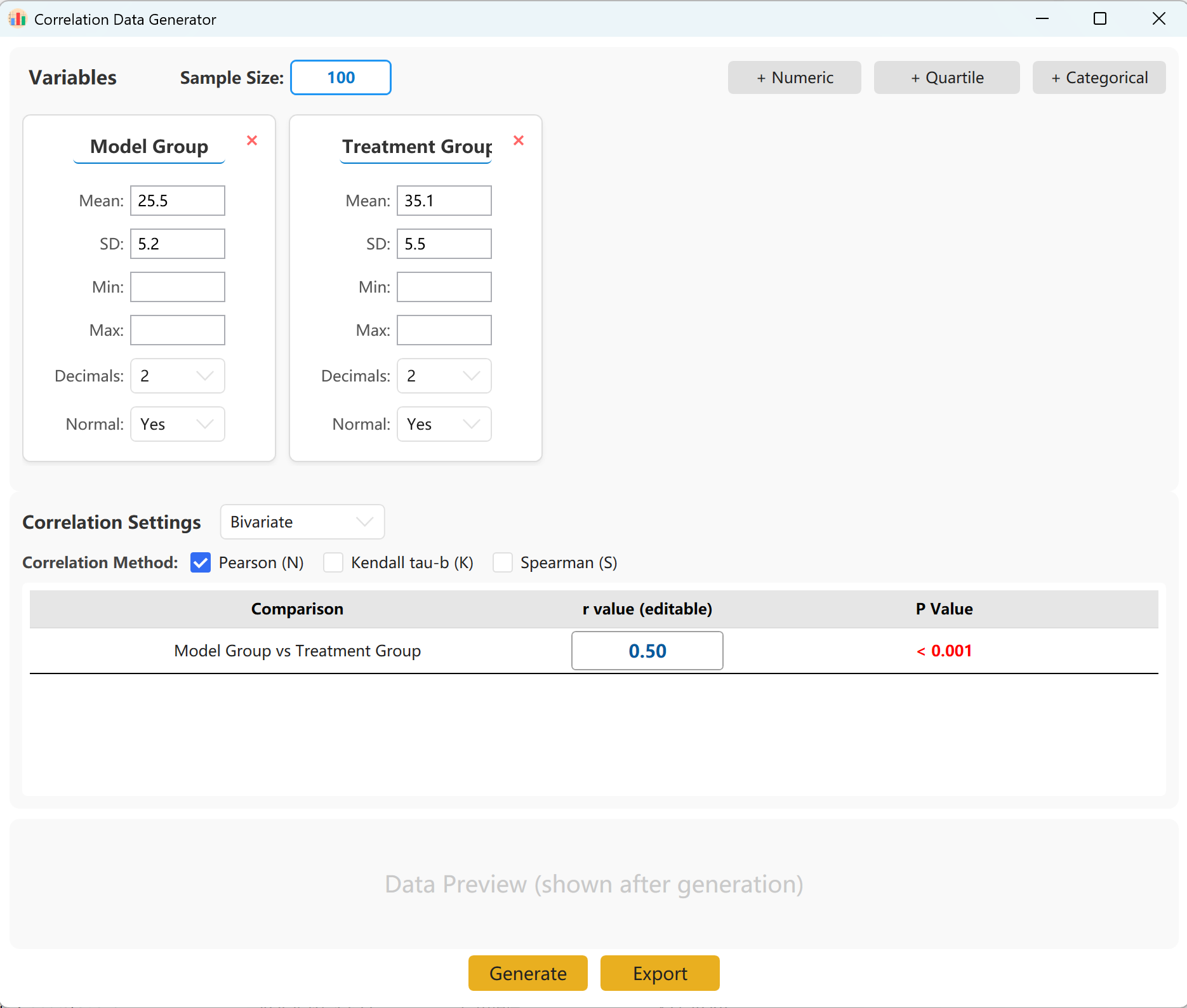
図14.1: 相関分析の設定
14.2 パラメータ
システムはクイックリファレンス用に2つの変数セットを事前読み込みします。連続(平均/SD)、四分位、カテゴリカル形式をサポートする変数を簡単に追加できます。設定パネル内で、各指標のサンプルサイズ、平均、標準偏差を指定します(最小値/最大値の制限はオプションです)。
グループ間の正確な目標相関係数(r)を指定できます。Generate ボタンをクリックしてシミュレーションを実行し、結果の相関行列をポップアップウィンドウに表示します。その後、Excelファイルとしてエクスポートできます。
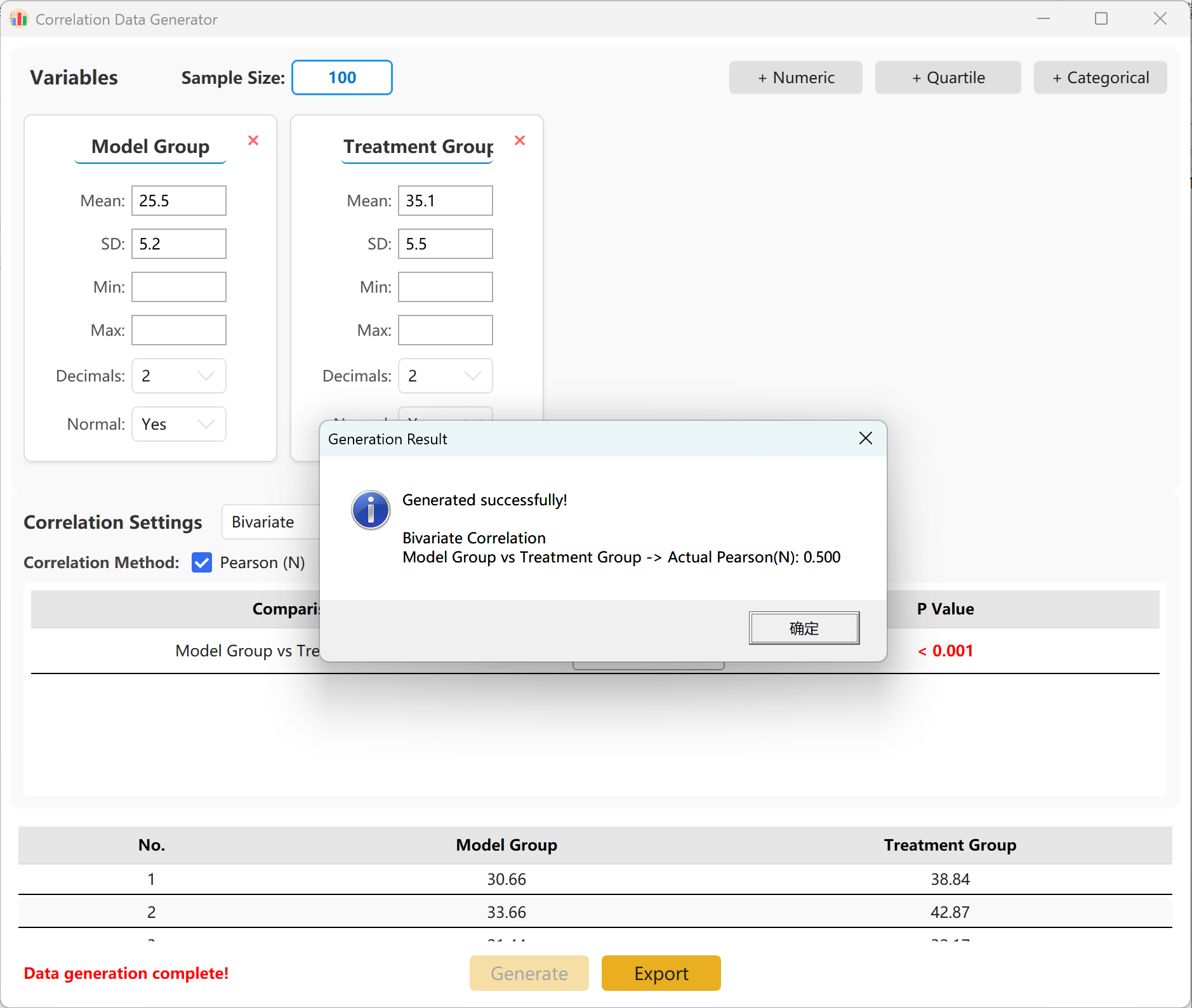
図14.2: 相関分析データの表示
