Документация и руководство пользователя
Добро пожаловать в официальную документацию DataSynth Pro. Это подробное руководство содержит инструкции по настройке параметров для различных статистических модулей для синтеза надежных, академически обоснованных и статистически валидных наборов данных полностью офлайн.
1. Генерация нескольких показателей одновременно
1.1 Предварительные требования и запуск
Дважды щелкните исполняемый файл для запуска приложения. Программа требует Microsoft .NET 8.0 Runtime Framework. Если он не установлен на вашем компьютере, следуйте инструкциям для загрузки и установки, затем перезапустите программу.
Предупреждение безопасности: Если ваше антивирусное программное обеспечение помечает исполняемый файл как ложное срабатывание, добавьте его в список исключений или доверенных программ.
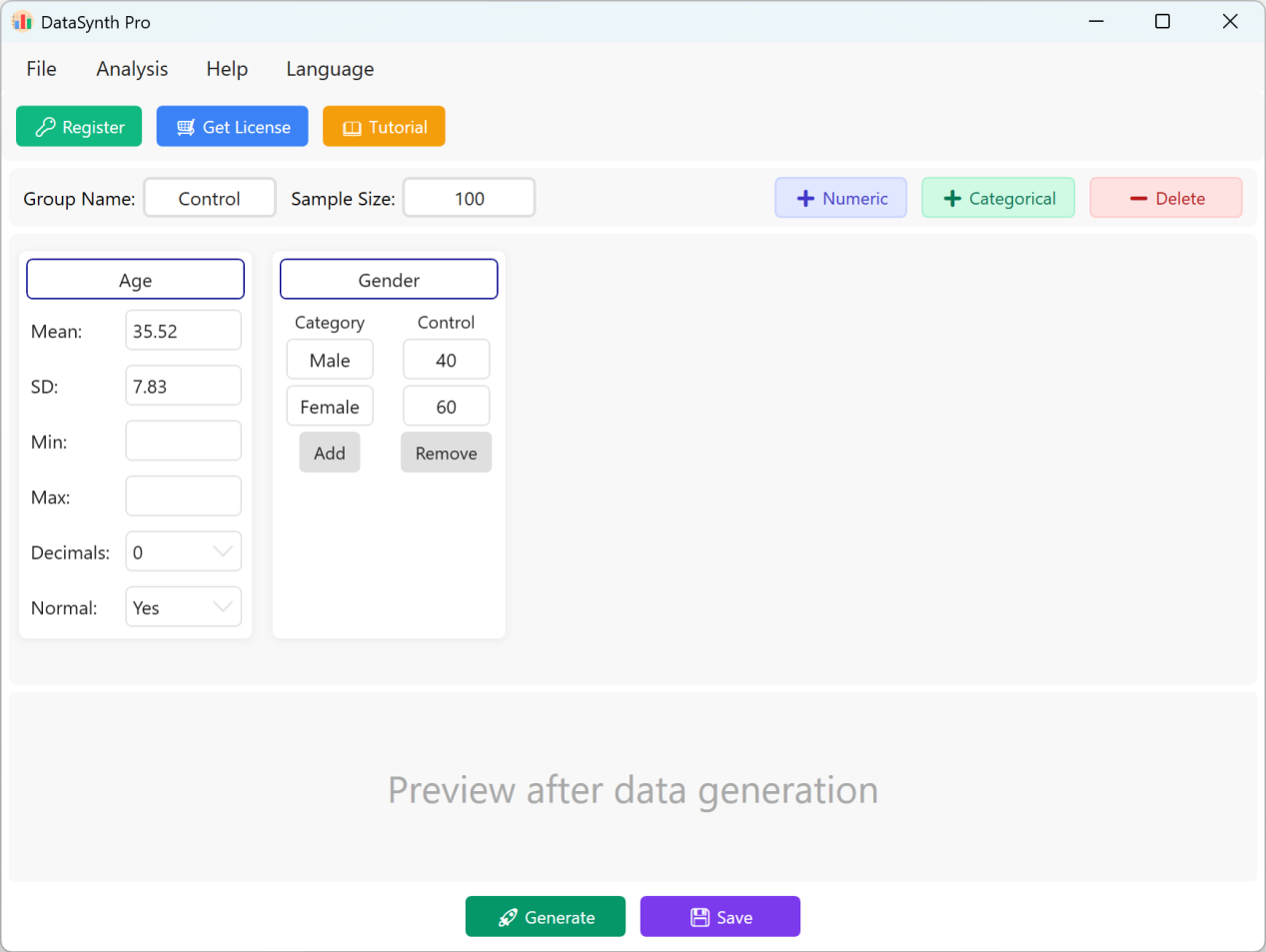
Рисунок 1.1: Главный интерфейс программы
1.2 Настройка параметров
По умолчанию приложение предварительно заполняет две непрерывные переменные: «Возраст» и «Пол» для быстрой справки. Группа по умолчанию называется «Контрольная группа», размер выборки установлен на 100 случаев. Если ваше исследование требует несколько групп, вы можете последовательно генерировать и экспортировать наборы данных для каждой группы, обновляя параметры для каждого запуска.
- Добавление непрерывных числовых переменных: Чтобы добавить новую количественную переменную, нажмите кнопку + Numeric. Затем укажите название показателя (например, «Индекс массы тела» или «ИМТ»), среднее значение, стандартное отклонение и количество десятичных знаков. Поля «Минимум» и «Максимум» необязательны.
- Настройки распределения данных: По умолчанию генерируемые числовые показатели следуют нормальному распределению. Если вам нужны данные с ненормальным распределением, установите опцию Normal Distribution в значение Нет.
Настройка распределения: Нормальное распределение основано на естественном диапазоне вариации; слишком строгие ограничения Минимума и Максимума обрежут нормальную кривую и могут привести к ненормально распределенным значениям.
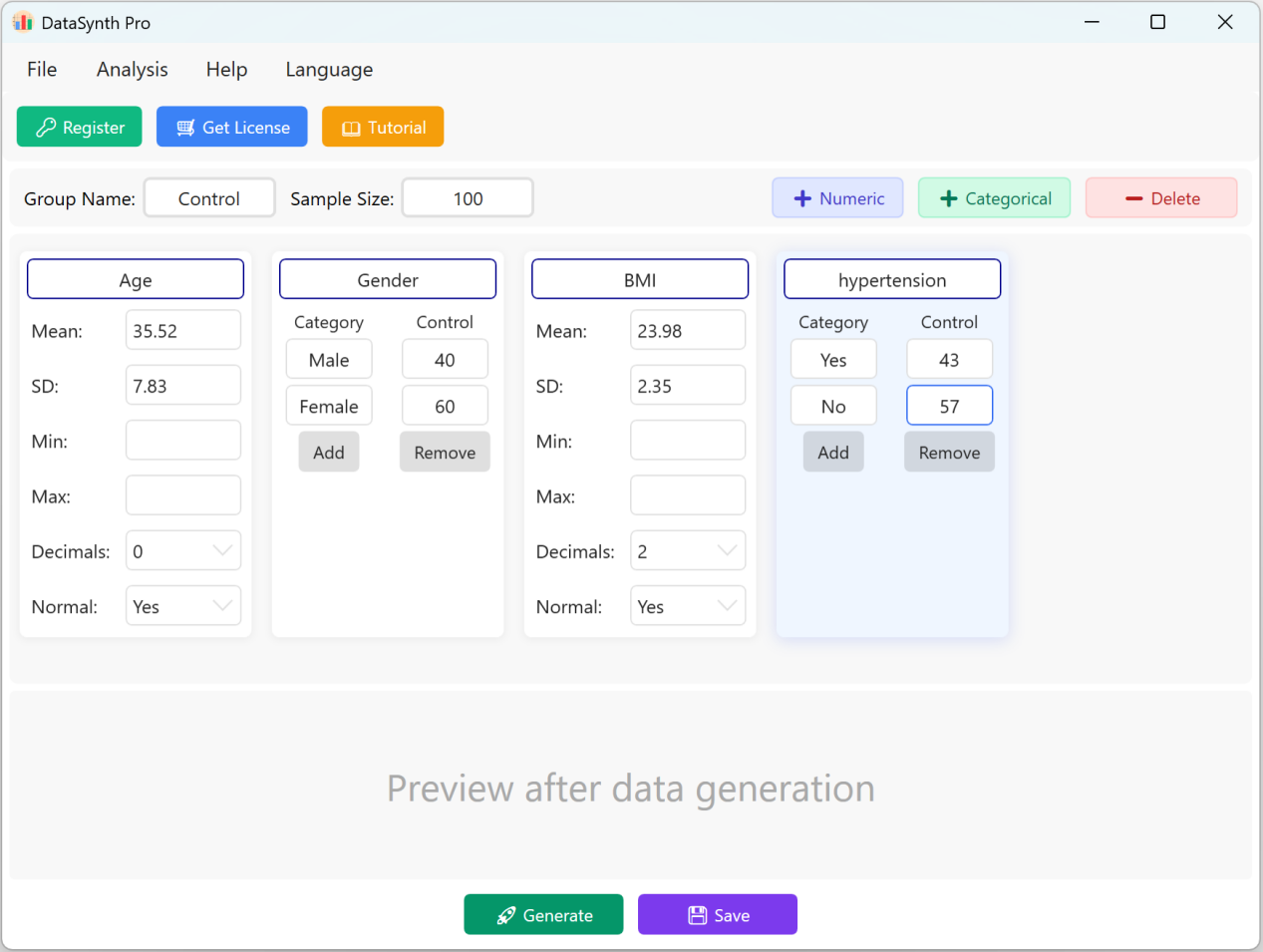
Рисунок 1.2: Добавление переменных
1.3 Добавление категориальных переменных
Нажмите кнопку + Categorical для добавления качественных переменных (например, «Гипертония»). Вы можете ввести названия категорий и соответствующие целевые распределения или пропорции.
1.4 Выполнение генерации
Нажмите кнопку Generate для синтеза заданного количества записей. После расчета появится окно сводной статистики, позволяющее проверить соответствие фактических сгенерированных значений заданным параметрам.
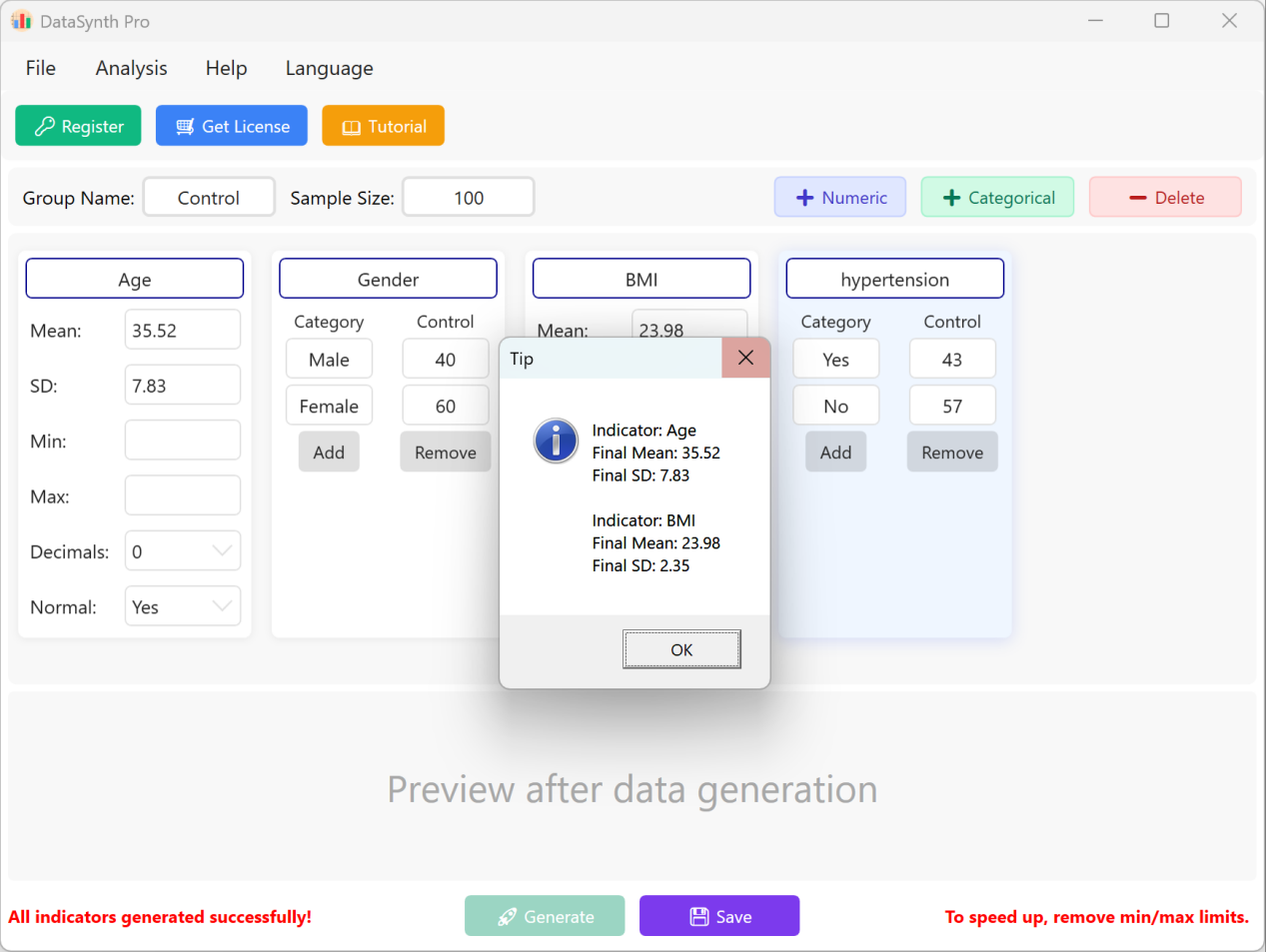
Рисунок 1.3: Выполнение генерации
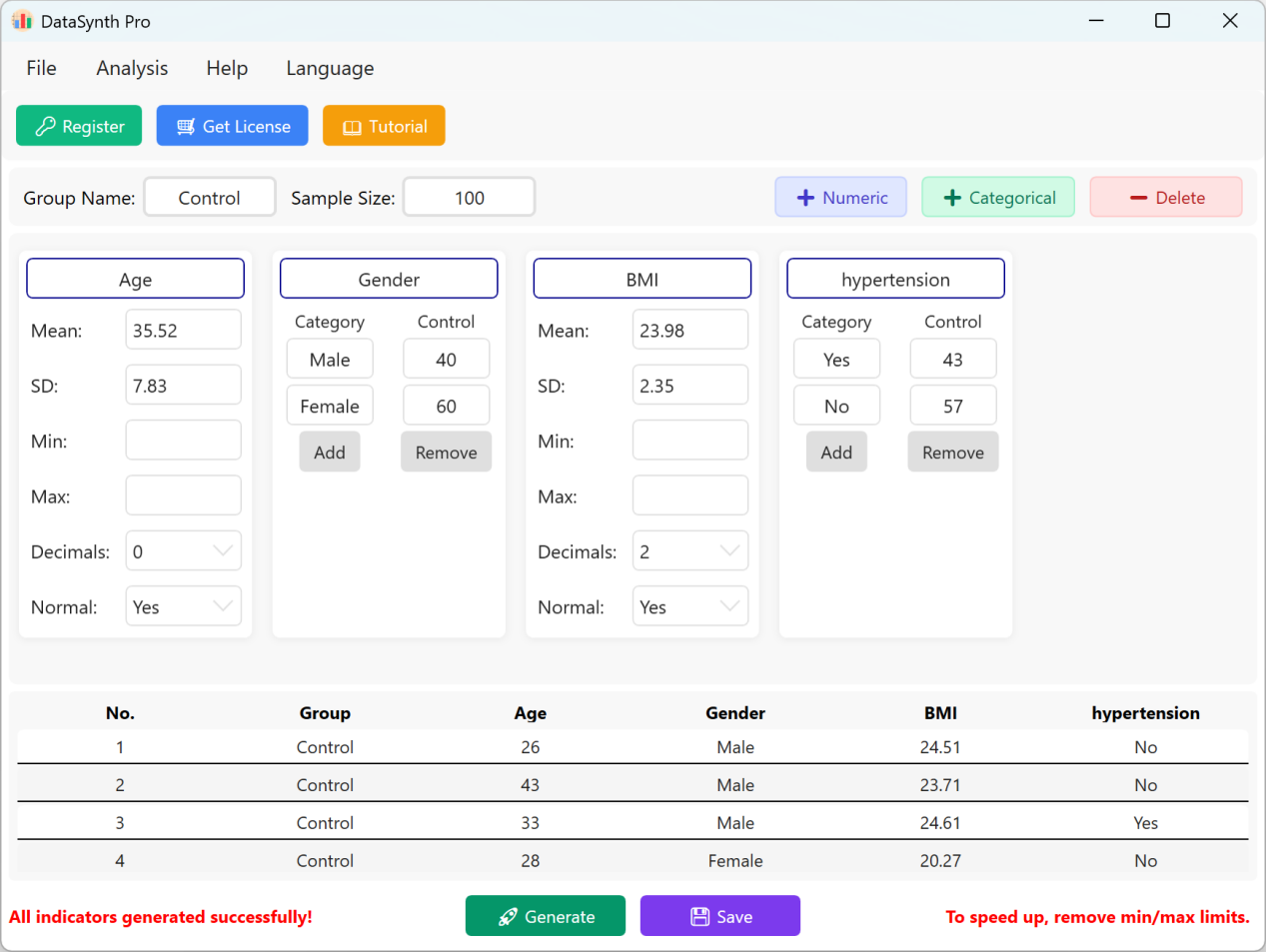
Рисунок 1.4: Отображение данных
1.5 Экспорт и проверка
Нажмите кнопку Save для экспорта сгенерированного набора данных в стандартный файл Excel.
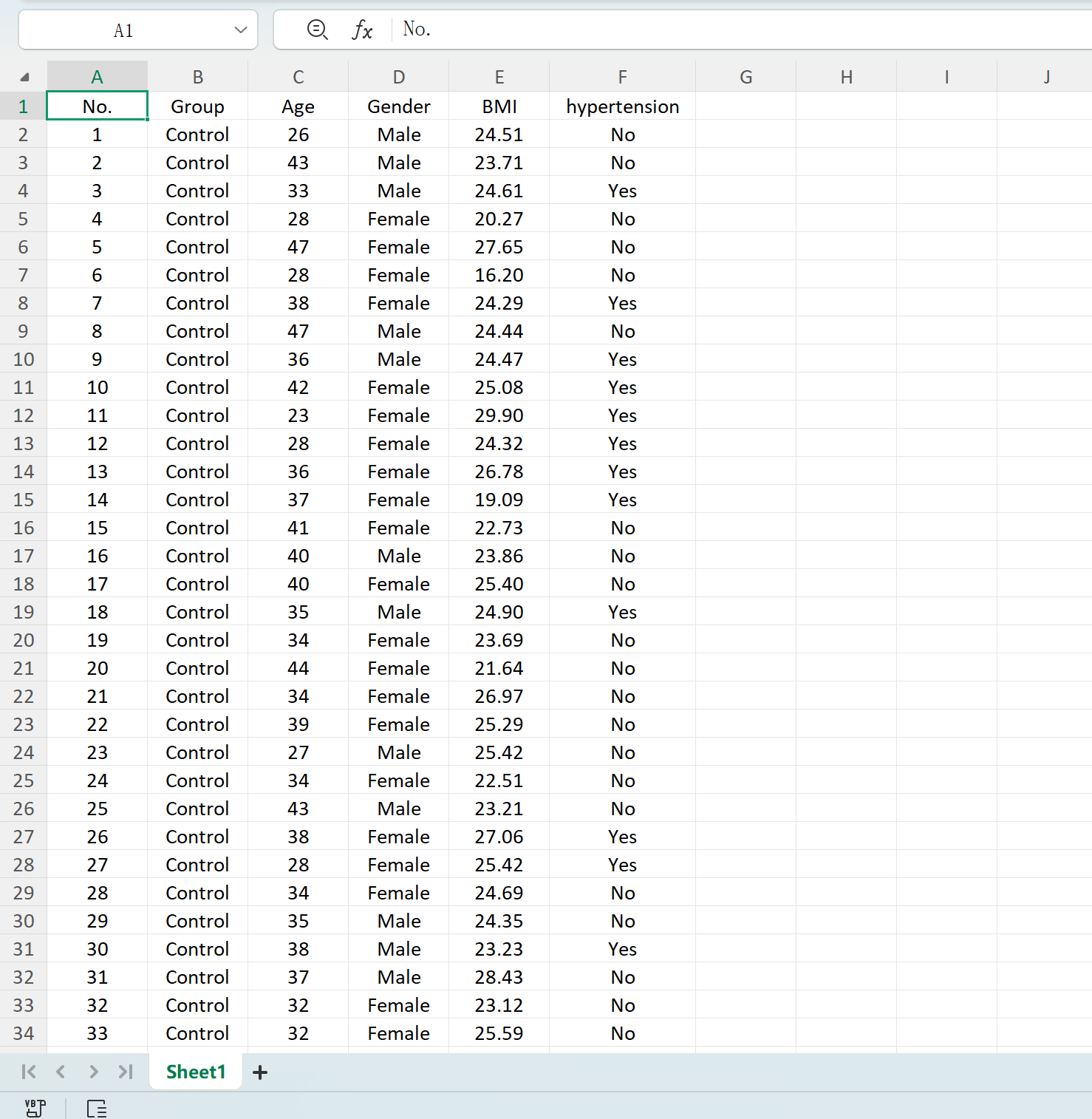
Рисунок 1.5: Экспорт таблиц в Excel
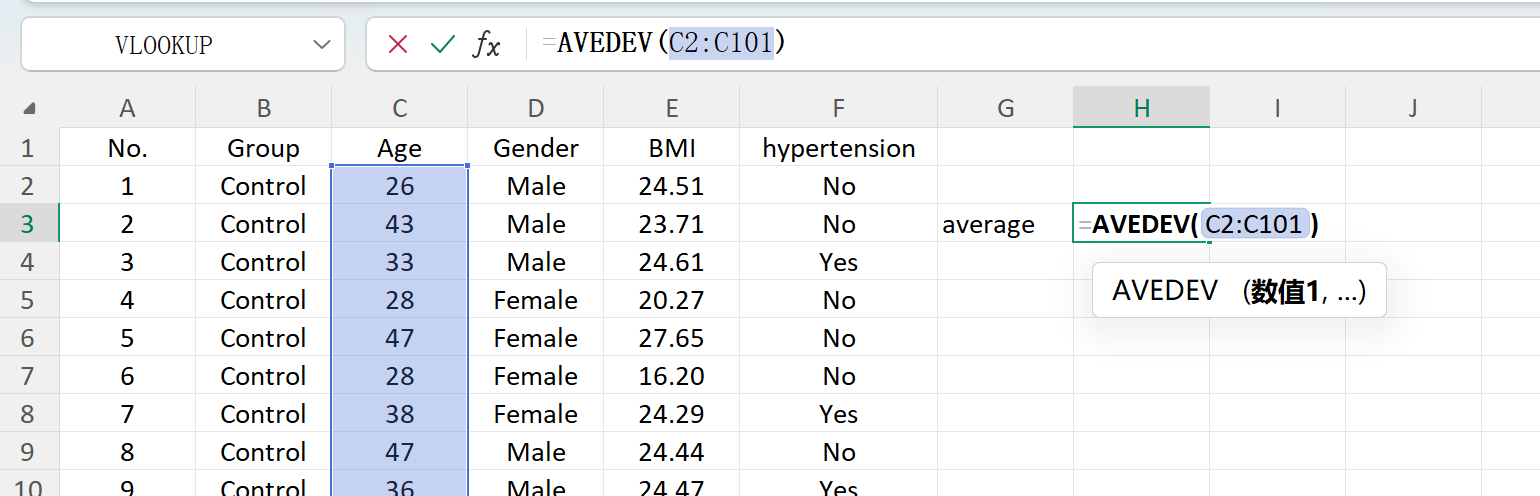
Рисунок 1.6: Вычисление среднего в Excel
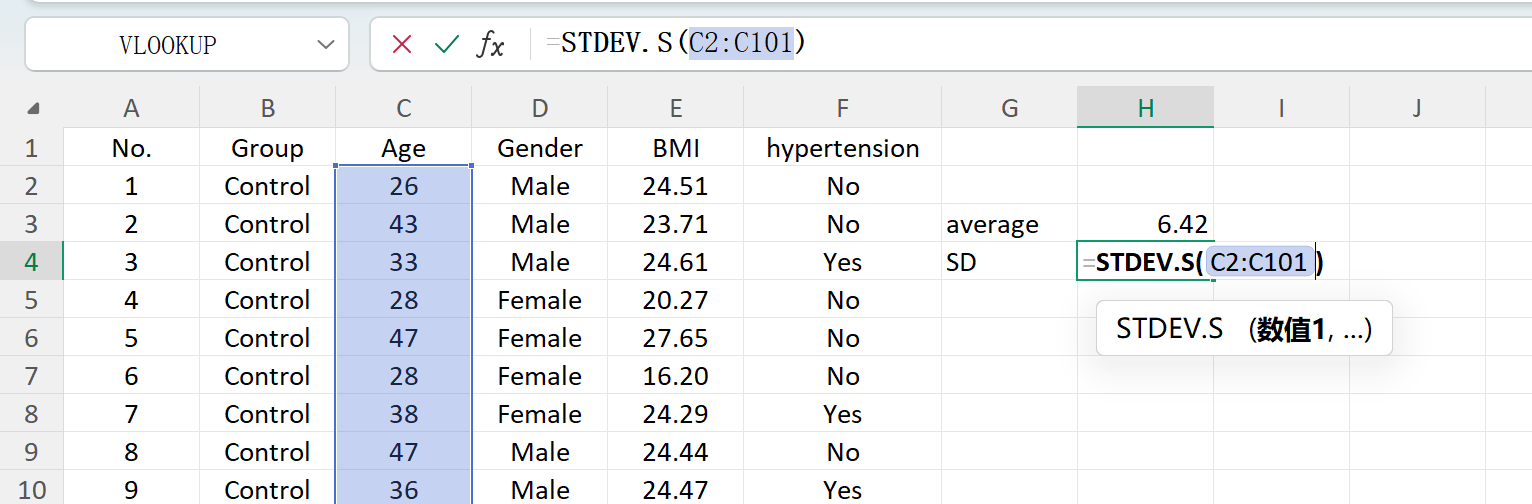
Рисунок 1.7: Вычисление стандартного отклонения в Excel
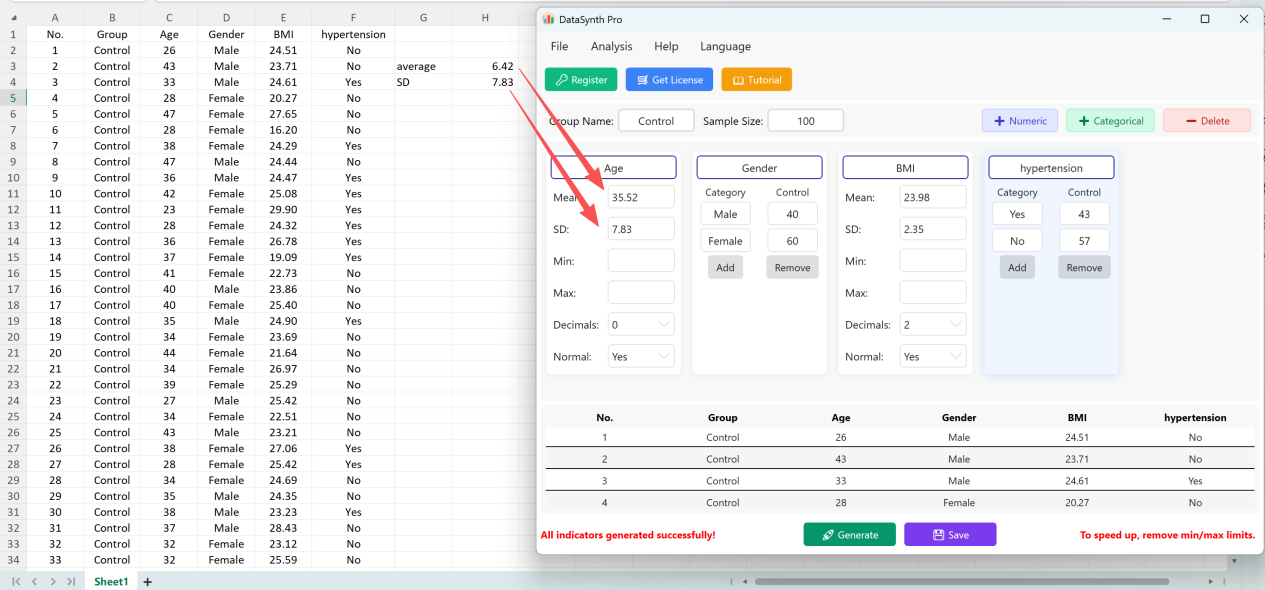
Рисунок 1.8: Результаты проверки совпадают с начальными настройками
1.6 Вычислительная эффективность
Оснащенный высокопроизводительным оптимизационным движком, программа может генерировать наборы данных, содержащие тысячи или десятки тысяч записей, за секунды.