15. ROC曲線分析のためのデータ生成
連続またはカテゴリカルのテスト変数が2つの状態(例:陽性 vs. 陰性診断)を区別する診断能力を評価します。
15.1 ワークフロー
Analyze → ROC Curve に移動します。
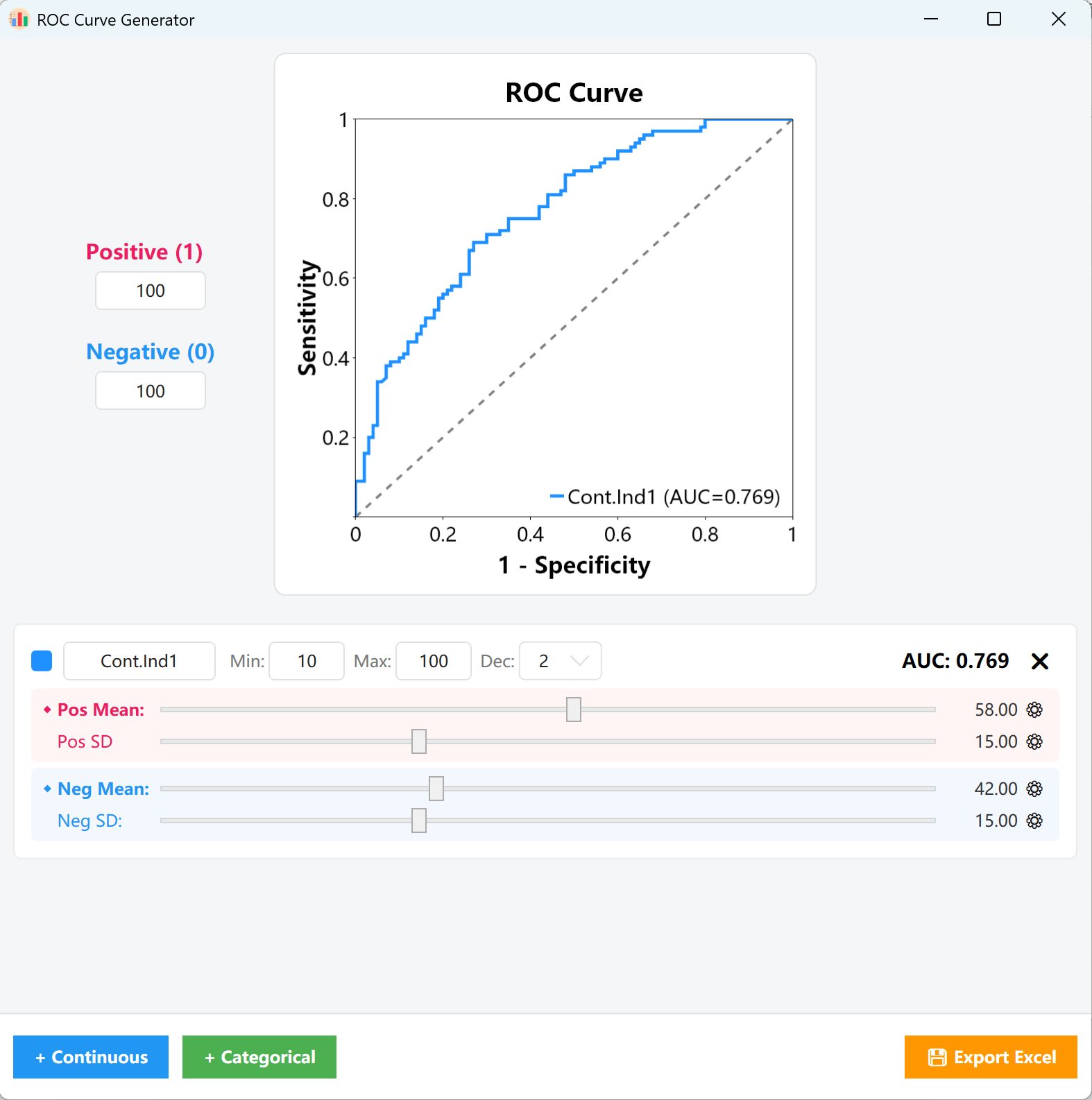
図15.1: ROC曲線設定
比率: 左側のパラメータパネルで、陽性サンプル(1)と陰性サンプル(0)の目標ケース数を入力します(例:100の陽性ケースと100の陰性ケース)。生成エンジンはこれらの比率に基づいて中核となる統計的サンプリング行列を構築します。
15.2 変数タイプ
左下の + Continuous または + Categorical をクリックして、対応する変数を作成します:
- 連続変数: カード上の変数名、最小値/最大値の範囲、目標の小数点以下の桁数をカスタマイズします。ピンクのスライダー(陽性グループ)と青のスライダー(陰性グループ)をドラッグして、それぞれの平均と標準偏差の分布を迅速に調整します。
- 精度調整: ビジュアルスライダーが必要な粒度に達しない場合は、パラメータの横にあるギアアイコンをクリックして、正確な浮動小数点値を手動で入力します。
- AUCの監視: この調整プロセス全体を通じて、カード右上のAUC = 0.XXXインジケーターと中央のプロットキャンバスが完全にリアルタイムで更新され、曲線を正確な目標カットオフに視覚的に合わせることができます。
- カテゴリカル変数: 陽性コホートと陰性コホートの正確な比率またはカウントを定義するだけです。ROC曲線とAUC値の対応する変化を即座に監視できます。
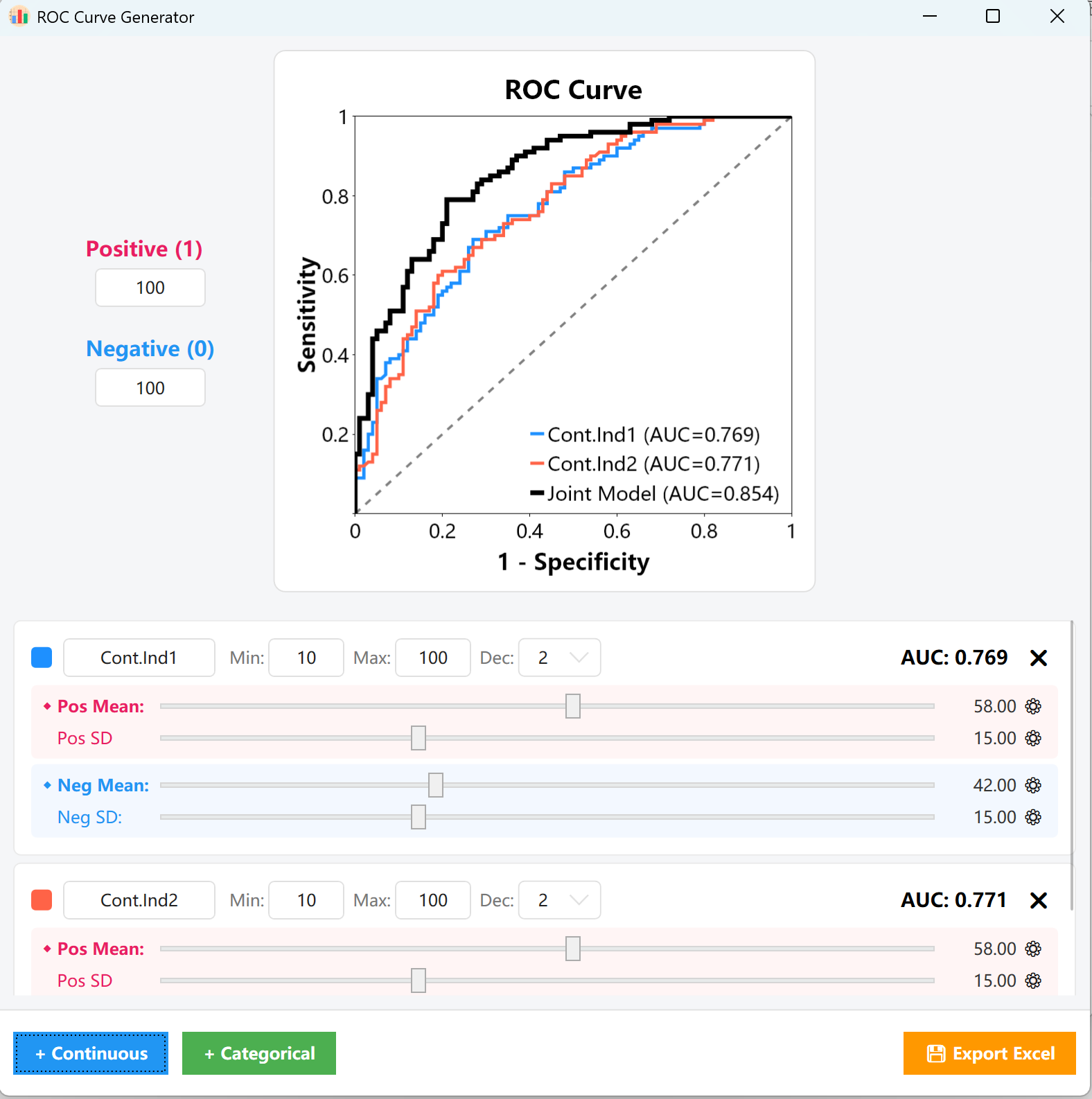
図15.2: ROC曲線プロットの表示
16. 設定パラメータの保存とエクスポート
反復的なモデリングタスクを効率化し、手動設定エラーを回避するために、アプリケーションは強力な組み込み設定状態保存メカニズムを提供します。
16.1 保存/復元
- 設定のエクスポート: File → Export Configuration に移動して、すべての設定パラメータ、変数定義、グループ構造、目標をローカルの`.json`設定ファイルとしてコンピュータに保存します。
- 設定のインポート: 将来のセッションで設定を復元するには、File → Import Configuration に移動し、以前保存した設定ファイルを選択します。ワークスペースはすぐにリロードされ、すべての変数カード、スライダー、パラメータ値を復元します。