Советы и рекомендации:
• Предпочтение нормального распределения: Данные по умолчанию соответствуют нормальному распределению для беспрепятственного последующего анализа.
2. Независимый T-Тест
Предназначен для поперечных исследований, сравнивающих средние двух различных групп. Широко используется в клинических испытаниях и социологических опросах.
2.1 Рабочий процесс
Перейдите в Analyze → Independent T-Test.
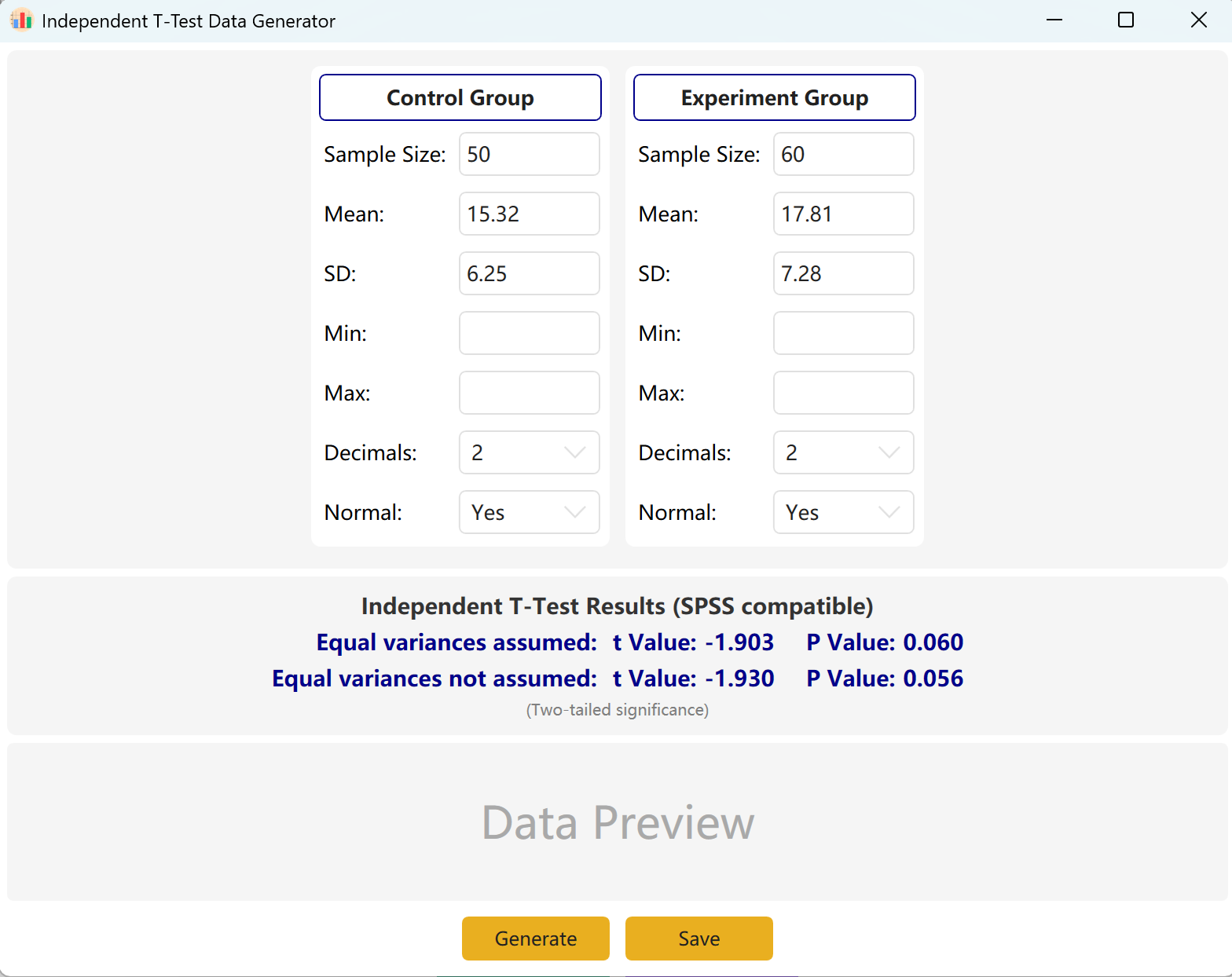
Рисунок 2.1: Настройка независимого T-Теста
2.2 Параметры
Программа предварительно заполняет примеры настроек для «Контрольной группы» и «Экспериментальной группы». Введите размер выборки, среднее и стандартное отклонение для каждой группы, чтобы просмотреть вычисленные t-значение и p-значение в реальном времени.
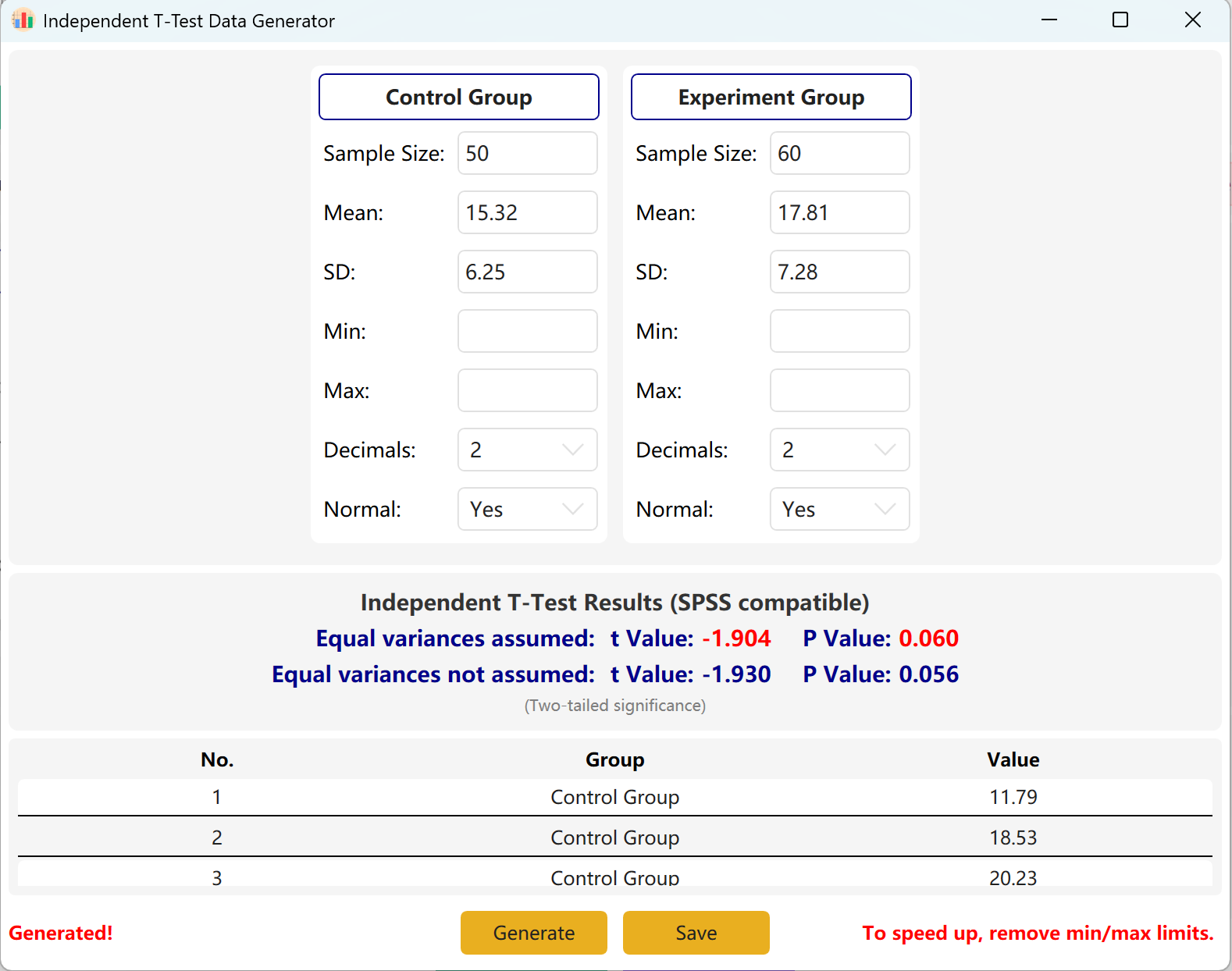
Рисунок 2.2: Отображение данных независимого T-Теста
3. Парный T-Тест
Используется для лонгитюдных исследований или crossover-исследований, где одни и те же субъекты измеряются дважды (например, до и после теста).
3.1 Рабочий процесс
Перейдите в Analyze → Paired T-Test.
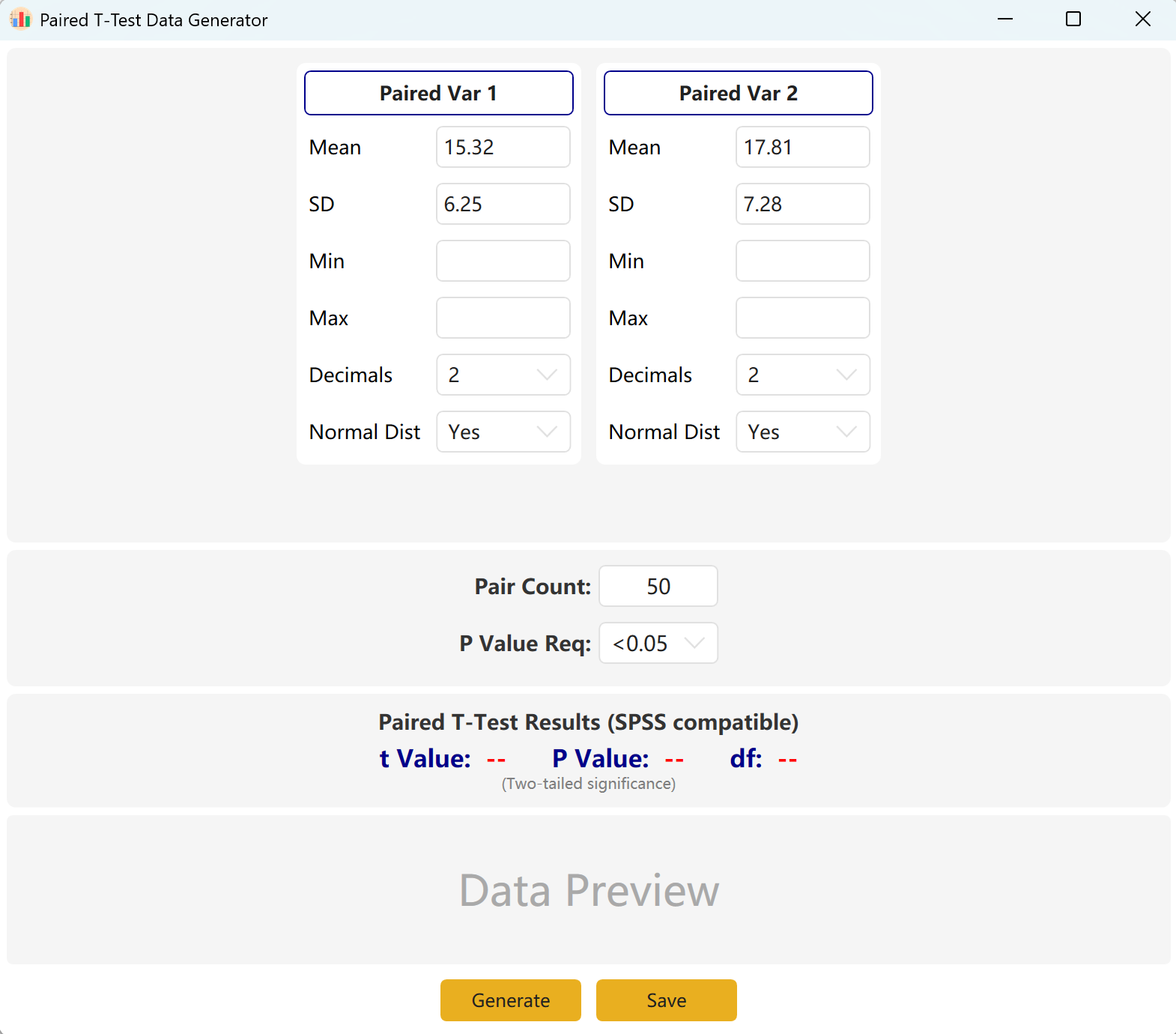
Рисунок 3.1: Настройка парного T-Теста
3.2 Логика моделирования
Программа по умолчанию устанавливает две парные переменные. Вы можете определить среднее и стандартное отклонение для каждой переменной и установить целевой диапазон p-значения.
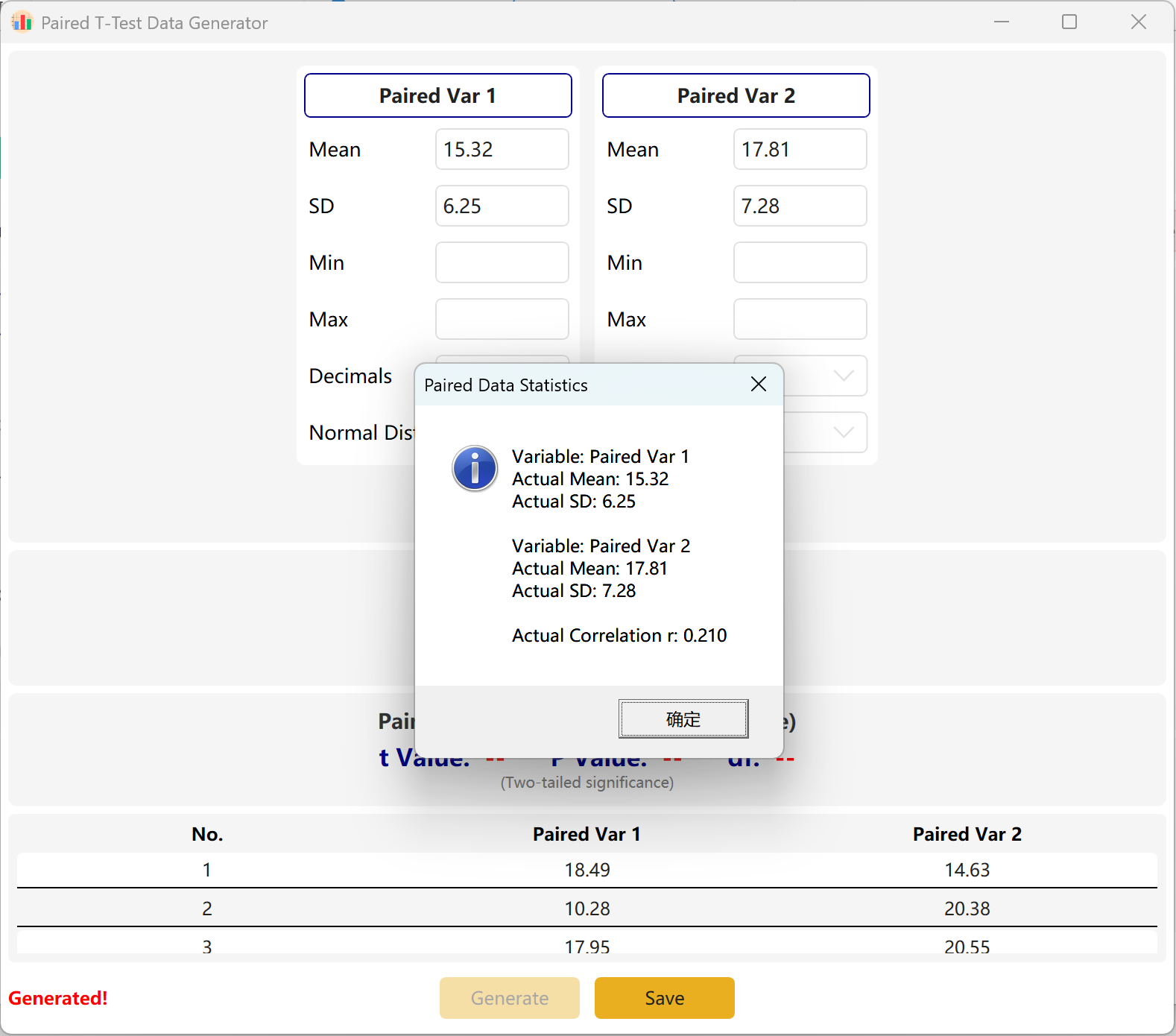
Рисунок 3.2: Отображение данных парного T-Теста
4. Критерий Хи-квадрат
Определяет наличие значимой связи между двумя категориальными переменными. Широко используется для демографических кросс-табуляций.
4.1 Рабочий процесс
Перейдите в Analyze → Chi-Square Test.
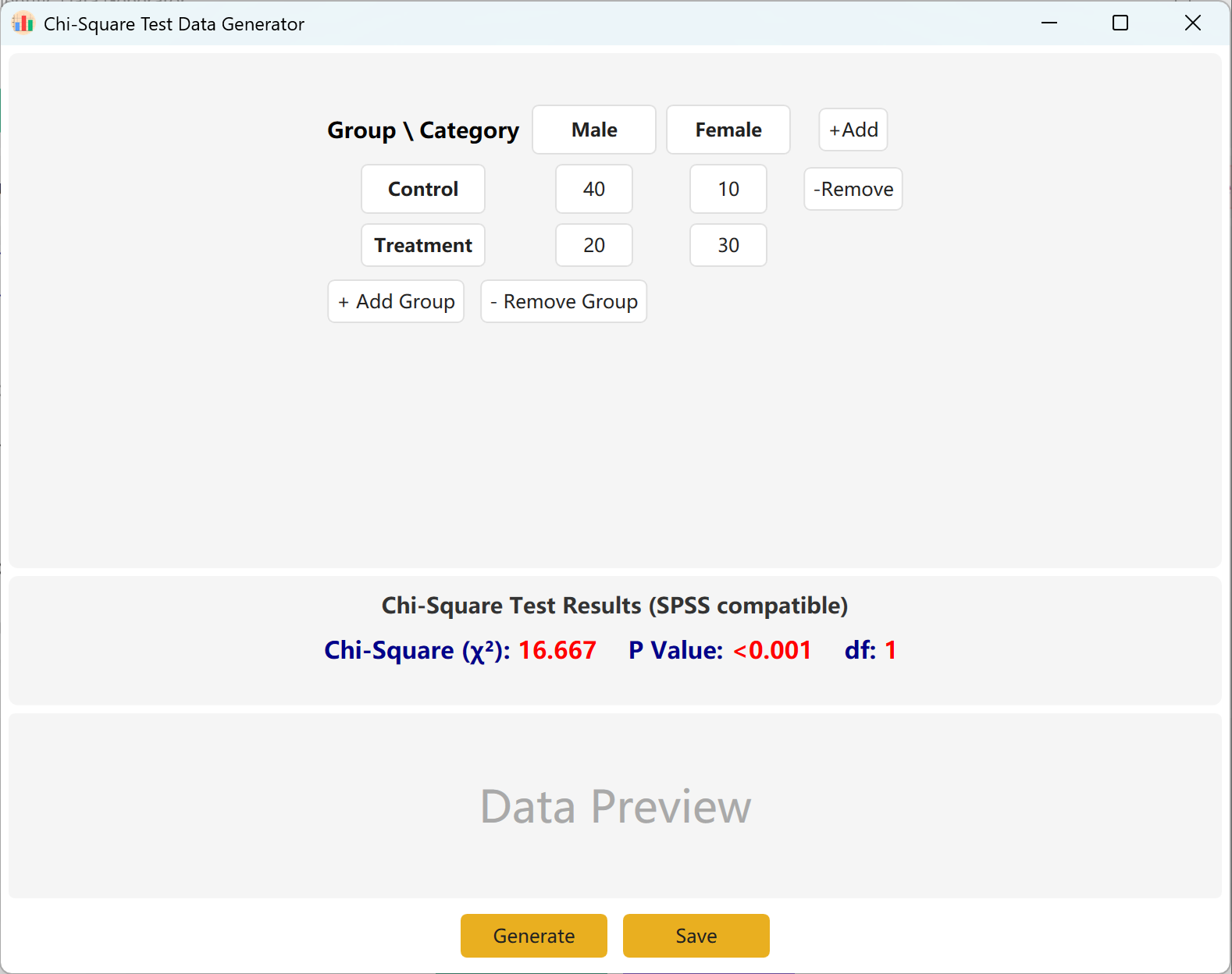
Рисунок 4.1: Настройка критерия Хи-квадрат
4.2 Матрица сопряженности
Интерфейс по умолчанию использует стандартную таблицу сопряженности 2x2. Заполните наблюдаемые частоты для каждой ячейки.
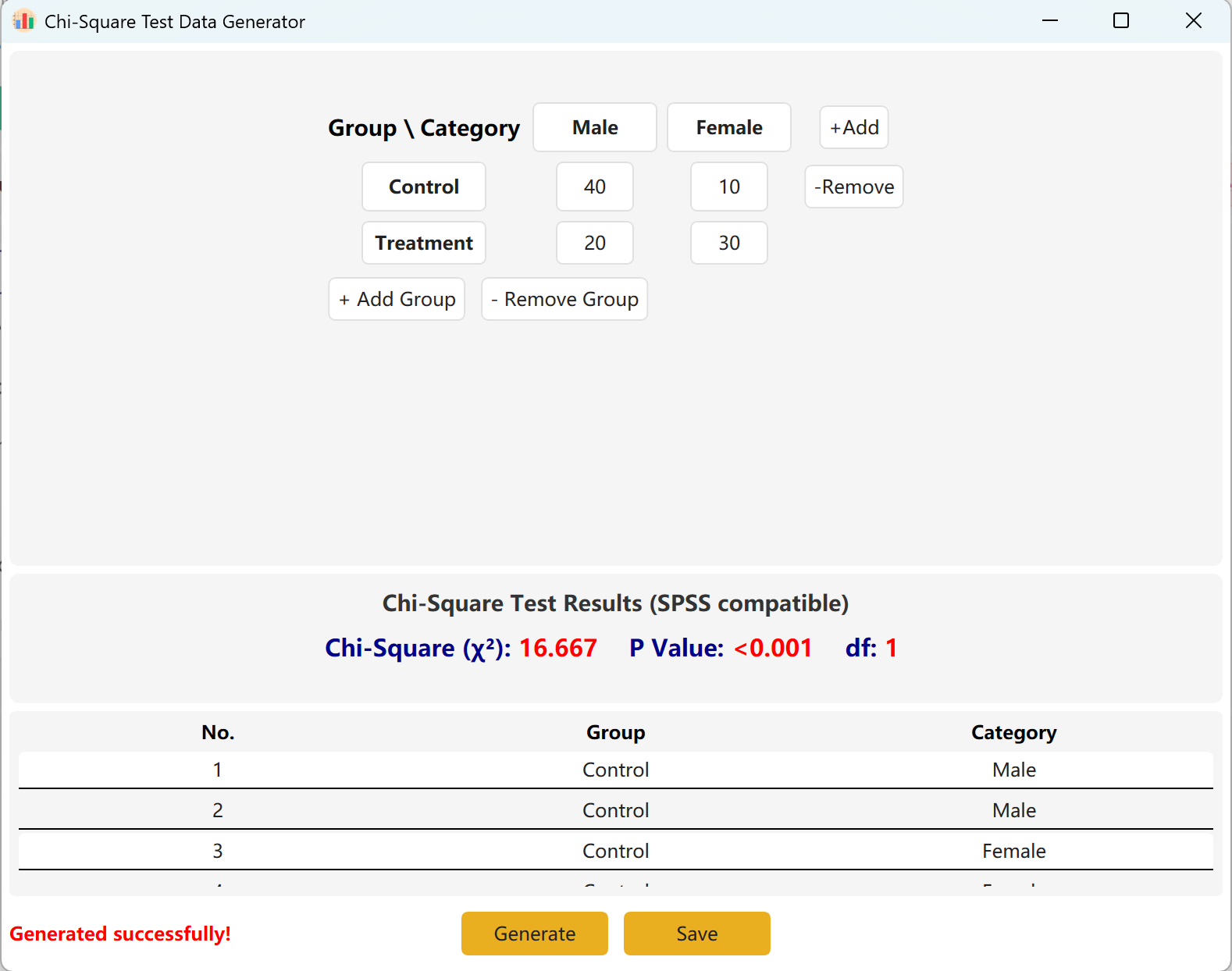
Рисунок 4.2: Отображение данных критерия Хи-квадрат
5. Однофакторный ANOVA
Используется при сравнении средних трех или более независимых групп. Алгоритм синтезирует внутригрупповую дисперсию и межгрупповые различия для достижения целевых F-значений.
5.1 Рабочий процесс
Перейдите в Analyze → ANOVA → One-Way ANOVA.
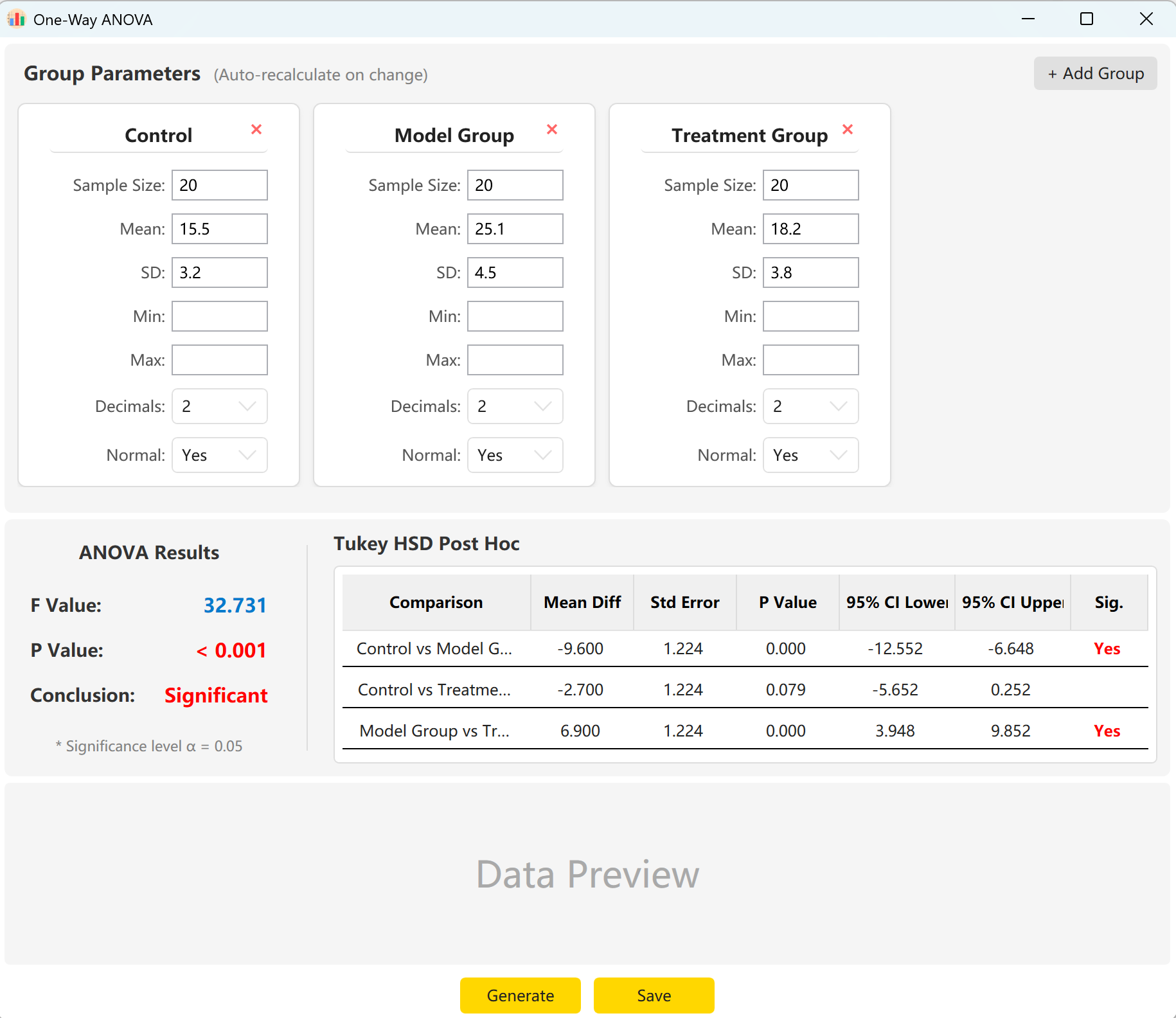
Рисунок 5.1: Настройка однофакторного ANOVA
5.2 Конфигурация
Система предварительно загружает параметры для трех групп. Просто введите размер выборки, среднее и стандартное отклонение для каждой группы.
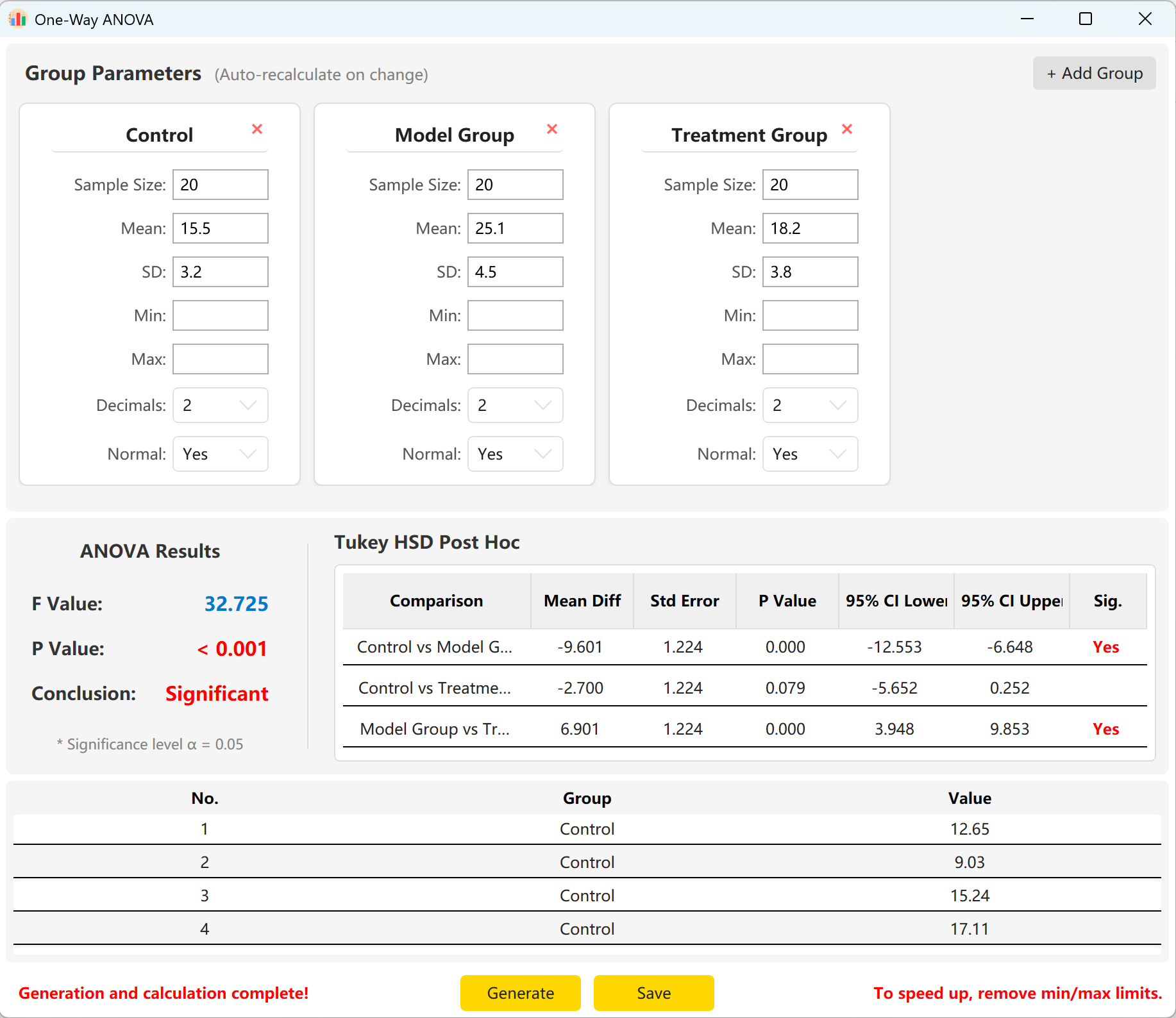
Рисунок 5.2: Отображение данных однофакторного ANOVA
6. Двухфакторный ANOVA
Исследует влияние двух независимых категориальных переменных на одну непрерывную зависимую переменную.
6.1 Рабочий процесс
Перейдите в Analyze → ANOVA → Two-Way ANOVA.
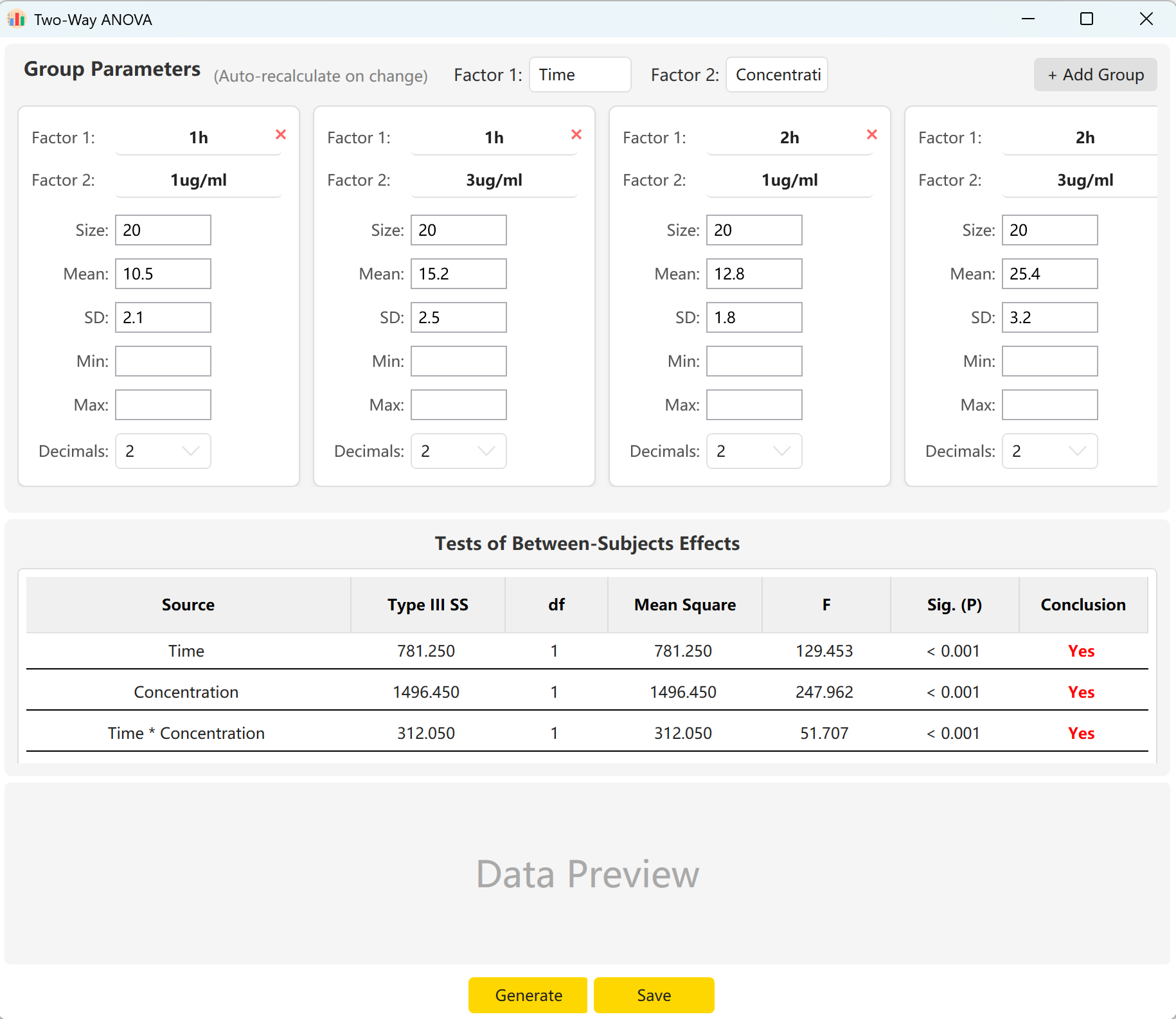
Рисунок 6.1: Настройка двухфакторного ANOVA
6.2 Факторы и взаимодействия
Инструмент по умолчанию использует два фактора: «Время» и «Концентрация».
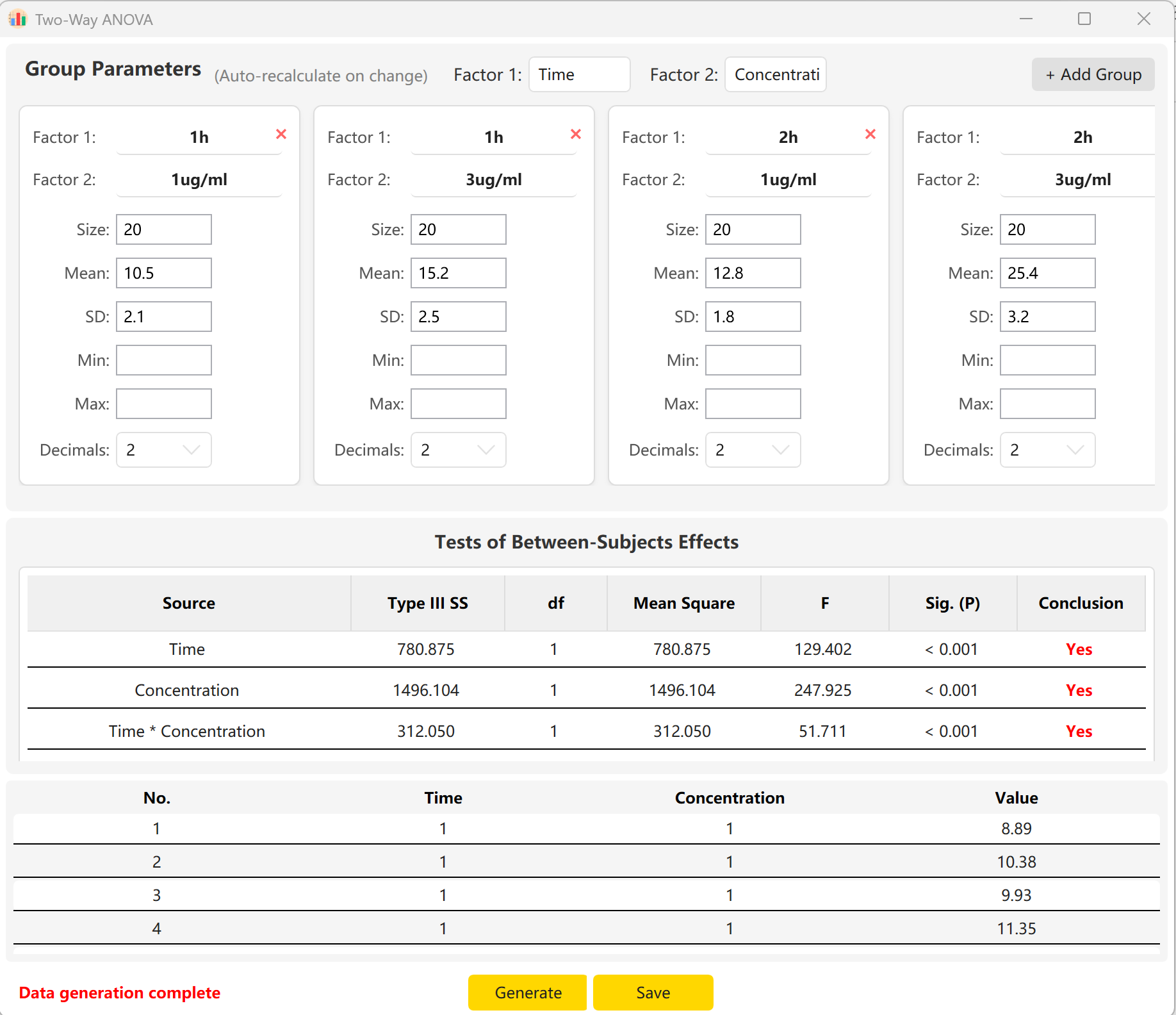
Рисунок 6.2: Отображение данных двухфакторного ANOVA
7. Однофакторный ANOVA с повторными измерениями
Расширение парного T-Теста на три или более временных точки. Идеально подходит для лонгитюдного отслеживания.
7.1 Рабочий процесс
Перейдите в Analyze → ANOVA → Repeated Measures ANOVA.
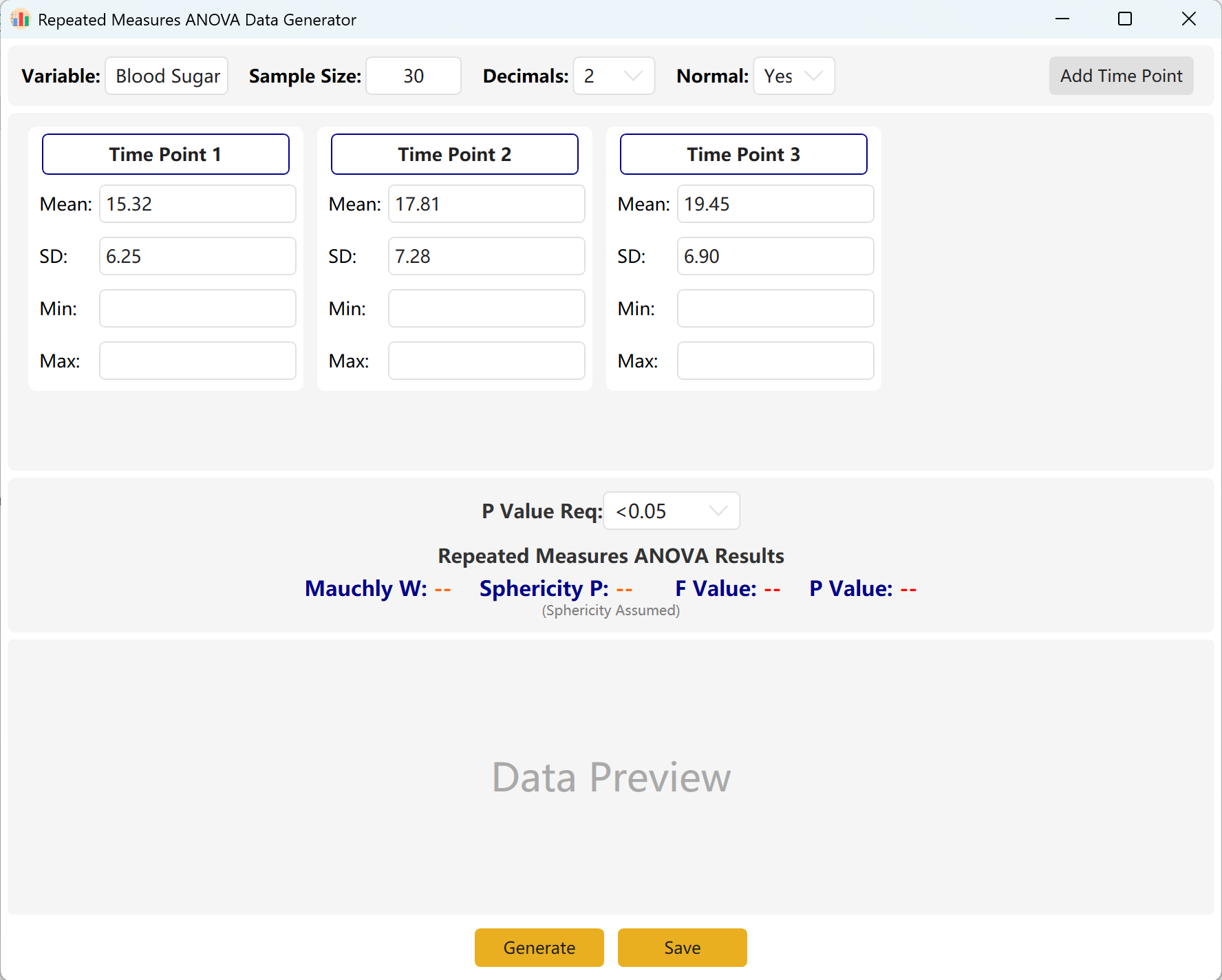
Рисунок 7.1: Настройка ANOVA с повторными измерениями
7.2 Повторные наблюдения
Система по умолчанию использует три временные точки наблюдения.
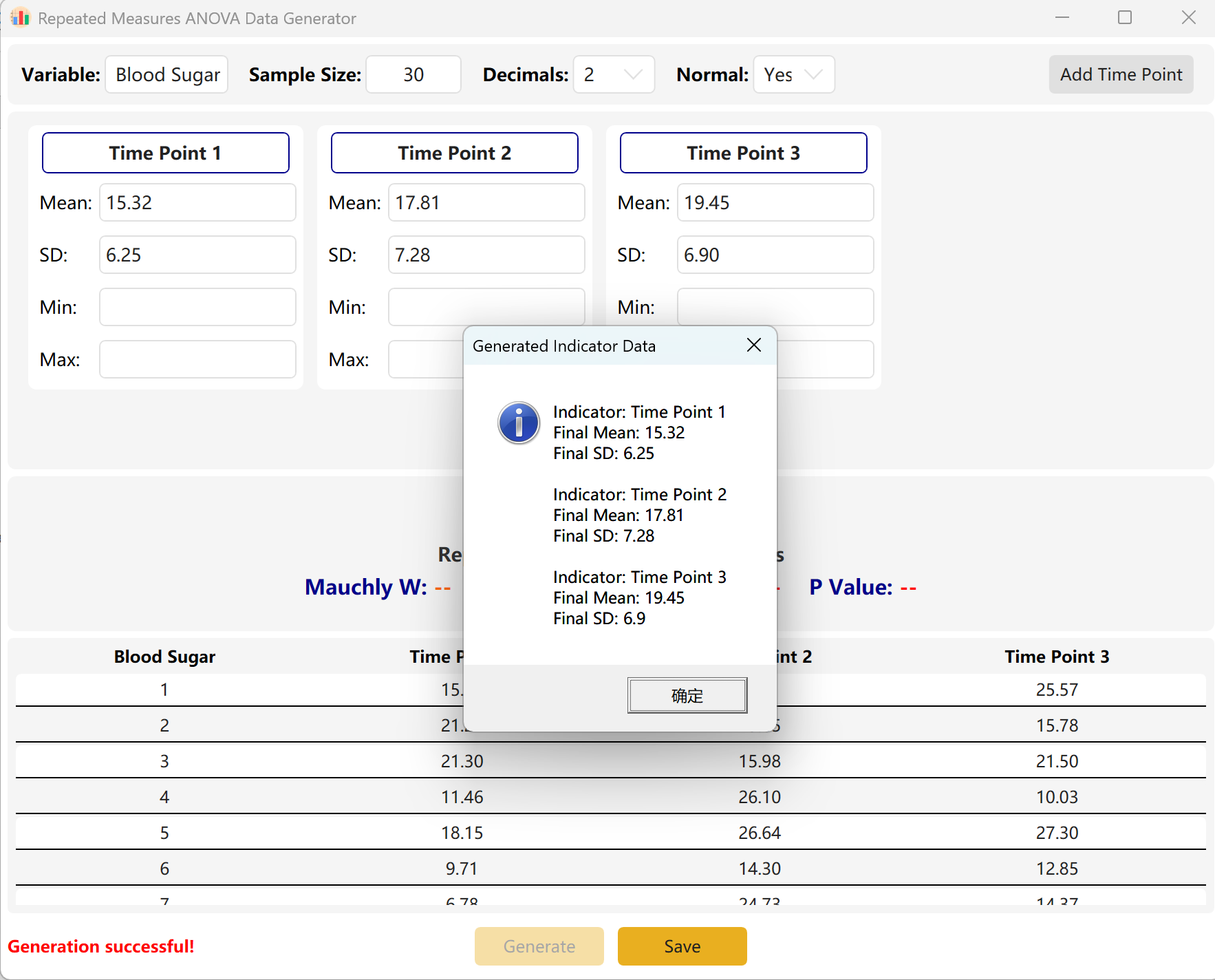
Рисунок 7.2: Отображение данных ANOVA с повторными измерениями
8. Ранговый суммарный тест для двух независимых выборок (Непараметрический)
Альтернатива U-тесту Манна-Уитни для данных, не соответствующих предположению о нормальности.
8.1 Рабочий процесс
Перейдите в Analyze → Non-parametric → 2 Independent Samples.
1.png)
Рисунок 8.1: Настройка теста для двух независимых выборок
9. Критерий Краскела-Уоллиса (K независимых выборок)
Эквивалент H-теста Краскела-Уоллиса. Генерирует порядковые или ненормально распределенные непрерывные данные для трех или более независимых групп.
9.1 Рабочий процесс
Перейдите в Analyze → Non-parametric → K Independent Samples.
1.png)
Рисунок 9.1: Настройка критерия Краскела-Уоллиса
10. Генерация квартильных данных
Разделяет упорядоченный по рангам набор данных на четыре равные части. Полезно для оценки разброса и центральной тенденции данных.
10.1 Рабочий процесс
Перейдите в Analyze → Quartile Data.
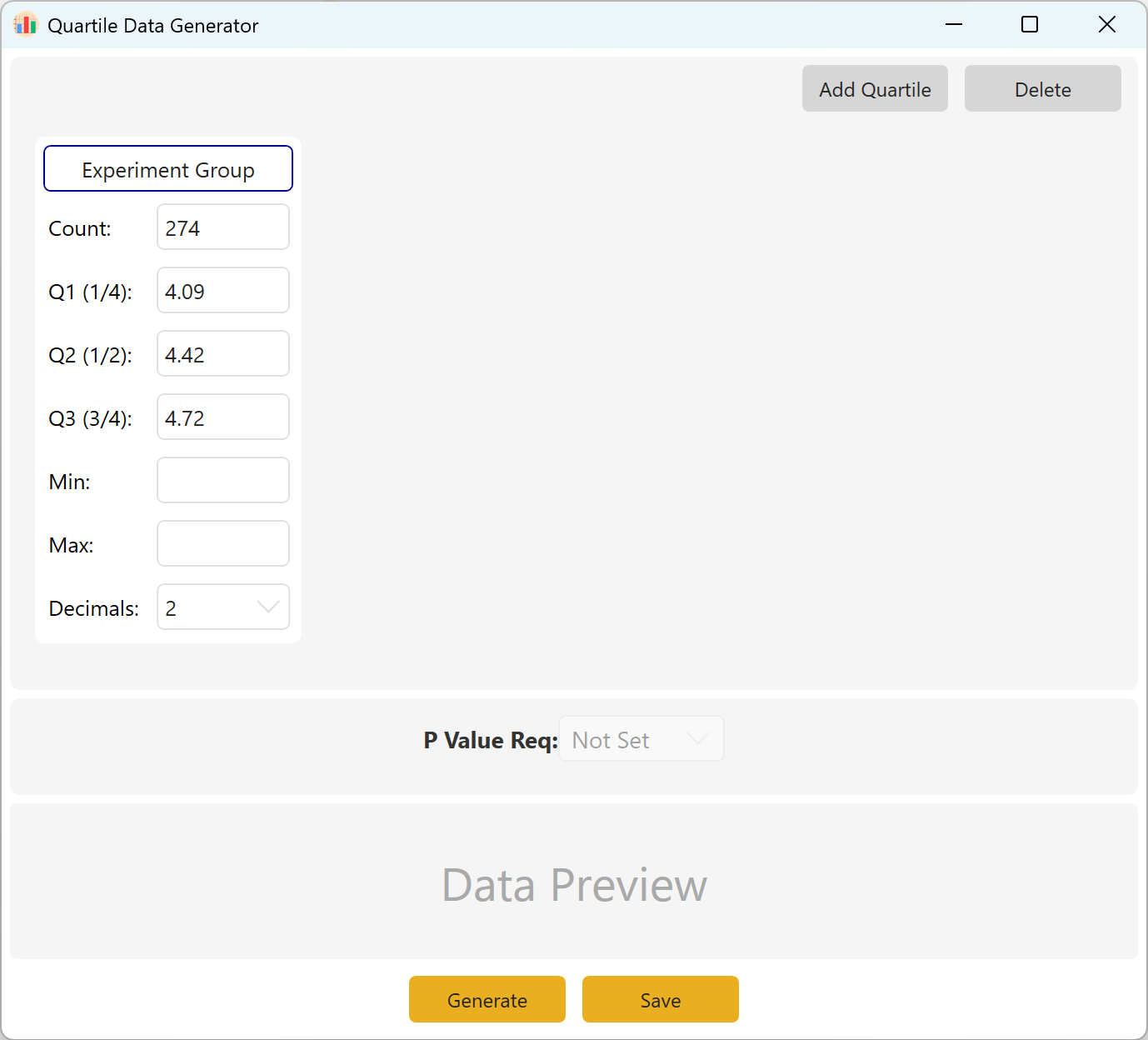
Рисунок 10.1: Настройка квартильных данных
11. Генерация данных для бинарной логистической регрессии
Необходим для задач классификации, где результат является дихотомическим. Широко используется в эпидемиологии.
11.1 Рабочий процесс
Перейдите в Analyze → Regression → Binary Logistic.
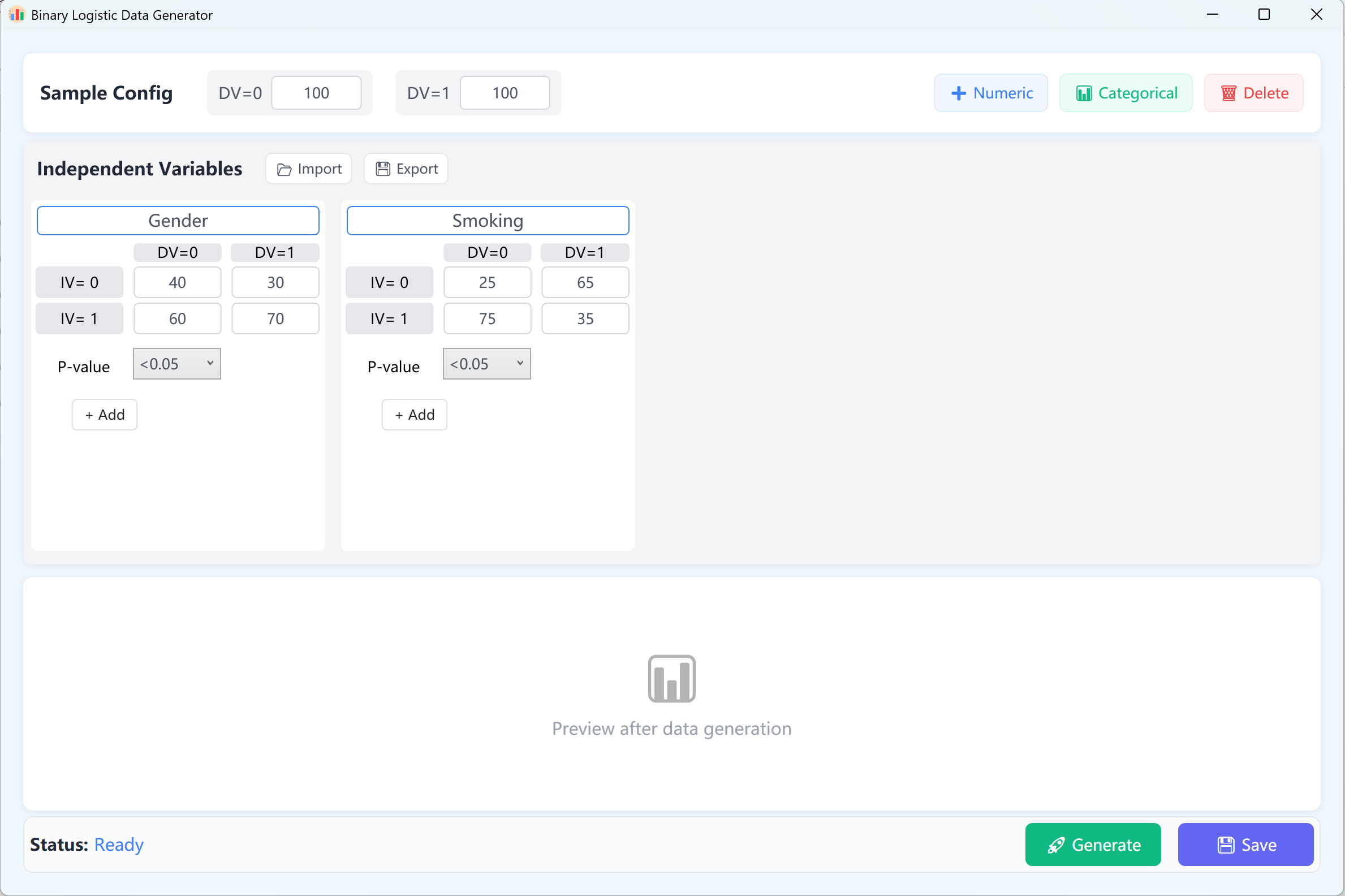
Рисунок 11.1: Настройка бинарной логистической регрессии
12. Генерация данных для множественной линейной регрессии
Основной инструмент прогнозного моделирования.
12.1 Рабочий процесс
Перейдите в Analyze → Regression → Linear Regression.
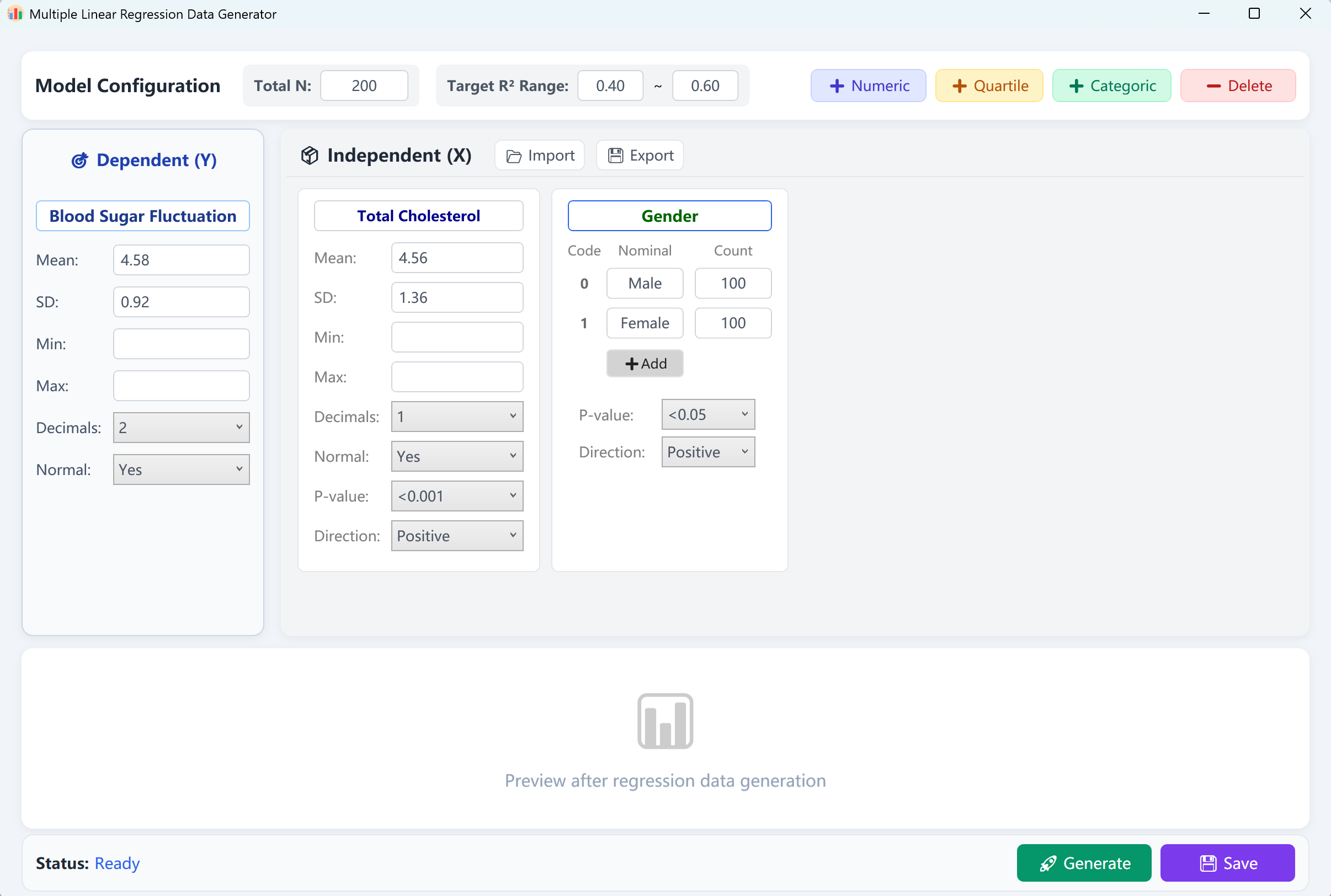
Рисунок 12.1: Настройка множественной линейной регрессии
13. Генерация данных для регрессии пропорциональных рисков Кокса
Золотой стандарт анализа выживаемости. Моделирует данные времени до события с учетом цензурирования справа.
13.1 Рабочий процесс
Перейдите в Analyze → Regression → Cox Regression.
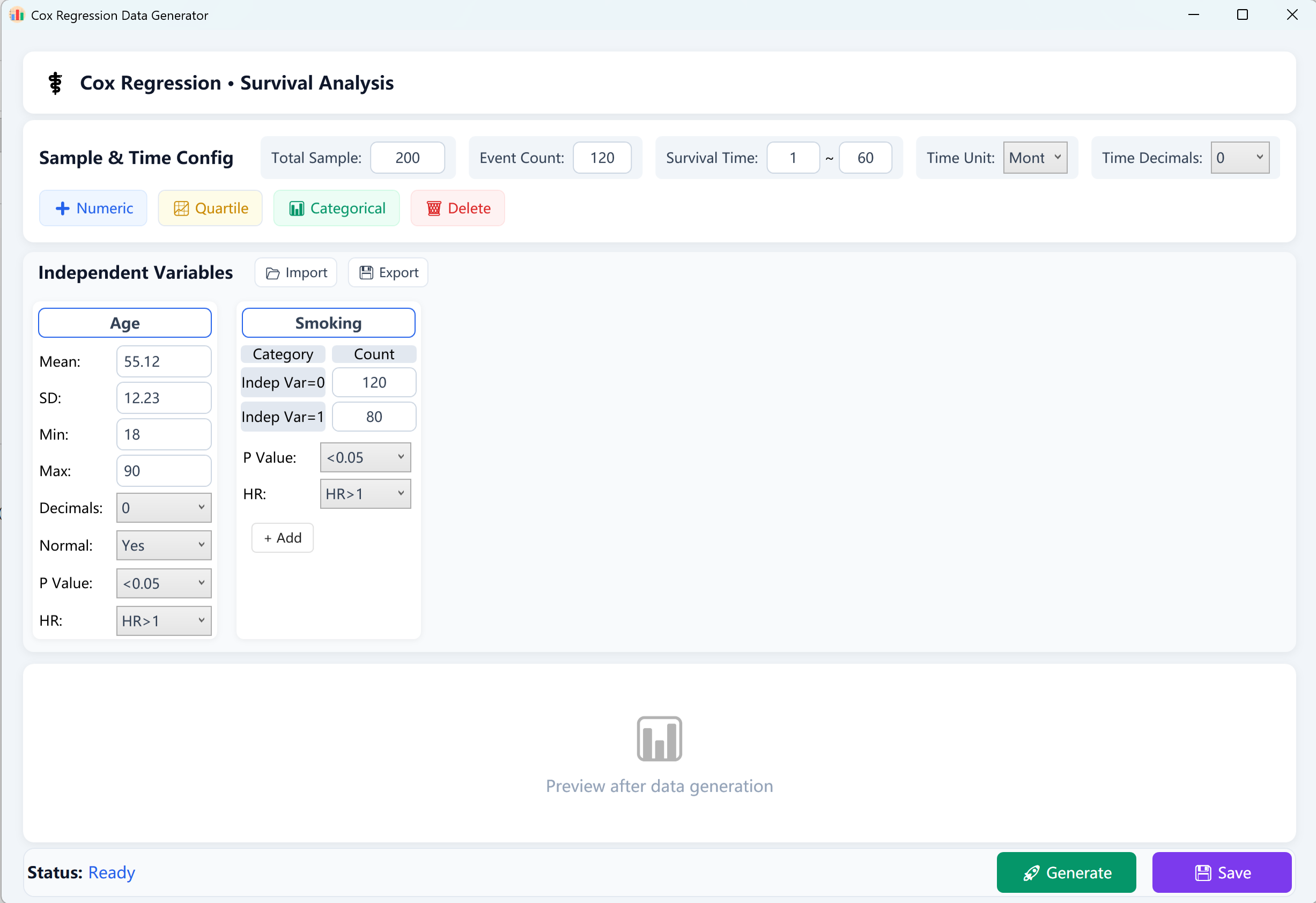
Рисунок 13.1: Настройка регрессии Кокса
14. Генерация данных для корреляционного анализа
Моделирует бивариантные связи (Пирсона или Спирмена) и частную корреляцию.
14.1 Рабочий процесс
Перейдите в Analyze → Correlation.
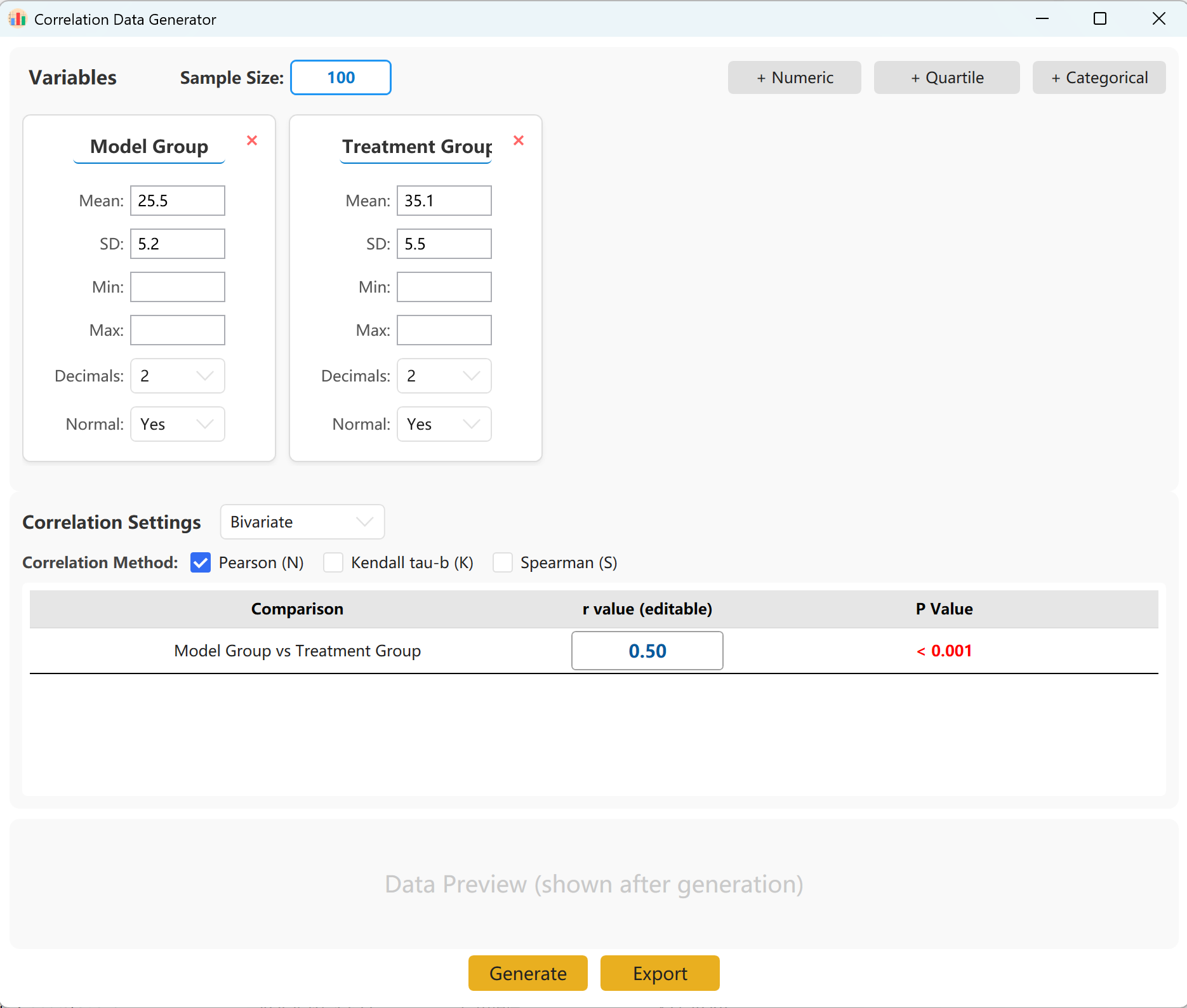
Рисунок 14.1: Настройка корреляционного анализа
15. Генерация данных для анализа ROC-кривых
Оценивает диагностическую способность тестовой переменной различать два состояния.
15.1 Рабочий процесс
Перейдите в Analyze → ROC Curve.
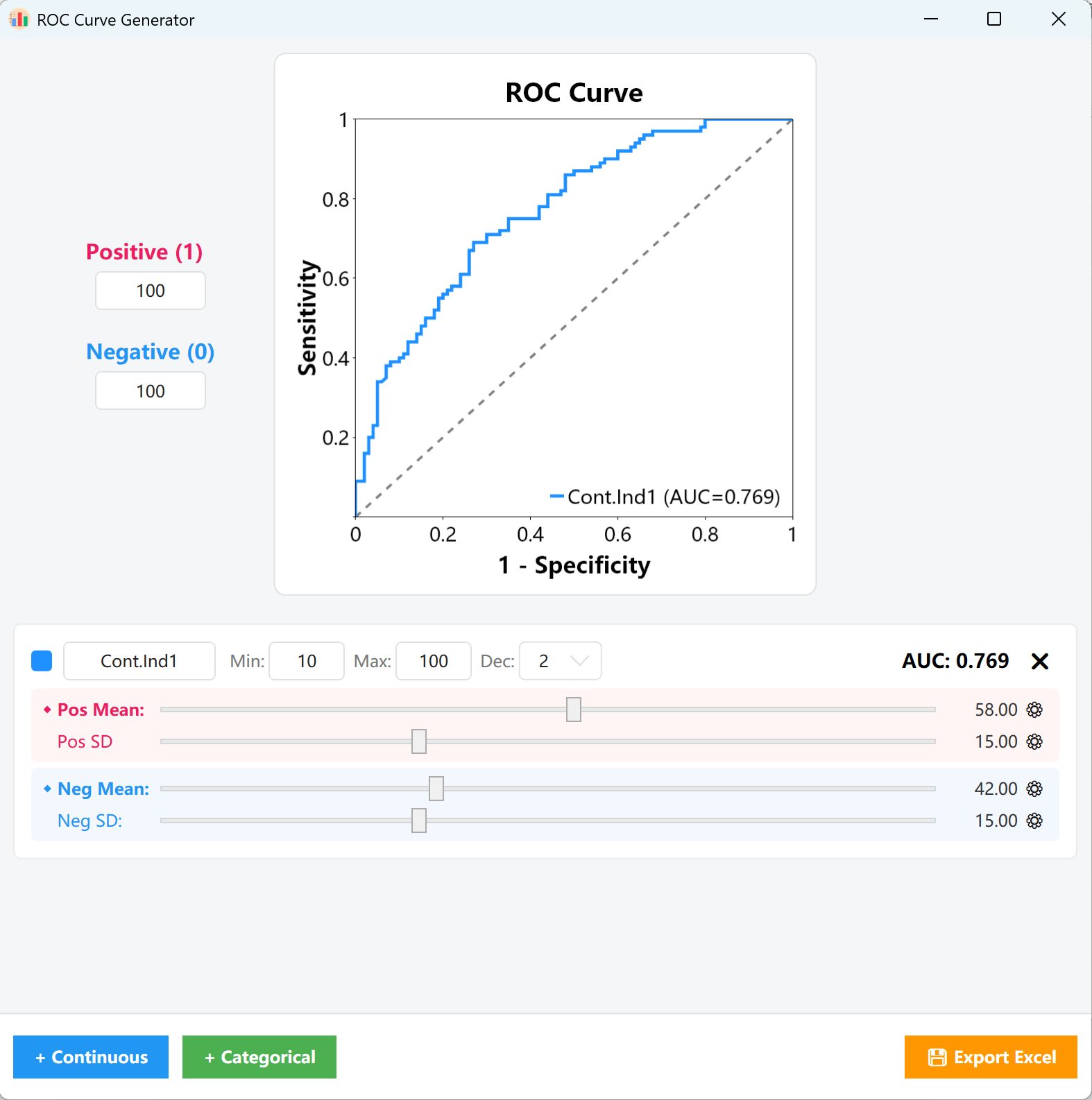
Рисунок 15.1: Настройка ROC-кривой
16. Сохранение и экспорт настроек конфигурации
Для оптимизации повторяющихся задач моделирования приложение предоставляет мощный механизм сохранения состояния конфигурации.
16.1 Сохранение/Восстановление
- Экспорт конфигурации: Перейдите в File → Export Configuration для сохранения всех параметров в файл `.json`.
- Импорт конфигурации: Перейдите в File → Import Configuration и выберите ранее сохраненный файл конфигурации.